") 阿里&華科大提出ONE-PEACE:更好的通用表征模型,刷新多個SOTA!
阿里&華科大提出ONE-PEACE:更好的通用表征模型,刷新多個SOTA!

上次介紹ImageBind給大家預告了我們近期會推出一個新工作,今天正式推出我們的通用多模態(tài)表征模型ONE-PEACE,拿到多個SOTA,展現(xiàn)emergent zeroshot的能力。正式放arxiv,github repo剛開,歡迎關注以及給個star支持下!

ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities
論文:https://arxiv.org/abs/2305.11172
代碼:https://github.com/OFA-Sys/ONE-PEACE
為什么是通用多模態(tài)表征模型
表征模型的重要性無需多言,尤其CLIP之后大家都意識到一個好的多模態(tài)表征模型在很多單模態(tài)任務上都會發(fā)揮著至關重要的基礎模型的作用。學習了大量模態(tài)alignment的數(shù)據(jù)之后的模型逐漸在學會去理解各個模態(tài)和模態(tài)間蘊含的知識。但過去大部分模型,基本都把重點關注在圖文數(shù)據(jù)上了,主要還是得益于社區(qū)貢獻了大量高質(zhì)量的如LAION這類的數(shù)據(jù)集。然而如果想更進一步去理解世界,我們希望能夠把全世界各種模態(tài)的信息關聯(lián)在一起,至少我們希望看到一個prototype來說明怎么實現(xiàn)一個不限模態(tài)(unlimited modalities)的通用表征模型。
ImageBind算是跨出了重要的一步,但我之前文章提了我的個人觀點,就是采用小規(guī)模其他模態(tài)和圖像的對齊數(shù)據(jù)來實現(xiàn)其他模態(tài)encoder和CLIP的vision encoder的方案,這類取巧的方案成本低實現(xiàn)容易,也能拿到不錯的結果,但真想做到足夠好,還有一定距離。
我們大概去年意識到這個問題開始嘗試做這個事情,相對來說兩位核心輸出的同學做起來有點苦哈哈,辛苦去收集數(shù)據(jù)和吭吭搞大規(guī)模預訓練。不過功夫不負有心人,我們還是一把輸出了一個4B規(guī)模的通用表征模型(圖文音三模態(tài)統(tǒng)一),在語義分割、音文檢索、音頻分類和視覺定位幾個任務都達到了新SOTA表現(xiàn),在視頻分類、圖像分類圖文檢索、以及多模態(tài)經(jīng)典benchmark也都取得了比較領先的結果。另外,模型展現(xiàn)出來新的zeroshot能力,即實現(xiàn)了新的模態(tài)對齊,比如音頻和圖像的對齊,或者音頻+文字和圖像的對齊,而這類數(shù)據(jù)并沒有出現(xiàn)在我們的預訓練數(shù)據(jù)集里。下面我來具體介紹下方法實現(xiàn)
ONE-PEACE的方法
總體而言,ONE-PEACE的模型結構核心還是基于transformer,只不過針對多模態(tài)做了特殊的設計,當然這里也得感謝前人的很多工作積累了非常多有用的經(jīng)驗。預訓練任務的思路就是幾個重要的多任務訓練,圍繞contrastive learning展開。模型架構和訓練方法整體如下圖所示:
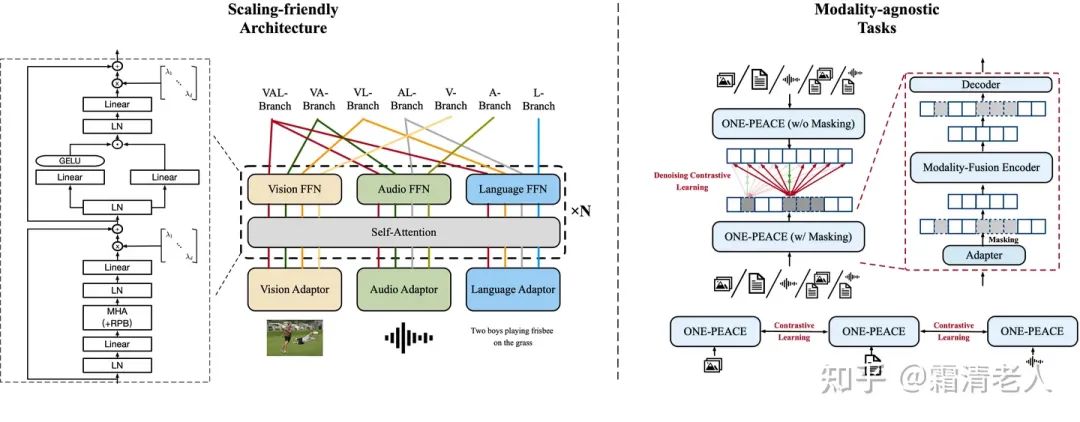
模型結構本質(zhì)上還是transformer,處理方法和我們之前做OFA接近,通過各自模態(tài)的adaptor實現(xiàn)信息的向量化,傳入Transformer engine。這里language adaptor就是最簡單的word embedding,vision adaptor采用了hierarchical MLP,相比過去使用ResNet或者CLIP ViT成本更低,audio adaptor采用的是convolutional feature extractor。輸入Transformer模型后,我們希望模型既有統(tǒng)一處理的部分,也有模態(tài)特定的處理部分。參考VLMo和BeiT-3的成功經(jīng)驗,我們將FFN部分設計成multiway(Modality-specific MoE)的方式,每個模態(tài)包含各自的FFN層。而在Transformer內(nèi)部,主要實現(xiàn)了幾處改動。一是GeGLU的引入,相比GeLU能實現(xiàn)更好的效果;二是相對位置編碼,實現(xiàn)更好的position表示;三是使用了Magneto的方案,在attention和FFN均新增layernorm增加訓練穩(wěn)定性,四是使用LayerScale,同樣能夠提升訓練穩(wěn)定性。
訓練方法上,我們主要圍繞對比學習展開,只不過實際實現(xiàn)并非只使用一個模態(tài)一個embedding然后做InfoNCE的方案。這部分主要分為兩類任務:
跨模態(tài)對比學習:這部分可以認為和CLIP的訓練方法類似,只不過擴展到更多的模態(tài)組合,從而實現(xiàn)模態(tài)和模態(tài)之間的對齊。這里我們同樣沒有遍歷所有模態(tài)的兩兩組合,而選用文本作為中介。
模態(tài)內(nèi)去噪對比學習:名字有點拗口,這里用的詞是intra-modal denoising contrastive learning。這個任務的本質(zhì)是masked element(language/image/audio)modeling,但走的是feature distillation的路線。之后有機會整理下feature distillation這條線的工作,在表征學習上還是取得不錯的進展。那么這里的masked element modeling,用的是拿沒被mask的輸入得到的表征作為teacher指導被mask輸入得到的表征這個student。有別于對應位置向量做L1/L2 loss的經(jīng)典方案,這里用的是對比學習。
整個訓練分為兩個階段,第一個階段可以理解為奠定基礎的訓練,即經(jīng)典的圖文數(shù)據(jù)預訓練。在這一部分圖文相關的參數(shù)都會被更新,包括self attention以及這兩個模態(tài)各自的FFN。而訓練完備后,如果要增加新的模態(tài),比如語音,只需要使用語音-文本對數(shù)據(jù)繼續(xù)預訓練,而這個階段就只有語音相關的參數(shù)會被更新,比如語音adaptor和語音FFN等。這種增加模態(tài)的方案同樣可以不斷拓展到更多模態(tài)上,只要使用上能夠align上其中一個模態(tài)的配對數(shù)據(jù)即可,而且因為很多參數(shù)共用,相比重新訓一個modality specific的encoder更容易拿到好結果。
實驗效果
實驗分為finetuning和zeroshot兩個部分,其中finetuning更多追求效果上的絕對提升,而zeroshot則是觀測其本身作為通用模型的表現(xiàn),尤其是emergent zeroshot capabilities這個部分更是展現(xiàn)這種模型能夠達到類比無監(jiān)督訓練的效果。
這里我調(diào)換下順序先介紹下比較有趣的emergent zeroshot capabilities。這里我們沒有合適的benchmark去評估,但是可以看不少有趣的例子。可以看到,模型不僅實現(xiàn)了新的模態(tài)對齊,還學會組合不同模態(tài)的元素去對齊新的模態(tài)。比如一個經(jīng)典的例子就是語音+文本召回圖片,比如snow這個文本配上鳥叫的聲音,就能召回鳥在雪中的圖片,挺有意思。下面給出更多例子:

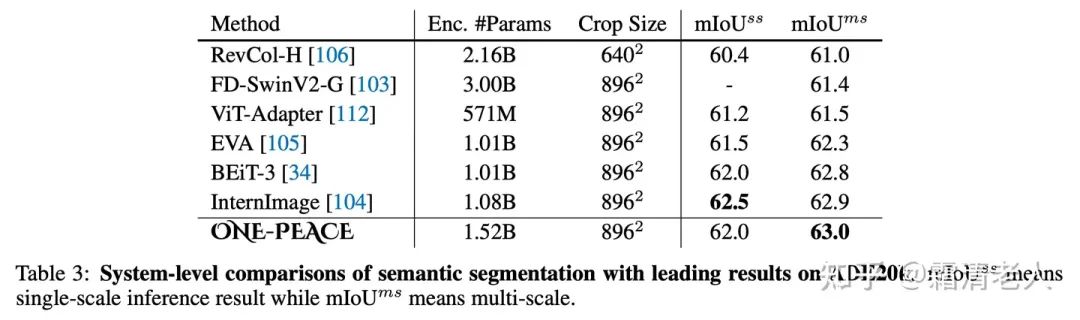
再看finetuning部分,ONE-PEACE主要在CV的任務上表現(xiàn)比較突出。其中在ADE20K上做語義分割,超出了EVA、BeiT-3、InternImage等一眾SOTA模型:
在MSCOCO上做物體檢測和實例分割僅次于RevCol,并且ONE-PEACE并沒有做Object365的intermediate finetuning:

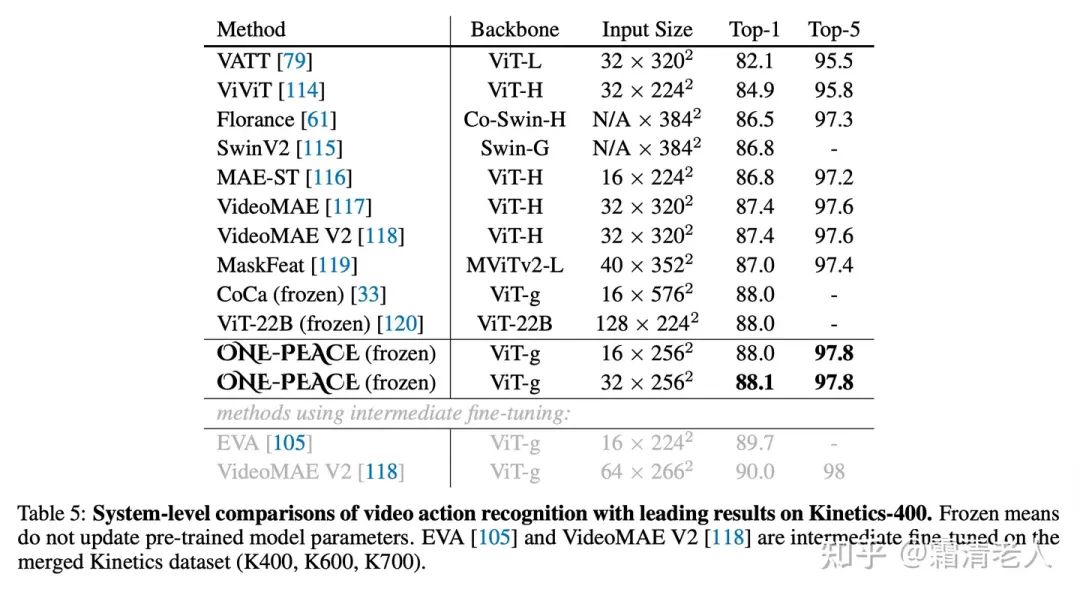
視頻分類的K400上,也達到88.1,超過了之前諸如CoCa的模型:
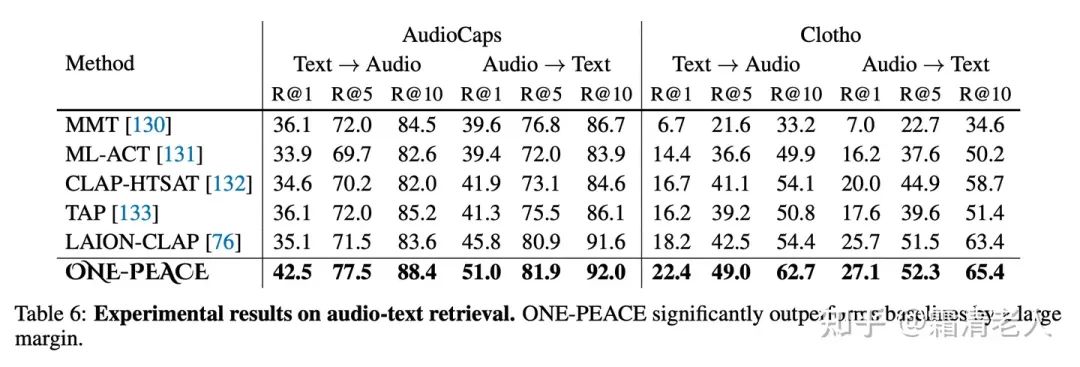
而落到語音領域,不管在音文檢索、音頻分類還是語音VQA上,都實現(xiàn)了新的SOTA,超過了LAION的LAION-CLAP:
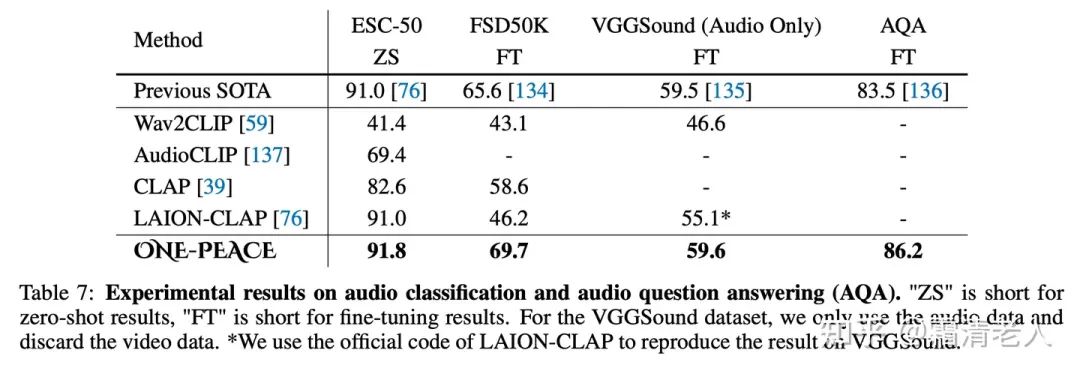
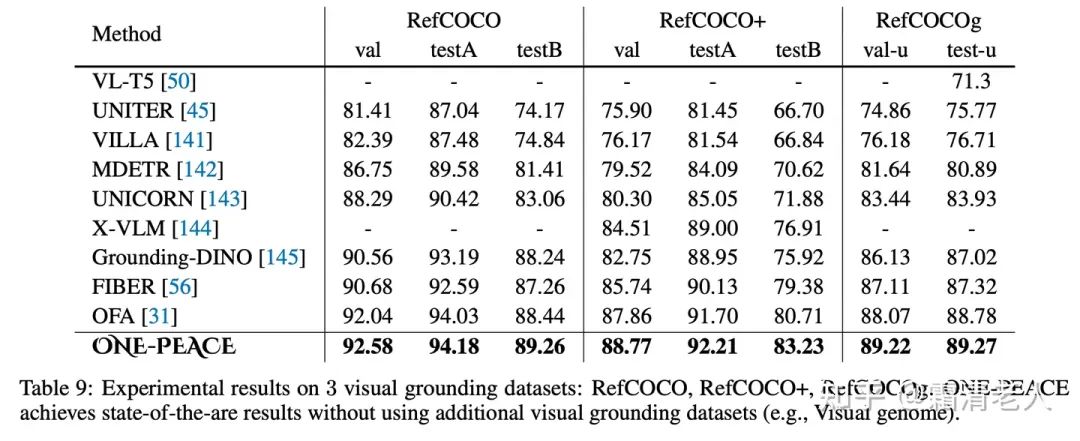
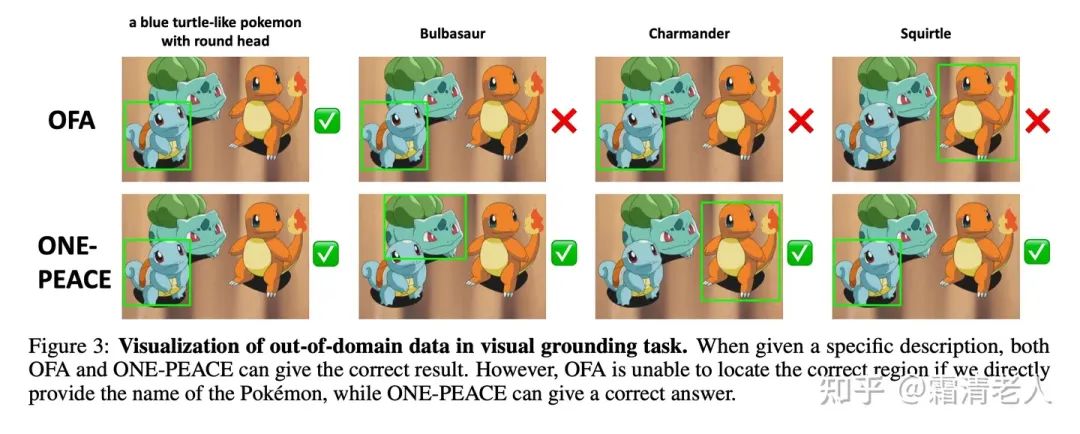
經(jīng)典的多模態(tài)benchmark上,在視覺定位這個任務上ONE-PEACE直接達到了SOTA表現(xiàn),并且在out-of-domain的setup下面也有很robust的表現(xiàn):
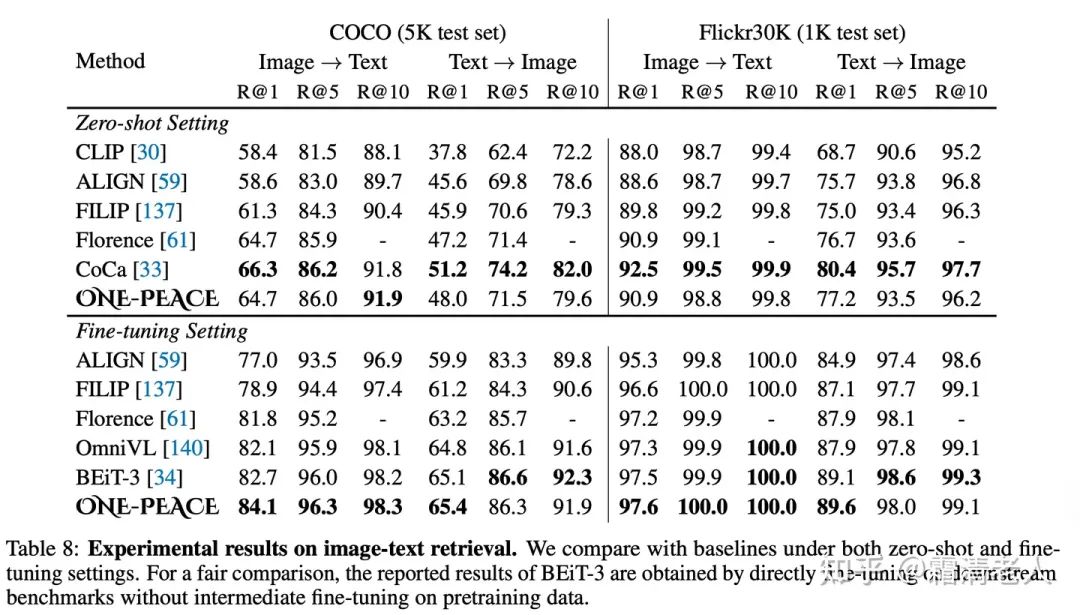
圖文檢索上,我們主要和沒有經(jīng)過intermediate finetuning的模型進行比較,主要對標的是雙塔召回模型,同樣可以看到ONE-PEACE不俗的表現(xiàn):
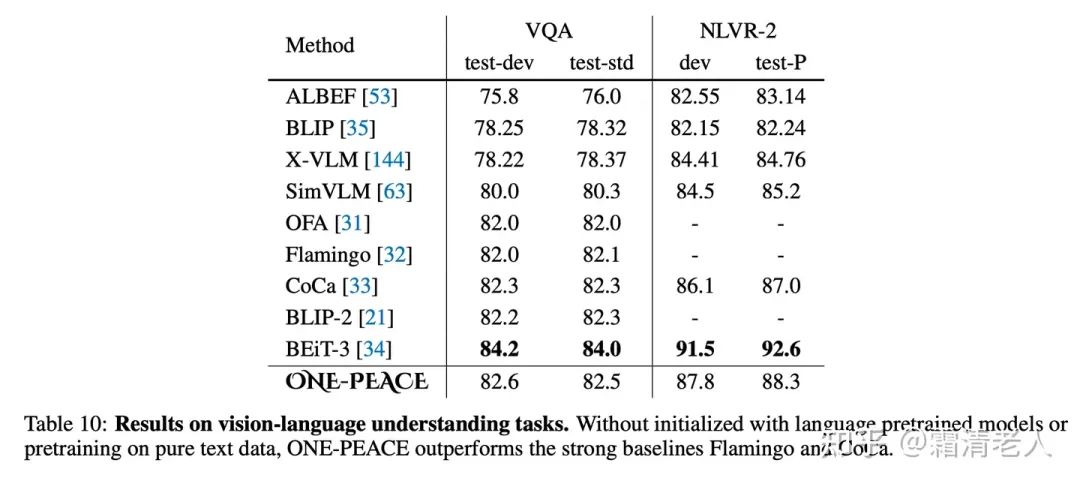
VQA和NLVR-2屬實肝不動BeiT-3,不過相比其他基本都有明顯優(yōu)勢:
當然,說這么多效果方面的東西,只是為了證明這個模型還是比較能打的。雖然沒法全部刷新那么狠,但可以看到一個模型可以做到整體這個效果,應該拉出去實際場景用用還是可以的。
不足與未來工作
不足之處其實上文也可以看到確實有些效果沒太做到頂,但僅僅追求SOTA意義其實不大。下一步我們要做的,其實是給出更多成功的實踐將這個模型擴展更多模態(tài),尤其是對比如視頻這類復雜模態(tài),怎么在真正高難度的任務上做得更好。另外,表征模型的潛力絕不僅僅只是在finetuning,也不在單純的zeroshot檢索,而在于其良好的對齊從而通過通用大模型做更復雜的人物,比如結合LLM。當前多模態(tài)LLM這個賽道發(fā)展如火如荼,ONE-PEACE怎么實現(xiàn)和強大的LLM結合,從而實現(xiàn)對世界的跨模態(tài)復雜任務的處理,也許相比追求benchmark更加關鍵。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1096瀏覽量
42330 -
模型
+關注
關注
1文章
3752瀏覽量
52111 -
數(shù)據(jù)集
+關注
關注
4文章
1236瀏覽量
26196
原文標題:阿里&華科大提出ONE-PEACE:更好的通用表征模型,刷新多個SOTA!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
IGBT的物理結構模型—BJT&MOS模型(1)
厲害了!阿里安全圖靈實驗室在ICDAR2017 MLT競賽刷新世界最好成績
Slew Rate of Op Amp Circuits
存儲類&作用域&生命周期&鏈接屬性

如何區(qū)分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),為true,你敢信?

攝像機&amp;amp;雷達對車輛駕駛的輔助
中科大&amp;字節(jié)提出UniDoc:統(tǒng)一的面向文字場景的多模態(tài)大模型
低成本擴大輸入分辨率!華科大提出Monkey:新的多模態(tài)大模型

高分工作!Uni3D:3D基礎大模型,刷新多個SOTA!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論