") 龍芯中科自研 GPGPU!大語言模型浪潮下,國產(chǎn)廠商如何把握機會?
龍芯中科自研 GPGPU!大語言模型浪潮下,國產(chǎn)廠商如何把握機會?

電子發(fā)燒友網(wǎng)報道(文/李彎彎)日前,在龍芯中科 2022 年度暨 2023 年第一季度業(yè)績暨現(xiàn)金分紅說明會上,龍芯中科董事長胡偉武宣布,集成龍芯自研 GPGPU (通用圖形處理器)的第一款 SoC 芯片預(yù)計將于 2024 年一季度流片。
胡偉武表示,目前已經(jīng)基本完成相關(guān) IP 研發(fā),正在開展全面驗證,在此基礎(chǔ)上,2024 年下半年將完成兼顧顯卡和算力加速功能的專用芯片流片。
大語言模型拉動GPGPU需求增長
GPGPU(通用圖形處理器),脫胎于 GPU(圖形處理器)。GPU最初是為解決 CPU 在圖形處理領(lǐng)域性能不足的問題而誕生的,而面對非圖像顯示領(lǐng)域并涉及大量并行運算的領(lǐng)域,比如 AI、加密解密、科學(xué)計算等,則更需要通用計算能力,GPGPU應(yīng)運而生。
近段時間,隨著ChatGPT的出圈,全球掀起大語言模型的研究熱潮。而無論是大模型的訓(xùn)練還是推理,這都離不開GPGPU芯片來提供算力支持。業(yè)界推測,在未來幾年內(nèi),大語言模型的訓(xùn)練和部署將推動GPGPU需求增長。
在訓(xùn)練端,英偉達(dá)可以說是這場大模型浪潮中的絕對受益者,目前全球大模型的訓(xùn)練基本依賴英偉達(dá)的GPU。英偉達(dá)有兩款強大的GPU產(chǎn)品:A100和H100。
A100 是英偉達(dá)2020年推出的數(shù)據(jù)中心級云端加速芯片,擁有540億晶體管,采用臺積電7nm工藝制程,支持FP16、FP32和FP64浮點運算,為人工智能、數(shù)據(jù)分析和HPC數(shù)據(jù)中心等提供算力。A100 提供超快速的顯存帶寬,可處理超大型模型和數(shù)據(jù)集。
H100是英偉達(dá)2022年3月發(fā)布的最新一代數(shù)據(jù)中心GPU,集成800億晶體管,采用臺積電定制的4nm工藝。英偉達(dá)CEO黃仁勛此前表示,這款GPU具有超強的計算能力,20個H100 GPU便可承托相當(dāng)于全球互聯(lián)網(wǎng)的流量。相比于A100,H100在FP16、FP32和FP64計算上快三倍,非常適用于當(dāng)下流行且訓(xùn)練難度高的大模型。
由于全球眾多科技企業(yè)加入大語言模型研究大軍,近段時間,英偉達(dá)的GPU供貨周期拉長,價格上漲,其A100 GPU市場單價兩個月前還在10萬元左右,如今已經(jīng)上漲到15萬元。
目前大部分研究都認(rèn)為,AI大模型預(yù)訓(xùn)練是一個非常耗時、耗力、耗電的過程,這部分對GPU的貢獻(xiàn)最大。然而實際上,如果真正地去計算成本,對于企業(yè)來說,大模型的推理將會耗費巨大的成本,而其中很大部分則是在GPU的購買上。

圖:沐曦研究科學(xué)家李兆石演講(電子發(fā)燒友拍攝)
在近日某人工智能論壇上,沐曦研究科學(xué)家李兆石介紹,以谷歌為例,谷歌目前主要的收入來源是搜索廣告,每次搜索平均能夠給谷歌帶來約1.6美分。
如果把類似ChatGPT插入到谷歌搜索里,在現(xiàn)在主流高性能的英偉達(dá)A100 GPU上,需要八張GPU才能做一次GPT3的推理,把電費和GPU的一次性購買成本算進(jìn)去,每次推理的平均成本大約是0.36美分,如果谷歌直接在谷歌搜索里用類似ChatGPT規(guī)模的大模型,相當(dāng)于很大一部分利潤都將耗費在大模型的推理成本上。
相當(dāng)于在A100上做GPT3規(guī)模的預(yù)訓(xùn)練,大概需要80萬美元。而把剛才0.36美分乘以谷歌每天的搜索次數(shù),可以發(fā)現(xiàn),直接在谷歌搜索里用這個GPT推理,這個推理成本每天是1億美元,推理成本遠(yuǎn)遠(yuǎn)高于預(yù)訓(xùn)練成本。
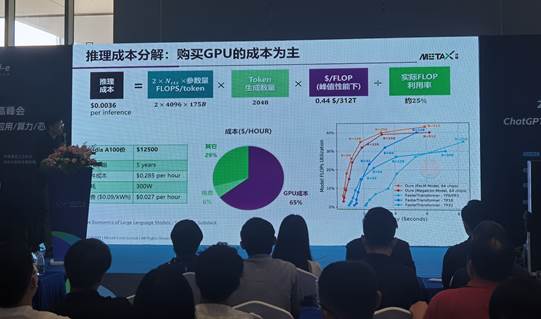
將這個推理成本再進(jìn)一步拆解,會發(fā)現(xiàn),以英偉達(dá)A100 GPU的市場價格12500美元計算(這是之前的價格,現(xiàn)在國內(nèi)價格基本上已經(jīng)漲到15到20萬人民幣),一般GPU的使用年限是五年,把這個購買成本線性平攤到五年時間,這個0.36美分的每次推理成本里面,65%是購買GPU的成本。也就是說GPU的一次性購買成本,占大模型訓(xùn)練和推理的絕大部分。
國內(nèi)AI算力芯片廠商的產(chǎn)品和技術(shù)進(jìn)展
可以看到,雖然目前大語言模型的訓(xùn)練基本依賴英偉達(dá)的GPU,然而隨著大模型逐漸走向落地應(yīng)用,在推理側(cè),國內(nèi)外AI算力芯片廠商將迎來較大的市場機會。
在國內(nèi),近些年已經(jīng)有不少廠商在高性能計算AI算力芯片領(lǐng)域取得進(jìn)展,包括寒武紀(jì)、海光信息、壁仞科技、摩爾線程、天數(shù)智芯、燧原科技、沐曦集成、芯動科技、登臨科技等。
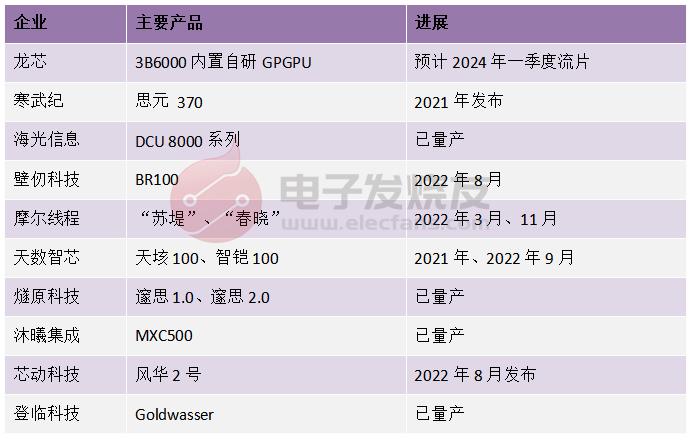
電子發(fā)燒友制表
如今CPU廠商龍芯也加入到了GPGPU大軍中,不過可以看到龍芯的GPGPU主要還是集成在自家的SOC中。事實上,龍芯早在2017年就開始研究GPU,2021年7月,該公司發(fā)布的龍芯3號系列處理器的配套橋片“龍芯7A2000”,內(nèi)部就首次集成了龍芯自研的GPU。
如今龍芯又透露了其在GPGPU方面的最新進(jìn)展。據(jù)胡偉武介紹,2024 年龍芯將流片首款大小核協(xié)同芯片。龍芯 3A6000 的下一代將是 3B6000,四大四小八個核,內(nèi)置自研 GPGPU。大核爭取通過結(jié)構(gòu)優(yōu)化再提高性能 20% 以上。
寒武紀(jì)是一家專注于人工智能芯片研發(fā)和技術(shù)創(chuàng)新的企業(yè),能夠為視覺、語音、自然語言處理、傳統(tǒng)機器學(xué)習(xí)等人工智能技術(shù)提供基礎(chǔ)計算平臺。2021年7月,寒武紀(jì)發(fā)布了其第三代云端 AI 芯片思元 370,以及基于思元 370 的兩款加速卡 MLU370-S4 和 MLU370-X4。
同時,寒武紀(jì)全新升級了 Cambricon Neuware 軟件棧,新增推理加速引擎 MagicMind,實現(xiàn)訓(xùn)推一體,顯著提升了開發(fā)部署的效率。而且,有 7nm 先進(jìn)工藝和全新 MLUarch03 架構(gòu)加持,思元 370 芯片算力最高可達(dá) 256TOPS (INT8),是上一代產(chǎn)品思元 270 算力的 2 倍。
海光信息的產(chǎn)品包括通用處理器(CPU)和協(xié)處理器(DCU),海光DCU屬于GPGPU的一種。海光DCU 8000系列,支持INT4、INT8、FP16、FP32、FP64運算精度,支持4個HBM2內(nèi)存通道,最高內(nèi)存帶寬為1TB/s、最大內(nèi)存容量為32GB。
海光DCU協(xié)處理器全面兼容ROCm GPU計算生態(tài),由于ROCm和CUDA在生態(tài)、編程環(huán)境等方面具有高度的相似性,CUDA用戶可以以較低代價快速遷移至ROCm平臺。
壁仞科技去年8月發(fā)布了首款通用GPU BR100,集成770億晶體管,其INT8算力達(dá)2048 TOPS,BF16算力達(dá)1024 TFLOPS,TF32+算力達(dá)512 TFLOPS,F(xiàn)P32算力達(dá)256 TFLOPS。同期,壁仞科技還發(fā)布了自主原創(chuàng)架構(gòu)——壁立仞、創(chuàng)造全球性能紀(jì)錄的OAM服務(wù)器——海玄,以及OAM模組——壁礪100,PCIe板卡產(chǎn)品——壁礪104,以及自主研發(fā)的BIRENSUPA軟件平臺。
摩爾線程已經(jīng)發(fā)布兩款自主研發(fā)的GPU芯片產(chǎn)品,去年3月發(fā)布GPU產(chǎn)品“蘇堤”,11月又發(fā)布了第二款GPU芯片“春曉”。“春曉”內(nèi)置MUSA架構(gòu)通用計算核心以及張量計算核心,可支持FP32、FP16和INT8三種計算精度;相較于其首款自研的GPU“蘇堤”,“春曉”內(nèi)置的四大計算引擎都進(jìn)行了全面升級,性能顯著提升,AI計算加速平均提升4倍。
天數(shù)智芯于2018年正式啟動通用GPU芯片設(shè)計,在2021年發(fā)布了其通用GPU“天垓100”芯片及天垓100加速卡,2021年10月宣布天垓100正式進(jìn)入量產(chǎn)環(huán)節(jié)。2022年9月,天數(shù)智芯又發(fā)布了首款7nm制程的云端推理通用GPU產(chǎn)品“智鎧100”。
智鎧 100 芯片支持 FP32、FP16、INT8 等多精度混合計算,實現(xiàn)了指令集增強、算力密度提升、計算存儲再平衡,支持多種視頻規(guī)格解碼。
燧原科技已經(jīng)迭代了兩代訓(xùn)練和推理產(chǎn)品,第三代也已經(jīng)在研發(fā)中。燧原科技已經(jīng)在科研領(lǐng)域和智慧城市的應(yīng)用中落地了訓(xùn)練和推理的超千卡算力集群。
該公司創(chuàng)始人兼COO張亞林此前在接受電子發(fā)燒友采訪的時候表示,類似ChatGPT這樣的AIGC生成式模型,對于燧原科技而言是個機遇,公司可以把已經(jīng)積累的系統(tǒng)集群的經(jīng)驗推廣到更多的客戶賽道上,幫助客戶使能更多大模型的生成。
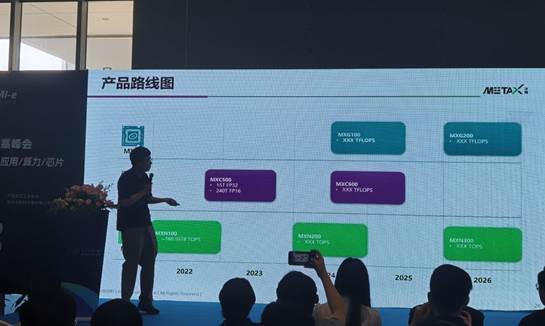
沐曦集成產(chǎn)品路線圖
沐曦集成目前有三條產(chǎn)品線規(guī)劃,G系列、C系列和N系列,G系列主要是用于圖形處理領(lǐng)域,C系列主要用于高性能云端的訓(xùn)練和推理,N系列主要是云端的推理芯片。現(xiàn)在N系列的云端推理芯片已經(jīng)量產(chǎn)出貨,C系列正在做調(diào)試,如果沒有問題的話,也很快就會量產(chǎn)。
芯動科技已經(jīng)發(fā)布兩款GPU芯片——風(fēng)華1號和風(fēng)華2號。風(fēng)華1號于2021年發(fā)布,于去年9月正式量產(chǎn)。風(fēng)華2號于2022年8月發(fā)布,是一款集超低功耗、強渲染、4K高清三屏顯示、及智能AI計算于一體的桌面和筆記本GPU。
風(fēng)華2號在AI計算能力方面,支持科學(xué)/邊緣計算,AI性能超過12.5TOPS,支持人臉識別、目標(biāo)識別、語義分割、圖像超分辨率等多種場景實時應(yīng)用。
登臨科技是一家專注于高性能通用計算平臺的芯片研發(fā)與技術(shù)創(chuàng)新的公司,其自主研發(fā)的GPU+架構(gòu)正式采用了軟件定義的片內(nèi)異構(gòu)體系,目前首款基于GPU+的系列產(chǎn)品—Goldwasser已在云至邊緣的各個應(yīng)用場景實現(xiàn)規(guī)模化落地。
登臨科技聯(lián)合創(chuàng)始人王平此前在接受電子發(fā)燒友采訪的時候表示,登臨科技希望通過異構(gòu),從由點及面在一些足夠大的市場領(lǐng)域,把產(chǎn)品做到比英偉達(dá)同系列產(chǎn)品更具性價比優(yōu)勢,甚至超過英偉達(dá)。
帶著這樣的出發(fā)點,在大型語言模型方面,登臨科技會更關(guān)心如何更好的提升產(chǎn)品的能效比。簡單來說,在同樣功耗下,登臨科技可以提供英偉達(dá)1.5到2倍的算力,在算力一致的情況下,做到單位功耗更低。這樣從計算的整體性能上,實現(xiàn)英偉達(dá)同類產(chǎn)品的能效比3倍的優(yōu)勢。如此一來,可以極大地節(jié)省電費及運維成本。
小結(jié)
很顯然,隨著ChatGPT的出圈,國內(nèi)外眾多科技企業(yè)掀起大語言模型的研究熱潮,而無論是大模型的訓(xùn)練還是部署,都離不開GPGPU芯片提供算力支持。目前而言,大模型的訓(xùn)練基本依賴英偉達(dá)的GPU,然而相比較而言,隨著大模型逐步落地應(yīng)用,在推理部分將同樣需要用到大量GPGPU,而這也是除英偉達(dá)之外,國內(nèi)外眾多GPGPU廠商的機會。
-
龍芯
+關(guān)注
關(guān)注
3文章
429瀏覽量
32785 -
GPGPU
+關(guān)注
關(guān)注
0文章
33瀏覽量
5504
發(fā)布評論請先 登錄
國產(chǎn)GPGPU集體爆發(fā)!沐曦登陸科創(chuàng)板,龍芯也宣布了

龍芯中科與宏杉科技完成產(chǎn)品適配互認(rèn)證

龍芯中科與凝思軟件達(dá)成戰(zhàn)略合作

中科曙光攜手中威科技助力南通人社AI客服落地
櫟新源與龍芯中科簽署戰(zhàn)略合作協(xié)議,國產(chǎn)超聲波掃描顯微鏡全面應(yīng)用龍芯底層產(chǎn)品

龍芯中科亮相2025數(shù)字孿生水利創(chuàng)新發(fā)展論壇
龍芯中科與中國核建達(dá)成全面戰(zhàn)略合作
喜訊 | 眺望電子2K3000工控系列入選龍芯中科伙伴產(chǎn)品

龍芯中科與文心系列模型開展深度技術(shù)合作
中科馭數(shù)亮相2025龍芯產(chǎn)品發(fā)布暨用戶大會
龍芯中科與研祥智能發(fā)布全新態(tài)勢感知專用設(shè)備
龍芯處理器支持WINDOWS嗎?
高端芯片自研,服務(wù)器芯片傳來好消息!
信創(chuàng)浪潮下,國產(chǎn)主板有什么新的發(fā)展機遇?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論