 GPU競爭壁壘:微架構和平臺生態
GPU競爭壁壘:微架構和平臺生態

據Global Market Insights 數據,全球 GPU 市場預計將以 CAGR 25.9%持續增長,至 2030 年達到 4000 億美元規模。其中 AI 領域大語言模型的持續推出以及參數量的不斷增長有望驅動模型訓練端、推理端 GPU 需求快速增長。
近年來,國產 GPU 廠商在圖形渲染 GPU 和高性能計算 GPGPU 領域上均推出了較為成熟的產品,在性能上不斷追趕行業主流產品,在特定領域達到業界一流水平。生態方面國產廠商大多兼容英偉達 CUDA,融入大生態進而實現客戶端不斷導入。在高端GPU 芯片進口受限的背景下,國產 GPU 廠商預計將乘政策東風,抓住國產替代契機快速成長。
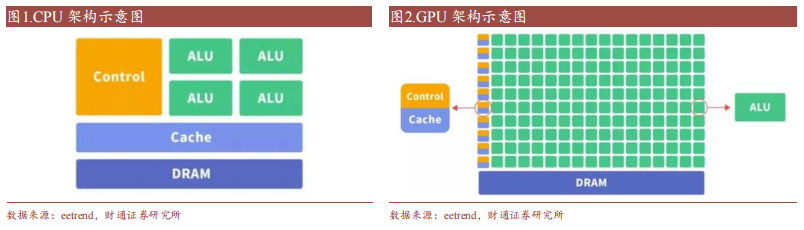
GPU(圖形處理器)最初是為了解決 CPU 在圖形處理領域性能不足的問題而誕生。CPU 作為核心控制計算單元,高速緩沖存儲器(Cache)、控制單元(Control)在 CPU 硬件架構設計中所占比例較大,主要為實現低延遲和處理單位內核性能要求較高的工作而存在,而計算單元(ALU)所占比例較小,這使得 CPU 的大規模并行計算表現不佳。GPU 架構內主要為計算單元,采用極簡的流水線進行設計,適合處理高度線程化、相對簡單的并行計算,在圖像渲染等涉及大量重復運算的領域擁有更強運算能力。 GPGPU脫胎于GPU,通用性提升

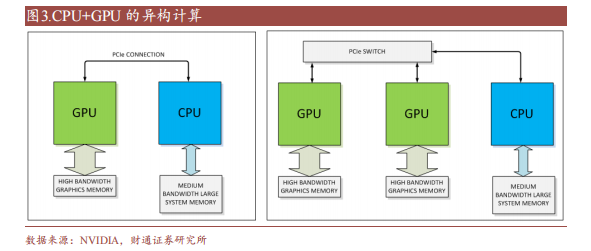
CPU+GPU 異構計算解決多元化計算需求
大語言模型開啟 AI 元年
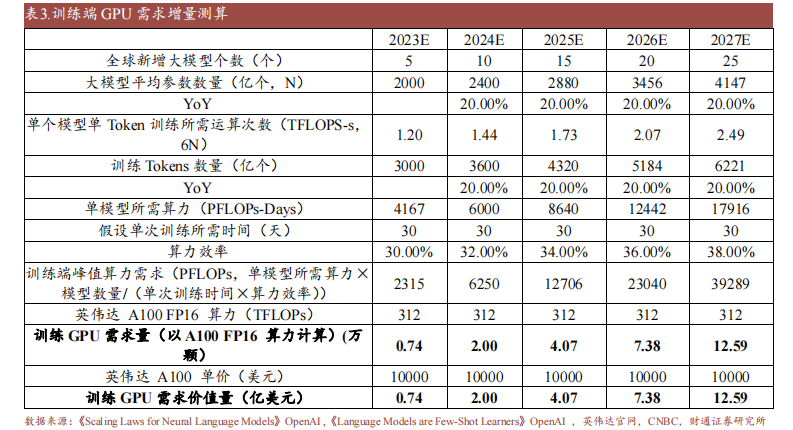
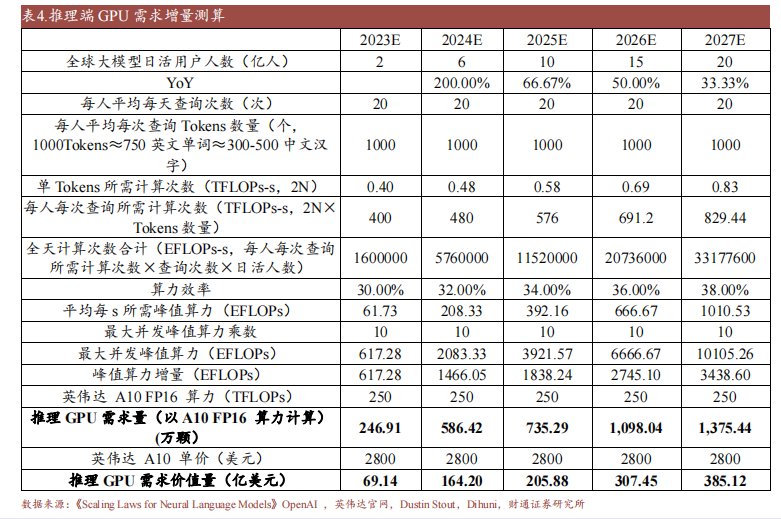
大語言模型有望拉動 GPU 需求增量
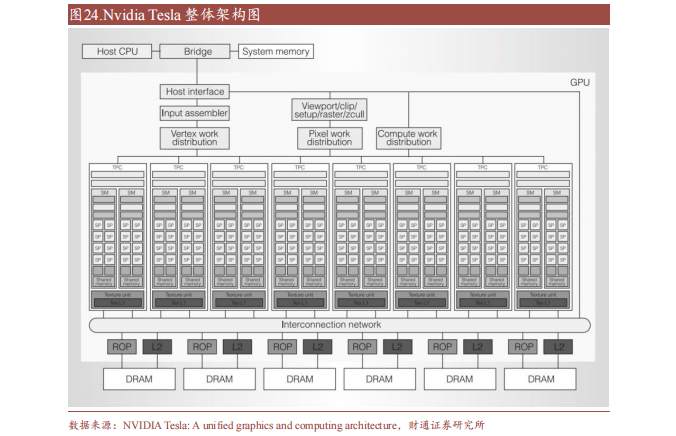
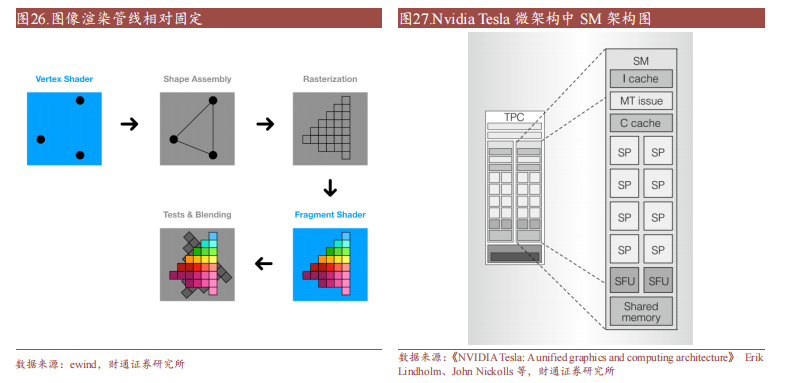
GPU 的微架構是用以實現指令執行的硬件電路結構設計 以 Nvidia 第一個實現統一著色器模型的 Tesla 微架構為例,從頂層 Host Interface 接受來自 CPU 的數據,藉由 Vertex(頂點)、Pixel(片元)、Compute(計算著色器)分發給各 TPC(Texture Processing Clusters 紋理處理集群)進行處理。
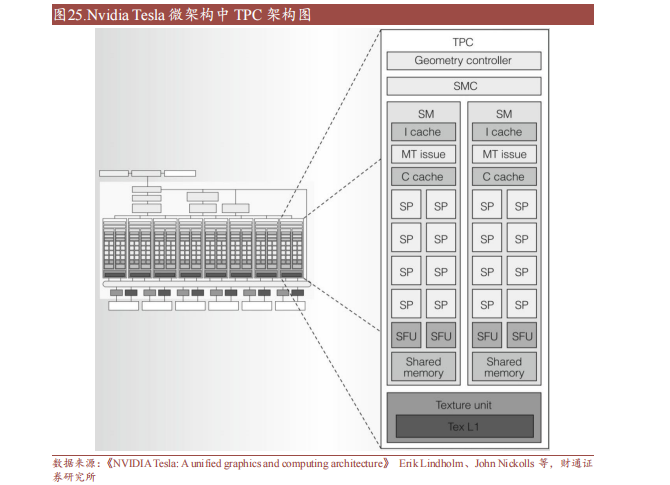
流處理器、特殊函數計算單元構成計算核心 在單個 TPC 中主要的運算結構為SM(Streaming Multiprocessor 流式多處理器),其內在蘊含 I Cache(指令緩存)、C Cache(常量緩存)以及核心的計算單元 SP(Streaming Processor 流處理器)和 SFU(Special Function Unit 特殊函數計算單元),外加 Texture Unit(紋理單元)。
解耦計算單元,擁抱通用計算 由于圖形渲染流管線相對固定,Nvidia 在 Tesla構中將部分重要環節剝離并實現可編程,解耦出 SM 計算單元用于通用計算,即可實現根據具體任務需要分配相應線程實現通用計算處理。
計算核心、紋理單元增加, GPC 功能更加完整,Nvidia Fermi 架構奠定完整GPU 計算架構基礎。
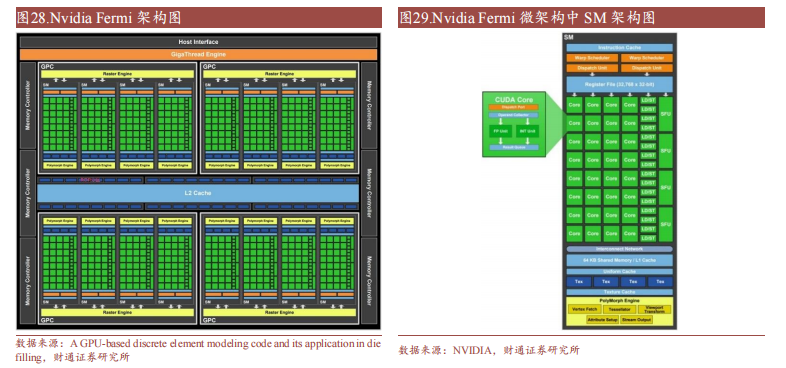
在Tesla 之后,Nvidia 第一個完整的 GPU 計算架構 Fermi通過制程微縮增加更多計算核心、紋理單元,并且通過增加 PolyMorph Engine(多形體引擎)和 Raster Engine(光柵引擎)使得原來 TPC 升級成為擁有更加完整功能的 GPC(Graphics Processing Clusters 圖形處理器集群)。Fermi 架構共包含 4 個 GPC,16 個 SM,512 個CUDA Core。
英偉達GPU從最初 Fermi 架構到最新的 Ampere 架構和 Hopper 架構
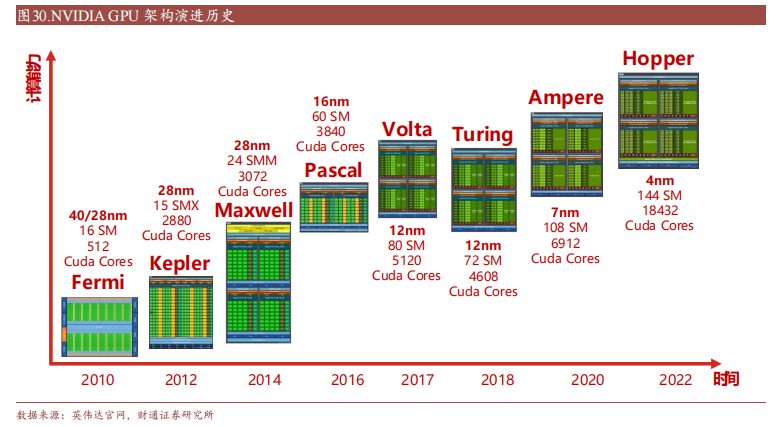
每一階段都在性能和能效比方面得到提升,引入了新技術,如 CUDA、GPUBoost、RT 核心和 Tensor 核心等,在圖形渲染、科學計算和深度學習等領域發揮重要作用。最新一代 Hopper 架構在 2022 年 3 月推出,旨在加速 AI 模型訓練,使用 Hopper Tensor Core 進行 FP8 和 FP16 的混合精度計算,以大幅加速Transformer 模型的 AI 計算。與上一代相比,Hopper 還將 TF32、FP64、FP16 和INT8 精度的每秒浮點運算(FLOPS)提高了 3 倍。
AMD 作為全球第二大GPU廠商,亦通過持續的架構演進保持其市場領先地位
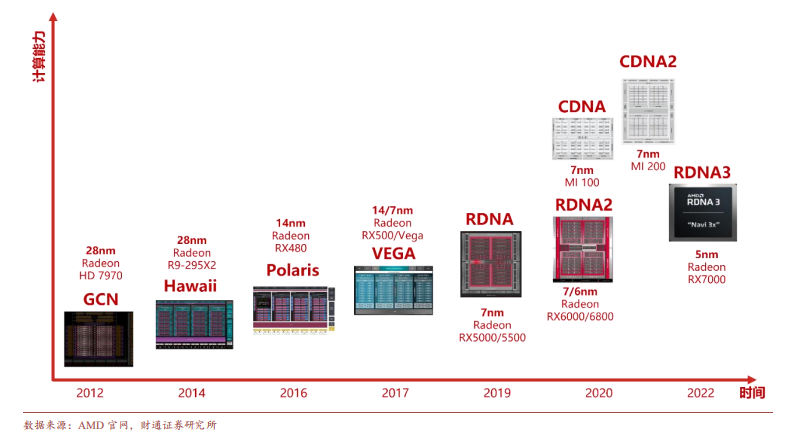
從2010年以來,AMD 相繼推出:GCN 架構、RDNA 架構、RDNA 2 架構、RDNA 3 架構、CDNA 架構和 CDNA 2 架構。最新一代面向高性能計算和人工智能 CDNA 2 架構于架構采用增強型 Matrix Core 技術,支持更廣泛的數據型和應用,針對高性能計算工作負載帶來全速率雙精度和全新 FP64 矩陣運算。基于 CDNA2 架構的 AMD Instinct MI250X GPU FP64 雙精度運算算力最高可達 95.7 TFLOPs。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
5194瀏覽量
135441 -
微架構
+關注
關注
0文章
22瀏覽量
7332
原文標題:GPU競爭壁壘:微架構和平臺生態
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
HarmonyOS首登微信公開課,分享跨平臺適配與體驗提升實踐經驗

景嘉微JM1100生態合作推介會深圳站成功舉辦
打破智能家居生態壁壘,樂鑫一站式Matter解決方案實現無縫互聯

瑞芯微這幾年為啥那么火?
景嘉微JM1100生態合作推介會北京站圓滿落幕
如何看懂GPU架構?一分鐘帶你了解GPU參數指標

景嘉微JM1100生態合作推介會長沙站圓滿結束
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
從封閉到開放:聚徽解碼安卓工控機如何打破工業軟件生態壁壘
GPU架構深度解析



 工商網監
工商網監
評論