 Linux入門之正則表達式
Linux入門之正則表達式

正則表達式是用來表達字符串匹配模式的方法,利用正則表達式,可以讓我們輕易地實現對目標字符串的 查找 、 刪除 、替換等操作。
正則表達式并不復雜,它并不包含難以理解的理論,只是一些約定好的匹配規則,但由于規則較多,可能比較容易忘記。
本文會先整理出所有的正則表達式以及其含義,接下來會利用grep命令,詳細介紹每種正則表達式的使用方式,并給出案例。
如果大家忘記了某個匹配規則的話,相信你只要再看一遍下方整理好的表格,就能回憶起其使用方法。
正則表達式規則
下方表格整理了常用正則表達式的匹配規則:
| 表達式 | 含義 |
|---|---|
| ^word | 匹配關鍵字出現在行首的行下面命令查詢以Hello開頭的行grep ^Hello regular.txt |
| word** | 匹配關鍵字出現在行尾的行下面命令查詢以 complete 結尾的行grep complete**regular.txt |
| . | 一定存在某個字符例如a.c可以匹配abc,acc,adc,aec等字符串 |
| \\ | 轉義符,去掉特殊符號的特殊含義下面的命令查找含有單引號'的行grep \\' regular.txt |
| * | 匹配0個或無窮多個前面的表達式下面命令查找es,ess,esss,esss...等字符串grep ess* regular.txt |
| [list] | 匹配中括號中的一個字符例如,t[ae]st既能匹配test,也能匹配tast |
| [n1-n2] | 是[list]的簡寫形式,匹配兩個字符之間的所有連續字符例如,[A-Z]匹配所有的大寫字符,[0-9]匹配0和9之間的任意一個數字 |
| [^list]或[^n1-n2] | 中括號中的^是取反的意思,它表示只要一行包含有非list中列出的任意字符,就會被匹配例如,下面命令查找包含有非大寫字符的行grep [^A-Z] regular.txt |
| {n} | 匹配n個前面的表達式 |
| {n, m} | 匹配連續n到m個前面的表達式 |
| {n,} | 匹配連續n個或以上個前面的表達式 |
下面將使用grep命令演示各個表達式的執行效果,測試使用的regular.txt文件內容如下圖所示:
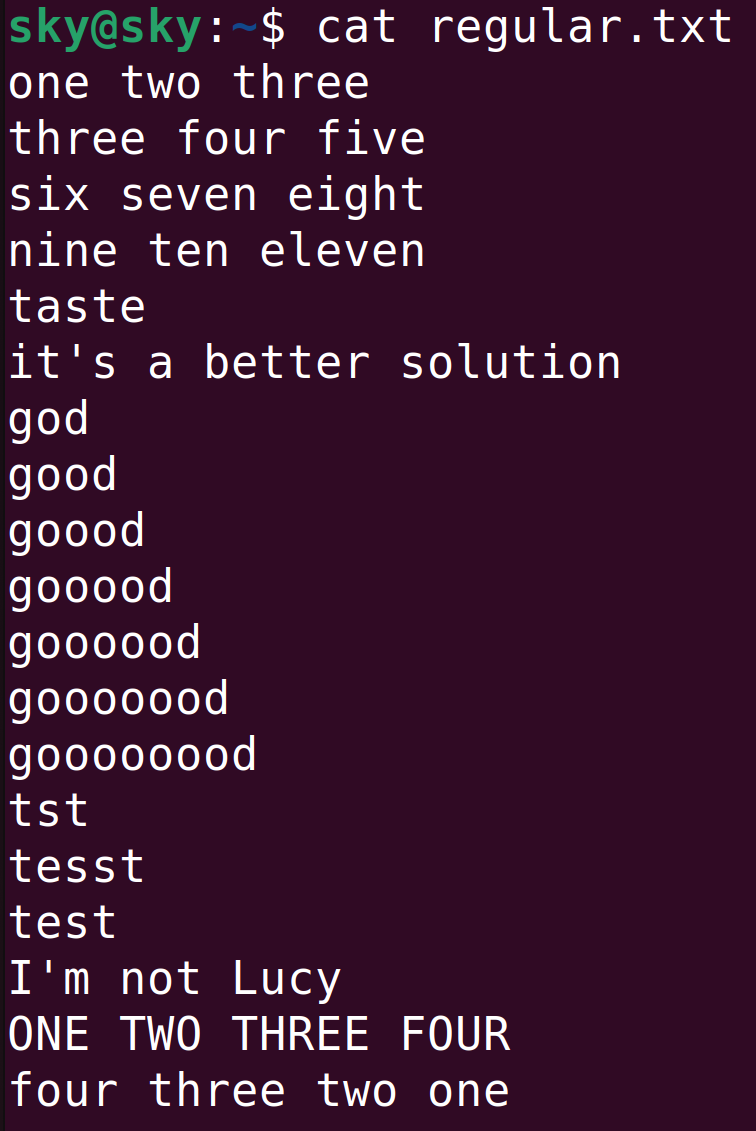
^word
grep one regular.txt命令的執行結果如下所示:
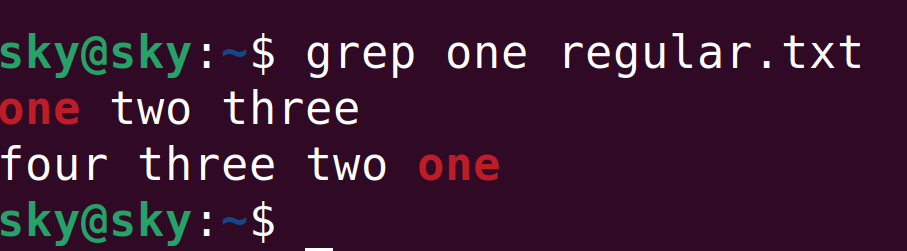
默認條件下,grep命令會把包含“one”的行都檢索出來。但如果你只想檢索以“one”開頭的行,要使用如下命令:
grep ^one regular.txt
其執行結果如下圖所示:

可以看到只有以“one”開頭的行被檢索出來了,那種雖然包含“one”,但并不以“one”開頭的行不會被檢索到。
word$
$表示只查詢以某個關鍵字結尾的行:
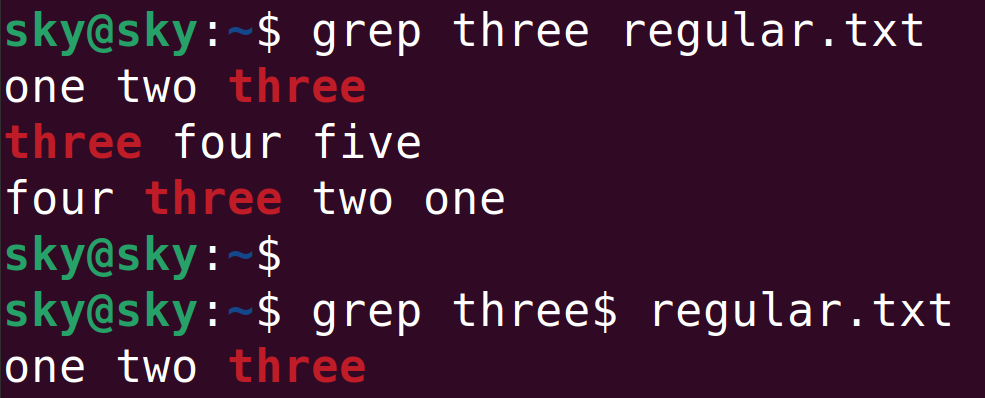
默認條件下,grep命令會把包含“three”的行都檢索出來。但使用$后,只有以“three”結尾的行會被檢索到。
小數點 .
.表示一定匹配且僅匹配一個字符。在regular.txt文件中,包含下面幾行:
taste
tst
tesst
test
但執行grep t.st regular.txt命令時,只有taste和test兩行內容會被檢索出來:
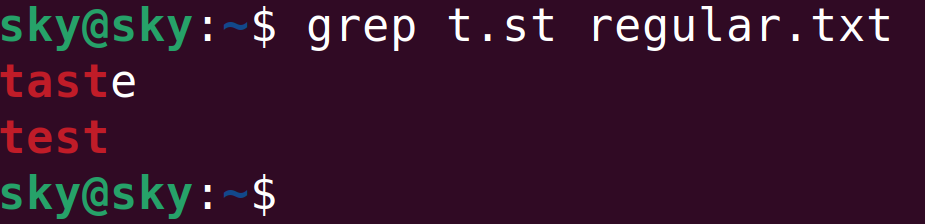
這是因為.一定匹配一個任意字符,所以只有taste和test兩行內容滿足要求。
星號 *
*表示重復任意次前面的表達式,包括0次和無窮次。
grep go* regular.txt命令執行結果如下:
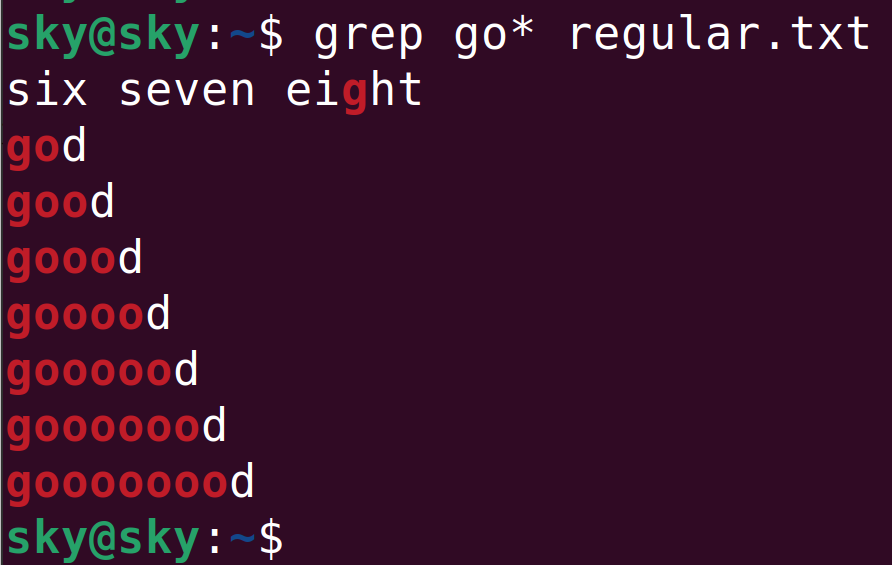
g、go、goo、goo...等字符串都會被檢索到。
[list]
匹配中括號中的任意一個字符,注意“[]”表達式只表示一個字符,中括號內的字符之間是“或”的關系。
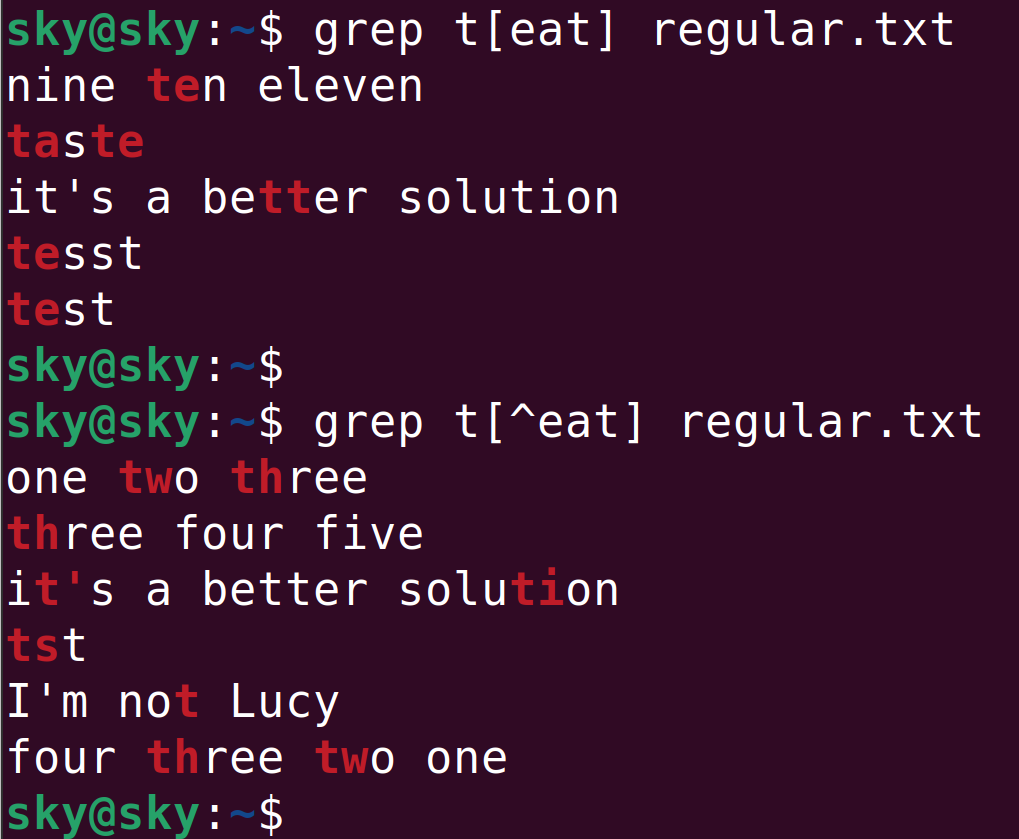
grep t[ea] regular.txt命令執行結果如下:

tst字符串就沒有被檢索到,因為s不在[ea]范圍內。
[n1-n2]
這是對[list]的簡寫形式,在處理連續字符集時很有效。
例如,想要列出所有的小寫字母,你可以用“[abcdefg...xyz]”來表達,但這樣輸入太多,比較麻煩。
由于小寫字母是連續的,所以可以用[a-z]表示所有的小寫字母。
grep t[a-z] regular.txt執行結果如下所示:

同理,[A-Z]表示所有大寫字母,[0-9]表示所有數字。
[^list] 或 [^n1-n2]
當^出現在中括號內時,它表達“取反”的含義。
下面是[list]形式使用^符號的前后結果對比:
下面是[n1-n2]形式使用'^'符號的前后結果對比:

, ,
這三種表達式本質上是一類表達式,都是表示前面表達式重復的次數。
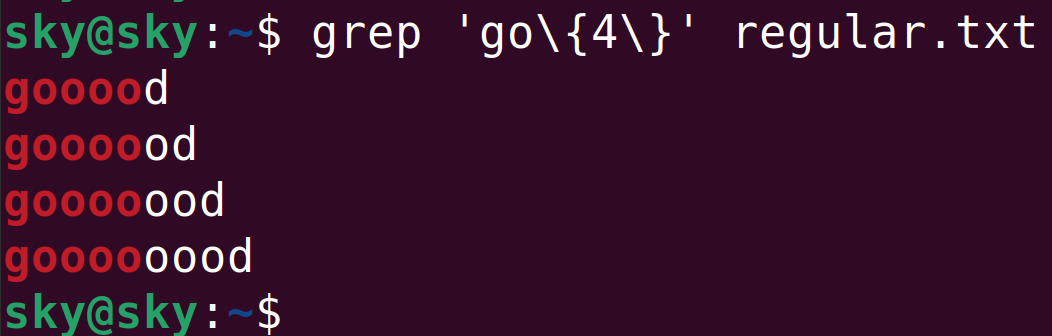
go\\{4\\}表示字母g后面必須跟著4個字母o:
go\\{4,6\\}表示字母g后面跟著4個字母o到6個字母o的字符串都是匹配的:

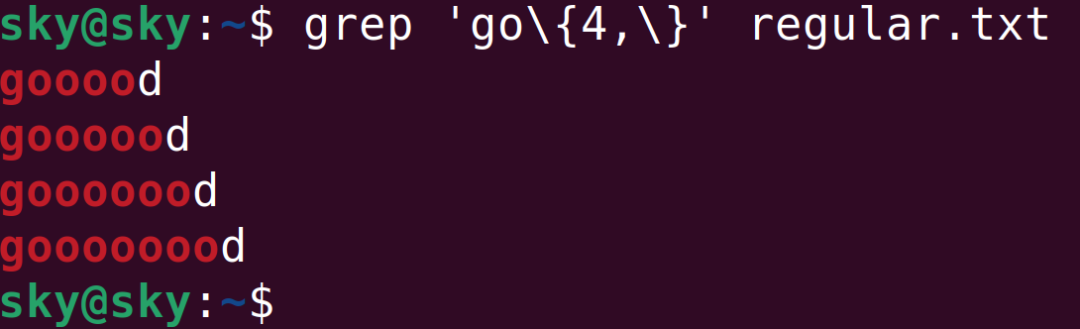
go\\{4,\\}表示字母g后面跟著4個字母o或超過4個字母o的字符串都是匹配的:
這里要注意,grep在使用\\{n,m\\}表達式時,表達式內容必須用單引號'或雙引號"擴起來。其它情況可以不使用雙引號或單引號。
反斜杠 \\
\\是轉義字符,當你要檢索某些特殊字符時,就需要使用它。
例如,下面檢索包含單引號的行:
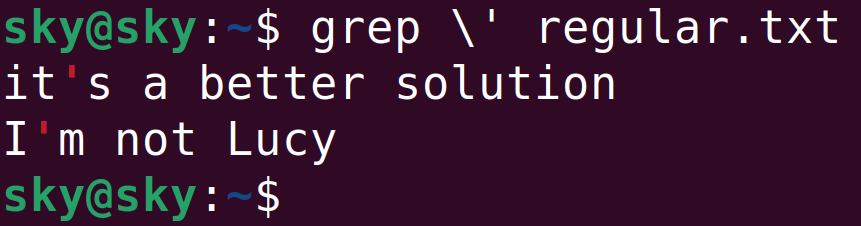
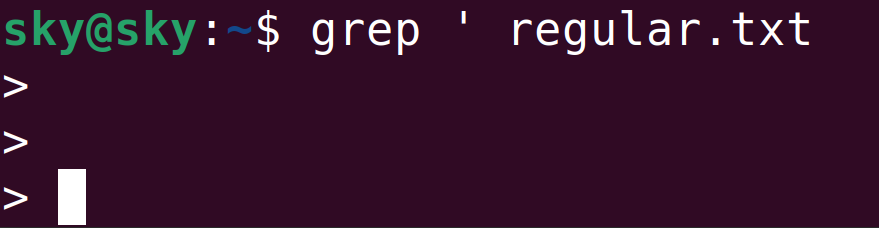
這里如果不使用\\,將無法正常執行命令:
—————END—————

技術人江湖互聯網技術分享,Elasticsearch系列教程
67篇原創內容
公眾號
收錄于合集 **#**linux
12個
上一篇Linux必知必會10:環境變量設置方式及原理
-
Linux
+關注
關注
88文章
11797瀏覽量
219387 -
字符串
+關注
關注
1文章
596瀏覽量
23204 -
正則表達式
+關注
關注
0文章
28瀏覽量
3869
發布評論請先 登錄
什么是正則表達式?正則表達式如何工作?哪些語法規則適用正則表達式?
shell正則表達式學習
深入淺出boost正則表達式
關于java正則表達式的用法詳解
快速入門IPv6和正則表達式

Python正則表達式的學習指南

Python正則表達式指南
python正則表達式中的常用函數
shell腳本基礎:正則表達式grep




 工商網監
工商網監
評論