 ChatGPT大模型,引領海內外巨頭競品發布
ChatGPT大模型,引領海內外巨頭競品發布

大模型運行成本高昂,準入壁壘較高。大模型對于訓練時間和參數量都有高要求,以 OpenAICEO Altman 在推特上回復馬斯克的留言可知,ChatGPT 平均一次聊天成本為幾美分。根據Similar Web 數據,2023 年1月 27 日至 2 月 3 日 ChatGPT 日活躍用戶達 2500 萬人。中性假設下,以平均單人單日對話 7 次,每次 3 美分成本進行測算,對應一年支出對話成本約為19.2 億美元。根據英偉達官網,A100 作為 DGX A100 系統的一部分進行銷售,該系統搭載 8個 A100 GPU,一個由 5 臺 DGX A100 系統組成的機架可替代一個包括 AI 訓練和推理基礎設施的數據中心,且功耗僅為其 1/20,成本為其 1/10,系統售價 19.9 萬美元。因此,在中性假設條件下,考慮到服務器約占數據中心成本的 70%(中商產業研究院),則 ChatGPT 運營一年將需要 6741 個 DGX A100 系統用于支撐訪問量。
ChatGPT帶動大模型競品發布,海內外科技巨頭先后加碼AI布局。
1)谷歌向AI公司Anthropic投資近 4 億美元,后者正在測試生成式 AI 工具 Claude,且谷歌也推出對標 ChatGPT 的聊天機器人 Bard。
2)微軟以 100 億美元投資 ChatGPT 的開發商 OpenAI,并獲得其 49%股權。2023年 2 月,微軟發布基于 ChatGPT 的 new Bing。
3)亞馬遜云服務 AWS 宣布與 AI 公司 HuggingFace 開展合作,Hugging Face 將在 AWS 上開發針對 ChatGPT 的開源競品,構建開源語言模型的下個版本 Bloom。
4)阿里達摩院正研發類 ChatGPT 的對話機器人,目前已處于內測階段。
5)百度開發類 ChatGPT 項目“文心一言”(ERINE Bot)。
6)京東推出產業版 ChatJD。
基于昆侖芯+飛槳+文心大模型 AI 底座,百度推出“文心一言”拉開國產生成式 AI 序幕。2023年 3 月 16 日,百度正式推出國內首款生成式 AI 產品“文心一言”,可支持文學創作、文案創作、數理推算、多模態生成等功能,目前已有多家廠商宣布接入。“文心一言”基于全棧自研的 AI 基礎設施進行學習和訓練:
? 昆侖芯 2 代 AI 芯片:“文心一言”的芯片層核心能力,采用自研 XPU-R 架構,通用性和性能顯著提升;256 TOPS@INT8 和 128 TFLOPS@FP16 的算力水平,較一代提升 2-3 倍,保障“文心一言”算力需求;采用 7nm 先進工藝,GDDR6 高速顯存,支持虛擬化,芯片間互聯和視頻編解碼等功能。
? 飛槳深度學習平臺:“文心一言”的框架層核心能力,系業內首個動靜統一的框架、首個通用異構參數服務器架構,支持端邊云多硬件和多操作系統,為文心大模型提供有效、快捷、完整的訓練框架。
? 文心知識增強大模型:“文心一言”的模型層核心能力,該產品主要采用 ERNIE 系列文心NLP 模型,擁有千億參數級別的 ERNIE 3.0 Zeus 為該系列最新模型,進一步提升了模型對于不同下游任務的建模能力,大大拓寬了“文心一言”的應用場景。
以 GPT-3 為例測算:大算力需求驅動 AI 硬件市場空間提升
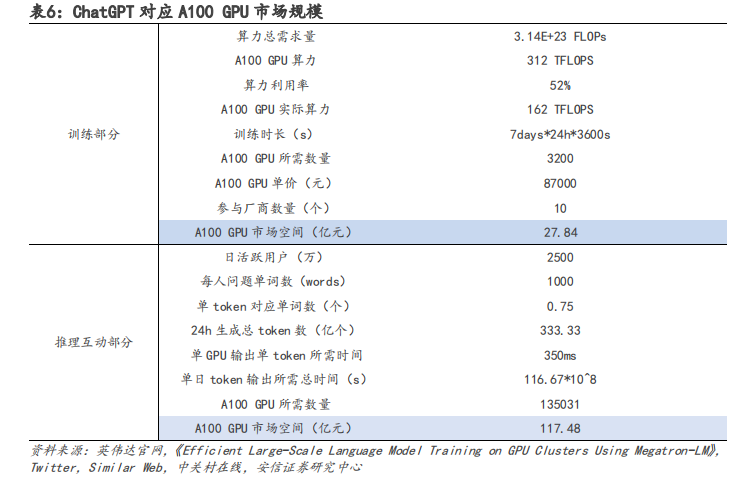
GPT-3(Generative Pre-trained Transformer 是 GPT-3.5 的上一代語言模型,目前一般所說的 GPT-3 即為擁有 1750 億參數的最大 GPT-3 模型,OpenAI 在公開發表的論文《Language Models are Few-Shot Learners》中對 GPT-3 模型進行了詳細分析。對于以 ChatGPT 為例的大模型算力需求,根據測算,我們預計用于高端 GPGPU 顯卡的訓練及推理部分市場空間合計約 145.32 億元,其中訓練市場規模為 27.84 億元,推理市場規模為 117.48 億元。
英偉達引領硬件端產品升級,國產 GPU 靜待花開
大 GPU 優勢在于通過并行計算實現大量重復性計算。GPGPU(General Purpose GPU)即通用GPU,能夠幫助 CPU 進行非圖形相關程序的運算。在類似的價格和功率范圍內,GPU 能提供比CPU 高得多的指令吞吐量和內存帶寬。
GPT-4 模型算力需求擴增,架構升級降本增效未來可期
根據 OpenAI 官網顯示,目前 GPT-4 每 4 小時只能處理 100 條消息,且并沒有開放圖片識別功能。大模型升級帶來的運算需求逐漸加碼,且可推測目前算力已處于供不應求狀態。
多模態拓展,圖片識別算力需求升級十倍以上。關于從圖片到 token 的轉換方式,OpenAI 未公布 GPT-4 的模型參數,假設 GPT-4 處理圖片視覺任務使用 VisionTransformer 模型(ViT),則輸入圖片尺寸必須為 224×224(ViT-B/16 版本)。根據 2021 年 ICLR 論文,模型原理大致為把一張圖片分成 nxn 個 Patch,每一個 Patch 作為一個 Token。即把一張 224×224×3 的圖片,切分為 16×16 大小的 Patch,每個 Patch 是三通道小圖片,得到 16×16×3=768 個 token并作為向量輸入。相較之下,根據前文 GPT-3 部分假設,假設每個文字問題 50-100 詞,即67-133token。我們可以粗略推論,圖像識別的所需算力是文字推理部分所需算力的十倍以上級別。
審核編輯 :李倩
-
AI芯片
+關注
關注
17文章
2128瀏覽量
36780 -
聊天機器人
+關注
關注
0文章
348瀏覽量
13092 -
ChatGPT
+關注
關注
31文章
1598瀏覽量
10269
原文標題:ChatGPT大模型,引領海內外巨頭競品發布
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
東風汽車海內外齊發力不斷斬獲新訂單
0.7元/百萬token碾壓競品! 小米新開源大模型,卷出AI普惠關鍵密碼

告別冰冷的監控,迎來「懂你」的AI智能伙伴!神眸大模型的全新進化

芯干線亮相2025中國電源學會學術年會
挑戰低功耗極限!杭州研極微發布「研極芯Gen2」以業界1/10功耗樹立續航新標桿

如何精準驅動菜品識別模型--基于米爾瑞芯微RK3576邊緣計算盒
亞馬遜 SP-API 深度開發:關鍵字搜索接口的購物意圖挖掘與合規競品分析
淘寶API實時競品監控,市場策略快人一步!
拼多多API價格戰預警,競品監控不落人后!
拼多多電商 API 接口:競品分析的絕佳工具!

2024年蘑菇車聯斬獲多項海內外重量級榮譽
ISO 11452-8 標準下,AS5x47y 如何破解競品傳感器的磁場 “弱點”?

晶科鑫2025慕尼黑上海電子展圓滿落幕

圓滿收官 | 凌科2025深圳低空展閉幕,原創方案產品備受關注

展會首日 | 直擊凌科開年展會首秀,海內外參觀者頻打卡



 工商網監
工商網監
評論