 DeepFlow AutoTagging 10x性能提升實戰
DeepFlow AutoTagging 10x性能提升實戰

為了探究云原生應用系統的內部狀態,我們希望向觀測數據中注入盡量豐富的標簽,這些標簽以往通過開發人員手動在代碼中注入,或通過配置 Promtheus、OpenTelemetry 實現,一方面造成了很大的工作量和資源開銷,另一方面也導致不同信號源的數據標簽不一致形成數據孤島。DeepFlow 依靠 AutoTagging 機制可以為所有觀測信號統一注入標準的、豐富的標簽,很好的解決了這些問題。SmartEncoding 的高性能編碼機制通過對標簽數據的分離編碼和查詢時關聯,我們將存儲開銷降低了 10~50 倍,并且能支持無限量的 K8s label/annotation 等信息作為業務自定義標簽。朋友們大家好,我是云杉網絡的宋貞,很高興今天能和大家一起分享 DeepFlow 的 AutoTagging 和 SmartEncoding 技術。這是 DeepFlow 的兩項關鍵核心技術,希望通過今天的介紹,可以讓大家詳細了解 AutoTagging 和 SmartEncoding 的實現方法,并為各位在可觀測性平臺的性能提升或者說是資源優化方向提供一個思路。內容下載:DeepFlow AutoTagging 10x性能提升實戰今天的分享將會從五個方面展開: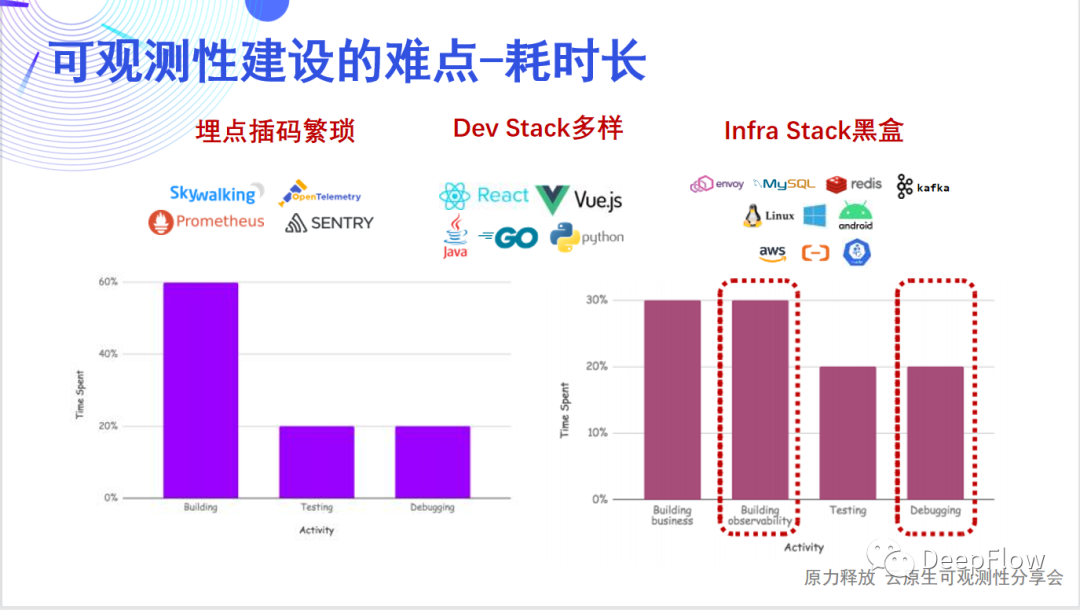 可觀測性建設耗時長我們認為應用開發團隊花了一半的時間用于可觀測性的建設。這張圖里面可以看到,開發者通常需要考慮在不同的 Dev Stack 和 Infra Stack 中如何埋點、如何插碼、如何傳遞追蹤上下文、如何生成指標/追蹤/日志數據并進行關聯,需要考慮的問題太多太雜。除此之外開發者還有很多時間在做 Debug,而這些 Debug 之所以耗費了這么多時間,通常大部分是因為可觀測性建設的欠缺導致。
可觀測性建設耗時長我們認為應用開發團隊花了一半的時間用于可觀測性的建設。這張圖里面可以看到,開發者通常需要考慮在不同的 Dev Stack 和 Infra Stack 中如何埋點、如何插碼、如何傳遞追蹤上下文、如何生成指標/追蹤/日志數據并進行關聯,需要考慮的問題太多太雜。除此之外開發者還有很多時間在做 Debug,而這些 Debug 之所以耗費了這么多時間,通常大部分是因為可觀測性建設的欠缺導致。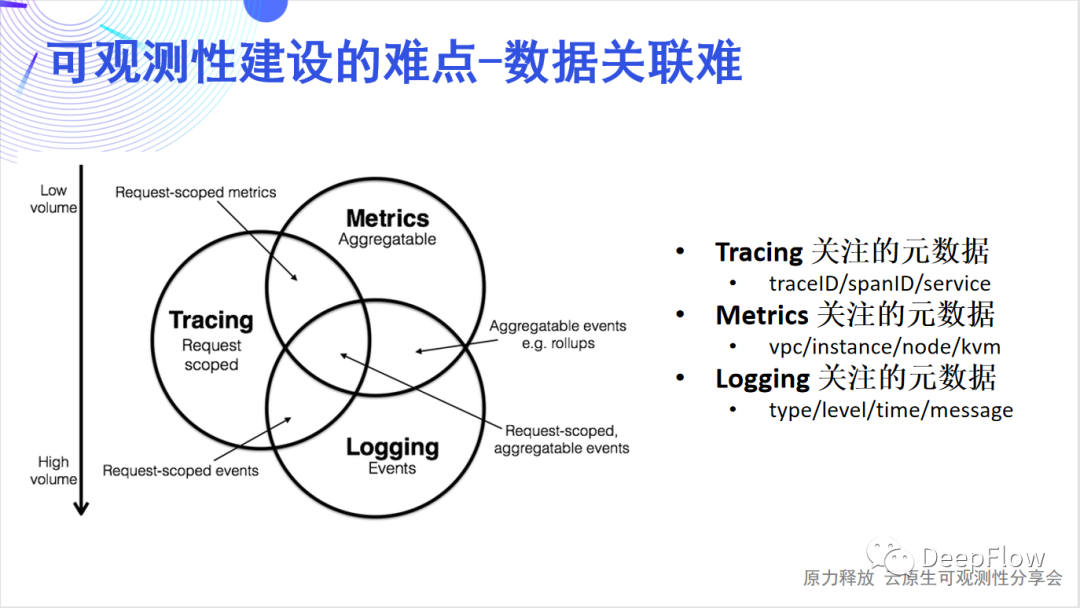 可觀測性建設數據關聯難可觀測性指標數據一般分為Tracing、Metric和Logging三類。
可觀測性建設數據關聯難可觀測性指標數據一般分為Tracing、Metric和Logging三類。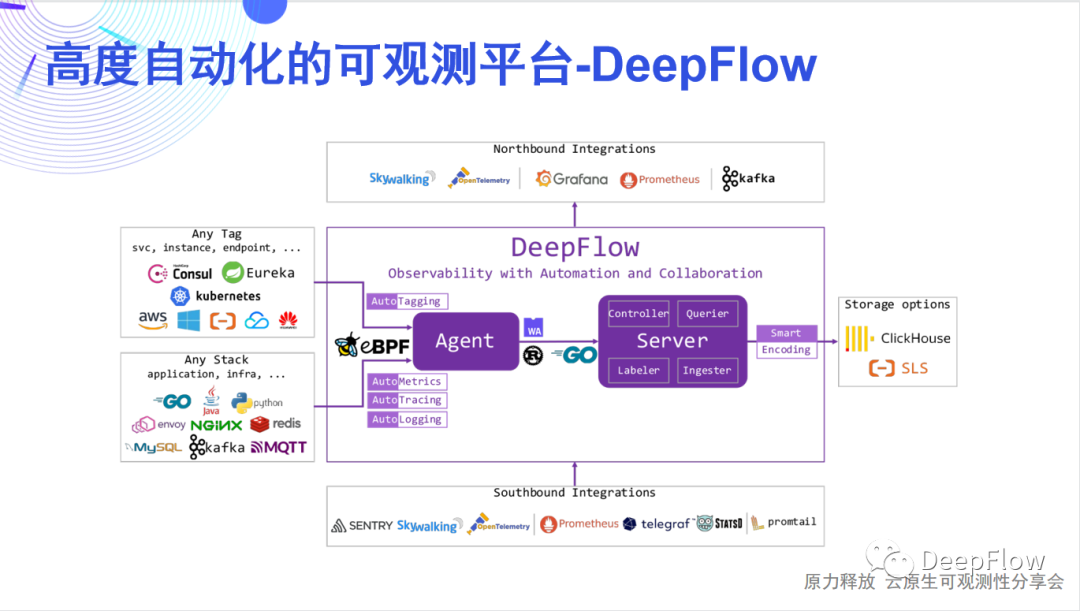 DeepFlow軟件架構DeepFlow的架構其實非常簡單,它簡單到只有一個Agent和一個Server,分別是數據采集組件和數據存儲查詢組件。Agent是使用Rust來實現的,高性能且內存安全,它通過eBPF技術實現了對任意開發技術棧、任意基礎設施的全自動應用性能指標數據采集(AutoMetrics),以及自動化的分布式鏈路追蹤(AutoTracing),這兩項是DeepFlow Agent獨有的能力,能極大降低開發者建設可觀測性的工作量。Server包含了4個內部模塊:Controller面向采集器Agent的管理,能納管多資源池的10萬量級的Agent;Labeler面向標簽數據的自動注入,提供AutoTagging的能力;Querier面向數據查詢,提供統一的SQL接口;Ingester面向數據存儲,提供插件化的、可替換可組合的數據庫接口。它支持水平擴展,而且完全不依賴外部的消息隊列或負載均衡,就能夠去實現對多個Region、多個資源池中Agent的負載均攤。Server也有兩個非常核心的技術,AutoTagging和SmartEncoding。通過AutoTagging我們能為Agent采集到的所有觀測數據自動注入統一的資源、實例和API標簽,使得我們能夠消除不同數據類型之間的隔閡,增強所有數據的關聯、切分、下鉆能力。SmartEncoding是我們非常創新的一個高性能的標簽編碼機制,通過這個機制,我們既能方便的進行數據關聯,又能將標簽注入的存儲性能提升10倍,這在我們的實際生產環境中已經進行了廣泛的驗證。
DeepFlow軟件架構DeepFlow的架構其實非常簡單,它簡單到只有一個Agent和一個Server,分別是數據采集組件和數據存儲查詢組件。Agent是使用Rust來實現的,高性能且內存安全,它通過eBPF技術實現了對任意開發技術棧、任意基礎設施的全自動應用性能指標數據采集(AutoMetrics),以及自動化的分布式鏈路追蹤(AutoTracing),這兩項是DeepFlow Agent獨有的能力,能極大降低開發者建設可觀測性的工作量。Server包含了4個內部模塊:Controller面向采集器Agent的管理,能納管多資源池的10萬量級的Agent;Labeler面向標簽數據的自動注入,提供AutoTagging的能力;Querier面向數據查詢,提供統一的SQL接口;Ingester面向數據存儲,提供插件化的、可替換可組合的數據庫接口。它支持水平擴展,而且完全不依賴外部的消息隊列或負載均衡,就能夠去實現對多個Region、多個資源池中Agent的負載均攤。Server也有兩個非常核心的技術,AutoTagging和SmartEncoding。通過AutoTagging我們能為Agent采集到的所有觀測數據自動注入統一的資源、實例和API標簽,使得我們能夠消除不同數據類型之間的隔閡,增強所有數據的關聯、切分、下鉆能力。SmartEncoding是我們非常創新的一個高性能的標簽編碼機制,通過這個機制,我們既能方便的進行數據關聯,又能將標簽注入的存儲性能提升10倍,這在我們的實際生產環境中已經進行了廣泛的驗證。 DeepFlow資源同步DeepFlow的標簽體系:
DeepFlow資源同步DeepFlow的標簽體系: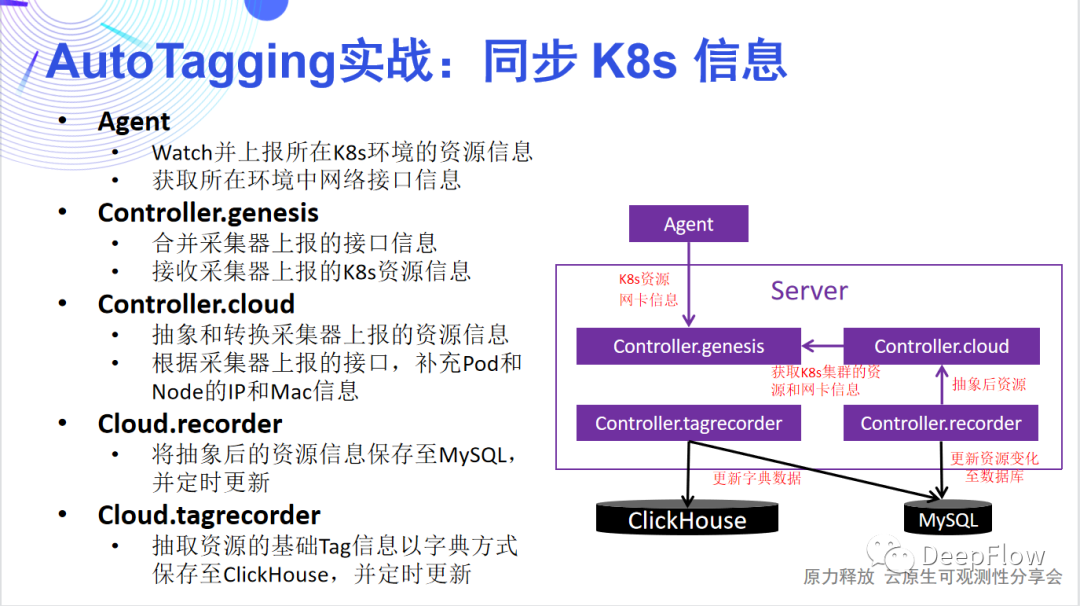 同步K8s資源的數據流同步云資源
同步K8s資源的數據流同步云資源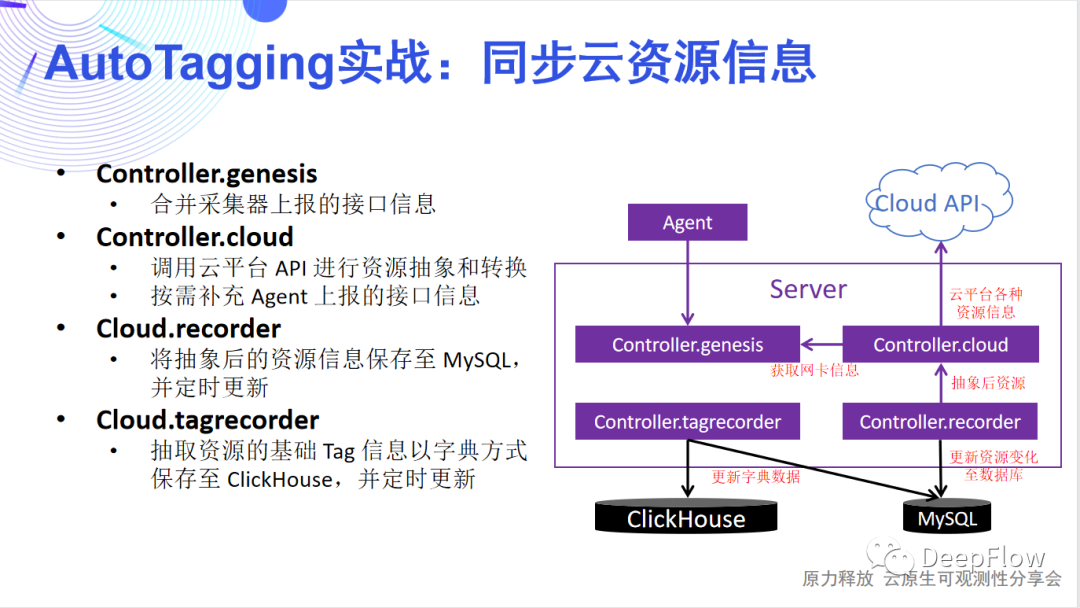 同步云資源的數據流理想很豐滿,現實很骨感。我們努力想實現觀測數據無縫跳轉,但當上百個標簽呈現在眼前時,你會發現后端資源消耗飆升,性能急劇下降,整個平臺別說無縫跳轉了,連使用都成了問題。于是 SmartEncoding 技術誕生了。
同步云資源的數據流理想很豐滿,現實很骨感。我們努力想實現觀測數據無縫跳轉,但當上百個標簽呈現在眼前時,你會發現后端資源消耗飆升,性能急劇下降,整個平臺別說無縫跳轉了,連使用都成了問題。于是 SmartEncoding 技術誕生了。 采集時編碼Controller 根據云平臺和 K8s 資源抽象好標簽信息進行 Int 編碼后,并不會將所有的標簽下發給 Agent。僅會下發最少量的標簽。這樣 Agent 只需要為數據追加很少的Int標簽即可。在混合云場景下,為了標識資源我們可以用 VPC ID 作為基,它能和 IP 地址聯合決定客戶端、服務端對應的實例和服務;可以通過 gpid 解決遠端進程信息標記的問題。我們主要考慮 Agent 做的工作盡量少,這樣可以最大限度的降低采集器的 CPU、內存消耗,以及傳輸數據的帶寬消耗。我們在生產環境中發現有些 K8s 的標簽會非常長,key 和 value 高達上百個字節。可以想象如果我們將上百個標簽注入每個請求傳輸到后端,消耗的帶寬會非常可觀。存儲時編碼
采集時編碼Controller 根據云平臺和 K8s 資源抽象好標簽信息進行 Int 編碼后,并不會將所有的標簽下發給 Agent。僅會下發最少量的標簽。這樣 Agent 只需要為數據追加很少的Int標簽即可。在混合云場景下,為了標識資源我們可以用 VPC ID 作為基,它能和 IP 地址聯合決定客戶端、服務端對應的實例和服務;可以通過 gpid 解決遠端進程信息標記的問題。我們主要考慮 Agent 做的工作盡量少,這樣可以最大限度的降低采集器的 CPU、內存消耗,以及傳輸數據的帶寬消耗。我們在生產環境中發現有些 K8s 的標簽會非常長,key 和 value 高達上百個字節。可以想象如果我們將上百個標簽注入每個請求傳輸到后端,消耗的帶寬會非常可觀。存儲時編碼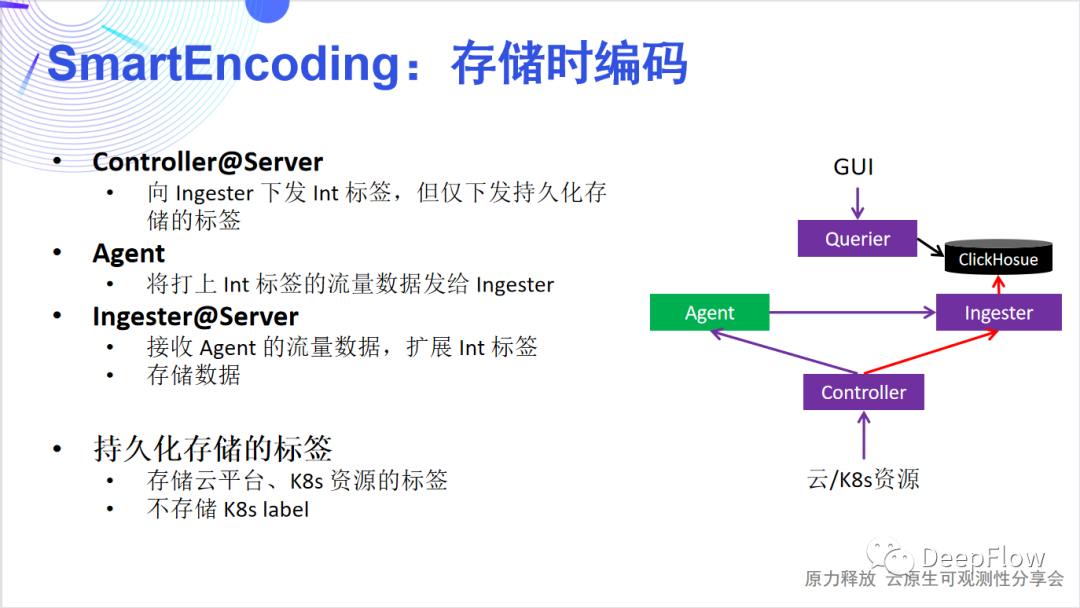 存儲時編碼同樣 Controller 會向 Ingester 下發 Int 標簽,但僅下發持久化存儲的標簽。Ingester 在收到 Agent 發過來的數據后,會進行一輪標簽的擴充,將 Agent 注入的少量標簽擴展為更為豐富的標簽集合。但這里注意的是,我們并不存儲自定義標簽。標簽的存儲是為了方便檢索和聚合,我們只需要保證每個切分粒度上都有標簽存在即可。舉例來講我們存儲 Region、AZ、VM、Node、Namespace、Service、POD 等固定的云或者 K8s 資源標簽即可,而其他的自定義的標簽一般是依附在這些標簽之上的,存在一定的對應的關系。另外,自定義標簽動態性高,也不適合全部存儲。根據我們的經驗,一般每一個請求涉及到的的固定標簽在40個左右,自定義標簽在60個左右。通過只存儲固定的資源標簽,我們能將壓力進一步降低。查詢時編/解碼
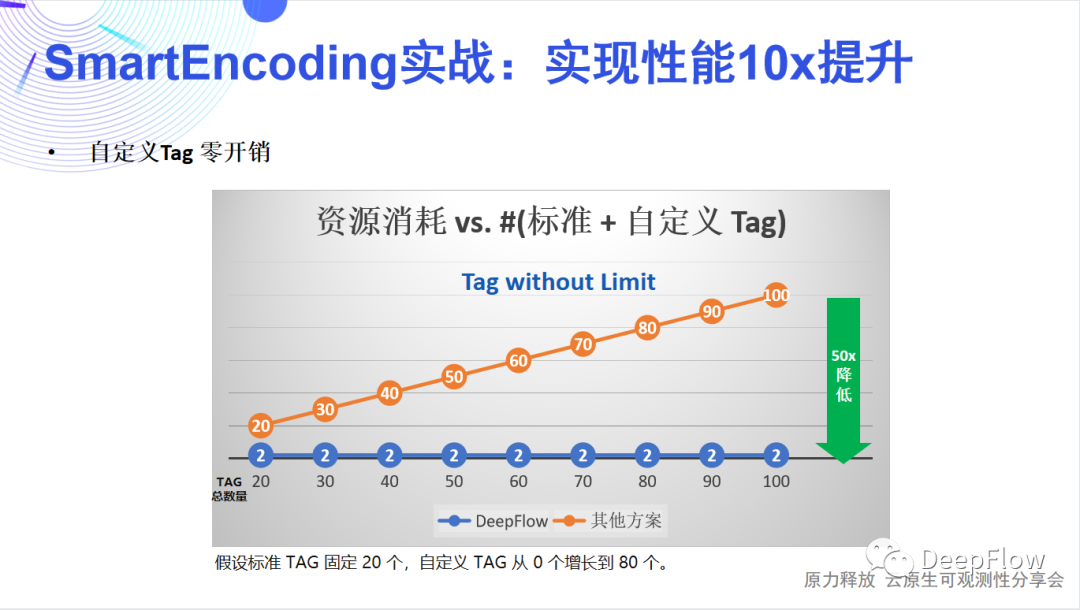
存儲時編碼同樣 Controller 會向 Ingester 下發 Int 標簽,但僅下發持久化存儲的標簽。Ingester 在收到 Agent 發過來的數據后,會進行一輪標簽的擴充,將 Agent 注入的少量標簽擴展為更為豐富的標簽集合。但這里注意的是,我們并不存儲自定義標簽。標簽的存儲是為了方便檢索和聚合,我們只需要保證每個切分粒度上都有標簽存在即可。舉例來講我們存儲 Region、AZ、VM、Node、Namespace、Service、POD 等固定的云或者 K8s 資源標簽即可,而其他的自定義的標簽一般是依附在這些標簽之上的,存在一定的對應的關系。另外,自定義標簽動態性高,也不適合全部存儲。根據我們的經驗,一般每一個請求涉及到的的固定標簽在40個左右,自定義標簽在60個左右。通過只存儲固定的資源標簽,我們能將壓力進一步降低。查詢時編/解碼 查詢時編解碼DeepFlow SQL支持通過字符串查詢和聚合,并且也支持自定義標簽的查詢和聚合。這里我們依賴 ClickHouse 的字典能力。通過編碼自定義標簽的 Filter 和 Group 查詢請求,利用 ClickHouse 的字典轉換為系統標簽;同時對于 Select 請求也可以利用 ClickHouse 的字典將系統標簽轉為字符串或者自定義標簽返回。我們再來回顧一下這三級編解碼,可以發現它能為我們節省大量的資源消耗,性能提升應該十分可觀。一方面采集器的CPU、內存可以降低,傳輸帶寬可以降低,最主要的還是后端存儲開銷的降低。我們在談論可觀測性時經常會談到采樣、避免高基數等。ClickHouse 采用稀疏索引,很好的避免了高基數問題。我們在此之上的多級編解碼又能將存儲開銷顯著降低,而且由于查詢階段掃描的數據量變小了,所以能獲得更好的查詢性能。這里有一些數據可以看一下,DeepFlow 默認使用 ClickHouse 存儲數據,在 SmartEncoding 的加持下,標準 Tag 的 CPU 和磁盤消耗相比 LowCard 存儲或直接存儲有一個數量級的優化,而由于自定義 Tag 不會隨數據寫入,在通常的場景下整體寫入資源消耗可降低50倍。
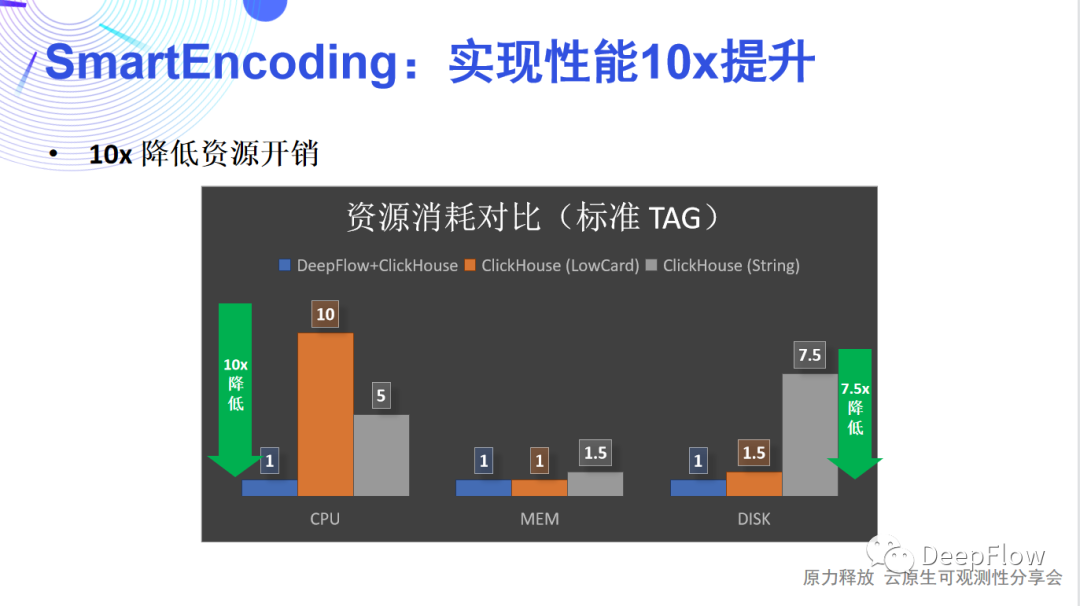
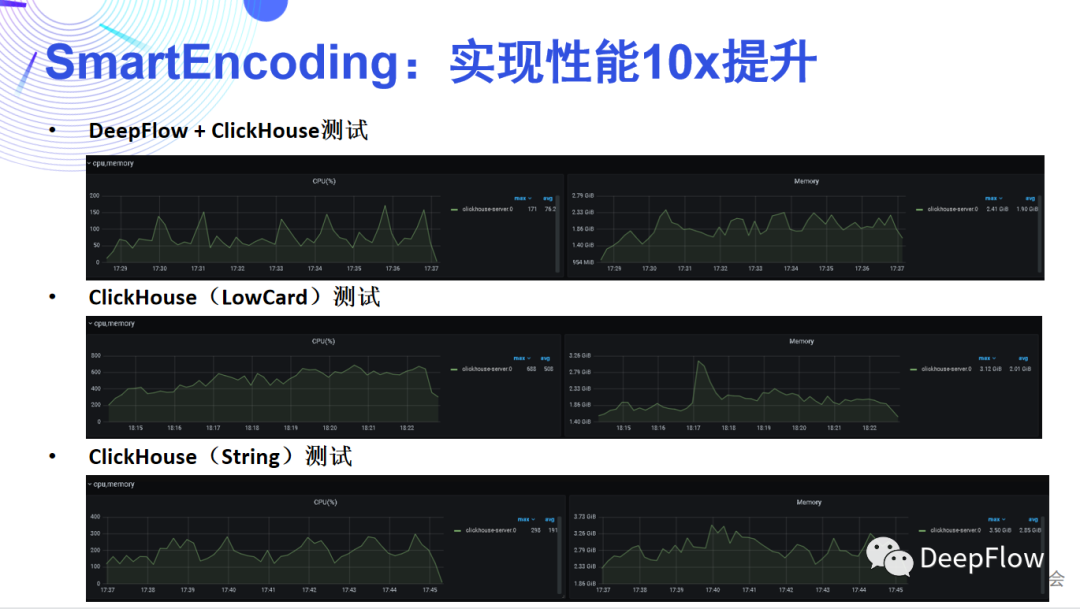
查詢時編解碼DeepFlow SQL支持通過字符串查詢和聚合,并且也支持自定義標簽的查詢和聚合。這里我們依賴 ClickHouse 的字典能力。通過編碼自定義標簽的 Filter 和 Group 查詢請求,利用 ClickHouse 的字典轉換為系統標簽;同時對于 Select 請求也可以利用 ClickHouse 的字典將系統標簽轉為字符串或者自定義標簽返回。我們再來回顧一下這三級編解碼,可以發現它能為我們節省大量的資源消耗,性能提升應該十分可觀。一方面采集器的CPU、內存可以降低,傳輸帶寬可以降低,最主要的還是后端存儲開銷的降低。我們在談論可觀測性時經常會談到采樣、避免高基數等。ClickHouse 采用稀疏索引,很好的避免了高基數問題。我們在此之上的多級編解碼又能將存儲開銷顯著降低,而且由于查詢階段掃描的數據量變小了,所以能獲得更好的查詢性能。這里有一些數據可以看一下,DeepFlow 默認使用 ClickHouse 存儲數據,在 SmartEncoding 的加持下,標準 Tag 的 CPU 和磁盤消耗相比 LowCard 存儲或直接存儲有一個數量級的優化,而由于自定義 Tag 不會隨數據寫入,在通常的場景下整體寫入資源消耗可降低50倍。
- 從可觀測性建設角度出發,總結大家在日常工作中遇到的痛點;
- 介紹 DeepFlow 的軟件架構、系統組成;
- 講解 DeepFlow 的關鍵特性 AutoTagging 技術;
- 講解支撐 AutoTagging 10x 性能提升的 SmartEncoding 技術;
-
總結并分享后續的迭代和演進計劃。
01觀測數據存儲的挑戰
可觀測性建設從去年開始在國內非常的火熱,大家談的越來越多。隨著云原生、微服務的發展落地,可觀測性建設逐漸成為了一個必不可少的工程手段。
可觀測性建設耗時長我們認為應用開發團隊花了一半的時間用于可觀測性的建設。這張圖里面可以看到,開發者通常需要考慮在不同的 Dev Stack 和 Infra Stack 中如何埋點、如何插碼、如何傳遞追蹤上下文、如何生成指標/追蹤/日志數據并進行關聯,需要考慮的問題太多太雜。除此之外開發者還有很多時間在做 Debug,而這些 Debug 之所以耗費了這么多時間,通常大部分是因為可觀測性建設的欠缺導致。可觀測性建設數據關聯難可觀測性指標數據一般分為Tracing、Metric和Logging三類。- Tracing關注的元數據是traceID/spanID/service/...;
- Metric關注的元數據是vpc/instance/node/kvm/...;
-
Logging關注的元數據是type/level/time/message/...。
02、DeepFlow 軟件架構
DeepFlow軟件架構DeepFlow的架構其實非常簡單,它簡單到只有一個Agent和一個Server,分別是數據采集組件和數據存儲查詢組件。Agent是使用Rust來實現的,高性能且內存安全,它通過eBPF技術實現了對任意開發技術棧、任意基礎設施的全自動應用性能指標數據采集(AutoMetrics),以及自動化的分布式鏈路追蹤(AutoTracing),這兩項是DeepFlow Agent獨有的能力,能極大降低開發者建設可觀測性的工作量。Server包含了4個內部模塊:Controller面向采集器Agent的管理,能納管多資源池的10萬量級的Agent;Labeler面向標簽數據的自動注入,提供AutoTagging的能力;Querier面向數據查詢,提供統一的SQL接口;Ingester面向數據存儲,提供插件化的、可替換可組合的數據庫接口。它支持水平擴展,而且完全不依賴外部的消息隊列或負載均衡,就能夠去實現對多個Region、多個資源池中Agent的負載均攤。Server也有兩個非常核心的技術,AutoTagging和SmartEncoding。通過AutoTagging我們能為Agent采集到的所有觀測數據自動注入統一的資源、實例和API標簽,使得我們能夠消除不同數據類型之間的隔閡,增強所有數據的關聯、切分、下鉆能力。SmartEncoding是我們非常創新的一個高性能的標簽編碼機制,通過這個機制,我們既能方便的進行數據關聯,又能將標簽注入的存儲性能提升10倍,這在我們的實際生產環境中已經進行了廣泛的驗證。03、AutoTagging:構建標準化的標簽體系
AutoTagging通過云API、K8s apiserver自動同步30多種資源標簽、100多種自定義微服務標簽,來構建標準化的標簽體系。
DeepFlow資源同步DeepFlow的標簽體系:-
自定義標簽
- k8s.label/k8s.env/k8s.annotation/..
- os.app/os.proc/...
- cloud.tag
-
進程
- 進程名
-
云資源
- 資源池:區域/可用區
- 計算資源:云服務器/宿主機
- 網絡資源:VPC/子網/路由器/IP地址
- 網絡服務:安全組/負載均衡器/NAT網關/對等連接/云企業網
- 存儲資源:云數據庫RDS/Redis
-
容器資源
- 容器集群/容器節點/命名空間/Ingress/容器服務/工作負載/POD
- 為什么是 Agent watch 并上報 K8s資源?一個 Server 可以管理多個集群中的 Agent,Agent在所屬集群中watch K8s,避免了集群外部用 server watch 時涉及到的權限和配置問題。
- 如何控制 Agent 對 K8s 資源的 watch?避免 K8s 的 API 壓力過大,不能讓所有的 Agent 都去 watch K8s,Server 在每個集群中選舉一個 Agent;僅讓被選中的 Agent watch K8s 資源。
- 內存優化:Agent 僅抓取同步必須的字段,同時會第一時間進行壓縮。
- 帶寬優化:僅當 K8s 資源有變化時,Agent 才會向 Server 發送具體的資源信息
同步K8s資源的數據流同步云資源-
同步云資源信息:通過調用云平臺 API 進行資源抽象和轉換,然后將相關標簽信息保存至 MySQL 中,并定期更新 ClickHosue 中的字典。
-
同步 Legacy Host 信息:一些環境中,可能沒有真正意義的云平臺,或者存在一些傳統主機需要監控,這就需要用Legacy Host同步方案。由于沒有具體的云API,我們完全通過Agent抓取所在服務器的名稱等基本信息和網卡信息,上報給Server匯總并進行資源抽象。
-
同步托管 K8s 信息:當 K8s 平臺部署在云資源上時,要做到真正的可觀測性,需要將K8s的資源和云資源關聯起來,才能真正做到無縫地關聯、切分和下鉆。我們一方面通過獲取 K8s 資源所在的 VPC,基于 VPC 內 IP 的唯一性,通過 VPC + IP 將 K8s 的容器節點與云服務器關聯起來;另一方面通過將云平臺的 API 調用與 K8s 獨立,兩者使用不同的調用頻率,從而解決大規模場景下,云平臺 API 慢與 K8s 資源更新快的矛盾。
同步云資源的數據流理想很豐滿,現實很骨感。我們努力想實現觀測數據無縫跳轉,但當上百個標簽呈現在眼前時,你會發現后端資源消耗飆升,性能急劇下降,整個平臺別說無縫跳轉了,連使用都成了問題。于是 SmartEncoding 技術誕生了。04、SmartEncoding:實現 10x 性能提升
SmartEncoding 將標簽注入分為3個階段,通過采集時編碼、存儲時編碼、和查詢時編/解碼降低標簽寫入的資源消耗,我們來詳細看看每個階段都如何實現:采集時編碼采集時編碼Controller 根據云平臺和 K8s 資源抽象好標簽信息進行 Int 編碼后,并不會將所有的標簽下發給 Agent。僅會下發最少量的標簽。這樣 Agent 只需要為數據追加很少的Int標簽即可。在混合云場景下,為了標識資源我們可以用 VPC ID 作為基,它能和 IP 地址聯合決定客戶端、服務端對應的實例和服務;可以通過 gpid 解決遠端進程信息標記的問題。我們主要考慮 Agent 做的工作盡量少,這樣可以最大限度的降低采集器的 CPU、內存消耗,以及傳輸數據的帶寬消耗。我們在生產環境中發現有些 K8s 的標簽會非常長,key 和 value 高達上百個字節。可以想象如果我們將上百個標簽注入每個請求傳輸到后端,消耗的帶寬會非常可觀。存儲時編碼存儲時編碼同樣 Controller 會向 Ingester 下發 Int 標簽,但僅下發持久化存儲的標簽。Ingester 在收到 Agent 發過來的數據后,會進行一輪標簽的擴充,將 Agent 注入的少量標簽擴展為更為豐富的標簽集合。但這里注意的是,我們并不存儲自定義標簽。標簽的存儲是為了方便檢索和聚合,我們只需要保證每個切分粒度上都有標簽存在即可。舉例來講我們存儲 Region、AZ、VM、Node、Namespace、Service、POD 等固定的云或者 K8s 資源標簽即可,而其他的自定義的標簽一般是依附在這些標簽之上的,存在一定的對應的關系。另外,自定義標簽動態性高,也不適合全部存儲。根據我們的經驗,一般每一個請求涉及到的的固定標簽在40個左右,自定義標簽在60個左右。通過只存儲固定的資源標簽,我們能將壓力進一步降低。查詢時編/解碼查詢時編解碼DeepFlow SQL支持通過字符串查詢和聚合,并且也支持自定義標簽的查詢和聚合。這里我們依賴 ClickHouse 的字典能力。通過編碼自定義標簽的 Filter 和 Group 查詢請求,利用 ClickHouse 的字典轉換為系統標簽;同時對于 Select 請求也可以利用 ClickHouse 的字典將系統標簽轉為字符串或者自定義標簽返回。我們再來回顧一下這三級編解碼,可以發現它能為我們節省大量的資源消耗,性能提升應該十分可觀。一方面采集器的CPU、內存可以降低,傳輸帶寬可以降低,最主要的還是后端存儲開銷的降低。我們在談論可觀測性時經常會談到采樣、避免高基數等。ClickHouse 采用稀疏索引,很好的避免了高基數問題。我們在此之上的多級編解碼又能將存儲開銷顯著降低,而且由于查詢階段掃描的數據量變小了,所以能獲得更好的查詢性能。這里有一些數據可以看一下,DeepFlow 默認使用 ClickHouse 存儲數據,在 SmartEncoding 的加持下,標準 Tag 的 CPU 和磁盤消耗相比 LowCard 存儲或直接存儲有一個數量級的優化,而由于自定義 Tag 不會隨數據寫入,在通常的場景下整體寫入資源消耗可降低50倍。
SELECTcol_1,col_2,col_3 FROMtbl_1 WHEREcol_4=y GROUPBYcol_1,col_2 HAVINGcol_5>100 ORDERBYcol_3 LIMIT100 ``` 我們可以查詢某個 Tag 的所有候選項: ```sql SHOWtag${tag_name}valuesFROM${table_name}
SHOWtag${tag_name}values FROM${table_name} WHEREdisplay_nameLIKE'*abc*'
SELECTpod FROM`vtap_flow_port.1m` WHEREpod_cluster='cluster1' GROUPBYpod 更多詳細用法[4]查詢 Universal Tag
- ClickHouse 的觀測數據表中保存tag ID
CREATETABLEflow_metrics.`vtap_flow_port.1m` ( `time`DateTime('Asia/Shanghai')COMMENT'v6.1.8'CODEC(DoubleDelta), `ip4`IPv4COMMENT'IPv4地址', `ip6`IPv6COMMENT'IPV6地址', `is_ipv4`UInt8COMMENT'是否IPV4地址.0:否,ip6字段有效,1:是,ip4字段有效', `l3_device_id`UInt32COMMENT'ip對應的資源ID', `l3_device_type`UInt8COMMENT'ip對應的資源類型', `l3_epc_id`Int32COMMENT'ip對應的EPCID', `pod_cluster_id`UInt16COMMENT'ip對應的容器集群ID', `pod_group_id`UInt32COMMENT'ip對應的容器工作負載ID', `pod_id`UInt32COMMENT'ip對應的容器PODID', `pod_node_id`UInt32COMMENT'ip對應的容器節點ID', `pod_ns_id`UInt16COMMENT'ip對應的容器命名空間ID' ) ENGINE=Distributed(...)
- ClickHouse 的字典表中保存tag ID和名稱對應關系
CREATEDICTIONARYflow_tag.pod_map ( `id`UInt64, `name`String, `icon_id`Int64 ) PRIMARYKEYid SOURCE(...)
- 通過 dictGet 實現tag ID到名稱的轉換
SELECTdictGet(flow_tag.pod_map,'name',toUInt64(pod_id))ASpod FROM`vtap_flow_port.1m` WHEREpod='deepflow' GROUPBYpod LIMIT1 查詢 K8s label
- ClickHouse 的字典表中保存tag ID和 K8s label對應關系
CREATEDICTIONARYflow_tag.k8s_label_map ( `pod_id`UInt64, `key`String, `value`String, ) PRIMARYKEYpod_id,key SOURCE(...) LIFETIME(MIN0MAX60) LAYOUT(COMPLEX_KEY_HASHED())
- 通過 dictGet 實現tag ID到 K8s label 的轉換
SELECTdictGet(flow_tag.k8s_label_map,'value',(toUInt64(pod_id),'app'))AS`label.app` FROM`vtap_flow_port.1m` WHERE`label.app`='xxx' LIMIT1 查詢集成數據,包括 Prometheus、Telegraf、OpenTelemetry 等數據。
- 存儲集成數據時,會將數據中原有的 Tag 和 Metric 的 name 和 value 分別定義為 Array 類型,一一對應。
CREATETABLEext_metrics.prometheus_web ( `time`DateTime('Asia/Shanghai')CODEC(DoubleDelta), `_tid`UInt8COMMENT'用于區分trident不同的pipeline', `az_id`UInt16COMMENT'可用區ID', `host_id`UInt16COMMENT'宿主機ID', `tag_names`Array(String)COMMENT'額外的tag', `tag_values`Array(String)COMMENT'額外的tag對應的值', `metrics_float_names`Array(String)COMMENT'額外的metrics', `metrics_float_values`Array(Float64)COMMENT'額外的metrics值' )
- Tag 候選項只需要保留不重復的值,所以我們使用 ReplacingMergeTree Engine
CREATETABLEflow_tag.ext_metrics_custom_field_local ( `time`DateTime('Asia/Shanghai')CODEC(DoubleDelta), `table`LowCardinality(String), `vpc_id`Int32, `pod_ns_id`UInt16, `field_type`LowCardinality(String)COMMENT'value:tag,metrics', `field_name`LowCardinality(String), `field_value_type`LowCardinality(String)COMMENT'value:string,float' ) ENGINE=ReplacingMergeTree(time)
- 通過 indexOf 進行 name 和 value 的對應
SELECTtag_values[indexOf(tag_names,'host')]AS`tag.host` FROMdeepflow_agent_collect_sender WHERE(tag_values[indexOf(tag_names,'host')])='xxxx' LIMIT1
05、總結與后續迭代計劃
通過以上分享,相信您會發現DeepFlow有豐富、統一的標準化標簽體系,非常方便進行數據關聯、切分、下鉆。通過 SmartEncoding 的性能優化,Server + ClickHouse 的資源消耗通常為業務消耗的 1%,即監控100個 16c64g 的容器節點,大概需要1個 16c64g 的 Node 部署 Server + ClickHouse,且可以通過對象存儲轉儲冷數據;而且常見的可觀測性數據一般都需要注入百量級的標簽,DeepFlow Agent 由于只注入了 VPC、GPID 少數幾個字段,因此它用于標簽注入的資源消耗幾乎只有其他方案的百分之幾。這樣10x性能的使用體驗,相信 Cloud-Native、NewOps 都會喜歡!后續我們會支持更豐富的自定義標簽,包括通過 K8s API 獲取的k8s.annotation 和 k8s.env、通過操作系統獲取的 os.proc 信息、通過執行命令獲取 os.app 信息;會從時間和帶寬消耗兩方面進一步優化AutoTagging的性能,通過不同類型資源的 API 可以設置不同的調用頻率,避免每次都是重新獲取全部資源來縮短縮短大規模下的資源同步時間;通過Agent 僅發送有變化的 K8s 資源信息,進一步降低帶寬消耗。06、關于DeepFlow
DeepFlow[5]是一款開源的高度自動化的可觀測性平臺,是為云原生應用開發者建設可觀測性能力而量身打造的全棧、全鏈路、高性能數據引擎。DeepFlow 使用 eBPF、WASM、OpenTelemetry 等新技術,創新的實現了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心機制,幫助開發者提升埋點插碼的自動化水平,降低可觀測性平臺的運維復雜度。利用 DeepFlow 的可編程能力和開放接口,開發者可以快速將其融入到自己的可觀測性技術棧中。 審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
核心技術
+關注
關注
4文章
625瀏覽量
20497 -
數據存儲
+關注
關注
5文章
1025瀏覽量
52946 -
軟件架構
+關注
關注
0文章
64瀏覽量
10642
原文標題:DeepFlow AutoTagging 10x性能提升實戰
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
5G手機?Redmi 10X性價比很高?Redmi 10X怎么樣?來看看Redmi 10X拆解
,Redmi又攜手聯發科天璣820,發布Redmi 10X,最低售價1599。主打高性價比,是否如實,一拆便知。 本次拆解的是Redmi 10X,6GB RAM+ 128GB ROM版。以下數據信息均以拆解
示波器的10X檔和1X檔輸入阻抗
選擇1X檔時,信號是沒經衰減進入示波器的。而選擇10X檔時,信號是經過衰減到1/10再到示波器的。當選擇10X檔時,應該將示波器上的讀數也擴大10
發表于 05-20 14:43
10X genomics課程筆記
課程筆記10X genomics10X genomics技術:文獻在10X官網中的publications。對單個細胞做RNA表達情況的定量分析。基于油包水乳濁液酶反應原理的分子生物學分析系統。可以
發表于 07-29 09:00
微軟承認基于虛擬化的功能將會讓Windows 10X的性能更出色
Windows 10X遠不只是Windows 10的新版本,因為它被設計為有著與Windows 7或Windows 10不同的應用程序、文件和軟件交互體驗。在Windows 10X系統
微軟Windows 10X系統支持UWP應用和Win32應用程序運行
微軟確認Windows 10X系統能夠運行UWP應用、網頁應用以及傳統的Win32應用程序。Win32、UWP和PWA應用程序都會通過Windows 10X的容器進行運行,從而保護操作系統免受潛在的惡意軟件和性能問題的影響。
Windows 10X春季正式上線,面向輕量級設備
根據目前掌握的信息Windows 10X將會在今 12月進入RTM階段,預估會在今年春季正式上線。而Windows 10X系統的主要更新會在每年的春季上線,因此微軟希望Windows 10給其讓路
微軟正式公開Windows 10X取代Windows 10,12月進入RTM階段
微軟已經正式公開了Windows 10X了,作為取代Windows 10的新系統,你對它期待嗎? 根據目前掌握的信息Windows 10X將會在今年12月進入RTM階段(下月就能用到),預估會在今年
Windows 10X今年即將到來?
微軟正在開發Windows 10X系統,已經不是什么秘密了。最近更是有消息顯示,在本年度的12月份,微軟就會公布Windows 10X的RTM版本,在明年的1月份Win10X則會正式推向市場。 作為
微軟即將新推出Windows 10X系統
微軟正在開發Windows 10X系統,已經不是什么秘密了。最近更是有消息顯示,在本年度的12月份,微軟就會公布Windows 10X的RTM版本,在明年的1月份Win10X則會正式推向市場。
盤點匯總Windows 10X的亮點功能
微軟已經完成了Windows 10X的RTM版,并將分發給硬件制造商。預計,Windows 10X將于2021年初與微軟合作伙伴的硬件產品一起推出,包括惠普、戴爾、聯想等。
Windows 10X相較Windows 10有哪些亮點?
Windows 10X是一款面向雙屏可折疊設備的操作系統。在沉寂了幾個月后,微軟終于完成了Windows 10X的RTM版,后續將分發給硬件制造商,預計將于2021年初用在惠普、戴爾、聯想等品牌的硬件產品上。那么,Windows 10X
淺談Windows 10X與Windows 10的主要區別
Windows 10X是在Windows 10的基礎上開發,采用現代的組件取代舊的程序,用戶界面相似,但是取消了活動磁貼以及文件資源器等。Windows 10X在2020年12月就完成了RTM版,微軟計劃在3月-6月期間正式發布
10x無源探頭正確使用方法介紹
用好無源探頭。10x無源探頭的最佳用法使用10x無源探頭時,有五個重要的最佳測量準則要遵守,以獲得10x探頭的最佳性能并避免常見的錯誤: 1、使用示波器前面板上的校準參考信號來補償探頭




 工商網監
工商網監
評論