 如何訓練ChatGPT?中國版ChatGPT下月面世
如何訓練ChatGPT?中國版ChatGPT下月面世

中國版ChatGPT下月面世
美國人工智能公司OpenAI的大語言模型ChatGPT在推出約兩個月后,1月已達到1億月活躍用戶,成為歷史上增長最快的消費者應用程序,更是掀起了新一輪人工智能浪潮。
北京時間2月8日凌晨,微軟推出由ChatGPT支持的最新版本必應搜索引擎和Edge瀏覽器,宣布要“重塑搜索”。微軟旗下Office、Azure云服務等所有產品都將全線整合ChatGPT。
更有甚者,中國百度公司2月7日表示,將在今年3月完成類似ChatGPT的項目“文心一言”(ERNIE Bot)的內部測試,加入這場全球競賽。
百度公司表示,文心一言(其英文名Ernie為“通過知識整合增強表征”的英文縮寫)是一種大型人工智能賦能的語言模式,于2019年啟動。該公司還說,它已經逐漸發展到能夠完成語言理解、語言生成和文本生成圖像等任務。
百度稱,該公司在人工智能四層架構中擁有全棧布局。“文心一言”位于模型層。基于公司在人工智能領域深耕數十年,擁有產業級知識增強文心大模型ERNIE,具備跨模態、跨語言的深度語義理解與生成能力。
如何訓練ChatGPT
ChatGPT現在支持GPT-3.5系列機型,比 GPT3更強大。 這些模型在 Microsoft 的Azure AI超級計算基礎設施上使用文本和代碼數據進行訓練。
具體來說,ChatGPT是在開源數據集上訓練的,訓練參數比上一代GPT3提升了10倍以上,并且人工標注數據和強化學習,相當于拿回了被GPT3去掉的微調步驟,實現了在與人類互動時從反饋中強化學習。
當我們想要構建一個AI模型時,最重要的步驟總結下來就是:定義架構、訓練、調試以及測試。記者詢問ChatGPT,你是如何訓練的,它的回復是:1. 選擇大規模語料庫,構建訓練集。2. 定義模型架構,通常使用Transformer模型。3. 選擇優化算法并設置超參數。4. 訓練模型,根據訓練損失下降情況和驗證集結果決定是否需要調整超參數。5. 使用測試集評估模型性能。6. 如果需要,對模型進行微調,以提高性能。
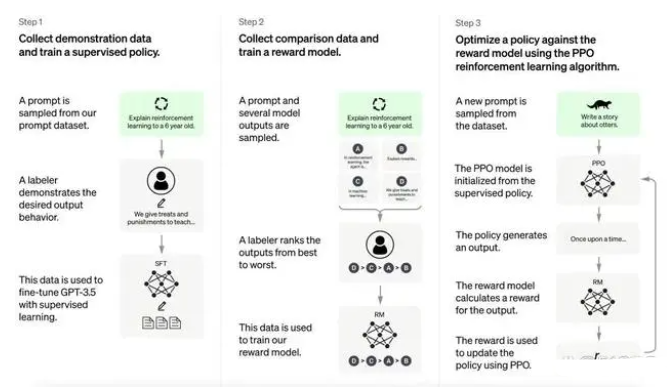
當決定要訓練一個語言類AI模型時,第一件事就要明確訓練AI的語料庫。語料庫的選擇十分重要,為了讓語言模型學到足夠多的語言信息,需要選擇盡量規模大的文本語料庫。以ChatGPT為例,訓練類似AI模型時,就需要準備各類網站的百科文章、網絡回答、專業論文等。據了解,一款通用AI算法所使用的預訓練語料庫大小為1-10GB之間,而用于訓練ChatGPT的前身——GPT-3的語料庫達到了45TB。
訓練AI執行語言任務還繞不開Transformer模型。Transformer模型(變換器)是一種采用自注意力機制的深度學習模型,自注意力的意思即可以按照輸入數據各部分重要性的不同而分配不同的權重。它通過計算詞與詞之間的相對位置關系來確定注意力的權值,最終生成語句的語義表示。Transformer的優勢在于其可以并行計算,速度快,精度高,是目前自然語言處理中最常使用的模型之一。
文章綜合與非網、參考消息網、新華社
-
聊天機器人
+關注
關注
0文章
348瀏覽量
13080 -
自然語言
+關注
關注
1文章
292瀏覽量
13966 -
ChatGPT
+關注
關注
31文章
1598瀏覽量
10207
發布評論請先 登錄
巨頭競逐AI醫療健康:OpenAI推出ChatGPT Health,螞蟻阿福國內領跑
ChatGPT擬上廣告,你的AI要開始帶貨了

今日看點|黃仁勛:物理AI的ChatGPT時刻已然到來;波士頓動力發布Atlas人形機器人量產版本
ChatGPT 智能體發布的觀點解析及對科義相關系統的現實意義
大家都在用什么AI軟件?有沒有好用的免費的AI軟件推薦一下?
AI真會人格分裂!OpenAI最新發現,ChatGPT善惡開關已開啟

樹莓派與EthernetHat:用ChatGPT實現的MQTT智能家居項目!

如何高效訓練AI模型?這些常用工具你必須知道!
樹莓派遇上ChatGPT,魔法熱線就此誕生!

用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集


能和Ai-M61模組對話了?手搓一個ChatGPT 語音助手
DeepSeek沖擊(含本地化部署實踐)



 工商網監
工商網監
評論