 3D UX-Net:超強的醫學圖像分割新網絡
3D UX-Net:超強的醫學圖像分割新網絡


Title: 3D UX-Net: a Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
Author: Ho Hin Lee et al. (范德堡大學)
Paper: https://arxiv.org/abs/2209.15076
Github: https://github.com/MASILab/3DUX-Net
引言
眾所周知,大多數醫學圖像如 MRI 和 CT 是屬于 volumetric data 類型。因此,為了更加充分的利用體素信息,近幾年已經提出了不少 3D CNNs 的模型,如 SwinUNETR、UNETR以及筆者前段時間分享過的UNETR++等。
整體來說,這些模型性能是越來越高,在幾個主流的 3D 數據基準測試中也實現了大大小小的 SOTA,特別是 3D 醫學圖像分割這塊。當然,時代在進步,作為一名高科技前沿從業者本身也是需要不斷汲取新的知識營養才能不被輕易的淘汰。今天小編就帶大家解讀下 ICLR 2023 新鮮出爐的 3D 醫學圖像分割之星——3D UX-Net。
3D UXNet 是一種輕量級3D卷積神經網絡,其使用 ConvNet 模塊調整分層 Transformer 以實現穩健的體素分割,在三個具有挑戰性的腦體積和腹部成像公共數據集與當前的 SOTA 模型如 SwinUNETR 對比,同時在以下三大主流數據集性能均達到了最優:
-
MICCAI Challenge 2021 FLARE -
MICCAI Challenge 2021 FeTA -
MICCAI Challenge 2022 AMOS
具體的,相比于 SwinUNETR,3D UX-Net 將 Dice 從 0.929 提高到 0.938 (FLARE2021),Dice 從 0.867 提高到 0.874 (Feta2021)。此外,為了進一步評估 3D UX-Net 的遷移學習能力,作者在 AMOS2022 數據集上訓練得到的模型在另一個數據集上取得了 2.27% Dice 的提升(0.880 → 0.900)。
動機
先來看看最近提出的一眾基于 Transformer 架構的 ViT 模型有什么優劣勢。以 SwinUNETR 為例,其將 ConvNet 的一些先驗引入到了 Swin Transformer 分層架構中,進一步增強了在 3D 醫學數據集中調整體素分割的實際可行性。此類 "Conv+Transforemr" 的組合拳的有效性在很大程度上歸功于以下兩個因素:
- 非局部自注意力所帶來的大感受野
- 大量的模型參數
為此,本文作者想到了應用深度卷積以更少的模型參數來模擬這些方法讓網絡學會如何捕獲更大感受野的行為。這一點筆者在前文《關于語義分割的億點思考》中也提過,文中對整個任務進行了深度剖析,有興趣的讀者可以自行翻閱公眾號歷史文章:
語義分割任務的核心思想是如何高效建模上下文信息,它是提升語義分割性能最為重要的因素之一,而有效感受野則大致決定了網絡能夠利用到多少上下文信息。
回到正文,本文的設計思路主要是受 ConvNeXt 啟發,還沒了解過的同學也可自行移動到公眾號翻閱歷史文章,筆者之前對該系列也講解過了,此處不再詳述。3D UX-Net 核心理念是設計出一種簡單、高效和輕量化的 網絡,其適用于 hierarchical transformers 的能力同時保留使用 ConvNet 模塊的優勢,如歸納偏置。具體地,其編碼器模塊設計的基本思想可分為: 1) block-wise(微觀層面) 及 2) layer-wise(宏觀層面)【可以類比下 ConvNeXt】。
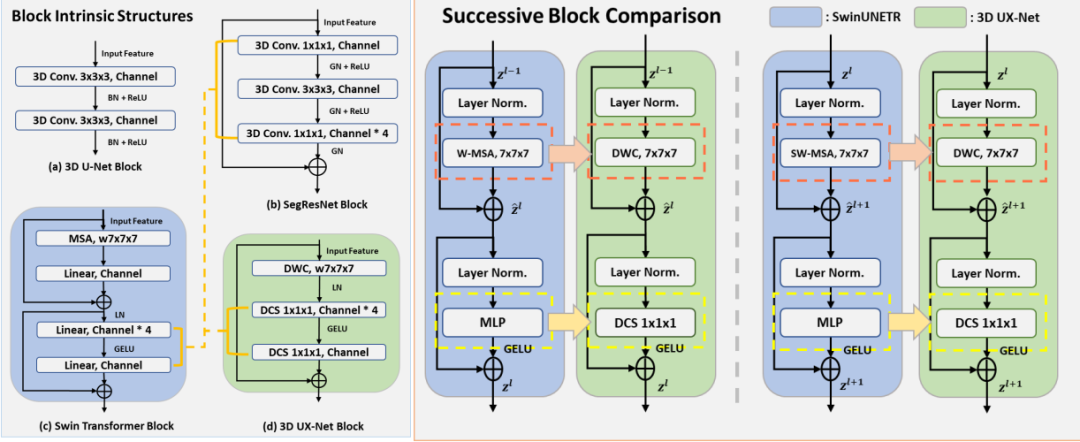
block-wise
首先,我們先從下列三個不同的視角進行討論。
Patch-wise Features Projection
對比 ConvNets 和 ViTs 之間的相似性,兩個網絡都使用一個共同的基礎模塊將特征表示縮小到特定的尺寸。以往的方法大都沒有將圖像塊展平為具有線性層的順序輸入,因此作者采用具備大卷積核的投影層來提取 patch-wise 特征作為編碼器的輸入。
Volumetric Depth-wise Convolution with LKs
Swin transformer 的內在特性之一是用于計算非局部 MSA 的滑動窗口策略。總的來說,有兩種分層方法來計算 MSA:基于窗口的 MSA (W-MSA) 和 移動窗口 MSA (SW-MSA)。這兩種方式都生成了跨層的全局感受野,并進一步細化了非重疊窗口之間的特征對應關系。
受深度卷積思想的啟發,作者發現自注意力中的加權和方法與每通道卷積基礎之間的相似之處,其認為使用 LK 大小的深度卷積可以在提取類似于 MSA 塊的特征時提供大的感受野。因此,本文建議采用 LK 大小(例如,從 7 × 7 × 7 開始)通過深度卷積壓縮 Swin transformer 的窗口移動特性。如此一來便可以保證每個卷積核通道與相應的輸入通道進行卷積運算,使得輸出特征與輸入具備相同的通道維度。
Inverted Bottleneck with Depthwise Convolutional Scaling
Swin transformer 的另一個固有結構是,它們被設計為 MLP 塊的隱藏層維度比輸入維度寬四倍,如下圖所示。有趣的是,這種設計與 ResNet 塊中的擴張率相關。因此,我們利用 ResNet 塊中的類似設計并向上移動深度卷積來計算特征。此外,通過引入了具有 1 × 1 × 1 卷積核大小的深度卷積縮放(DCS),以獨立地線性縮放每個通道特征。通過獨立擴展和壓縮每個通道來豐富特征表示,可以最小化跨通道上下文產生的冗余信息,同時在每個階段增強了與下采樣塊的跨通道特征對應。最后,通過使用 DCS,可以進一步將模型復雜度降低 5%,并展示了與使用 MLP 模型的架構相當的結果。
layer-wise
介紹完微觀層面的設計思想,再讓我們從宏觀層面出發,以另外三個嶄新的視角去理解作者的動機。
Applying Residual Connections
從上圖左上角可以看到,標準的 3D U-Net 模型內嵌的模塊為 2 個 3 x 3 x 3 卷積的堆疊,其展示了使用小卷積核提取具有增加通道的局部表示的樸素方法;而其右手邊的 SegResNet 則應用了類似 3D 版本的瓶頸層,先降維再升維最后再接殘差表示;緊接著左下角的便是 Swin Transformer,其基于窗口注意力+MLP層的組合;最后右下角便是本文所提出的模塊,其在最后一個縮放層之后應用輸入和提取特征之間的殘差連接。此外,在殘差求和前后并沒有應用到任何的歸一化層和激活層。
Adapting Layer Normalization
我們知道,在卷積神經網絡中,BN 是一種常用策略,它對卷積表示進行歸一化以增強收斂性并減少過擬合。然而,之前的工作已經證明 BN 會對模型的泛化能力產生不利影響。因此作者這里跟 ConvNeXt 一致,將 BN 替換為 LN。
Using GELU as the Activation Layer
ReLU 是個好東西,幾乎是現代 CNNs 模型的首選激活函數。作者在這里提倡使用 GELU,這是一種基于高斯誤差的線性變換單元,相對 ReLU 更加平滑,也是其中一種變體,解決 ReLU 因負梯度被硬截斷而導致的神經元失活問題。
方法
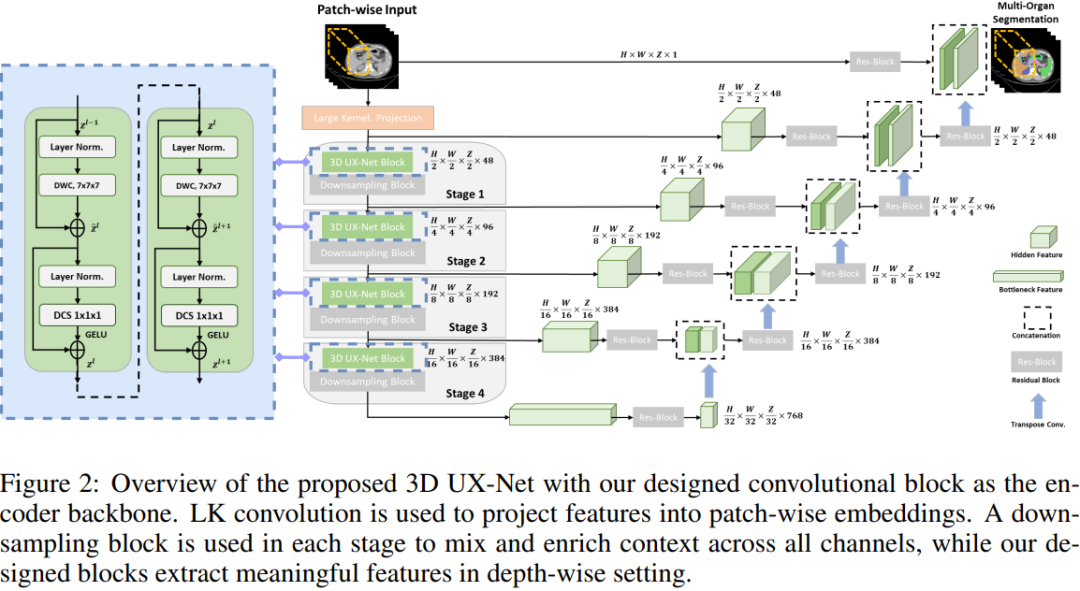
可以看出,整體的設計思路非常簡潔,框架也是一目了然,就一個標準的 3D U-Net 架構,由編碼器-解碼器組成,同時結合長跳躍連接操作幫助網絡更好的恢復空間細節的定位。也沒啥好分析的,下面就簡單拆開來看看,帶大家快速的過一遍就行。
DEPTH-WISE CONVOLUTION ENCODER
首先,輸入部分應用一個大卷積核將原始圖像映射到一個低維空間分辨率的潛在空間特征表示,一來降低顯存參數量計算量等,二來可以增大網絡感受野,順便再處理成編碼器輸入所需的格式,總之好處多多,不過都是基操。
處理完之后就輸入到編碼器中進行主要的特征提取,該編碼器共4個stage,也是標準的16倍下采樣。每個stage由多個不同的 3D UX-Net Block 構成,具體長啥樣自己看下左圖一點就通。主要的特點就是主打輕量化和大感受野。
DECODER
編碼器中每個階段的多尺度輸出通過長跳躍連接鏈接到基于 ConvNet 的解碼器,并形成一個類似U形的網絡以用于下游的分割任務。這一塊就跟標準的 3D U-Net 幾乎沒啥兩樣了。
實驗
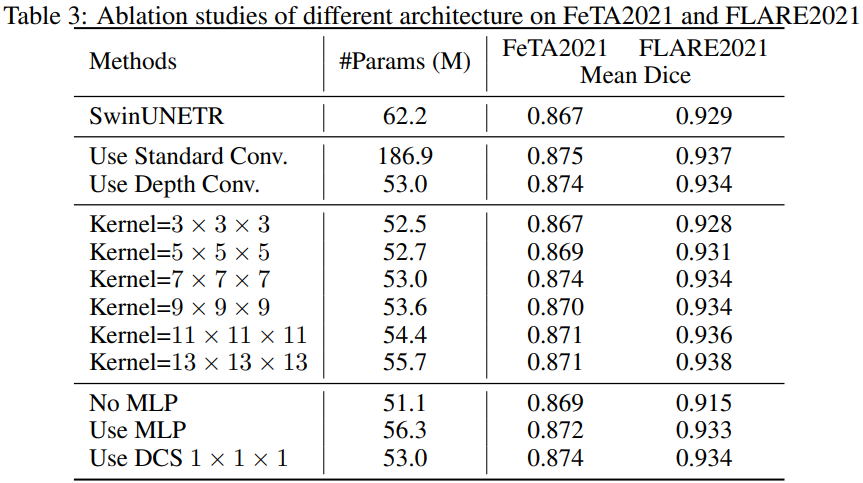
消融實驗
可視化效果
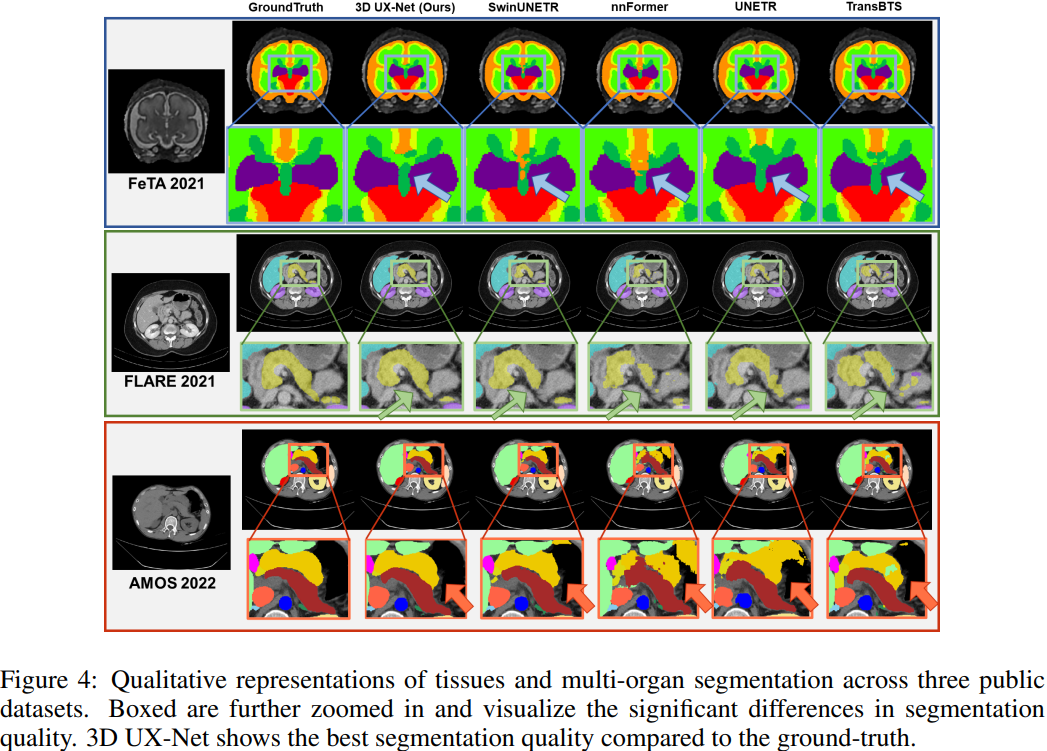
可以看到,與 GT 相比,3D UX-Net器官和組織的形態得到了很好的保存。
與 SOTA 方法的對比
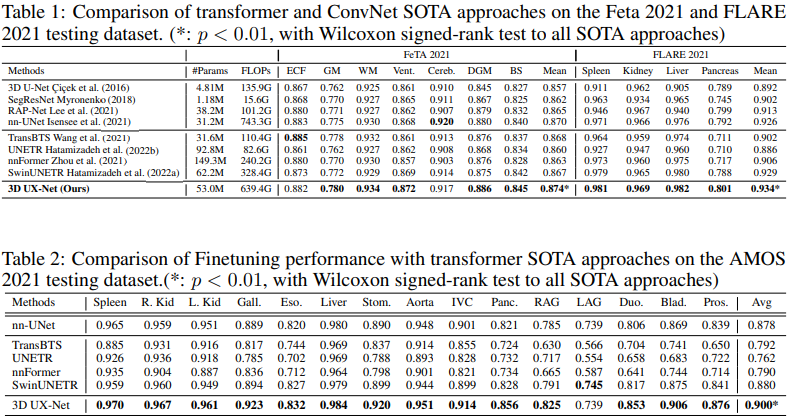
從上述表格可以看出,3D UX-Net 在所有分割任務中均展示出最佳性能,并且 Dice 分數有了顯著提高(FeTA2021:0.870 到 0.874,FLARE2021:0.929 到 0.934)。
總結
本文為大家介紹了 3D UX-Net,這是第一個將分層 Transformer 的特征與用于醫學圖像分割的純 ConvNet 模塊相適應的3D網絡架構。具體地,本文重新設計了具有深度卷積的編碼器塊,以更低的代價實現與 Transformer 想媲美的能力。最后,通過在三個具有挑戰性的公共數據集上進行的廣泛實驗表明所提方法的高效性。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107778 -
圖像分割
+關注
關注
4文章
182瀏覽量
18776 -
數據集
+關注
關注
4文章
1236瀏覽量
26196
原文標題:ICLR 2023 | 3D UX-Net:超強的醫學圖像分割新網絡
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
常見3D打印材料介紹及應用場景分析

探索TLE493D-P3XX-MS2GO 3D 2Go套件:開啟3D磁傳感器評估之旅
iDS iToF Nion 3D相機,開啟高性價比3D視覺新紀元!


玩轉 KiCad 3D模型的使用

季豐電子邀您相約2025國際3D視覺感知與應用大會
iTOF技術,多樣化的3D視覺應用
3D打印能用哪些材質?

TechWiz LCD 3D應用:FFS仿真
【正點原子STM32MP257開發板試用】基于 DeepLab 模型的圖像分割

一種以圖像為中心的3D感知模型BIP3D



 工商網監
工商網監
評論