 國內最大自動駕駛智算中心發布,為何車企紛紛自建智算中心?
國內最大自動駕駛智算中心發布,為何車企紛紛自建智算中心?

電子發燒友網報道(文/李彎彎)前不久,毫末智行與火山引擎共同發布了中國自動駕駛行業最大的智算中心——毫末“雪湖·綠洲”(MANA OASIS)。據毫末智行CEO顧維灝介紹,MANA OASIS的算力高達67億億次/秒,存儲帶寬可達2T/秒,通信帶寬達到800G/秒,可以為自動駕駛技術的持續迭代提供充足動力。
不僅僅是自動駕駛車自身算力,智算中心也成為車企和自動駕駛公司競爭的焦點。眾所周知,自動駕駛行業的領軍企業特斯拉在幾年前就已經建立自己的智算中心,并且還自研芯片以提升效率。國內除了毫末智行,小鵬汽車在今年8月也宣布已經建成自動駕駛智算中心。
多方面優化,MANA OASIS訓練效率提升100倍
結合自動駕駛近十年的發展歷史,毫末智行認為,可以將近十年的自動駕駛技術發展分成三個階段:最早的硬件驅動方式,可以稱為自動駕駛的1.0時代;最近幾年的軟件驅動方式,可稱之為自動駕駛的2.0時代;即將發生,并將持續發展的數據驅動方式,是自動駕駛的3.0時代。數據驅動也是自動駕駛發展公認的方向,而它對智算中心的要求很高。
因此毫末和火山引擎共同定制了一個屬于自動駕駛的智算中心。具體來看,在系統架構方面,如下圖,左邊是高性能存儲,基于高性能并行文件系統VePFS,可以提供高達2T/s的讀取速度,并且支持百億級小文件高速讀寫。右邊是計算平臺,提供了充沛的算力,每臺服務器配置8個GPU卡,通過600G/s的雙向NVSwitch高速互聯,進行通信。服務器之間通過4張200G帶寬的RDMA網絡互聯,提供高達800G/s的網絡帶寬。
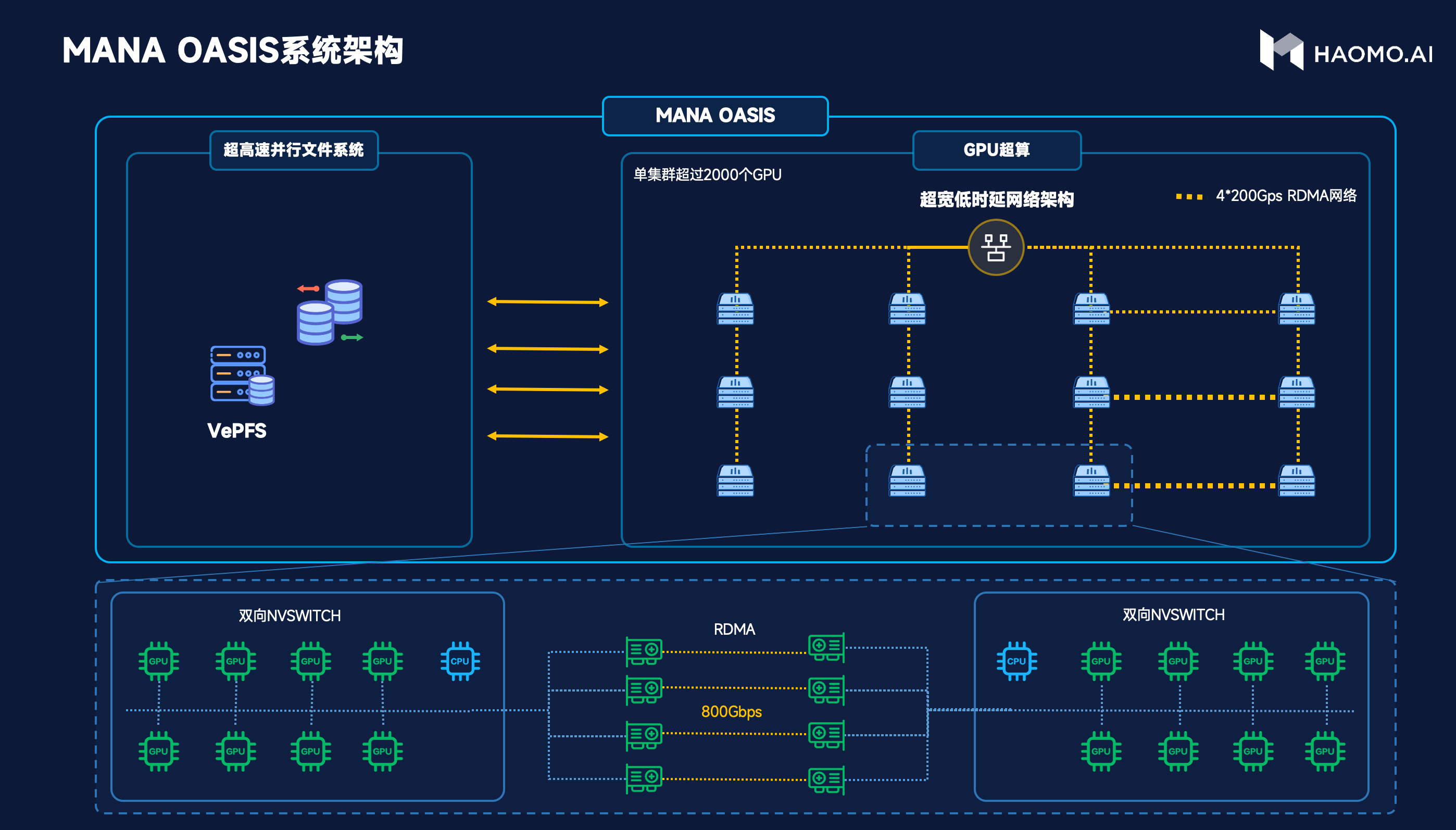
在數據管理上,為了充分發揮智算中心的價值,讓GPU持續飽和運行,毫末經過2年多研發,建立了全套面向大規模AI訓練的毫末文件系統。在采集端,把數據按照訓練的要求,以4D Clip為單位組織文件形態;在傳輸端,基于毫末場景庫,對數據進行場景化分析,打上各類Tag,方便模型基于Tag從不同維度對數據進行采樣、分布統計、語料提取;在訓練端,基于分級存儲理念,把對象存儲、高性能、顯存充分整合,實現高容量與高性能并存。
最終實現了百P數據篩選速度提升10倍、百億小文件隨機讀寫延遲小于500us。在毫末文件系統的加持下,消除數據瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓練加速上也做了大量優化。大家都知道,transformer大模型的訓練成本非常高,訓練一個大模型有時成本高達幾千萬。毫末在此方向深入研究,借鑒了學術界最新的研究成果,基于Sparse MoE,可以根據計算特點,進行稀疏激活,提高計算效率,實現單機8卡就能訓練百億參數大模型的效果。
毫末智算中心也實現了跨機共享expert的方法,完成千億參數規模大模型的訓練,而且訓練成本降低到百卡周級別。在此基礎上,毫末基于自己的業務特點,設計并實現了業界領先的多任務并行訓練系統,能同時處理圖片、點云、結構化文本等多種模態的信息,既保證了模型的稀疏性,又提升了計算效率。結合多方面的優化,毫末智算中心的訓練效率提升了100倍。
為何小鵬、特斯拉等車企要建立自己的智算中心
除了毫末智行,小鵬汽車、特斯拉等車企也已建設自己的智算中心。今年8月,小鵬汽車宣布在烏蘭察布建成當時中國最大的自動駕駛智算中心“扶搖”,用于自動駕駛模型訓練。“扶搖”基于阿里云智能計算平臺,算力可達600PFLOPS(每秒浮點運算60億億次),將小鵬自動駕駛核心模型的訓練速度提升了近170倍。
通過與阿里云合作,“扶搖”以更低成本實現了更強算力。具體來看,對GPU資源進行細粒度切分、調度,將GPU資源虛擬化利用率提高3倍,支持更多人同時在線開發,效率提升十倍以上。在通訊層面,端對端通信延遲降低80%至2微秒。
整體計算效率上,實現了算力的線性擴展。存儲吞吐比業界20GB/s的普遍水準提升了40倍,數據傳輸能力相當于從送快遞的微型面包車,換成了20多米長的40噸集裝箱重卡。此外,阿里云機器學習平臺PAI提供了模型訓練部署、推理優化等AI工程化工具,比開源框架訓練性能提升30%以上。
“扶搖”支持小鵬自動駕駛核心模型的訓練時長從7天,縮短至1小時內,大幅提速近170倍。據介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統的算法模型訓練。和高速道路相比,城市路段的交通狀況更為復雜,自動駕駛特殊場景的數據集規模增加了上百倍。
早幾年前,特斯拉就已經建立了自己的AI計算中心——Dojo,總計使用了1.4萬個英偉達的GPU來訓練AI模型。為了進一步提升效率,特斯拉在2021年發布了自研的AI加速芯片D1,25個D1封裝在一起組成一個訓練模塊(Training tile),然后再將訓練模塊組成一個機柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計算中心的最新進展,用自研的D1芯片打造的計算設備能夠提升30%的模型訓練效率。
可以看到,車企和自動駕駛公司自建智算中心,能夠在性能上進行多方面的優化,提升效率。此外在成本上也會更有利,何小鵬此前談到,對于智能汽車公司來說,算力成本將會從今天的億元級別上升到將來的十億元級別。因此,如果持續使用公有云服務,邊際成本將會不斷上漲。如果自行組建智算中心,一次性投資約在數千萬到1億元以內,長期來看性價比更高。
不僅僅是自動駕駛車自身算力,智算中心也成為車企和自動駕駛公司競爭的焦點。眾所周知,自動駕駛行業的領軍企業特斯拉在幾年前就已經建立自己的智算中心,并且還自研芯片以提升效率。國內除了毫末智行,小鵬汽車在今年8月也宣布已經建成自動駕駛智算中心。
多方面優化,MANA OASIS訓練效率提升100倍
結合自動駕駛近十年的發展歷史,毫末智行認為,可以將近十年的自動駕駛技術發展分成三個階段:最早的硬件驅動方式,可以稱為自動駕駛的1.0時代;最近幾年的軟件驅動方式,可稱之為自動駕駛的2.0時代;即將發生,并將持續發展的數據驅動方式,是自動駕駛的3.0時代。數據驅動也是自動駕駛發展公認的方向,而它對智算中心的要求很高。
因此毫末和火山引擎共同定制了一個屬于自動駕駛的智算中心。具體來看,在系統架構方面,如下圖,左邊是高性能存儲,基于高性能并行文件系統VePFS,可以提供高達2T/s的讀取速度,并且支持百億級小文件高速讀寫。右邊是計算平臺,提供了充沛的算力,每臺服務器配置8個GPU卡,通過600G/s的雙向NVSwitch高速互聯,進行通信。服務器之間通過4張200G帶寬的RDMA網絡互聯,提供高達800G/s的網絡帶寬。
在數據管理上,為了充分發揮智算中心的價值,讓GPU持續飽和運行,毫末經過2年多研發,建立了全套面向大規模AI訓練的毫末文件系統。在采集端,把數據按照訓練的要求,以4D Clip為單位組織文件形態;在傳輸端,基于毫末場景庫,對數據進行場景化分析,打上各類Tag,方便模型基于Tag從不同維度對數據進行采樣、分布統計、語料提取;在訓練端,基于分級存儲理念,把對象存儲、高性能、顯存充分整合,實現高容量與高性能并存。
最終實現了百P數據篩選速度提升10倍、百億小文件隨機讀寫延遲小于500us。在毫末文件系統的加持下,消除數據瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓練加速上也做了大量優化。大家都知道,transformer大模型的訓練成本非常高,訓練一個大模型有時成本高達幾千萬。毫末在此方向深入研究,借鑒了學術界最新的研究成果,基于Sparse MoE,可以根據計算特點,進行稀疏激活,提高計算效率,實現單機8卡就能訓練百億參數大模型的效果。
毫末智算中心也實現了跨機共享expert的方法,完成千億參數規模大模型的訓練,而且訓練成本降低到百卡周級別。在此基礎上,毫末基于自己的業務特點,設計并實現了業界領先的多任務并行訓練系統,能同時處理圖片、點云、結構化文本等多種模態的信息,既保證了模型的稀疏性,又提升了計算效率。結合多方面的優化,毫末智算中心的訓練效率提升了100倍。
為何小鵬、特斯拉等車企要建立自己的智算中心
除了毫末智行,小鵬汽車、特斯拉等車企也已建設自己的智算中心。今年8月,小鵬汽車宣布在烏蘭察布建成當時中國最大的自動駕駛智算中心“扶搖”,用于自動駕駛模型訓練。“扶搖”基于阿里云智能計算平臺,算力可達600PFLOPS(每秒浮點運算60億億次),將小鵬自動駕駛核心模型的訓練速度提升了近170倍。
通過與阿里云合作,“扶搖”以更低成本實現了更強算力。具體來看,對GPU資源進行細粒度切分、調度,將GPU資源虛擬化利用率提高3倍,支持更多人同時在線開發,效率提升十倍以上。在通訊層面,端對端通信延遲降低80%至2微秒。
整體計算效率上,實現了算力的線性擴展。存儲吞吐比業界20GB/s的普遍水準提升了40倍,數據傳輸能力相當于從送快遞的微型面包車,換成了20多米長的40噸集裝箱重卡。此外,阿里云機器學習平臺PAI提供了模型訓練部署、推理優化等AI工程化工具,比開源框架訓練性能提升30%以上。
“扶搖”支持小鵬自動駕駛核心模型的訓練時長從7天,縮短至1小時內,大幅提速近170倍。據介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統的算法模型訓練。和高速道路相比,城市路段的交通狀況更為復雜,自動駕駛特殊場景的數據集規模增加了上百倍。
早幾年前,特斯拉就已經建立了自己的AI計算中心——Dojo,總計使用了1.4萬個英偉達的GPU來訓練AI模型。為了進一步提升效率,特斯拉在2021年發布了自研的AI加速芯片D1,25個D1封裝在一起組成一個訓練模塊(Training tile),然后再將訓練模塊組成一個機柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計算中心的最新進展,用自研的D1芯片打造的計算設備能夠提升30%的模型訓練效率。
可以看到,車企和自動駕駛公司自建智算中心,能夠在性能上進行多方面的優化,提升效率。此外在成本上也會更有利,何小鵬此前談到,對于智能汽車公司來說,算力成本將會從今天的億元級別上升到將來的十億元級別。因此,如果持續使用公有云服務,邊際成本將會不斷上漲。如果自行組建智算中心,一次性投資約在數千萬到1億元以內,長期來看性價比更高。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
自動駕駛
+關注
關注
793文章
14882瀏覽量
179856 -
智算中心
+關注
關注
0文章
115瀏覽量
2539
發布評論請先 登錄
相關推薦
熱點推薦
智算中心彈性擴容與風液混合制冷架構避坑指南
隨著人工智能技術的爆發式增長,智算中心作為支撐AI模型訓練與推理的核心基礎設施,其建設邏輯正在發生深刻變革。維諦技術(Vertiv)作為全球領先的數字基礎設施保障專家,致力于為全球智算中心
算力越高,自動駕駛汽車就會越聰明?
在自動駕駛行業,說起算力,很多人第一反應是“更強就是更好”,更快的芯片、更大的算力池,感覺就可以讓汽車能看得更清楚、做決定更快、更安全。但事實并非如此。對于自動駕駛汽車來說,算力確實重
智能算力為何必須先進存力
作為東數西算戰略的關鍵樞紐,中國移動呼和浩特數據中心不僅是中國移動“4+N+31+X”算力網絡中規模最大、技術最先進、保障最完備的中心節點,
智算IP廣域網助力算力互聯網建設進入快車道
人工智能大模型等應用爆發式發展帶動了智能算力需求激增,全國各地紛紛建設大量智算中心。在迎來新機遇的同時,算力行業也面臨數據安全、提高企業用
車與車之間的群體智能會成為自動駕駛的未來嗎?
在自動駕駛的發展過程中,人們最常提到的是“單車智能”。意思就是,車輛依靠自己的攝像頭、雷達、算法和算力去感知環境、做出決策、完成駕駛。但單車智能能力有限,光靠一輛車“單打獨斗”,必然會
算力賦能未來:自動駕駛如何從科幻駛入現實?
當一輛汽車以120km/h飛馳時,每0.1秒的決策延遲就意味著3.3米的“生死距離”。而現在,自動駕駛車輛能在毫秒間完成剎車、變道甚至緊急避障——這背后,是算力在無聲地重塑人類出行方式。感知系統

為什么自動駕駛企業認準它做 “算力心臟”?智銳通 MM3080Ti MXM 顯卡用實力說話
智銳通 MM3080TIB6-16G MXM 顯卡憑借 “高性能、小尺寸、高可靠” 的核心優勢,為該自動駕駛企業解決了嵌入式場景下的算力適配難題,也為行業提供了 “場景化算力硬件” 的參考方向。

自動駕駛系統的算力越高就越好嗎?
[首發于智駕最前沿微信公眾號]自動駕駛系統的“算力”是指車載計算平臺中用于執行感知、決策、規劃和控制等算法的硬件性能指標。之前給大家分享了算力的概念及作用,從概念上看,算力越強大,就意
施耐德電氣Galaxy VXL UPS助力智算中心發展
隨著智算中心處理數據的規模不斷攀升,其物理基礎關鍵設施所經受的考驗也日益嚴峻,空間之困、功率之壓、散熱之危、可用之艱、AI之難、運維之繁......,面對智算中心發展中的重重難關,基礎
華為數據中心自動駕駛網絡通過EANTC歐洲高級網絡測試中心L4級自智網絡測評
Networking Test Center,簡稱“EANTC”)發布華為數據中心自動駕駛網絡的自智網絡(Autonomous Network,簡稱“AN”)分級測評結果。此次測評結果顯示,華為

新能源車軟件單元測試深度解析:自動駕駛系統視角
的潛在風險增加,尤其是在自動駕駛等安全關鍵系統中。根據ISO 26262標準,自動駕駛系統的安全完整性等級(ASIL-D)要求單點故障率必須低于10^-8/小時,這意味著每小時的故障概率需控制在億
發表于 05-12 15:59
AI將如何改變自動駕駛?
[首發于智駕最前沿微信公眾號]五一假期繼續閑聊一下,還歡迎大家隨意留言,隨著人工智能(AI)的發展,很多車企及自動駕駛供應商正嘗試將AI融入自動駕駛系統,為何大家都在積極推動這一技術?
大算力芯片的生態突圍與算力革命
電子發燒友網報道(文 / 李彎彎)大算力芯片,即具備強大計算能力的集成電路芯片,主要應用于高性能計算(HPC)、人工智能(AI)、數據中心、自動駕駛等需要海量數據并行計算的場景。隨著 AI 與大數
施耐德電氣冷板式液冷CDU產品解決AI智算中心散熱難題
AI“火熱”可謂必然,智算中心卻必須“冷靜”——由于功率密度激增,相比傳統數據中心,智算中心所產生的熱量也在飆升,“制冷”問題必須得到妥善解



 工商網監
工商網監
評論