") K8S三種探針ReadinessProbe、LivenessProbe和StartupProbe之探索
K8S三種探針ReadinessProbe、LivenessProbe和StartupProbe之探索

事件背景
因?yàn)?k8s 中采用大量的異步機(jī)制、以及多種對(duì)象關(guān)系設(shè)計(jì)上的解耦,當(dāng)應(yīng)用實(shí)例數(shù) 增加/刪除、或者應(yīng)用版本發(fā)生變化觸發(fā)滾動(dòng)升級(jí)時(shí),系統(tǒng)并不能保證應(yīng)用相關(guān)的 service、ingress 配置總是及時(shí)能完成刷新。在一些情況下,往往只是新的 Pod 完成自身初始化,系統(tǒng)尚未完成 Endpoint、負(fù)載均衡器等外部可達(dá)的訪問信息刷新,老的 Pod 就立即被刪除,最終造成服務(wù)短暫的額不可用,這對(duì)于生產(chǎn)來說是不可接受的,所以 k8s 就加入了一些存活性探針:StartupProbe、LivenessProbe、ReadinessProbe。
技術(shù)探索
POD 狀態(tài)
Pod 常見的狀態(tài)
Pending:掛起,我們?cè)谡?qǐng)求創(chuàng)建 pod 時(shí),條件不滿足,調(diào)度沒有完成,沒有任何一個(gè)節(jié)點(diǎn)能滿足調(diào)度條件。已經(jīng)創(chuàng)建了但是沒有適合它運(yùn)行的節(jié)點(diǎn)叫做掛起,這其中也包含集群為容器創(chuàng)建網(wǎng)絡(luò),或者下載鏡像的過程。
Running:Pod 內(nèi)所有的容器都已經(jīng)被創(chuàng)建,且至少一個(gè)容器正在處于運(yùn)行狀態(tài)、正在啟動(dòng)狀態(tài)或者重啟狀態(tài)。
Succeeded:Pod 中所以容器都執(zhí)行成功后退出,并且沒有處于重啟的容器。
Failed:Pod 中所以容器都已退出,但是至少還有一個(gè)容器退出時(shí)為失敗狀態(tài)。
Unknown:未知狀態(tài),所謂 pod 是什么狀態(tài)是 apiserver 和運(yùn)行在 pod 節(jié)點(diǎn)的 kubelet 進(jìn)行通信獲取狀態(tài)信息的,如果節(jié)點(diǎn)之上的 kubelet 本身出故障,那么 apiserver 就連不上 kubelet,得不到信息了,就會(huì)看 Unknown 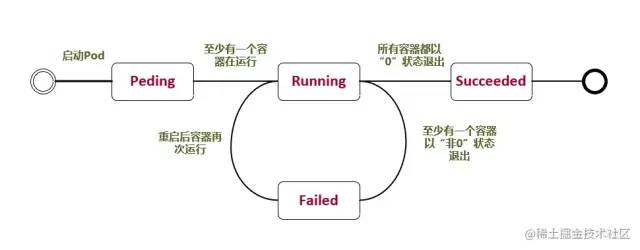
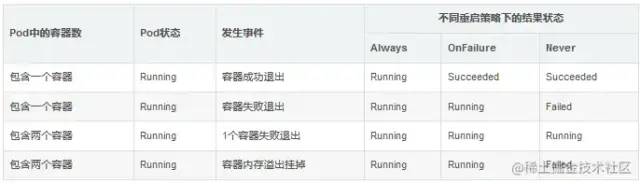
Pod 重啟策略
Always: 只要容器失效退出就重新啟動(dòng)容器。
OnFailure: 當(dāng)容器以非正常(異常)退出后才自動(dòng)重新啟動(dòng)容器。
Never: 無論容器狀態(tài)如何,都不重新啟動(dòng)容器。
Pod 常見狀態(tài)轉(zhuǎn)換場(chǎng)景
探針簡(jiǎn)介
K8S 提供了 3 種探針:
ReadinessProbe
LivenessProbe
StartupProbe(這個(gè) 1.16 版本增加的)
探針存在的目的
在 Kubernetes 中 Pod 是最小的計(jì)算單元,而一個(gè) Pod 又由多個(gè)容器組成,相當(dāng)于每個(gè)容器就是一個(gè)應(yīng)用,應(yīng)用在運(yùn)行期間,可能因?yàn)槟承┮馔馇闆r致使程序掛掉。那么如何監(jiān)控這些容器狀態(tài)穩(wěn)定性,保證服務(wù)在運(yùn)行期間不會(huì)發(fā)生問題,發(fā)生問題后進(jìn)行重啟等機(jī)制,就成為了重中之重的事情,考慮到這點(diǎn) kubernetes 推出了活性探針機(jī)制。有了存活性探針能保證程序在運(yùn)行中如果掛掉能夠自動(dòng)重啟,但是還有個(gè)經(jīng)常遇到的問題,比如說,在 Kubernetes 中啟動(dòng) Pod,顯示明明 Pod 已經(jīng)啟動(dòng)成功,且能訪問里面的端口,但是卻返回錯(cuò)誤信息。還有就是在執(zhí)行滾動(dòng)更新時(shí)候,總會(huì)出現(xiàn)一段時(shí)間,Pod 對(duì)外提供網(wǎng)絡(luò)訪問,但是訪問卻發(fā)生 404,這兩個(gè)原因,都是因?yàn)?Pod 已經(jīng)成功啟動(dòng),但是 Pod 的的容器中應(yīng)用程序還在啟動(dòng)中導(dǎo)致,考慮到這點(diǎn) Kubernetes 推出了就緒性探針機(jī)制。
LivenessProbe:存活性探針,用于判斷容器是不是健康,如果不滿足健康條件,那么 Kubelet 將根據(jù) Pod 中設(shè)置的 restartPolicy (重啟策略)來判斷,Pod 是否要進(jìn)行重啟操作。LivenessProbe 按照配置去探測(cè) ( 進(jìn)程、或者端口、或者命令執(zhí)行后是否成功等等),來判斷容器是不是正常。如果探測(cè)不到,代表容器不健康(可以配置連續(xù)多少次失敗才記為不健康),則 kubelet 會(huì)殺掉該容器,并根據(jù)容器的重啟策略做相應(yīng)的處理。如果未配置存活探針,則默認(rèn)容器啟動(dòng)為通過(Success)狀態(tài)。即探針返回的值永遠(yuǎn)是 Success。即 Success 后 pod 狀態(tài)是 RUNING
ReadinessProbe:就緒性探針,用于判斷容器內(nèi)的程序是否存活(或者說是否健康),只有程序(服務(wù))正常, 容器開始對(duì)外提供網(wǎng)絡(luò)訪問(啟動(dòng)完成并就緒)。容器啟動(dòng)后按照 ReadinessProbe 配置進(jìn)行探測(cè),無問題后結(jié)果為成功即狀態(tài)為 Success。pod 的 READY 狀態(tài)為 true,從 0/1 變?yōu)?1/1。如果失敗繼續(xù)為 0/1,狀態(tài)為 false。若未配置就緒探針,則默認(rèn)狀態(tài)容器啟動(dòng)后為 Success。對(duì)于此 pod、此 pod 關(guān)聯(lián)的 Service 資源、EndPoint 的關(guān)系也將基于 Pod 的 Ready 狀態(tài)進(jìn)行設(shè)置,如果 Pod 運(yùn)行過程中 Ready 狀態(tài)變?yōu)?false,則系統(tǒng)自動(dòng)從 Service 資源 關(guān)聯(lián)的 EndPoint 列表中去除此 pod,屆時(shí) service 資源接收到 GET 請(qǐng)求后,kube-proxy 將一定不會(huì)把流量引入此 pod 中,通過這種機(jī)制就能防止將流量轉(zhuǎn)發(fā)到不可用的 Pod 上。如果 Pod 恢復(fù)為 Ready 狀態(tài)。將再會(huì)被加回 Endpoint 列表。kube-proxy 也將有概率通過負(fù)載機(jī)制會(huì)引入流量到此 pod 中。
StartupProbe: StartupProbe 探針,主要解決在復(fù)雜的程序中 ReadinessProbe、LivenessProbe 探針無法更好地判斷程序是否啟動(dòng)、是否存活。進(jìn)而引入 StartupProbe 探針為 ReadinessProbe、LivenessProbe 探針服務(wù)。
(★)ReadinessProbe 與 LivenessProbe 的區(qū)別
ReadinessProbe 當(dāng)檢測(cè)失敗后,將 Pod 的 IP:Port 從對(duì)應(yīng)的 EndPoint 列表中刪除。
ivenessProbe 當(dāng)檢測(cè)失敗后,將殺死容器并根據(jù) Pod 的重啟策略來決定作出對(duì)應(yīng)的措施。
(★) StartupProbe 與 ReadinessProbe、LivenessProbe 的區(qū)別
如果三個(gè)探針同時(shí)存在,先執(zhí)行 StartupProbe 探針,其他兩個(gè)探針將會(huì)被暫時(shí)禁用,直到 pod 滿足 StartupProbe 探針配置的條件,其他 2 個(gè)探針啟動(dòng),如果不滿足按照規(guī)則重啟容器。另外兩種探針在容器啟動(dòng)后,會(huì)按照配置,直到容器消亡才停止探測(cè),而 StartupProbe 探針只是在容器啟動(dòng)后按照配置滿足一次后,不再進(jìn)行后續(xù)的探測(cè)。
正確的 ReadinessProbe 與 LivenessProbe 使用方式
LivenessProbe 和 ReadinessProbe 兩種探針都支持下面三種探測(cè)方法:
ExecAction:在容器中執(zhí)行指定的命令,如果執(zhí)行成功,退出碼為 0 則探測(cè)成功。
HTTPGetAction:通過容器的 IP 地址、端口號(hào)及路徑調(diào)用 HTTP Get 方法,如果響應(yīng)的狀態(tài)碼大于等于 - 200 且小于 400,則認(rèn)為容器健康。
TCPSocketAction:通過容器的 IP 地址和端口號(hào)執(zhí)行 TCP 檢 查,如果能夠建立 TCP 連接,則表明容器健康。
探針探測(cè)結(jié)果有以下值:
Success:表示通過檢測(cè)。
Failure:表示未通過檢測(cè)。
Unknown:表示檢測(cè)沒有正常進(jìn)行。
LivenessProbe 和 ReadinessProbe 兩種探針的相關(guān)屬性 探針(Probe)有許多可選字段,可以用來更加精確的控制 Liveness 和 Readiness 兩種探針的行為(Probe):
initialDelaySeconds:容器啟動(dòng)后要等待多少秒后就探針開始工作,單位“秒”,默認(rèn)是 0 秒,最小值是 0
periodSeconds:執(zhí)行探測(cè)的時(shí)間間隔(單位是秒),默認(rèn)為 10s,單位“秒”,最小值是 1
timeoutSeconds:探針執(zhí)行檢測(cè)請(qǐng)求后,等待響應(yīng)的超時(shí)時(shí)間,默認(rèn)為 1s,單位“秒”,最小值是 1
successThreshold:探針檢測(cè)失敗后認(rèn)為成功的最小連接成功次數(shù),默認(rèn)為 1s,在 Liveness 探針中必須為 1s,最小值為 1s。
failureThreshold:探測(cè)失敗的重試次數(shù),重試一定次數(shù)后將認(rèn)為失敗,在 readiness 探針中,Pod 會(huì)被標(biāo)記為未就緒,默認(rèn)為 3s,最小值為 1s
Tips:initialDelaySeconds 在 ReadinessProbe 其實(shí)可以不用配置,不配置默認(rèn) pod 剛啟動(dòng),開始進(jìn)行 ReadinessProbe 探測(cè),但那又怎么樣,除了 StartupProbe,ReadinessProbe、LivenessProbe 運(yùn)行在 pod 的整個(gè)生命周期,剛啟動(dòng)的時(shí)候 ReadinessProbe 檢測(cè)失敗了,只不過顯示 READY 狀態(tài)一直是 0/1,ReadinessProbe 失敗并不會(huì)導(dǎo)致重啟 pod,只有 StartupProbe、LivenessProbe 失敗才會(huì)重啟 pod。而等到多少 s 后,真正服務(wù)啟動(dòng)后,檢查 success 成功后,READY 狀態(tài)自然正常
正確的 StartupProbe 使用方式
StartupProbe 探針支持下面三種探測(cè)方法:
ExecAction:在容器中執(zhí)行指定的命令,如果執(zhí)行成功,退出碼為 0 則探測(cè)成功。
HTTPGetAction:通過容器的 IP 地址、端口號(hào)及路徑調(diào)用 HTTP Get 方法,如果響應(yīng)的狀態(tài)碼大于等于 200 且小于 400,則認(rèn)為容器 健康。
TCPSocketAction:通過容器的 IP 地址和端口號(hào)執(zhí)行 TCP 檢 查,如果能夠建立 TCP 連接,則表明容器健康。
探針探測(cè)結(jié)果有以下值:
Success:表示通過檢測(cè)。
Failure:表示未通過檢測(cè)。
Unknown:表示檢測(cè)沒有正常進(jìn)行。
StartupProbe 探針屬性
initialDelaySeconds:容器啟動(dòng)后要等待多少秒后就探針開始工作,單位“秒”,默認(rèn)是 0 秒,最小值是 0
periodSeconds:執(zhí)行探測(cè)的時(shí)間間隔(單位是秒),默認(rèn)為 10s,單位“秒”,最小值是 1
timeoutSeconds:探針執(zhí)行檢測(cè)請(qǐng)求后,等待響應(yīng)的超時(shí)時(shí)間,默認(rèn)為 1s,單位“秒”,最小值是 1
successThreshold:探針檢測(cè)失敗后認(rèn)為成功的最小連接成功次數(shù),默認(rèn)為 1s,在 Liveness 探針中必須為 1s,最小值為 1s。
failureThreshold:探測(cè)失敗的重試次數(shù),重試一定次數(shù)后將認(rèn)為失敗,在 readiness 探針中,Pod 會(huì)被標(biāo)記為未就緒,默認(rèn)為 3s,最小值為 1s
Tips:在 StartupProbe 執(zhí)行完之后,其他 2 種探針的所有配置才全部啟動(dòng),相當(dāng)于容器剛啟動(dòng)的時(shí)候,所以其他 2 種探針如果配置了 initialDelaySeconds,建議不要給太長(zhǎng)。
使用舉例
LivenessProbe 探針使用示例
通過 exec 方式做健康探測(cè)
[root@localhost~]#vimliveness-exec.yaml
apiVersion:v1 kind:Pod metadata: name:liveness-exec labels: app:liveness spec: containers: -name:liveness image:busybox args:#創(chuàng)建測(cè)試探針探測(cè)的文件 -/bin/sh --c -touch/tmp/healthy;sleep30;rm-rf/tmp/healthy;sleep600 LivenessProbe: initialDelaySeconds:10#延遲檢測(cè)時(shí)間 periodSeconds:5#檢測(cè)時(shí)間間隔 exec:#使用命令檢查 command:#指令,類似于運(yùn)行命令sh -cat#sh后的第一個(gè)內(nèi)容,直到需要輸入空格,變成下一行 -/tmp/healthy#由于不能輸入空格,需要另外聲明,結(jié)果為shcat"空格"/tmp/healthy
思路整理:
容器在初始化后,執(zhí)行(/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600")首先創(chuàng)建一個(gè) /tmp/healthy 文件,然后執(zhí)行睡眠命令,睡眠 30 秒,到時(shí)間后執(zhí)行刪除 /tmp/healthy 文件命令。而設(shè)置的存活探針檢檢測(cè)方式為執(zhí)行 shell 命令,用 cat 命令輸出 healthy 文件的內(nèi)容,如果能成功執(zhí)行這條命令一次(默認(rèn) successThreshold:1),存活探針就認(rèn)為探測(cè)成功,由于沒有配置(failureThreshold、timeoutSeconds),所以執(zhí)行(cat /tmp/healthy)并只等待 1s,如果 1s 內(nèi)執(zhí)行后返回失敗,探測(cè)失敗。在前 30 秒內(nèi),由于文件存在,所以存活探針探測(cè)時(shí)執(zhí)行 cat /tmp/healthy 命令成功執(zhí)行。30 秒后 healthy 文件被刪除,所以執(zhí)行命令失敗,Kubernetes 會(huì)根據(jù) Pod 設(shè)置的重啟策略來判斷,是否重啟 Pod。
通過 HTTP 方式做健康探測(cè)
[root@localhost~]#viliveness-http.yaml
apiVersion:v1 kind:Pod metadata: name:liveness-http labels: test:liveness spec: containers: -name:liveness image:test.com/test-http-prober:v0.0.1 LivenessProbe: failureThreshold:5#檢測(cè)失敗5次表示未就緒 initialDelaySeconds:20#延遲加載時(shí)間 periodSeconds:10#重試時(shí)間間隔 timeoutSeconds:5#超時(shí)時(shí)間設(shè)置 successThreshold:2#檢查成功為2次表示就緒 httpGet: scheme:HTTP port:8081 path:/ping
思路整理:在 pod 啟動(dòng)后,初始化等待 20s 后,LivenessProbe 開始工作,去請(qǐng)求 http://Pod_IP:8081/ping 接口,類似于 curl -I http://Pod_IP:8081/ping 接口,考慮到請(qǐng)求會(huì)有延遲(curl -I 后一直出現(xiàn)假死狀態(tài)),所以給這次請(qǐng)求操作一直持續(xù) 5s,如果 5s 內(nèi)訪問返回?cái)?shù)值在>=200 且<=400 代表第一次檢測(cè) success,如果是其他的數(shù)值,或者 5s 后還是假死狀態(tài),執(zhí)行類似(ctrl+c)中斷,并反回 failure 失敗。等待 10s 后,再一次地去請(qǐng)求 http://Pod_IP:8081/ping 接口。如果有連續(xù)的 2 次都是 success,代表無問題。如果期間有連續(xù)的 5 次都是 failure,代表有問題,直接重啟 pod,此操作會(huì)伴隨 pod 的整個(gè)生命周期。Tips Http Get 探測(cè)方式有如下可選的控制字段:
scheme: 用于連接 host 的協(xié)議,默認(rèn)為 HTTP。host:要連接的主機(jī)名,默認(rèn)為 Pod IP,可以在 Http Request headers 中設(shè)置 host 頭部。port:容器上要訪問端口號(hào)或名稱。path:http 服務(wù)器上的訪問 URI。httpHeaders:自定義 HTTP 請(qǐng)求 headers,HTTP 允許重復(fù) headers。
通過 TCP 方式做健康探測(cè)
[root@localhost~]#viliveness-tcp.yaml
apiVersion:v1 kind:Pod metadata: name:liveness-tcp labels: app:liveness spec: containers: -name:liveness image:nginx LivenessProbe: initialDelaySeconds:15 periodSeconds:20 tcpSocket: port:80
思路整理:TCP 檢查方式和 HTTP 檢查方式非常相似,在容器啟動(dòng) initialDelaySeconds 參數(shù)設(shè)定的時(shí)間后,kubelet 將發(fā)送第一個(gè) LivenessProbe 探針,嘗試連接容器的 80 端口,類似于 telnet 80 端口。每隔 20 秒(periodSeconds)做探測(cè),如果連接失敗則將殺死 Pod 重啟容器。
ReadinessProbe 探針使用示例
ReadinessProbe 探針使用方式和 LivenessProbe 探針探測(cè)方法一樣,也是支持三種,只是一個(gè)是用于探測(cè)應(yīng)用的存活,一個(gè)是判斷是否對(duì)外提供流量的條件。
[root@localhost~]#vimreadiness-exec.yaml
apiVersion:v1 kind:Pod metadata: name:readiness-exec labels: app:readiness-exec spec: containers: -name:readiness-exec image:busybox args:#創(chuàng)建測(cè)試探針探測(cè)的文件 -/bin/sh --c -touch/tmp/healthy;sleep30;rm-rf/tmp/healthy;sleep600 LivenessProbe: initialDelaySeconds:10 periodSeconds:5 exec: command: -cat -/tmp/healthy --- apiVersion:v1 kind:Pod metadata: name:readiness-http labels: app:readiness-http spec: containers: -name:readiness-http image:test.com/test-http-prober:v0.0.1 ports: -name:server containerPort:8080 -name:management containerPort:8081 ReadinessProbe: initialDelaySeconds:20 periodSeconds:5 timeoutSeconds:10 httpGet: scheme:HTTP port:8081 path:/ping --- apiVersion:v1 kind:Pod metadata: name:readiness-tcp labels: app:readiness-tcp spec: containers: -name:readiness-tcp image:nginx LivenessProbe: initialDelaySeconds:15 periodSeconds:20 tcpSocket: port:80
這里說說 terminationGracePeriodSeconds
terminationGracePeriodSeconds 這個(gè)參數(shù)非常的重要,具體講解。請(qǐng)參考我的另外一篇文章《詳細(xì)解讀 Kubernetes 中 Pod 優(yōu)雅退出,幫你解決大問題》, 里面有詳細(xì)的解釋,我這里說下其他的內(nèi)容。
Tips: terminationGracePeriodSeconds 不能用于 ReadinessProbe,如果將它應(yīng)用于 ReadinessProbe 將會(huì)被 apiserver 接口所拒絕
LivenessProbe: httpGet: path:/ping port:liveness-port failureThreshold:1 periodSeconds:30 terminationGracePeriodSeconds:30#寬限時(shí)間30s
StartupProbe 探針使用示例
[root@localhost~]#vimstartup.yaml
apiVersion:v1 kind:Pod metadata: name:startup labels: app:startup spec: containers: -name:startup image:nginx StartupProbe: failureThreshold:3#失敗閾值,連續(xù)幾次失敗才算真失敗 initialDelaySeconds:5#指定的這個(gè)秒以后才執(zhí)行探測(cè) timeoutSeconds:10#探測(cè)超時(shí),到了超時(shí)時(shí)間探測(cè)還沒返回結(jié)果說明失敗 periodSeconds:5#每隔幾秒來運(yùn)行這個(gè) httpGet: path:/test prot:80
思路整理:在容器啟動(dòng) initialDelaySeconds (5 秒) 參數(shù)設(shè)定的時(shí)間后,kubelet 將發(fā)送第一個(gè) StartupProbe 探針,嘗試連接容器的 80 端口。如果連續(xù)探測(cè)失敗沒有超過 3 次 (failureThreshold) ,且每次探測(cè)間隔為 5 秒 (periodSeconds) 和探測(cè)執(zhí)行時(shí)間不超過超時(shí)時(shí)間 10 秒/每次 (timeoutSeconds),則認(rèn)為探測(cè)成功,反之探測(cè)失敗,kubelet 直接殺死 Pod。
總結(jié)
通過對(duì)三種探針的探索,我們能夠得到一句話的總結(jié):理解底層結(jié)構(gòu),能夠最大程度在可用性、安全性,持續(xù)性等方面讓 Pod 達(dá)到最佳工作狀態(tài)。凡事沒有“銀彈”,尤其對(duì)重要的業(yè)務(wù)需要一個(gè)案例一個(gè)解決方案,希望這次的分析能提供給大家開啟一個(gè)思路之門。
審核編輯:湯梓紅
-
探針
+關(guān)注
關(guān)注
4文章
229瀏覽量
21622 -
容器
+關(guān)注
關(guān)注
0文章
531瀏覽量
22965 -
Service
+關(guān)注
關(guān)注
0文章
31瀏覽量
14343 -
POD
+關(guān)注
關(guān)注
0文章
18瀏覽量
6286
原文標(biāo)題:K8S 三種探針 ReadinessProbe、LivenessProbe和StartupProbe 之探索
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
什么是 K8S,如何使用 K8S
OpenStack與K8s結(jié)合的兩種方案的詳細(xì)介紹和比較
Docker不香嗎為什么還要用K8s
簡(jiǎn)單說明k8s和Docker之間的關(guān)系
K8S集群服務(wù)訪問失敗怎么辦 K8S故障處理集錦

mysql部署在k8s上的實(shí)現(xiàn)方案
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
什么是K3s和K8s?K3s和K8s有什么區(qū)別?
k8s生態(tài)鏈包含哪些技術(shù)
k8s云原生開發(fā)要求




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論