 字節跳動基于Iceberg的海量特征存儲實踐
字節跳動基于Iceberg的海量特征存儲實踐

01背景
字節跳動特征存儲痛點
當前行業內的特征存儲整體流程主要分為以下四步:
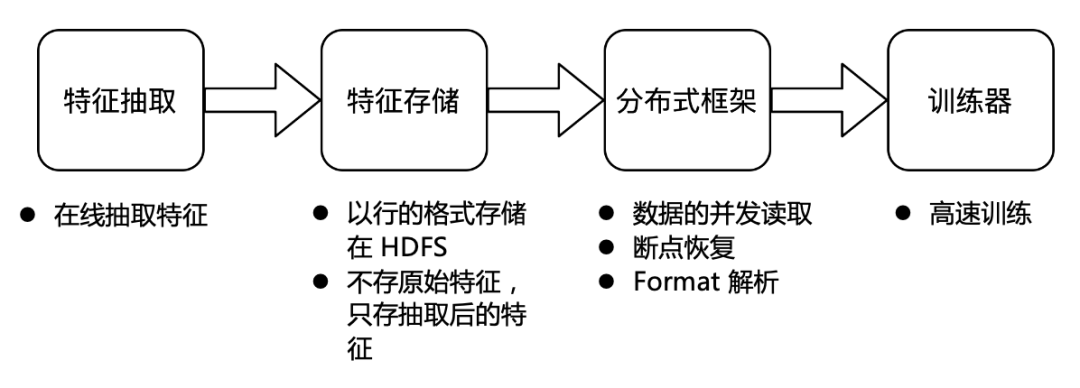
特征存儲的整體流程
業務在線進行特征模塊抽取;
抽取后的特征以行的格式存儲在 HDFS,考慮到成本,此時不存儲原始特征,只存抽取后的特征;
字節跳動自研的分布式框架會將存儲的特征并發讀取并解碼發送給訓練器;
訓練器負責高速訓練。
字節跳動特征存儲總量為 EB 級別,每天的增量達到 PB 級別,并且每天用于訓練的資源也達到了百萬核心,所以整體上字節的存儲和計算的體量都是非常大的。在如此的體量之下,我們遇到了以下三大痛點:
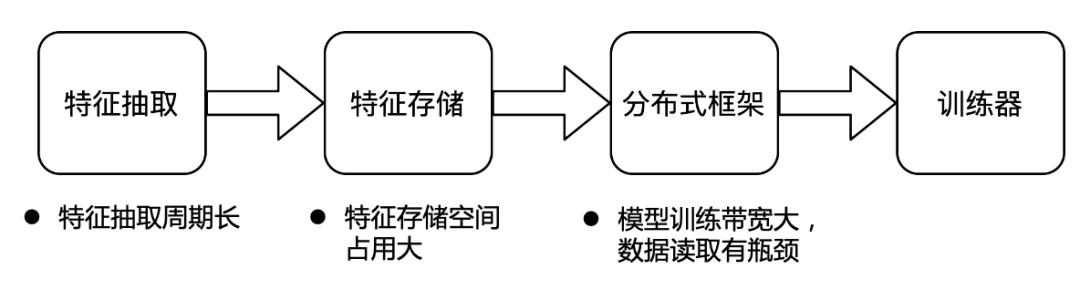
特征抽取周期長。在特征抽取上,當前采用的是在線抽取的方式。大量的算法工程師,每天都在進行大量的特征相關的試驗。在當前的在線抽取模式下,如果有算法工程師想要調研一個新的特征,那么他首先需要定義特征的計算方式,等待在線模塊的統一上線,然后需要等在線抽取的特征積累到一定的量級后才可以進行訓練,從而判斷這個特征是否有效果。這個過程通常需要2周甚至更長的時間。并且,如果發現特征的計算邏輯寫錯或想要更改計算邏輯,則需重復上述過程。在線特征抽取導致當前字節特征調研的效率非常低。基于當前的架構,離線特征調研的成本又非常高。
特征存儲空間占用大。字節的特征存儲當前是以行存的形式進行存儲。如果基于當前的行存做特征調研,則需要基于原來的路徑額外生成新的數據集。一方面需要額外的空間對新的數據集進行存儲,另一方面還需要額外的計算資源去讀取原來的全量數據生成新的數據,且很難做數據的管理和復用。行存對于特征存儲來說,也很難進行優化,占用空間較大。
模型訓練帶寬大,數據讀取有瓶頸。字節當前將每個業務線的絕大部分特征都存儲在一個路徑下,訓練的時候會直接基于這個路徑進行訓練。對于每個模型,訓練所需的特征是不一樣的,每個業務線可能存有上萬個特征,而大部分模型訓練往往只需要幾百個特征,但因為特征是以行存格式進行存儲,所以訓練時需要將上萬特征全部讀取后,再在內存中進行過濾,這就使得模型訓練的帶寬需求非常大,數據的讀取成為了整個訓練的瓶頸。
基于痛點的需求梳理
基于上述問題,我們與業務方一同總結了若干需求:
存儲原始特征:由于在線特征抽取在特征調研上的低效率,我們期望能夠存儲原始特征;
離線調研能力:在原始特征的基礎上,可以進行離線調研,從而提升特征調研效率;
支持特征回填:支持特征回填,在調研完成后,可以將歷史數據全部刷上調研好的特征;
降低存儲成本:充分利用數據分布的特殊性,降低存儲成本,騰出資源來存儲原始特征;
降低訓練成本:訓練時只讀需要的特征,而非全量特征,降低訓練成本;
提升訓練速度:訓練時盡量降低數據的拷貝和序列化反序列化開銷。
02字節跳動海量特征存儲解決方案
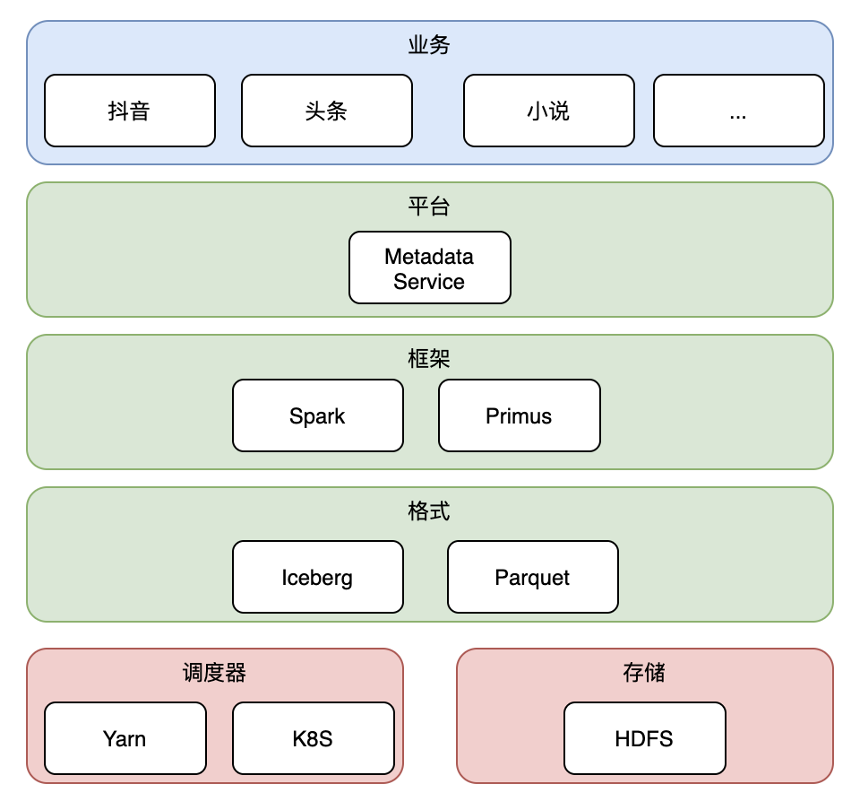
在字節的整體架構中,最上層是業務層,包括抖音、頭條、小說等字節絕大部分業務線;
其下我們通過平臺層,給業務同學提供簡單易用的 UI 和訪問控制等功能;
在框架層,我們使用 Spark 作為特征處理框架(包括預處理和離線特征調研等),字節自研的 Primus 作為訓練框架;
在格式層,我們選用 Parquet 作為文件格式,Iceberg 作為表格式;
最下層是調度器 Yarn & K8s 以及存儲 HDFS。
下面我們重點針對格式層進行詳細介紹。
技術選型

為了滿足業務方提到的6個需求,我們首先想到的是通過 Parquet 列存的格式,降低行存的存儲成本,節省的空間可用來存儲原始特征。同時由于 Parquet 選列可以下推到存儲層的特性,在訓練時可以只讀需要的特征,從而降低訓練時反序列化的成本,提升訓練的速度。
但是使用 Parquet 引入了額外的問題,原來的行存是基于 Protobuf 定義的半結構化數據,不需要預先定義 Schema,而使用 Parquet 以后,我們需要先知道 Schema,然后才能進行數據的存取,那么在特征新增和淘汰時,Schema 的更新就是一個很難解決的問題。Parquet 并不支持數據回填,如果要回填歷史幾年的數據,就需要將數據全量讀取,增加新列,再全量寫回,這一方面會浪費大量的計算資源,另一方面做特征回填時的 overwrite 操作,會導致當前正在進行訓練的任務由于文件被替換而失敗。
為了解決這幾個問題,我們引入了 Iceberg 來支持模式演進、特征回填和并發讀寫。
Iceberg 是適用于大型數據集的一個開源表格式,具備模式演進、隱藏分區&分區演進、事務、MVCC、計算存儲引擎解耦等特性,這些特性匹配了我們所有的需求。因此,我們選擇了 Iceberg 作為我們的數據湖。
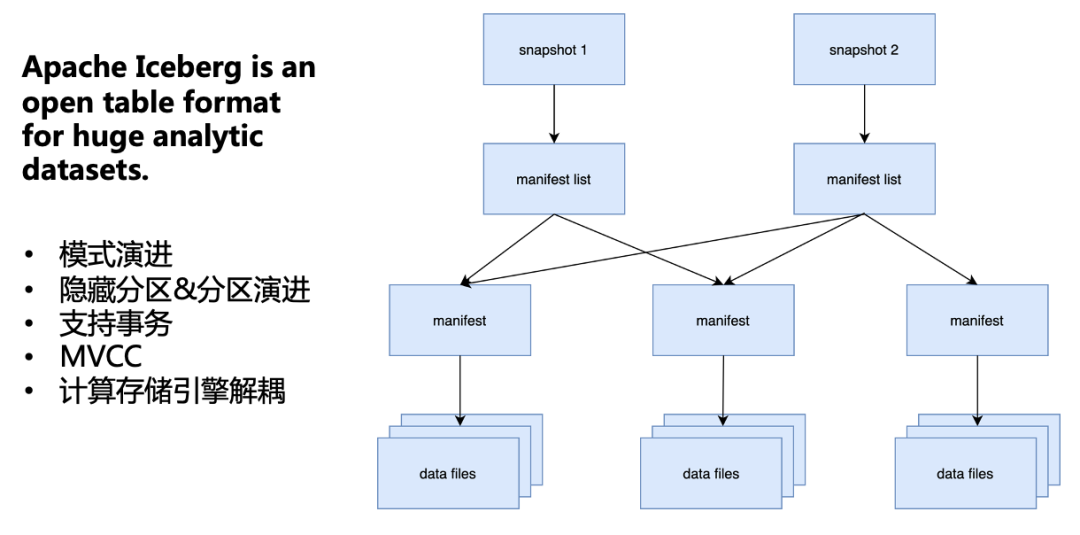
整體上 Iceberg 是一個分層的結構,snapshot 層存儲了當前表的所有快照;manifest list 層存儲了每個快照包含的 manifest 云數據,這一層的用途主要是為了多個 snapshot 可以復用下一層的 manifest;manifest 層,存儲了下層 Data Files 元數據;最下面的 Data File 是就是實際的數據文件。通過這樣的多層結構,Iceberg 可以支持上述包括模式演進等幾個特性。
下面我們來一一介紹 Iceberg 如何支持這些功能。
字節跳動海量特征存儲解決方案
并發讀寫
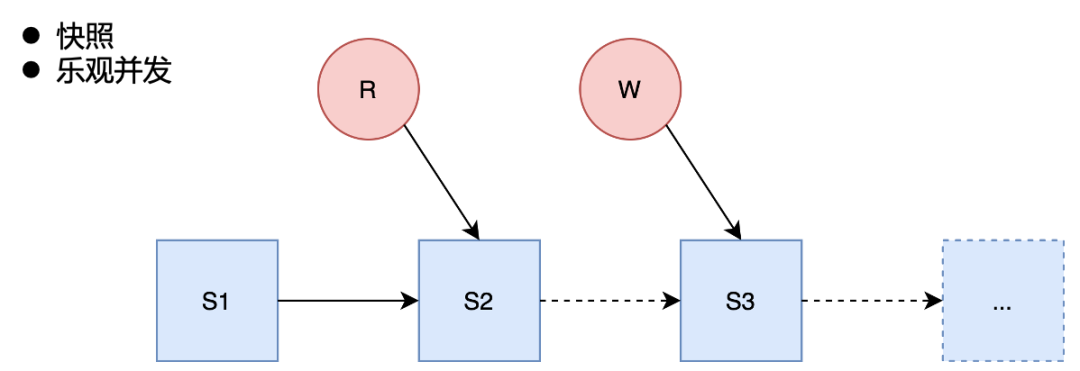
在并發讀取方面,Iceberg 是基于快照的讀取,對 Iceberg 的每個操作都會生成新的快照,不影響正在讀取的快照,從而保證讀寫互不影響。
在并發寫入方面,Iceberg 是采用樂觀并發的方式,利用HDFS mv 的原子性語義保證只有一個能寫入成功,而其他的并發寫入會被檢查是否有沖突,若沒有沖突,則寫入下一個 snapshot。
模式演進
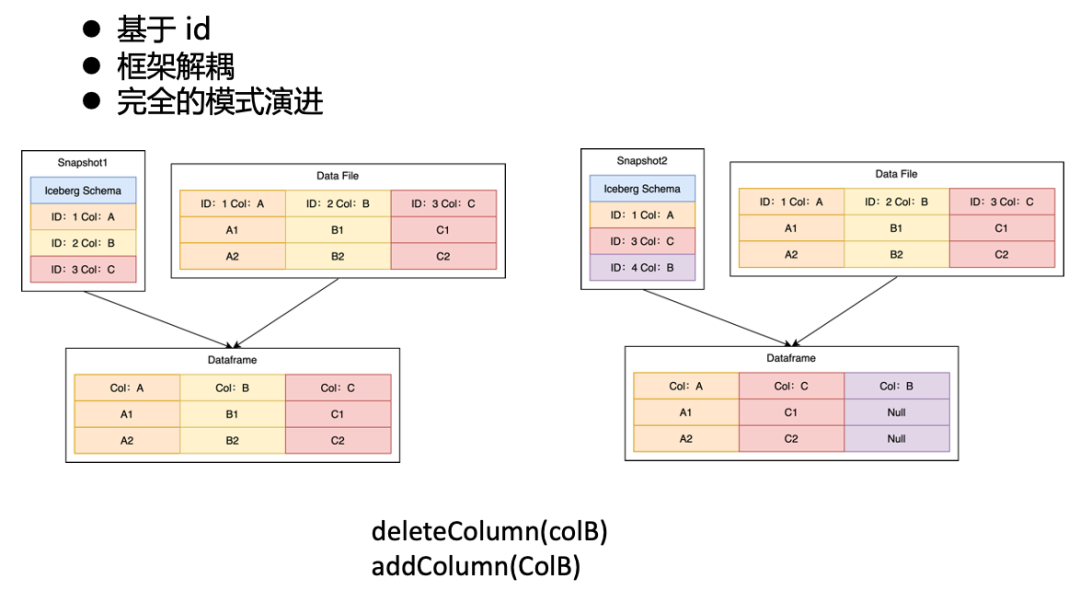
Iceberg 的模式演進原理
我們知道,Iceberg 元數據和 Parquet 元數據都有 Column,而中間的映射關系,是通過 ID 字段來進行一對一映射。
例如上面左圖中,Iceberg 和 Parquet 分別有 ABC 三列,對應 ID 1、2、3。那最終讀取出的 Dataframe 就是 和 Parquet 中一致包含 ID 為1、2、3的 ABC 三列。而當我們對左圖進行兩個操作,刪除舊的 B 列,寫入新的 B 列后, Iceberg 對應的三列 ID 會變成1、3、4,所以右圖中讀出來的 Dataframe,雖然也是 ABC 三列,但是這個 B 列的 ID 并非 Parquet 中 B 列的 ID,因此最終實際的數據中,B 列為空值。
特征回填
寫時復制
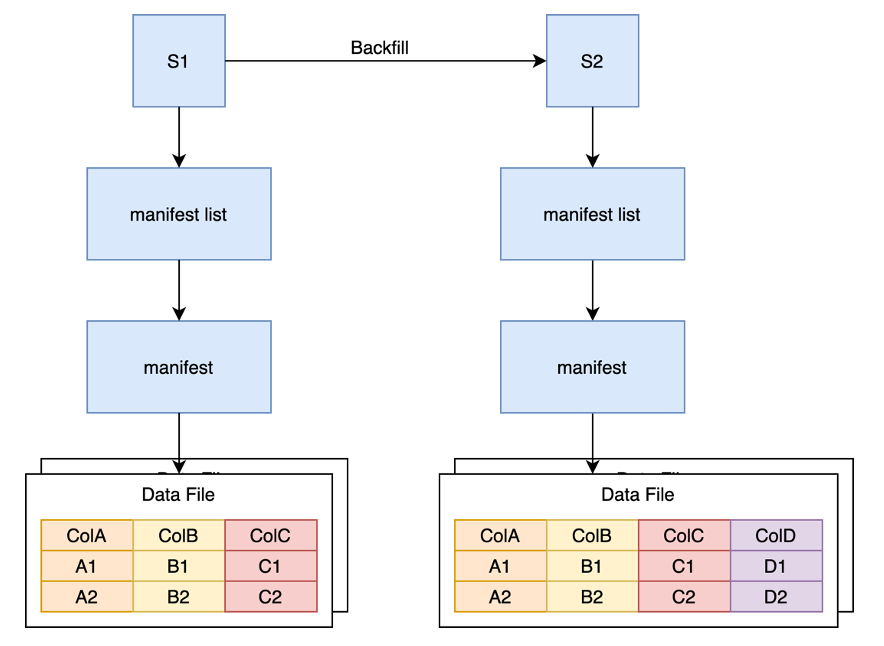
如上圖所示,COW 方式的特征回填通過一個 Backfill 任務將原快照中的數據全部讀出,然后寫入新列,再寫出到新的 Data File 中,并生成新的快照。
這種方式的缺點在于雖然我們只需要寫一列數據,但是需要將整體數據全部讀出,再全部寫回,不僅浪費了大量的計算資源用來對整個 Parquet 文件進行編碼解碼,還浪費了大量的 IO 來讀取全量數據,且浪費了大量的存儲資源來存儲重復的 ABC 列。
因此我們基于開源 Iceberg 自研了 MOR 的 Backfill 方案。
讀時合并
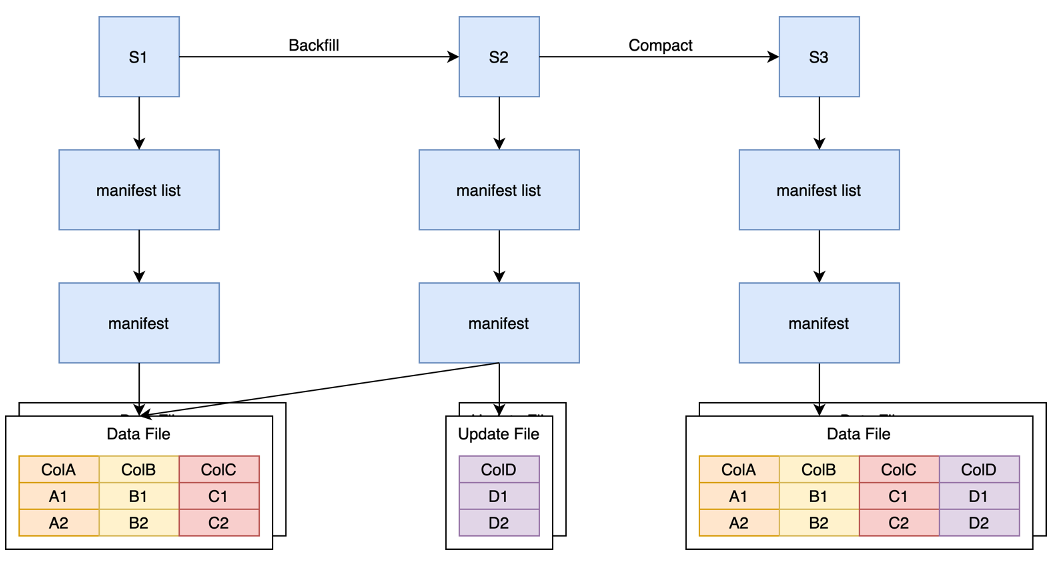
如上圖所示,在 MOR 方案中,我們仍然需要一個 Backfill 任務來讀取原始的 Data File 文件,但是這里我們只讀取需要的字段。比如我們只需要 A 列通過某些計算邏輯生成 D 列,那么 Backfill 任務則只讀取 A 的數據,并且 Snapshot2 中只需要寫包含 D 列的 update 文件。隨著新增列的增多,我們也需要將 Update 文件合并回 Data File 文件中。
為此,我們又提供了 Compaction 邏輯,即讀取舊的 Data File 和 Update File,并合并成一個單獨的 Data File。
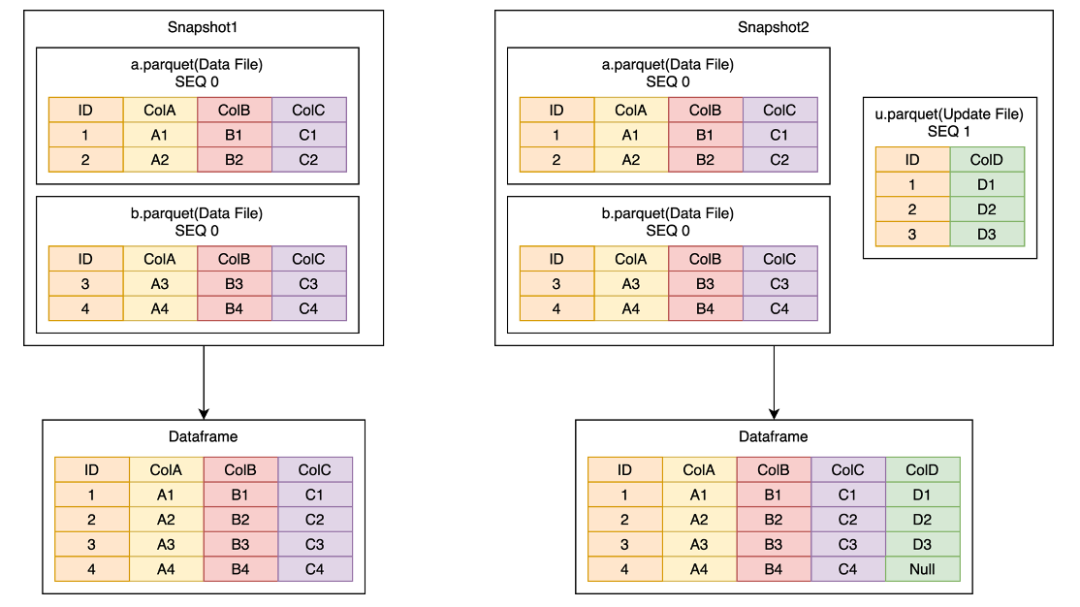
MOR原理如上圖,假設原來有一個邏輯 Dataframe 是由兩個 Data File 構成, 現在需要回填一個 ColD 的內容。我們會寫入一個包含 ColD 的 Update File,這樣 Snapshot2 中的邏輯 Dataframe 就會包含ABCD 四列。
實現細節:
Data File 和 Update File 都需要一個主鍵,并且每個文件都需要按照主鍵排序,在這個例子中是 ID;
讀取時,會根據用戶選擇的列,分析具體需要哪些 Update File 和 Data File;
根據 Data File 中主鍵的 min-max 值去選擇與該 Data File 相對應的 Update File;
MOR 整個過程是多個 Data File 和 Update File 多路歸并的過程;
歸并的順序由 SEQ 來決定,SEQ 大的數據會覆蓋 SEQ 小的數據。
COW 與 MOR 特性比較
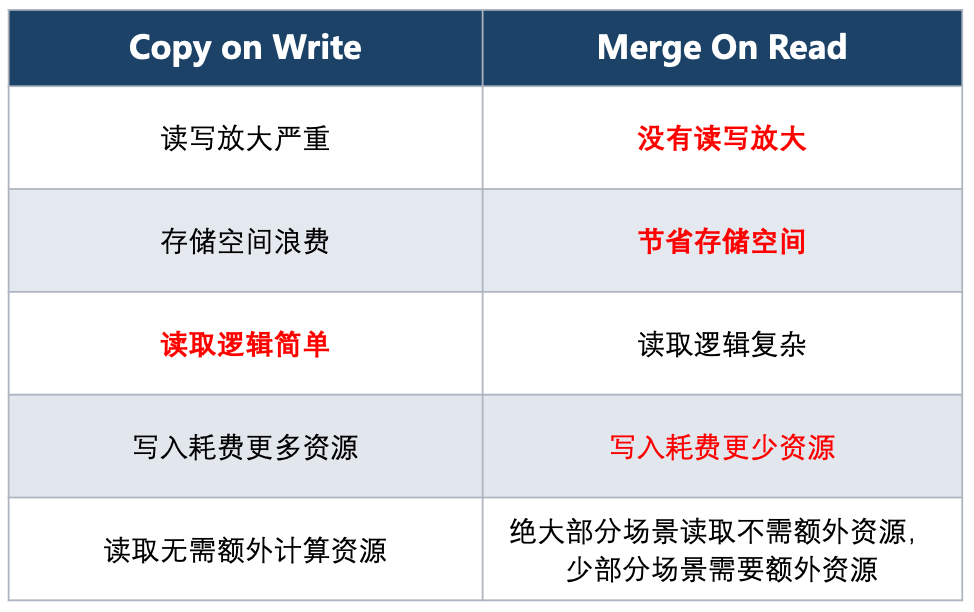
相比于 COW 方式全量讀取和寫入所有列,MOR 的優勢是只讀取需要的列,也只寫入更新的列,沒有讀寫放大問題。在計算上節省了大量的資源,讀寫的 IO 也大大降低,相比 COW 方式每次 COW 都翻倍的情況, MOR 只需要存儲新增列,也大大避免了存儲資源浪費。
考慮到性能的開銷,我們需要定期 Compaction,Compaction 是一個比較重的操作,和 COW 相當。但是 Compaction 是一個異步的過程,可以在多次 MOR 后進行一次 Compaction。那么一次 Compaction 的開銷就可以攤銷到多次 MOR 上,例如10次 COW 和10次 MOR + 1次 Compaction 相比,存儲和讀寫成本都從原來的 10x 降到當前的 2x 。
MOR 的實現成本較高,但這可以通過良好的設計和大量的測試來解決。
而對于模型訓練來說,由于大多數模型訓練只需要自己的列,所以大量的線上模型都不需要走 MOR 的邏輯,可以說基本沒有開銷。而少數的調研模型,往往只需讀自己的 Update File 而不用讀其他的 Update File ,所以整體上讀取的額外資源也并未增加太多。
訓練優化
從行存改為 Iceberg 后,我們也在訓練上也做了大量的優化。
在我們的原始架構中,分布式訓練框架并不解析實際的數據內容,而是直接以行的形式把數據透傳給訓練器,訓練器在內部進行反序列化、選列等操作。
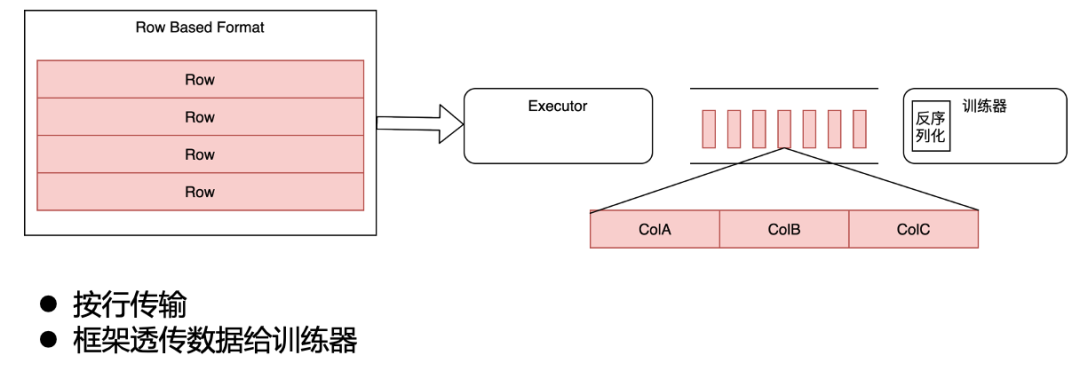
原始架構
引入 Iceberg 后,我們要拿到選列帶來的 CPU 和 IO 收益就需要將選列下推到存儲層。最初為了保證下游訓練器感知不到,我們在訓練框架層面,將選列反序列化后,構造成原來的 ROW 格式,發送給下游訓練器。相比原來,多了一層序列化反序列化的開銷。
這就導致遷移到 Iceberg 后,整體訓練速度反而變慢,資源也增加了。
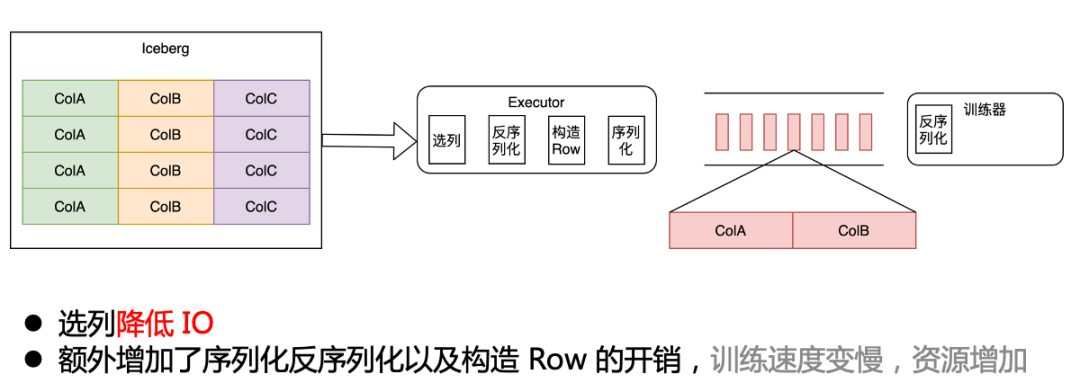
列式改造為了提升訓練速度,我們通過向量化讀取的方式,將 Iceberg 數據直接讀成 Batch 數據,發送給訓練器,這一步提升了訓練速度,并降低了部分資源消耗。
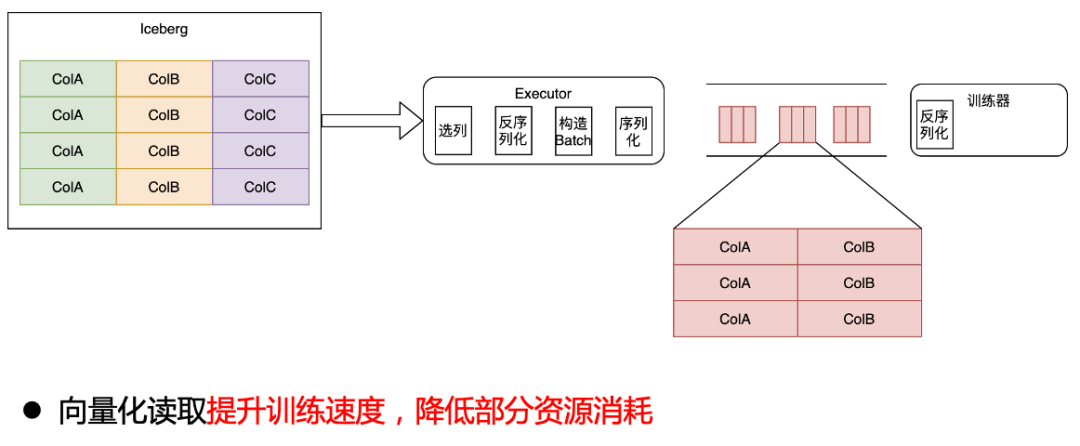
向量化讀取
為了達到最優效果,我們與訓練器團隊合作,直接修改了訓練器內部,使訓練器可以直接識別 Arrow 數據,這樣我們就實現了從 Iceberg 到訓練器端到端的 Arrow 格式打通,這樣只需要在最開始反序列化為 Arrow ,后續的操作就完全基于 Arrow 進行,從而降低了序列化和反序列化開銷,進一步提升訓練速度,降低資源消耗。
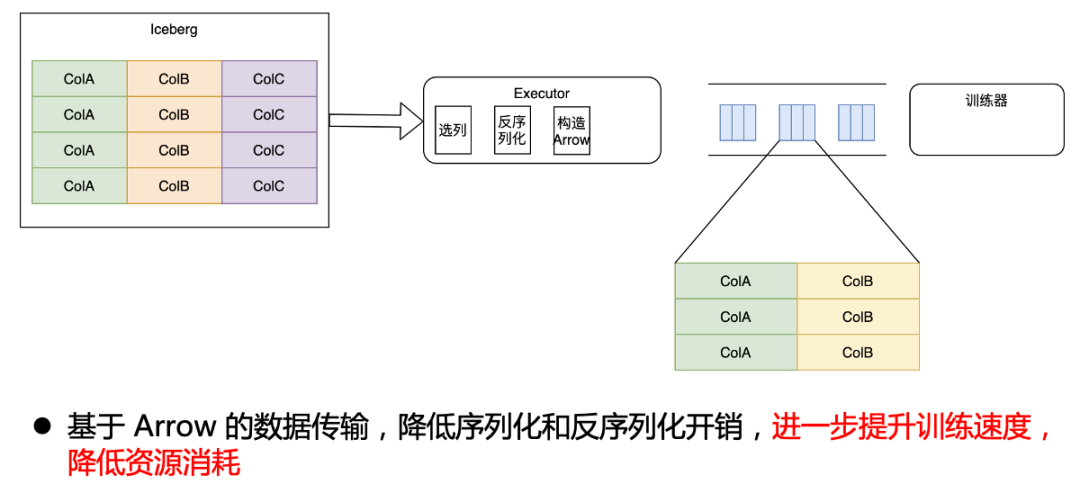
Arrow
優化收益
最終,我們達到了最初的目標,取得了離線特征工程的能力。在存儲成本上,普遍降低了40%以上;在同樣的訓練速度下,CPU 降低了13%,網絡IO 降低40%。
03未來規劃
未來,我們規劃支持以下4種能力:
Upsert 的能力,支持用戶的部分數據回流;
物化視圖的能力,支持用戶在常用的數據集上建立物化視圖,提高讀取效率;
Data Skipping 能力,進一步優化數據排布,下推更多邏輯,進一步優化 IO 和計算資源;
基于 Arrow 的數據預處理能力,向用戶提供良好的數據處理接口,同時將預處理提前預期,進一步加速后續的訓練。
審核編輯:湯梓紅
-
存儲
+關注
關注
13文章
4855瀏覽量
90208 -
訓練器
+關注
關注
0文章
4瀏覽量
6504 -
字節跳動
+關注
關注
0文章
352瀏覽量
10118
原文標題:字節跳動基于Iceberg的海量特征存儲實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
字節跳動全面屏電子設備專利曝光 有望應用于字節跳動旗下堅果手機



 工商網監
工商網監
評論