 采用檢測框架CoP通過控制偏好檢測事實不一致
采用檢測框架CoP通過控制偏好檢測事實不一致

01、研究動機
在生成式摘要任務中,模型基于輸入文檔逐詞生成摘要。隨著深度學習的發展,生成式摘要取得了巨大進展。然而在現在的模型所生成的摘要中,超過70%含有事實不一致錯誤[1]。這些不一致錯誤嚴重限制了生成式摘要的實際應用。要解決這個問題的第一步就是評估摘要的一致性,檢測出不一致錯誤。
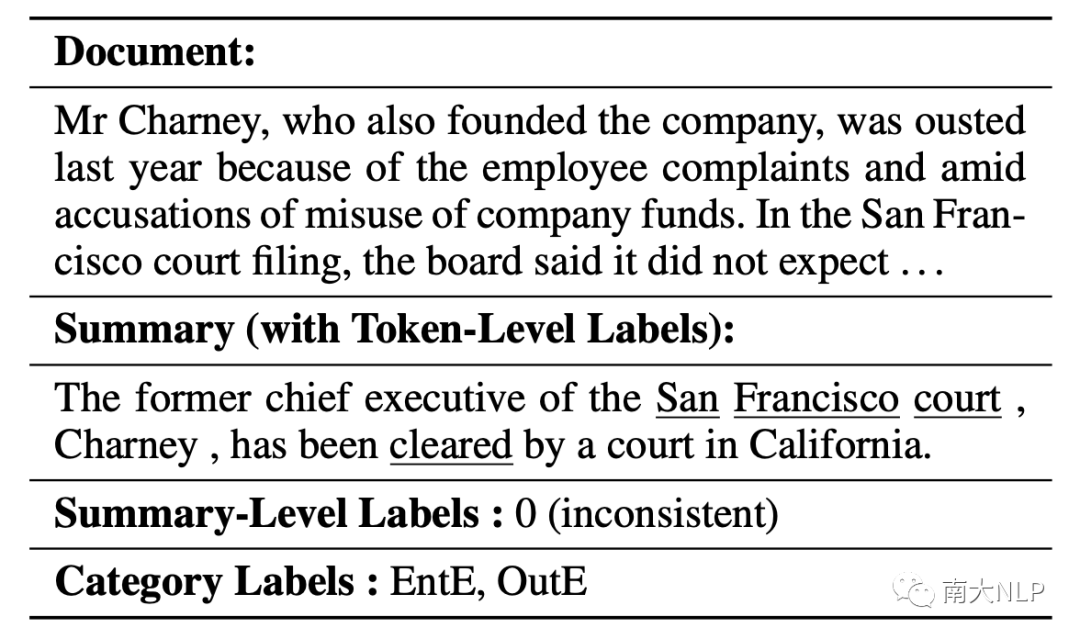
表1:一個多種粒度的事實不一致檢測例子(下劃線標記是詞級別的不一致標注,EntE和OutE是具體不一致類別,對應實體錯誤以及不在原文錯誤)
摘要的生成過程中有兩個因素:文檔X提供重要的事實信息來支持生成一致的摘要內容。同時,在大規模語料上訓練的模型M提供語言先驗知識來保證生成摘要的流暢性。因此摘要中每個詞的生成概率由文檔X和模型M聯合決定。而生成概率正反映了模型對摘要的偏好,對應存在模型對一致摘要的偏好以及對流暢摘要的偏好。這樣的因果關系如圖1(a)所示。
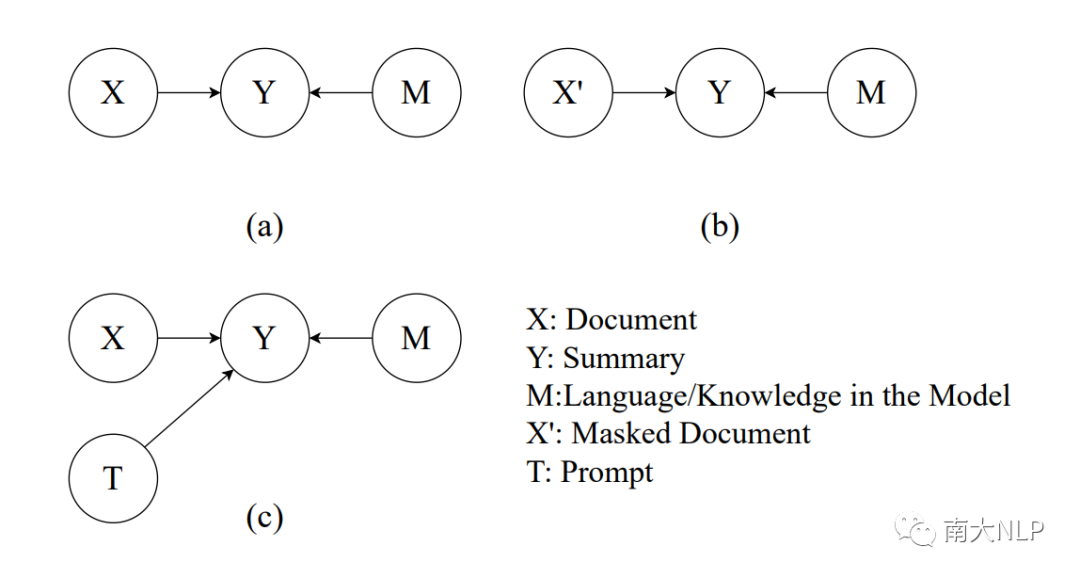
圖1:不同推理過程的示意圖:(a)常規的推理過程,Y的生成由文檔和預訓練模型共同決定;(b) CoCo[3]提出的使用部分Mask文檔的推理過程;(c)我們提出的使用prompt的推理過程。
一致性評估的本質是衡量摘要Y受原文X支持的程度,也就是衡量X到Y的因果效應。直接使用常規推理過程的生成概率(如BARTScore[2])不能夠區分X和M的因果效應,二者的偏好是混雜的。比如一些流暢性很差但是事實一致的摘要會獲得一個較低的生成概率,被誤判為不一致。概率差分方法使用一個額外推理過程來分離偏好。如圖1(b)所示,CoCo[3]使用一個被部分遮蓋(Mask)的文檔作為額外推理的輸入。然而,被遮蓋的文檔天然缺乏流暢性,違背語言先驗知識,評估的過程依然受到和事實一致性無關的偏好影響。除此之外合理且精確的決定遮蓋文檔中哪些詞語也很困難。
02、貢獻
我們提出了一個事實不一致檢測框架CoP,有三個優勢:
在無監督的條件下,利用prompt更好的過濾模型的一致性無關偏好,專注于檢測事實不一致。
可以和prompt tuning結合,高效利用少量標簽數據訓練,進一步提升性能。
通過靈活的設計prompt,不需要額外訓練就可以控制特定的偏好來檢測具體的不一致類別。
實驗結果表明我們的框架CoP在三個事實不一致檢測任務上獲得了SOTA表現,進一步的實驗分析驗證了我們方法的有效性。
03、方法
3.1利用帶prompt的額外推理來控制偏好
我們的框架包括兩個推理過程(圖2)。第一次推理和常見的生成過程是一樣的:利用文檔X作為輸入,并將待測摘要Y輸入解碼器的進行forced-decoding,得到待測摘要Y中每一個詞的生成概率。第二次推理我們將文檔和一個prompt T一起作為輸入,利用類似過程可以得到第二個概率。
我們可以根據實際的應用場景來設計prompt。考慮一個最簡單的情況,我們用待測摘要作為prompt (我們稱這種離散文本prompt為prompt text)。很直觀的,假如待測摘要和輸入文檔事實一致,那么它是一種輸入冗余,因此不會帶來巨大的概率變化。相反的,摘要中的不一致部分會帶來更大的概率變化。換而言之,差分概率更多的由模型對一致性的偏好引起,進而過濾了無關偏好,例如對流暢性的偏好。具體而言我們用第二次推理的概率減去第一次的概率,計算出差分概率。越大的差分概率意味著和原文的不一致程度越高。高于閾值的詞語會被預測為不一致,我們可以根據具體的應用設置閾值來控制預測比例。例如,對于期望更高召回率的不一致改錯任務,可以選擇一個相對低的閾值。
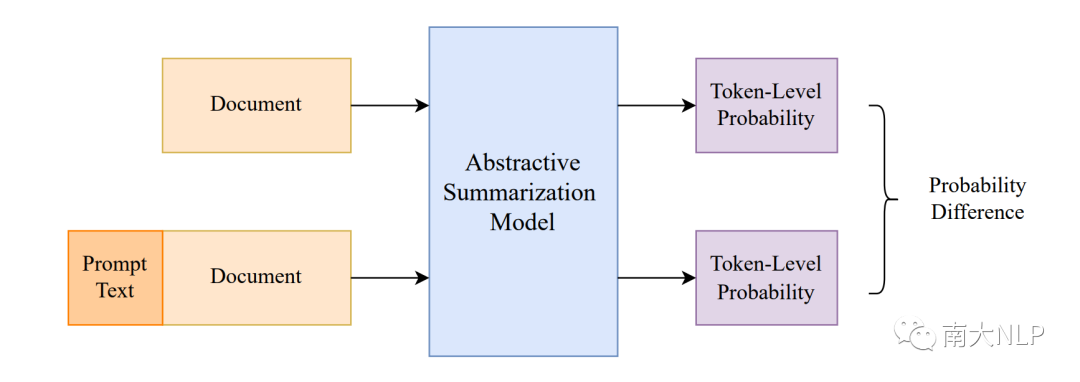
圖2:我們的框架CoP示意圖
3.2、對具體不一致類別設計prompt
先前的工作[4]詳細定義了不一致類型,并統計了類型分布。現有的評估方法往往忽略了這些詳細信息。我們認為能夠檢測不一致類型的評估工具有助于分析現有模型的錯誤傾向、指導未來的研究方向。其中EntE(實體相關不一致), CorefE(指代相關不一致),OutE(不在原文的不一致)相對高頻,分別出現了36%, 10%和27%,我們以它們為例來說明我們框架的工作過程。
最基礎的prompt是整個待測摘要,可以覆蓋摘要里的所有不一致內容,對應的可以解決OutE。而對于檢測其他類別的不一致,我們可以通過添加類別相關的事實信息來針對性控制偏好。對于實體錯誤,我們從摘要里抽取出實體,并把實體列表拼接到prompt text。對于指代錯誤,我們類似的對摘要進行指代消解,并將對應的指代信息插入到代詞的后面。假如生成概率顯著受這些額外的類別相關的事實信息影響,那么我們可以認定這個摘要包含和對應類別相關的不一致。
此時我們仍然獲得的是詞級別的不一致分數,而類別相關的標注往往是摘要級別的。最簡單的方法就是在摘要上對詞級別分數做平均(所有詞語的權重均等)。然而我們的框架可以精細的檢查每一個詞的一致性,包含實體詞和指代詞。我們加倍對應類別詞語的權重,讓模型更專注于該類別的一致性評估。
3.3利用prompt tuning從有限數據中學習
事實一致性的標注數據相當稀缺。得益于我們框架的靈活性,我們可以集成prompt tuning[5],進一步的從有限的標注數據中學習。從離散的詞匯空間中學習prompt text相當困難,因此我們提出了一個小規模的任務相關的連續向量prompt vector。我們希望prompt vector可以幫助模型更好的區分prompt text和輸入文檔,并引導模型在二者之間做精細的事實分析比對,強化對事實一致性的偏好。
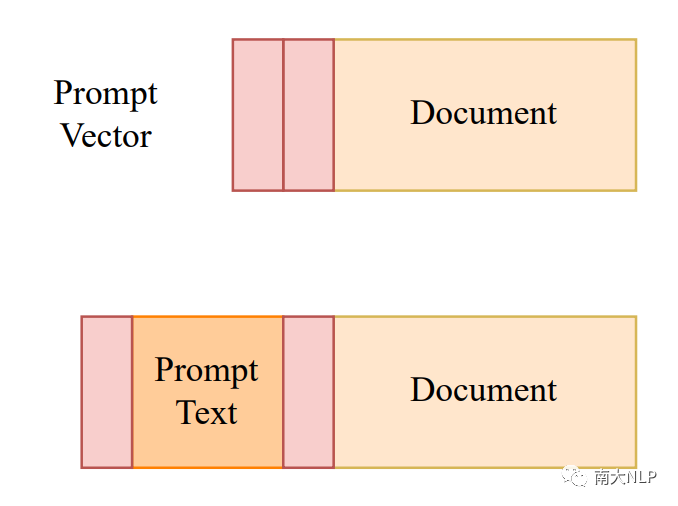
圖3:prompt vector示意圖(使用紅色標出)
如圖3所示,我們在第二次推理中的prompt text前后加上prompt vector。為了保證推理過程的一致性,我們在第一次推理中也保留prompt vector,區別在于第一次推理中沒有prompt text。我們凍結了整個生成模型,僅學習小規模的prompt vector。使用如下的損失函數進行更新參數:
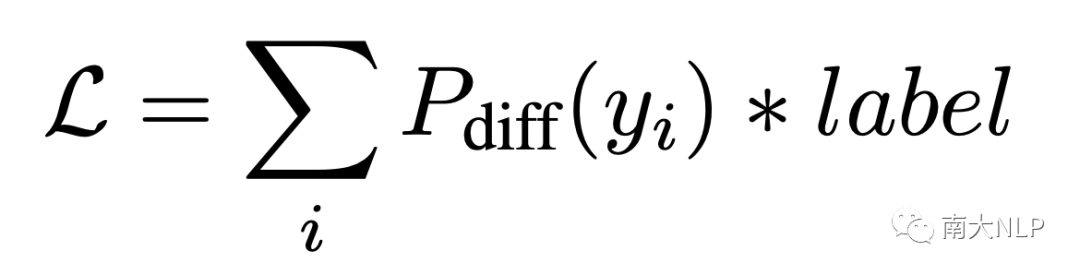
其中label是詞級別的標記,用1和-1表示當前詞是一致和不一致。損失函數將直接優化任務目標:最大化不一致詞語的差分概率,最小化一致詞語的差分概率。
04、實驗
我們在XSum Hallucination Annotations[1],QAGS [6],FRANK [4]三個數據集上進行實驗。XSum Hallucination Annotations數據集提供了詞級別的不一致標簽,0/1分別表示當前詞是一致/不一致。QAGS和FRANK提供了摘要級別的分數來表示一致性,越高的分數代表了越高的一致性。FRANK數據集還提供了不一致類別標簽,同樣用分數表示。我們測試了三個設置下的CoP,分別是不需要訓練的Ours Zero-Shot、使用300條數據訓練的Ours Few-Shot,以及使用1200條數據訓練的Ours Full-Shot。
4.1無監督下檢測不一致
如表2,3所示,我們統計了XSum Hallucination Annotations數據集每一個子集和數據集整體的F1。Ours Zero-Shot效果的效果相當不錯,比起之前表現最好的模型BARTScore[2]提升了4.64,直觀的證明了利用prompt做額外推理去過濾無關偏好的有效性。即便是比起那些使用大量偽數據的方法,Ours Zero-Shot也相當有競爭力,比DAE-Weak[7]提升了4.62。此外,在每一個數據子集上的穩定提升證明了我們的模型有足夠的泛化能力來處理不同模型生成的摘要。
表2:在每一個數據子集上的F1(×100),*代表這個方法不需要訓練
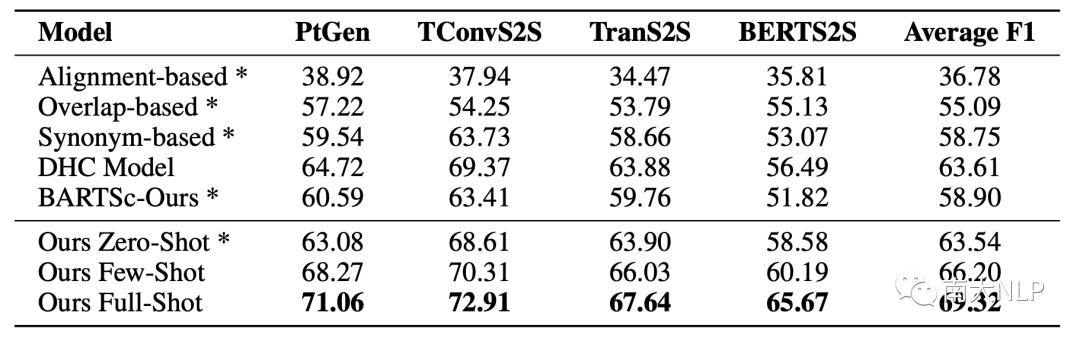
表3:數據集級別的F1(×100),*代表這個方法不需要訓練
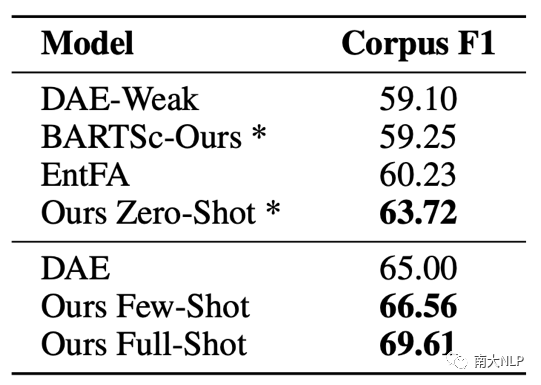
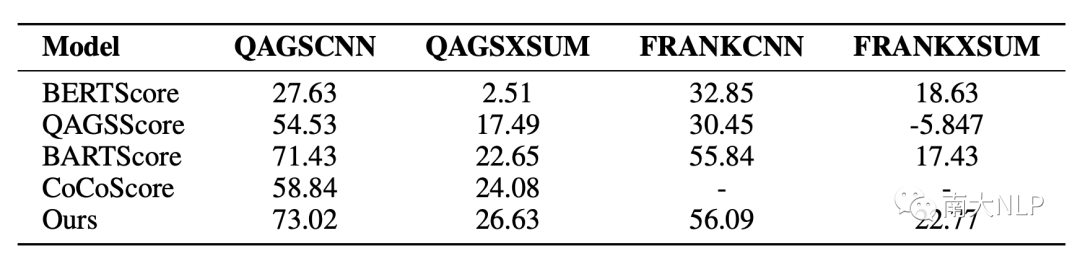
表4展示了在摘要級別上和人工標注分數的Pearson系數,我們的模型在4個數據集上都取得了SOTA。值得注意的是,我們的模型在QAGS-XSUM和FRANK-XSUM上取得了更加顯著的提升,分別比BARTScore提升3.98和5.34。XSUM是一個更加抽象且含有更多噪音的數據集,在XSUM上取得顯著優勢表明CoP能夠更好的分離語言知識偏好,專注于不一致的檢測。
表4:指標評估和人工一致性分數的摘要級別Pearson系數(×100)
4.2結合prompt tuning高效改進性能
我們進一步的在詞級別的不一致檢測任務上驗證prompt tuning的有效性,結果如表2和表3所示。CoP僅僅使用300條真實數據就超過了使用2000條真實數據的DAE以及使用960k偽數據的DHC,達到了SOTA水平。這表明了CoP能夠更加有效的從少量數據中學習。當標記數據增多時,模型的性能也能進一步提升。當我們使用完整的1200條數據訓練時,數據集級別的F1達到69.61,比表現很不錯的Zero-Shot進一步提升9.24%。和使用2000條數據的DAE相比,CoP提升了4.61,展示了更高的學習效率。
4.3具體類別的事實不一致檢測
表5和表6的結果表明Our Base已經超過了之前的工作,證明CoP不僅擅長檢測細粒度的不一致,也能夠很好的檢測具體類別的不一致錯誤,而CoP還可以通過設計和使用多樣的prompt進一步的提升多種不一致類別的檢測結果。值得注意的是這個過程并不需要任何額外訓練。
此外我們還注意到,當我們的模型改進特定不一致類別的檢測結果時,還影響了整體和OutE這兩種不一致類型。我們認為這可能因為(1)EntE是一個相當常見的錯誤,改進這個類別會加強模型對整體不一致程度的評估。(2)各種不一致類別之間也存在聯系,比如EntE和OutE。當模型無法很好的理解原文的實體時,它也很容易產生不在原文的不一致。我們在附錄里進一步討論了不一致類別之間的關系。
表5:指標評估和人工CorefE標注分數的Pearson系數(×100)
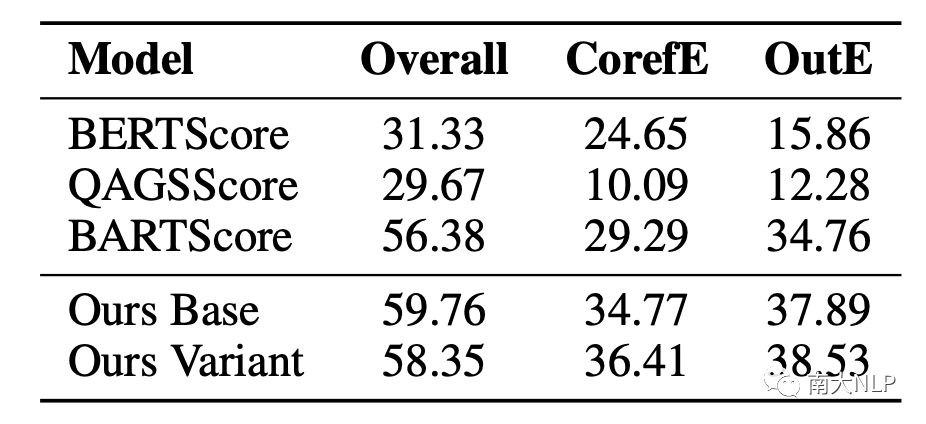
表6:指標評估和人工EntE標注分數的Pearson系數(×100)
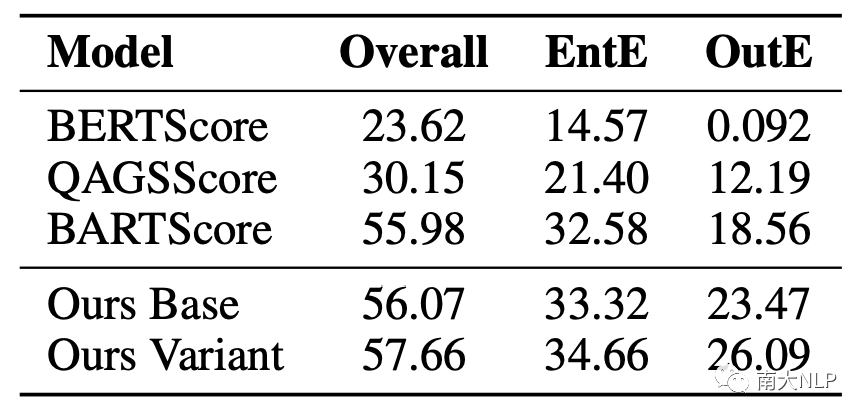
05、分析
5.1不同backbone上的魯棒性
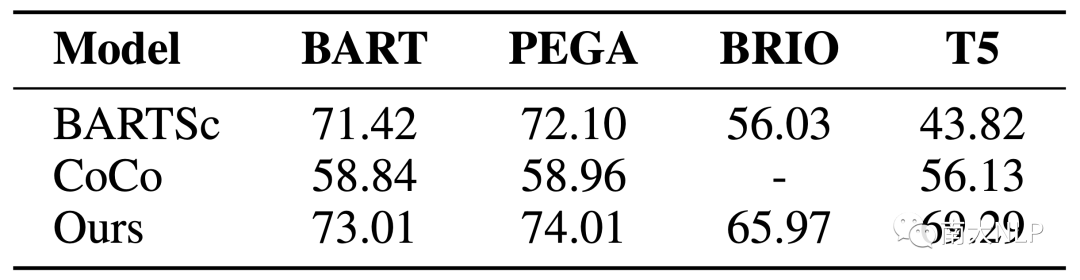
我們在QAGS-CNN上測試了基于不同的backbone的CoP和baseline,結果于表7。可以看到在不同backbone上CoP保持了穩定的優勢,證明了其魯棒性。
表7:在不同Backbone上的表現
5.2靈活的prompt vector長度
作為第一篇在一致性領域結合prompt tuning的工作,我們也分析了prompt vector長度的影響。如圖4所示,隨著長度的增加,受益于更多可訓練參數帶來的更強表達能力,模型的效果會逐漸提升。但和prefix tuning[5]類似的,超過閾值之后效果出現了一些下降,這可能是因為更多參數帶來的過擬合數據噪音的風險。比起先前的工作只能從一個固定大小的預訓練模型開始訓練,我們可以通過靈活調節參數量適應實際應用的不同數據規模。
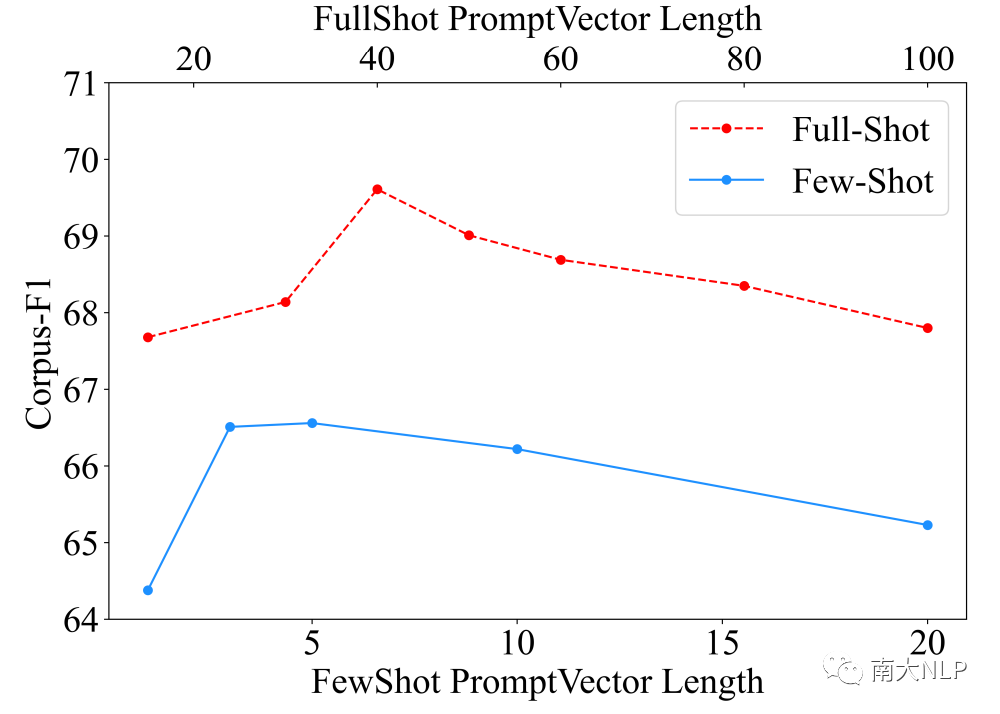
圖4:prompt vector長度和數據集級別F1,兩個X軸對應兩個訓練設定
5.3 prompt tuning帶來更清晰的決策邊界
我們可視化了CoP預測的評估分數于圖5。可以觀察到在Zero-Shot下,分數分布就存在區別,很直接的解釋了為什么CoP可以在無監督環境下工作。而利用prompt tuning從微量數據中學習之后,分數的分布呈現了更加清晰的邊界,極大的幫助CoP分辨出摘要的不一致。
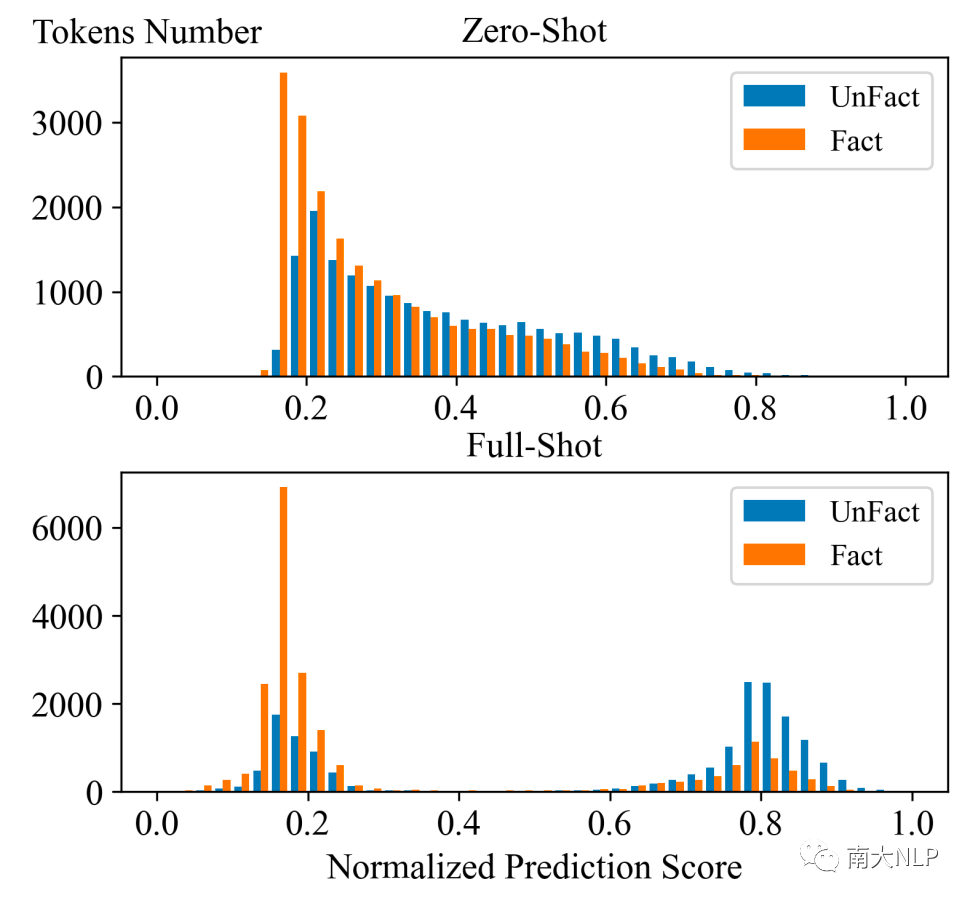
圖5:標準化后的分數分布,更高的分數代表CoP認為這個詞更可能是不一致
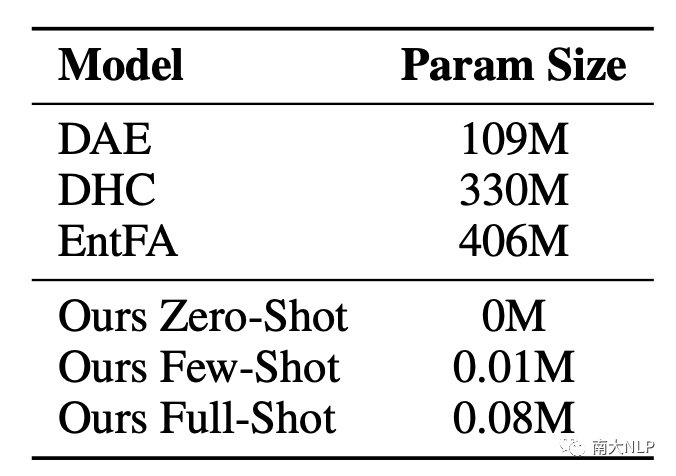
5.4高效的少量訓練參數
可訓練參數的規模極大影響訓練效率以及所需顯存。在這個低資源任務中,之前的工作為了訓練大模型,往往需要構造大量偽數據,增加了訓練代價。偽數據和真實數據分布的差異,也導致了天然性能差距。我們比較CoP和之前工作的參數規模,結果顯示我們僅僅用了0.02%的參數就超過了之前的工作,展示了我們框架的高效性。
表8:不同方法的可訓練參數規模
5.5樣例分析
表9:越高的分數代表模型認為摘要更一致(下劃線是詞級別不一致標注)
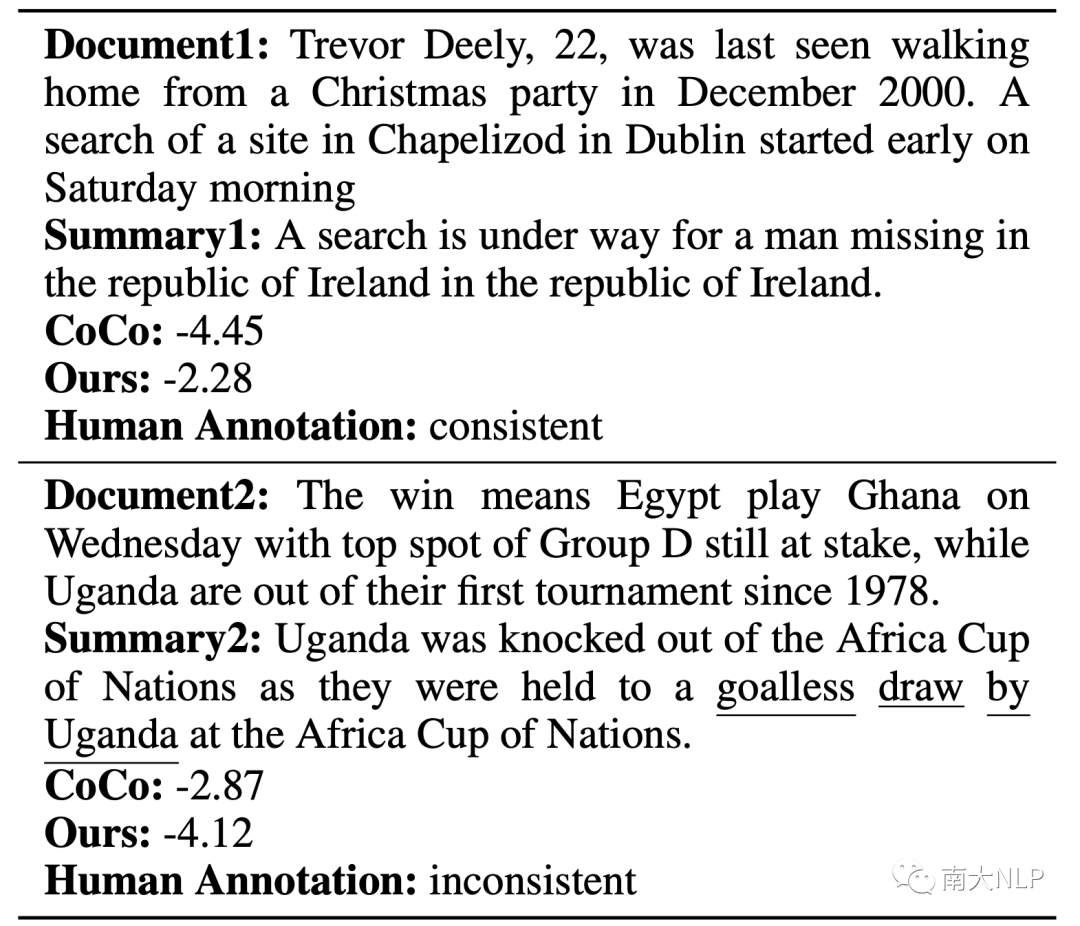
我們展示了兩個測試集的例子。摘要1是事實一致的,但是存在生成冗余。對于那些不能很好過濾流暢性偏好的方法,生成冗余會誤導模型去認為這個摘要不一致。顯然我們的方法給出了一個更合理的分數。另一個例子則相反,相當流暢且僅僅在一些核心詞語上出現了不一致錯誤。CoCo給了一個更高的分數,并不能發現不一致錯誤,CoP展現了更好檢測事實不一致的能力。
06、總結
在本篇工作中,我們提出了CoP,利用prompt來控制模型偏好,檢測事實不一致。通過分離無關偏好,CoP不需要訓練就可以精確的檢測出事實不一致。此外CoP可以衡量特定類型的偏好并檢測出具體不一致類型。我們還探索了結合prompt tuning來高效的從少量真實數據中學習。CoP在三個不一致檢測任務上取得了SOTA結果,證明了我們方法的有效性。
審核編輯:郭婷
-
深度學習
+關注
關注
73文章
5599瀏覽量
124398
原文標題:AAAI2023 | 通過控制偏好檢測事實不一致
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
變頻器同時帶動2個同型號電機速度不一致的解決方法
自動駕駛感知不一致是怎么發生的?
鏡頭不一致的問題原因分析
TC397 EVB板子DAP調試接口不一致,是否導致我無法穩定燒寫程序問題?
CAN總線采樣點不一致的危害
變頻器運行頻率與給定頻率不一致的原因及解決方案
采樣點不一致:總線通信的隱形殺手




 工商網監
工商網監
評論