 IBM全新AIU芯片:5nm工藝,230億晶體管!深度學習處理性能強勁!
IBM全新AIU芯片:5nm工藝,230億晶體管!深度學習處理性能強勁!

電子發燒友網報道(文/李彎彎)不久前,IBM 研究院推出了一款AI處理器,名為人工智能單元(Artificial Intelligent Unit,AIU),這是IBM首個用于運行和訓練深度學習模型的完整 SoC。IBM聲稱,其比通用CPU工作更快、更高效。
AIU:32個處理器核心、230億個晶體管
這款AIU芯片是IBM研究院AI硬件中心投入五年開發出的結果,AI硬件中心于2019年啟動,專注于開發下一代芯片與AI系統。該中心的目標是,計劃未來每年將AI硬件效率提升2.5倍。到2029年,將AI模型的訓練和運行速度拉高1000倍。
據IBM介紹,該芯片采用5nm制程工藝,共有32個處理器核心和230億個晶體管,在設計易用性方面,與普通顯卡相當,能夠介入任何帶有PCI插槽的計算機或服務器。AIU芯片,旨在支持多種格式并簡化從圖像識別到自然語言處理的人工智能工作流程。
AIU芯片與傳統用于訓練的GPU芯片有何不同?一直以來,深度學習模型依賴于CPU加GPU協處理器的組合進行訓練與運行。GPU最初是為沉浸圖形圖像而開發,后來人們發現其在AI領域有著顯著優勢,因此GPU在AI訓練領域占據了非常重要的位置。
IBM開發的AIU并非圖形處理器,它是專為深度學習模型加速設計的,針對矩陣和矢量計算進行了優化。AIU能夠解決高復雜計算問題,并以遠超CPU的速度執行數據分析。
AIU芯片有何特點呢?過去這些年,AI與深度學習模型在各行各業中快速普及,同時深度學習的發展也給算力資源帶來了巨大的壓力。深度學習模型的體量越來越大,包含數十億甚至數萬億個參數。而硬件效率的發展卻似乎跟不上深度學習模型的增長速度。
過去,計算一般集中在高精度64位與32位浮點運算層面。IBM認為,有些計算任務并不需要這樣的精度,于是提出了降低傳統計算精度的新術語——近似計算。
如何理解呢?IBM認為對于常見的深度學習任務,其實并不需要那么高的計算精度,就比如說人類大腦,即使沒有高分辨率,也能夠分辨出家人或者小貓。也就是說各種任務,其實都可以通過近似計算來處理。
在AIU芯片的設計中,近似計算發揮著重要作用。IBM研究人員設計的AIU芯片精度低于CPU,而這種較低精度也讓新型AIU硬件加速器獲得了更高的計算密度。IBM使用混合8位浮點(HFP)計算,而非AI訓練中常見的32位或16點浮點計算。由于精度較低,因此該芯片的運算執行速度可達到FP16的2倍,同時繼續保持類似的訓練效能。
IBM在AI芯片技術上的不斷升級
在去年2月的國際固態電路會議(ISSCC 2021)上,IBM也曾發布過一款性能優異的AI芯片,據IBM稱它是當時全球首款高能效AI芯片,采用7nm制程工藝,可達到80%以上的訓練利用率和60%以上的推理利用率,而通常情況下,GPU的利用率在30%以下。
有對比數據顯示,IBM 7nm高能效AI芯片的性能和能效,不同程度地超過了IBM此前推出的14nm芯片、韓國科學院(KAIST)推出的65nm芯片、平頭哥推出的12nm芯片含光800、NVIDIA推出的7nm芯片A100、聯發科推出的7nm芯片。
IBM去年推出的這款7nm AI芯片支持fp8、fp16、fp32、int4、int2混合精度。在fp32和fp8精度下,這款芯片每秒浮點運算次數分別達到16TFLOPS和25.6TFLOPS,能效比為3.5TFLOPS/W和1.9TFLOPS。而被業界高度認可的NVIDIA A100 GPU在fp16精度下的能效比為0.78TFLOPS/W,低于IBM這款高能效AI芯片。
IBM在官網中稱,這款AI芯片之所以能夠兼顧能效和性能,是因為該芯片支持超低精度混合8位浮點格式((HFP8,hybrid FP8)。這是IBM于2019年發布的一種高度優化設計,允許AI芯片在低精度下完成訓練任務和不同AI模型的推理任務,同時避免任何質量損失。
可以看到IBM此次發布的新款AIU與去年2月發布的7nm AI芯片,都采用了IBM此前提出的近似計算。從性能來看,去年推出的那款AI芯片一定程度上甚至超過了目前業界訓練場景普遍使用的NVIDIA A100 GPU,而今年新推出的AIU無論是在制程工藝、晶體管數量上都有升級,可想而知性能水平將會更高。
AIU:32個處理器核心、230億個晶體管
這款AIU芯片是IBM研究院AI硬件中心投入五年開發出的結果,AI硬件中心于2019年啟動,專注于開發下一代芯片與AI系統。該中心的目標是,計劃未來每年將AI硬件效率提升2.5倍。到2029年,將AI模型的訓練和運行速度拉高1000倍。
據IBM介紹,該芯片采用5nm制程工藝,共有32個處理器核心和230億個晶體管,在設計易用性方面,與普通顯卡相當,能夠介入任何帶有PCI插槽的計算機或服務器。AIU芯片,旨在支持多種格式并簡化從圖像識別到自然語言處理的人工智能工作流程。
AIU芯片與傳統用于訓練的GPU芯片有何不同?一直以來,深度學習模型依賴于CPU加GPU協處理器的組合進行訓練與運行。GPU最初是為沉浸圖形圖像而開發,后來人們發現其在AI領域有著顯著優勢,因此GPU在AI訓練領域占據了非常重要的位置。
IBM開發的AIU并非圖形處理器,它是專為深度學習模型加速設計的,針對矩陣和矢量計算進行了優化。AIU能夠解決高復雜計算問題,并以遠超CPU的速度執行數據分析。
AIU芯片有何特點呢?過去這些年,AI與深度學習模型在各行各業中快速普及,同時深度學習的發展也給算力資源帶來了巨大的壓力。深度學習模型的體量越來越大,包含數十億甚至數萬億個參數。而硬件效率的發展卻似乎跟不上深度學習模型的增長速度。
過去,計算一般集中在高精度64位與32位浮點運算層面。IBM認為,有些計算任務并不需要這樣的精度,于是提出了降低傳統計算精度的新術語——近似計算。
如何理解呢?IBM認為對于常見的深度學習任務,其實并不需要那么高的計算精度,就比如說人類大腦,即使沒有高分辨率,也能夠分辨出家人或者小貓。也就是說各種任務,其實都可以通過近似計算來處理。
在AIU芯片的設計中,近似計算發揮著重要作用。IBM研究人員設計的AIU芯片精度低于CPU,而這種較低精度也讓新型AIU硬件加速器獲得了更高的計算密度。IBM使用混合8位浮點(HFP)計算,而非AI訓練中常見的32位或16點浮點計算。由于精度較低,因此該芯片的運算執行速度可達到FP16的2倍,同時繼續保持類似的訓練效能。
IBM在AI芯片技術上的不斷升級
在去年2月的國際固態電路會議(ISSCC 2021)上,IBM也曾發布過一款性能優異的AI芯片,據IBM稱它是當時全球首款高能效AI芯片,采用7nm制程工藝,可達到80%以上的訓練利用率和60%以上的推理利用率,而通常情況下,GPU的利用率在30%以下。
有對比數據顯示,IBM 7nm高能效AI芯片的性能和能效,不同程度地超過了IBM此前推出的14nm芯片、韓國科學院(KAIST)推出的65nm芯片、平頭哥推出的12nm芯片含光800、NVIDIA推出的7nm芯片A100、聯發科推出的7nm芯片。
IBM去年推出的這款7nm AI芯片支持fp8、fp16、fp32、int4、int2混合精度。在fp32和fp8精度下,這款芯片每秒浮點運算次數分別達到16TFLOPS和25.6TFLOPS,能效比為3.5TFLOPS/W和1.9TFLOPS。而被業界高度認可的NVIDIA A100 GPU在fp16精度下的能效比為0.78TFLOPS/W,低于IBM這款高能效AI芯片。
IBM在官網中稱,這款AI芯片之所以能夠兼顧能效和性能,是因為該芯片支持超低精度混合8位浮點格式((HFP8,hybrid FP8)。這是IBM于2019年發布的一種高度優化設計,允許AI芯片在低精度下完成訓練任務和不同AI模型的推理任務,同時避免任何質量損失。
可以看到IBM此次發布的新款AIU與去年2月發布的7nm AI芯片,都采用了IBM此前提出的近似計算。從性能來看,去年推出的那款AI芯片一定程度上甚至超過了目前業界訓練場景普遍使用的NVIDIA A100 GPU,而今年新推出的AIU無論是在制程工藝、晶體管數量上都有升級,可想而知性能水平將會更高。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
芯片
+關注
關注
463文章
54010瀏覽量
466159 -
IBM
+關注
關注
3文章
1868瀏覽量
77007
發布評論請先 登錄
相關推薦
熱點推薦
揭秘芯片測試:如何驗證數十億個晶體管
微觀世界的“體檢”難題在一枚比指甲蓋還小的芯片中,集成了數十億甚至上百億個晶體管,例如NVIDIA的H100GPU包含800億個晶體管。要如何確定每一個

深度解讀晶體管的轉移特性曲線
本文介紹了晶體管轉移特性曲線及其核心參數的意義。曲線描述了柵壓控制漏極電流的過程,涵蓋關斷、亞閾值與導通區,是定義數字邏輯和平衡芯片性能的基石。
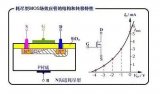
探索BFU520Y:雙NPN寬帶硅射頻晶體管的卓越性能
探索BFU520Y:雙NPN寬帶硅射頻晶體管的卓越性能 在射頻晶體管的領域中,NXP的BFU520Y脫穎而出,成為高速、低噪聲應用的理想之選。今天,我們就來深入剖析這款雙NPN寬帶硅射頻晶體管
漏致勢壘降低效應如何影響晶體管性能
隨著智能手機、電腦等電子設備不斷追求輕薄化,芯片中的晶體管尺寸已縮小至納米級(如3nm、2nm)。但尺寸縮小的同時,一個名為“漏致勢壘降低效應(DIBL)”的物理現象逐漸成為制約
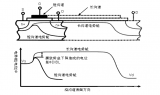
NSVT5551M雙極晶體管技術深度解析與應用指南
安森美 (onsemi) NSVT5551M雙極晶體管通過了AEC-Q101認證,是一款NPN通用型低V~CE(sat)~ 放大器。這款NPN雙極晶體管具有匹配的芯片,存放溫度范圍為-55°C至

多值電場型電壓選擇晶體管結構
多值電場型電壓選擇晶體管結構
為滿足多進制邏輯運算的需要,設計了一款多值電場型電壓選擇晶體管。控制二進制電路通斷需要二進制邏輯門電路,實際上是對電壓的一種選擇,而傳統二進制邏輯門電路通常比較復雜
發表于 09-15 15:31
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+半導體芯片產業的前沿技術
為我們重點介紹了AI芯片在封裝、工藝、材料等領域的技術創新。
一、摩爾定律
摩爾定律是計算機科學和電子工程領域的一條經驗規律,指出集成電路上可容納的晶體管數量每18-24個月會增加一倍,同時芯
發表于 09-15 14:50
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+工藝創新將繼續維持著摩爾神話
。那該如何延續摩爾神話呢?
工藝創新將是其途徑之一,芯片中的晶體管結構正沿著摩爾定律指出的方向一代代演進,本段加速半導體的微型化和進一步集成,以滿足AI技術及高性能計算飛速發展的需求。
發表于 09-06 10:37
今日看點丨蔚來自研全球首顆車規5nm芯片!;沃爾沃中國區啟動裁員計劃
低延時,快速響應。”此外,李斌還表示,這款芯片對全行業開放,誰想用都可以找我們,還可以降本。 ? 據悉,神璣NX9031芯片和底層軟件均實現自主設計,擁有超過500億顆晶體管。
發表于 07-08 10:50
?2147次閱讀
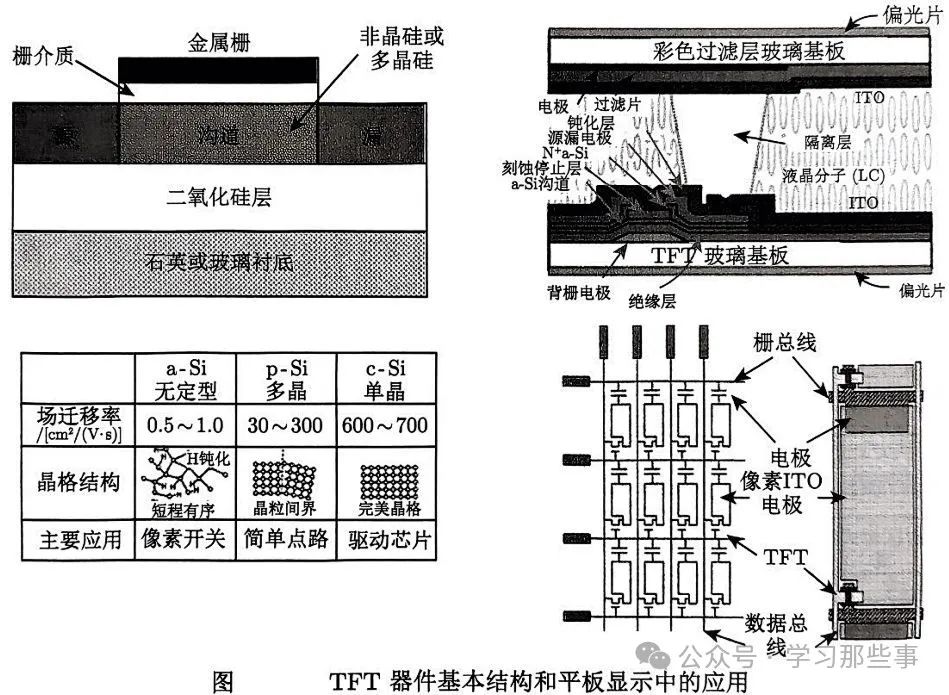
薄膜晶體管技術架構與主流工藝路線
導語薄膜晶體管(TFT)作為平板顯示技術的核心驅動元件,通過材料創新與工藝優化,實現了從傳統非晶硅向氧化物半導體、柔性電子的技術跨越。本文將聚焦于薄膜晶體管制造技術與前沿發展。
Cadence UCIe IP在Samsung Foundry的5nm汽車工藝上實現流片成功
我們很高興能在此宣布,Cadence 基于 UCIe 標準封裝 IP 已在 Samsung Foundry 的 5nm 汽車工藝上實現首次流片成功。這一里程碑彰顯了我們持續提供高性能車規級 IP 解決方案?的承諾,可滿足新一代汽

多值電場型電壓選擇晶體管結構
多值電場型電壓選擇晶體管結構
為滿足多進制邏輯運算的需要,設計了一款多值電場型電壓選擇晶體管。控制二進制電路通斷需要二進制邏輯門電路,實際上是對電壓的一種選擇,而傳統二進制邏輯門電路通常比較復雜
發表于 04-15 10:24
晶體管電路設計(下)
晶體管,FET和IC,FET放大電路的工作原理,源極接地放大電路的設計,源極跟隨器電路設計,FET低頻功率放大器的設計與制作,柵極接地放大電路的設計,電流反饋型OP放大器的設計與制作,進晶體管
發表于 04-14 17:24



 工商網監
工商網監
評論