 聚焦“源1.0”背后的計算挑戰以及我們采取的訓練方法
聚焦“源1.0”背后的計算挑戰以及我們采取的訓練方法

從2018年的BERT到2020年的GPT-3,NLP語言模型經歷了爆發式的發展過程,其中BERT模型的參數量為3.4億,而GPT-3的模型參數量達到了1750億。2021年9月,浪潮發布了“源1.0”,它是目前規模最大的中文AI單體模型,參數規模高達2457億,訓練采用的中文數據集達5TB。“源1.0”在語言智能方面表現優異,獲得中文語言理解評測基準CLUE榜單的零樣本學習和小樣本學習兩類總榜冠軍。測試結果顯示,人群能夠準確分辨人與“源1.0”作品差別的成功率低于50%。
海量的參數帶來了模型訓練和部署上的巨大挑戰。本文將聚焦“源1.0”背后的計算挑戰以及我們采取的訓練方法。
“源1.0”的模型結構
“源1.0”是一個典型的語言模型。語言模型通俗來講就是能夠完成自然語言理解或者生成文本的神經網絡模型。對于“源1.0”,我們考慮語言模型(Language Model,LM)和前綴語言模型(Prefix Language Model,PLM)兩種模型結構。如下圖所示:
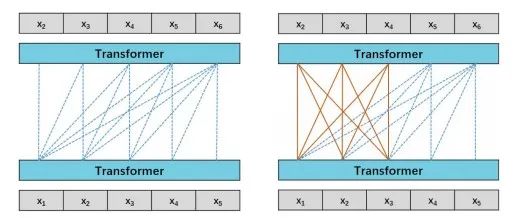
圖1 模型結構示意圖(左圖為LM,右圖為PLM)
我們比較了130億參數的LM和PLM在不同下游任務上的結果,注意到LM在Zero-Shot和Few-Shot上表現更好,而PLM在微調方面表現出色。微調通常會在大多數任務中帶來更好的準確性,然而微調會消耗大量的計算資源,這是不經濟的。所以我們選擇LM作為“源 1.0”模型的基礎模型結構。
?
如何訓練“源1.0”
| 源1.0訓練面對的挑戰
“源1.0”的訓練需要面對的第一個挑戰就是數據和計算量的挑戰。
數據方面,如果把訓練一個巨量模型的訓練過程比作上異常戰役的話,那么數據就是我們的彈藥。數據量的多少,決定了我們可以訓練模型的規模,以及最后的效果。針對這一方面,我們構建了一個全新的中文語料庫,清洗后的高質量數據規模達到了5TB,是目前規模最大的中文語料庫。
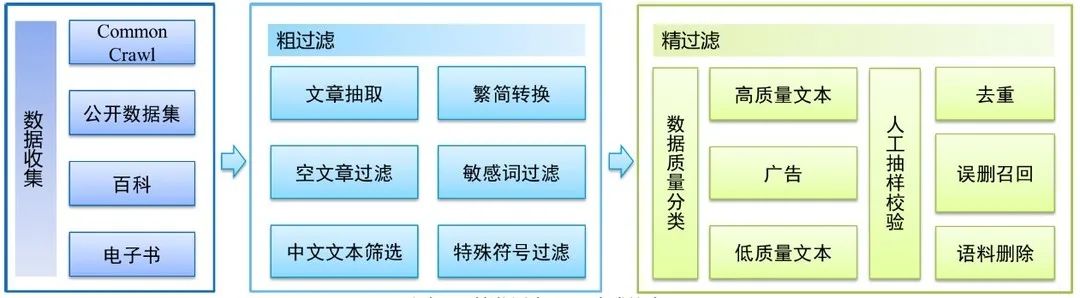
圖2 數據預處理流程圖
算力方面,根據OpenAI提出的PetaFlop/s-day衡量標準,我們可以估算“源1.0”訓練的計算需求情況。根據Wikipedia提供的數據(https://en.wikipedia.org/wiki/OpenAI),GPT-3的計算需求約為3640 PetaFlop/s-day,而“源1.0”的計算需求達到了4095 PetaFlop/s-day。
計算資源的巨大開銷是限制研究人員研發具有數以千萬計參數的NLP大模型的瓶頸。例如GPT-3是在由10000個GPU所組成的集群上訓練得到的。我們在設計“源1.0”的模型結構時,考慮到了影響大規模分布式訓練的關鍵因素,采用了專門的分布式訓練策略,從而加速了模型的訓練過程。
在模型訓練時一般最常用的是采用數據并行分布式計算策略,但這只能滿足小模型的訓練需求。對于巨量模型來說,由于其模型參數量過大,遠遠超過常用計算設備比如GPU卡的顯存容量,因此需要專門的算法設計來解決巨量模型訓練的顯存占用問題,同時還需要兼顧訓練過程中的GPU計算性能的利用率。
| “源1.0”的訓練策略
為了解決顯存不足的問題,我們采用了張量并行、流水并行、數據并行相結合的并行策略,實現了在2128個GPU上部署“源1.0”,并完成了1800億tokens的訓練。
a. 張量并行
針對單個GPU設備不能完整的承載模型訓練,一個解決方案就是張量并行+數據并行的2D并行策略。具體來說,使用多個GPU設備為1組,比如單個服務器內的8個GPU為1組,組內使用張量并行策略對模型進行拆分,組間(服務器間)采用數據并行。
對于張量并行部分,NVIDIA在Megatron-LM中提出了針對Transformer結構的張量并行解決方案。其思路是把每一個block的參數和計算都均勻的拆分到N個GPU設備上,從而實現每個GPU設備都承擔這一block的參數量和計算量的1/N效果。圖3展示了對Transformer結構中的MLP層和self-attention層進行張量并行拆分計算的過程示意圖。
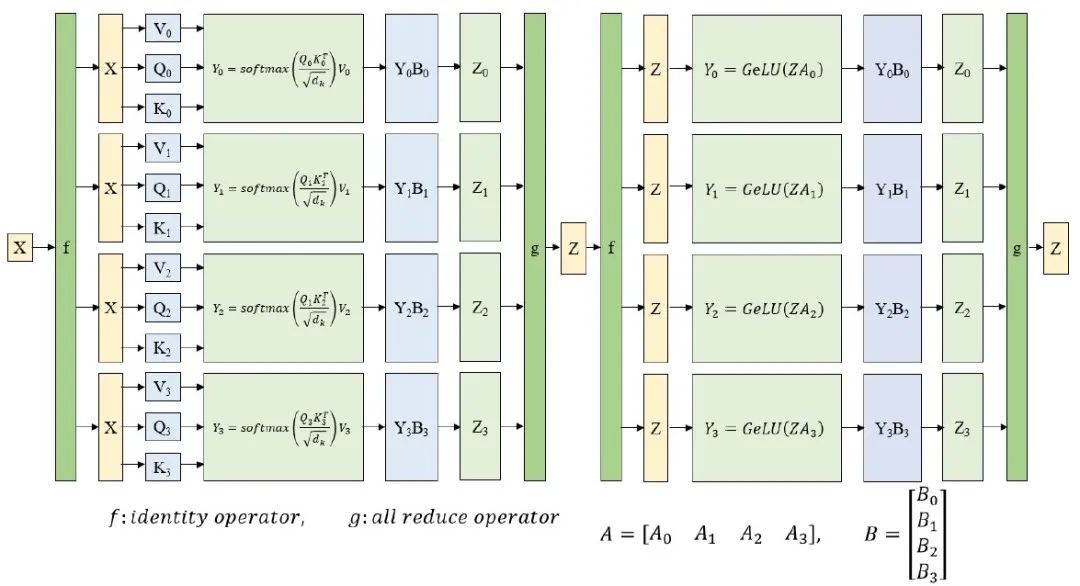
圖3 張量并行示意圖
在訓練過程中,tensor經過每一層的時候,計算量與通信數據量之比 如下:
如下:
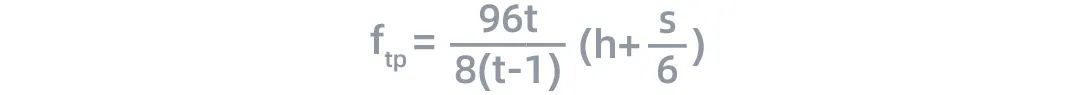
其中,S為輸入序列的長度,h為隱藏層的大小(hidden size)。
b. 流水并行

圖4 流水線并行示意圖
對于具有數千億參數的語言模型,這些參數很難被存放在單個節點中。流水線并行將LM的層序列在多個節點之間進行分割,以解決存儲空間不足的問題,如圖5所示。每個節點都是流水線中的一個階段,它接受前一階段的輸出并將結果過發送到下一階段。如果前一個相鄰節點的輸出尚未就緒,則當前節點將處于空閑狀態。節點的空閑時間被稱為流水線氣泡(pipline bubble)。為了提高流水行并行的性能,我們必須盡可能減少在氣泡上花費的時間。定義流水線中氣泡的理想時間占比為如下形式:
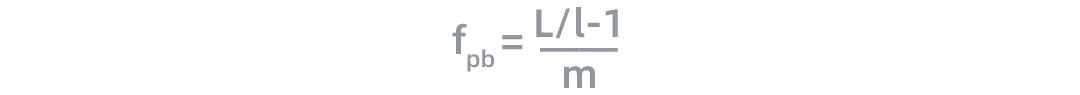
根據這一公式,流水線氣泡的耗時隨著層數L的增加而增加,隨著微批次大小(micro-batch-size)的增加而減小。當m?L/l的時候,流水并行過程中的流水線氣泡對訓練性能的影響幾乎可以忽略。
與此同時,在流水并行過程中,節點間的計算量與通信數據量之比為:
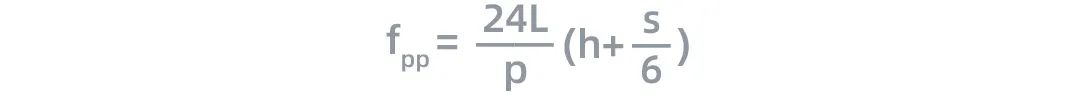
根據上面的公式,流水線中節點的計算效率與h和S呈線性關系,這與張量并行類似。
c. 數據并行
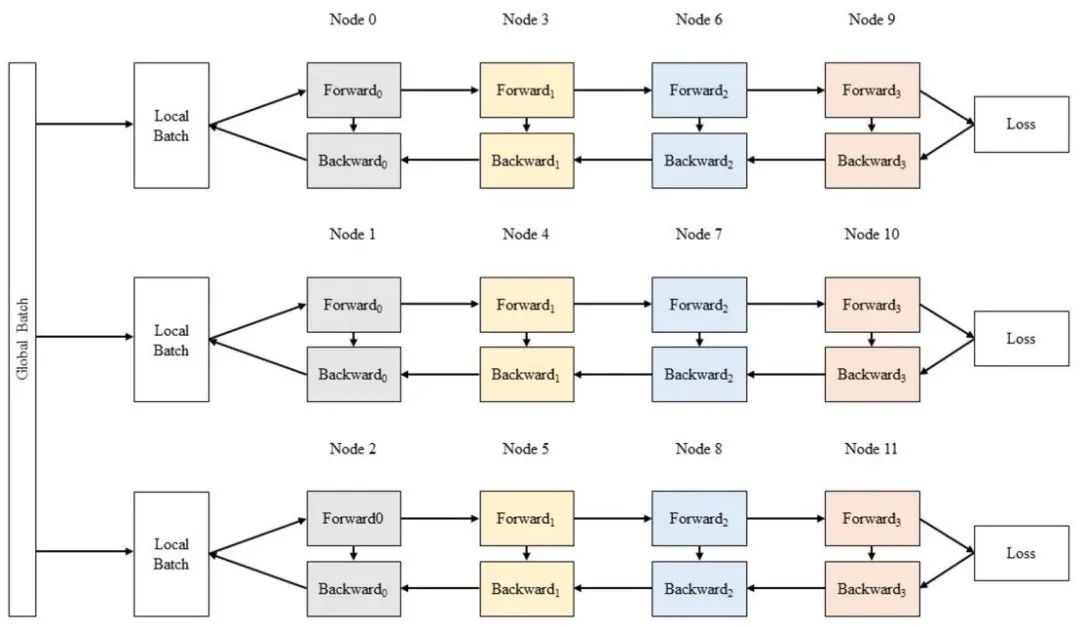
圖6 數據并行示意圖
采用數據并行時,全局批次大小(global batch size)按照流水線分組進行分割。每個流水線組都包含模型的一個副本,數據在組內按照局部批次規模送入模型副本。數據并行時的計算量與通信數據量的比值可用如下公式近似:
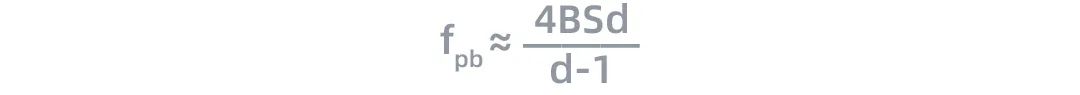
當d? 1時,上面公式可以進一步簡化成:

根據這一公式,我們可以看出數據并行的計算效率與全局批次大小B和序列長度S呈正比關系。由于模型對內存的需求與S的平方成正比,與B成線性關系,因此增加全局批次大小可以更有效的提升數據并行的效率。
當全局批次大小過大的時候,模型很容易出現不收斂的問題,為了保證模型訓練過程的穩定性,我們將全局批次大小限制在了10^7個token內。
根據以上的理論分析,我們確定了設計“源1.0”巨量模型結構的基本原則:
盡可能增加序列長度,因為它有利于張量并行、流水線并行和數據并行。由于內存占用與序列長度的平方成正比,因此有必要在反向傳播時重新計算激活函數,以節省內存開銷;
語言模型中層數太多會對性能產生負面影響,因為這會增加在流水線氣泡上的時間消耗;
增加隱藏層大小可以提高張量并行和流水線并行的性能;
增加節點中的微批次大小可以提高流水線并行效率,增加全局批次大小可以提升數據并行的效率;
在這一設計原則的基礎上,我們設計的“源1.0”的模型結構以及分布式策略的設置如下表所示:

結合模型結構的特性以及我們使用集群的硬件特性,我們如下的節點配置和分布式策略選擇:
“源1.0”模型在訓練過程中共使用了2128個GPU;
模型分成了7組,每組38臺AI服務器,里面放置一個完整的“源1.0”模型,7組之間采用數據并行;
每組的38個服務器,采用流水并行每個服務器放置1/38的模型(2個Transformer Layer),一共76層;
在每臺服務器內采用張量并行,按照Transformer結構的每一層進行均勻切分;
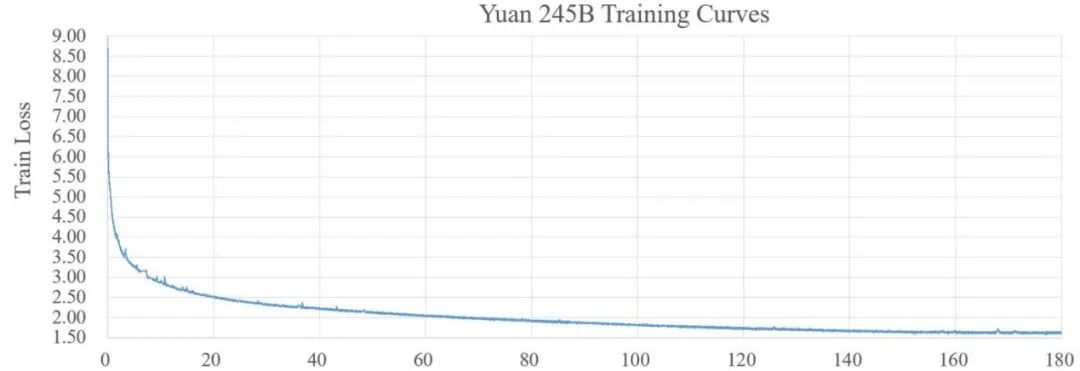
模型收斂曲線如下圖:
關于“源1.0”的更多信息,大家可以參照浪潮發布在arxiv上的論文:https://arxiv.org/abs/2110.04725
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107779 -
模型
+關注
關注
1文章
3752瀏覽量
52111 -
語言模型
+關注
關注
0文章
571瀏覽量
11314
原文標題:如何訓練2457億參數量的中文巨量模型“源1.0”
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
泰克專家探討類腦計算背后的器件邏輯與現實挑戰
摩爾線程發布SimuMax v1.1:從仿真工具升級為全棧工作流平臺,助力大模型訓練提效
重要通知 | Splashtop 即將停止支持 TLS 1.0/1.1

摩爾線程發布大模型訓練仿真工具SimuMax v1.0

【「DeepSeek 核心技術揭秘」閱讀體驗】第三章:探索 DeepSeek - V3 技術架構的奧秘
大模型推理顯存和計算量估計方法研究
GLAD應用:高斯光束的吸收和自聚焦效應
基于RK3576開發板的yolov11-track多目標跟蹤部署教程

GLAD應用:高斯光束的吸收和自聚焦效應
海思SD3403邊緣計算AI數據訓練概述
RAKsmart智能算力架構:異構計算+低時延網絡驅動企業AI訓練范式升級
聚焦離子束技術的原理和應用



 工商網監
工商網監
評論