") Transformer常用的輕量化方法
Transformer常用的輕量化方法

本文梳理了一些Transformer常用的輕量化方法,并分領(lǐng)域的介紹了一些主流的輕量化Transformer。
引言:近年來,Transformer模型在人工智能的各個領(lǐng)域得到了廣泛應(yīng)用,成為了包括計算機視覺,自然語言處理以及多模態(tài)領(lǐng)域內(nèi)的主流方法。盡管Transformer在大部分任務(wù)上擁有極佳的性能,其過大的參數(shù)量限制了在現(xiàn)實場景下的應(yīng)用,也給相關(guān)研究帶來了困難,由此帶來了Transformer輕量化領(lǐng)域的發(fā)展。筆者首先梳理了一些Transformer常用的輕量化方法,并分領(lǐng)域的介紹了一些主流的輕量化Transformer。歡迎大家批評指正,相互交流。
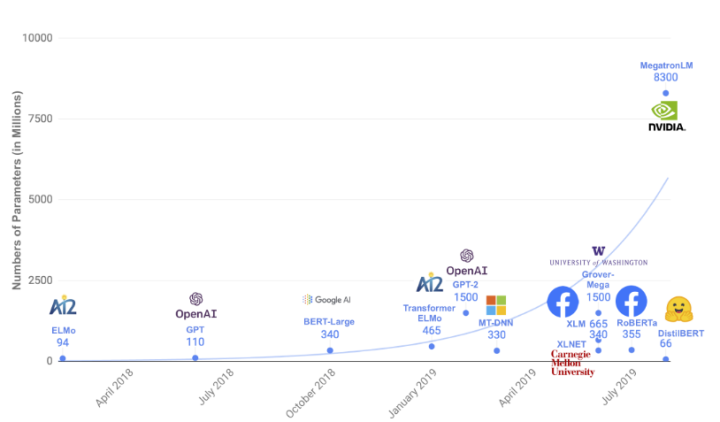
預(yù)訓(xùn)練模型參數(shù)量增長趨勢
1.Transformer中常用的模型壓縮方法
量化:量化的基本思想即利用低比特的數(shù)據(jù)類型來替代原本的高比特數(shù)據(jù)類型,同時對數(shù)據(jù)的存儲空間與計算的復(fù)雜度進(jìn)行輕量化。簡單的訓(xùn)練后量化,即直接對訓(xùn)練好的模型參數(shù)進(jìn)行量化會帶來很大的誤差,目前主要會采用量化感知訓(xùn)練(Quantized-Aware Training, QAT)的方式,在訓(xùn)練時全精度優(yōu)化,僅模擬低精度的推理過程,很好的降低了量化過程的性能損失。
剪枝:剪枝方法基于lottery ticket假設(shè),即模型中只有小部分參數(shù)起了核心作用,其他的大部分參數(shù)是無效參數(shù),可以去除掉。剪枝可以分為非結(jié)構(gòu)化剪枝與結(jié)構(gòu)化剪枝。非結(jié)構(gòu)化剪枝即定位參數(shù)矩陣中接近于0或者有接近0趨勢的參數(shù),并將這些參數(shù)歸零,使參數(shù)矩陣稀疏化。結(jié)構(gòu)化剪枝即消減模型中結(jié)構(gòu)化的部分,如多頭注意力中不需要的注意力頭,多層Transformer中不需要的若干層等等。
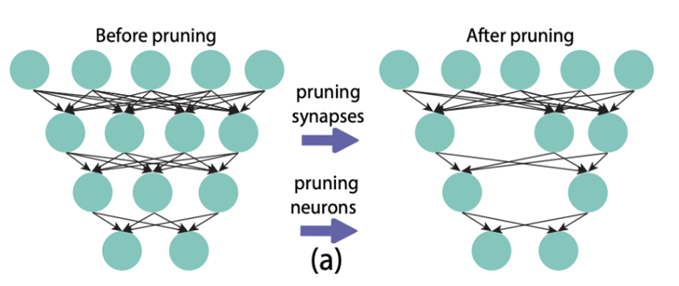
非結(jié)構(gòu)化剪枝
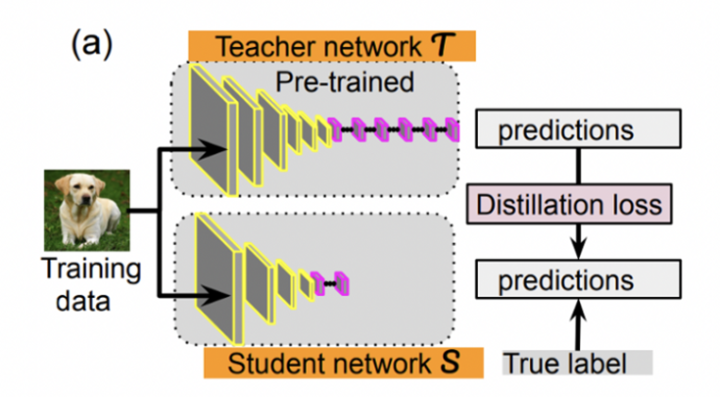
知識蒸餾:知識蒸餾通常在一個大的老師模型與一個小的學(xué)生模型之間進(jìn)行。通過老師模型在監(jiān)督數(shù)據(jù)上輸出的“軟標(biāo)簽分布”來訓(xùn)練學(xué)生模型。這種“軟標(biāo)簽”的學(xué)習(xí)能夠很好的克服監(jiān)督數(shù)據(jù)中標(biāo)簽偏差的問題,帶來了很好的知識遷移的能力。
參數(shù)共享:在模型同質(zhì)的部分間共享參數(shù)。
2.預(yù)訓(xùn)練語言模型中的輕量化Transformer
Transformer最早在自然語言領(lǐng)域中得到廣泛的應(yīng)用,其強大的能力帶來了預(yù)訓(xùn)練領(lǐng)域的快速發(fā)展,并在相關(guān)領(lǐng)域帶來了革新。但是隨著預(yù)訓(xùn)練模型規(guī)模的不斷增大,訓(xùn)練與部署一個預(yù)訓(xùn)練模型的代價也不斷提升,預(yù)訓(xùn)練語言模型輕量化的研究方向應(yīng)運而生。由于以Bert為代表的預(yù)訓(xùn)練語言模型的主流架構(gòu)仍是Transformer,因此Transformer的輕量化也成為了當(dāng)前NLP領(lǐng)域的一個重要課題。以下是筆者整理的幾篇經(jīng)典的預(yù)訓(xùn)練語言模型中的輕量化工作,供讀者參考。
Q8BERT: Quantized 8Bit BERT
https://arxiv.org/pdf/1910.06188.pdf
Q8BERT是量化方法在Bert上的樸素運用。除了采用了基本的量化感知訓(xùn)練方式外,Q8BERT還采用了指數(shù)滑動平均的方式平滑QAT的訓(xùn)練過程。最終,在壓縮了近4倍參數(shù)量,取得4倍推理加速的前提下,Q8BERT在GLUE與SQUAD數(shù)據(jù)集上取得了接近Bert的效果,證明了量化方法在Bert上的有效性。
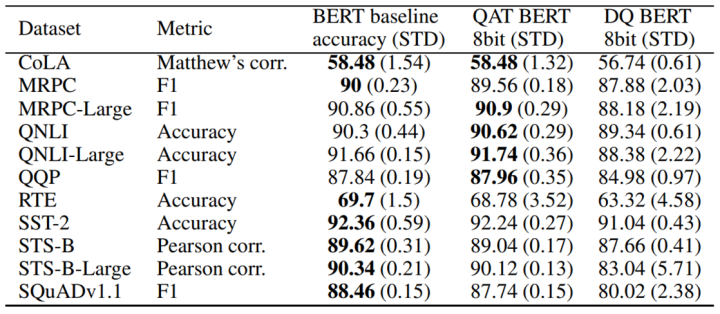
Q8BERT在下游任務(wù)上的表現(xiàn)
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/pdf/1910.01108.pdf
DistillBERT是huggingface發(fā)布的一個小版本的Bert模型,它只在輸出層面采用了軟標(biāo)簽的蒸餾,將Bert的層數(shù)壓縮到了原本的1/2,并在各個下游任務(wù)上取得了不錯的結(jié)果。
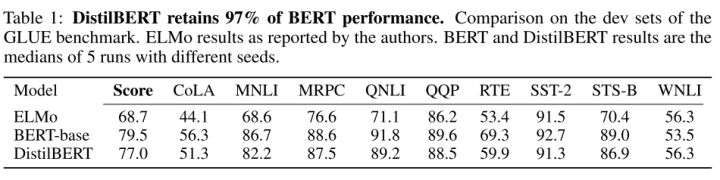
在GLUE上,DisitlBERT只用了60%的參數(shù),保留了97%的性能
TinyBERT: Distilling BERT for Natural Language Understanding
https://arxiv.org/pdf/1909.10351.pdf
與DistilBERT相同,TinyBERT同樣是知識蒸餾在Bert壓縮上的應(yīng)用。不同于DistillBERT只在預(yù)訓(xùn)練階段采用知識蒸餾,TinyBERT同時在預(yù)訓(xùn)練和微調(diào)階段采用了兩階段的知識蒸餾,使得小模型能夠?qū)W到通用與任務(wù)相關(guān)的語義知識。
TinyBERT蒸餾策略
同時,TinyBERT采用了更加細(xì)粒度的知識蒸餾方式,對embedding層的輸出,Transformer每一層中隱藏層與注意力計算的輸出以及整個模型的軟標(biāo)簽進(jìn)行了知識蒸餾,得到了更加精準(zhǔn)的知識遷移效果。
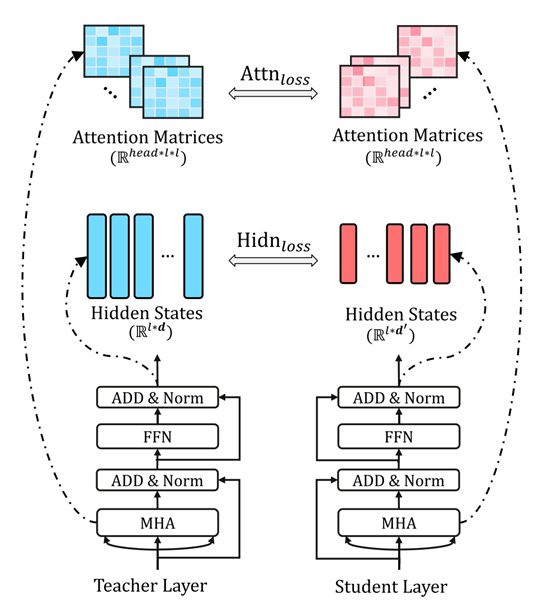
更加細(xì)粒度的蒸餾方式
最終,TinyBERT將BERT模型蒸餾成了一個4層且隱藏層維度更小的模型,并取得了不亞于更高參數(shù)量的DistilBERT的效果。
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
https://arxiv.org/pdf/1909.11942.pdf
ALBERT是Google在ICLR2020上的一篇工作。它首先采用了詞表矩陣分解的方法,由于Bert采用了一個很大的詞表,因此詞表的embedding層包含了很大的參數(shù)量,ALBERT采用了參數(shù)分解(Factorized embedding parameterization)的方式減少這部分的參數(shù)量。具體而言,對于一個包含V 個單詞的詞表,假如詞表的隱藏層大小E 與模型的隱藏層大小H 相等,則embedding層包含的參數(shù)量為V × E 。考慮到V通常較大,embedding的總參數(shù)量也會較大。為了減少參數(shù)量, 與直接對one-hot的詞向量映射到 H 維空間不同,ALBERT首先將詞向量映射到較小的E 維空間,再映射到H 維空間。將參數(shù)量從O(V × H)降低到了O(V × E + E × H) ,實現(xiàn)了embedding層的壓縮。
除此之外,ALBERT還進(jìn)行了Transformer內(nèi)跨層的參數(shù)壓縮,通過跨Tranformer層的完全參數(shù)共享,ALBERT對參數(shù)量進(jìn)行了充分的壓縮,在低參數(shù)量的條件下取得了與Bert-base相似的效果,同時在相近的參數(shù)量下可以保證模型更深,隱藏層維度更大,在下游任務(wù)下的表現(xiàn)更好。
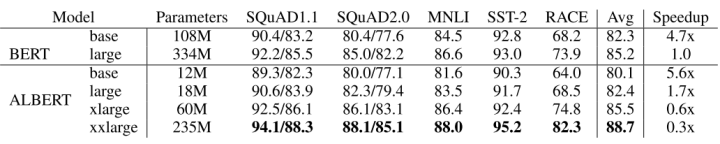
ALBERT的參數(shù)量及下游任務(wù)表現(xiàn)
3.計算機視覺中的輕量化Transformer
盡管Transformer在計算機視覺領(lǐng)域的應(yīng)用相較于NLP領(lǐng)域稍慢一步,但Vision Transformer的橫空出世使得Transformer也占據(jù)了視覺模型的主流。后期基于MAE與BEiT的預(yù)訓(xùn)練方法更加鞏固了Transformer在計算機視覺領(lǐng)域的地位。與自然語言理解領(lǐng)域相同,計算機視覺中的Transformer同樣面臨著參數(shù)量過多,部署困難的問題,因此也需要輕量化的Transformer來高效的完成下游任務(wù)。以下是筆者整理的幾篇近年來計算機視覺領(lǐng)域中的輕量化工作,供讀者參考。
Training data-efficient image transformers & distillation through attention
http://proceedings.mlr.press/v139/touvron21a/touvron21a.pdf
DeiT是Facebook在2021年的一篇工作,模型的核心方法是通過知識蒸餾對視覺Transformer進(jìn)行壓縮。DeiT采用了兩種蒸餾方法實現(xiàn)了老師模型到學(xué)生模型的知識遷移:
Soft Distillation:通過老師模型輸出的軟標(biāo)簽進(jìn)行知識蒸餾。
Hard-label Distillation:通過老師模型預(yù)測出的實際標(biāo)簽進(jìn)行知識蒸餾,意義在于糾正可能存在的有監(jiān)督數(shù)據(jù)的標(biāo)簽偏差。
DeiT在蒸餾過程中引入了Distillation token的概念,其作用與Class token類似,但Class token用于在原數(shù)據(jù)上利用交叉熵進(jìn)行訓(xùn)練,Distillation token用于模擬老師模型的軟分布輸出或利用老師模型預(yù)測的hard-label進(jìn)行訓(xùn)練。
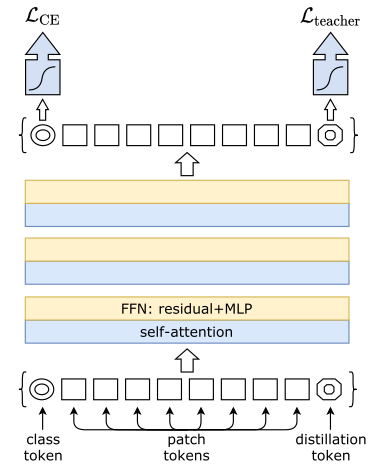
Disillation token
通過在老師模型上的蒸餾過程,DeiT擁有更小的參數(shù)規(guī)模和更快的推理速度的條件下,取得了比ViT更好的效果。
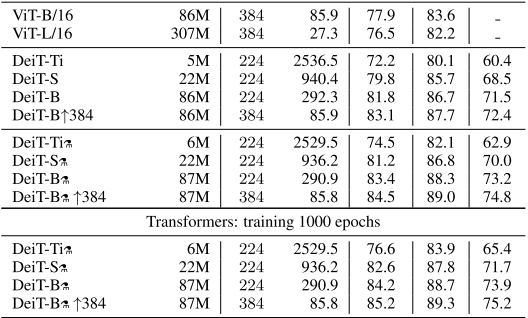
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136810068.pdf
TinyViT是微軟在2022年的一篇工作,這篇工作的核心依然是知識蒸餾,但是在工程實現(xiàn)上進(jìn)行了一些優(yōu)化,使得小模型能夠在更大的數(shù)據(jù)規(guī)模下通過知識蒸餾獲取到大模型的知識。DeiT采用的知識蒸餾方法是相當(dāng)昂貴的,因為在蒸餾過程中,教師模型與老師模型會同時占用GPU的內(nèi)存,限制了batch_size的增加與學(xué)生模型的訓(xùn)練速度。且軟標(biāo)簽在老師模型輸出端到學(xué)生模型輸出端的遷移也會帶來一定的計算資源損耗。
為了解決這個問題,TinyViT提出了一種軟標(biāo)簽預(yù)生成的方法,即解耦軟標(biāo)簽的生成與學(xué)生模型的訓(xùn)練過程。先進(jìn)行軟標(biāo)簽的生成與預(yù)存儲,再利用預(yù)存儲的軟標(biāo)簽對學(xué)生模型進(jìn)行訓(xùn)練。由于預(yù)存儲軟標(biāo)簽向量會帶來極大的存儲損耗,考慮到這些向量大部分是稀疏的(因為對于一個訓(xùn)練好的老師模型,給定一張圖片,只有極小部分類別會存在成為正確標(biāo)簽的概率),作者采用了存儲稀疏標(biāo)簽的策略,即只存儲top-k概率的標(biāo)簽以及其對應(yīng)的概率。在訓(xùn)練學(xué)生模型時將這樣的稀疏標(biāo)簽還原成完整的概率分布,并進(jìn)行知識蒸餾。整個pipeline如下圖所示:
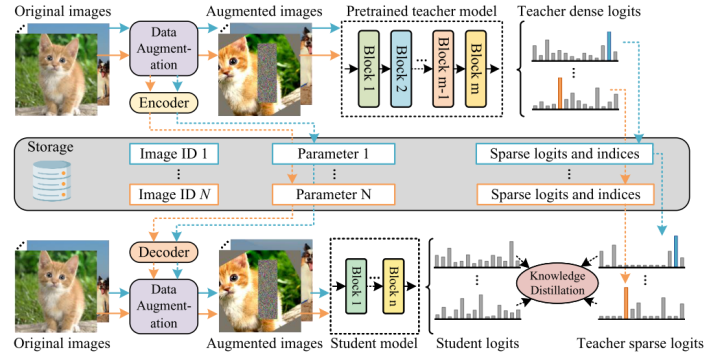
TinyViT的蒸餾流程
在相同的模型規(guī)模下,TinyViT提高了知識蒸餾的速度與數(shù)據(jù)量,并取得了分類任務(wù)上的提升。
MiniViT: Compressing Vision Transformers with Weight Multiplexing
https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_MiniViT_Compressing_Vision_Transformers_With_Weight_Multiplexing_CVPR_2022_paper.pdf
MiniViT是微軟在CVPR2022的一篇工作,采用了權(quán)重復(fù)用的方法來壓縮模型的參數(shù)。與ALBERT不同的是,作者發(fā)現(xiàn)單純的權(quán)重復(fù)用會導(dǎo)致每層梯度l2范數(shù)的同質(zhì)化以及最后幾層輸出特征相關(guān)性的降低。為了解決這個問題,MiniViT采用了Weight Transformation與Weight Distillation的方法來解決這個問題。Weight Transformation,即在每一層之間插入小型的類似Adapter的結(jié)構(gòu),以保證每層的輸出不會因為參數(shù)量相同而同質(zhì)化。Weight Distillation,即采用一個老師模型來引導(dǎo)MiniViT的輸出以增強模型性能。整體的pipeline如下所示:
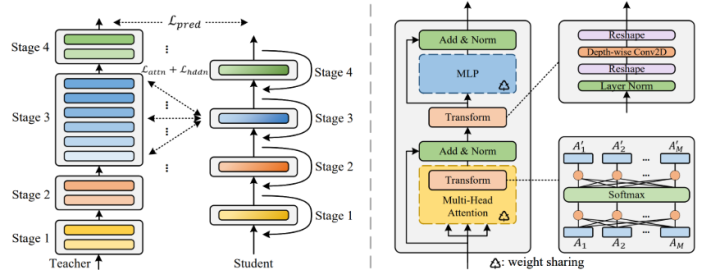
作為一個通用的壓縮方法,作者在DeiT與Swin-Transformer上進(jìn)行了測試。在更小的參數(shù)量下,在ImageNet數(shù)據(jù)集上,Mini版本的模型均取得了不亞于甚至更好的效果。
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
https://proceedings.neurips.cc/paper/2021/file/747d3443e319a22747fbb873e8b2f9f2-Paper.pdf
本文是清華大學(xué)在Nips2021上的一篇工作,其借鑒了模型壓縮中剪枝的思想,但是是對Transformer每一層的輸入token進(jìn)行了稀疏化。Token稀疏化的基本假設(shè)在于:對于一張圖片,一定會存在一些冗余部分對模型的預(yù)測結(jié)果影響很小,對這些部分的削減可以很大程度的增加模型的推理速度。
DynamicViT的具體做法是:通過在每一層間增加一個輕量化的預(yù)測模塊,預(yù)測哪一些部分的token是可以被丟棄掉的。在預(yù)測完后通過一個二進(jìn)制的決策掩碼來完成對token的丟棄。同時,作者修改了訓(xùn)練的目標(biāo)函數(shù),保證了每一層丟棄的token數(shù)量是有限的。
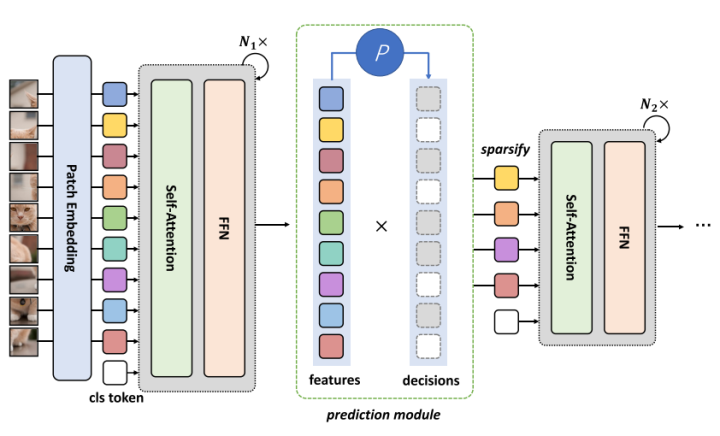
DynamicViT的稀疏化模塊
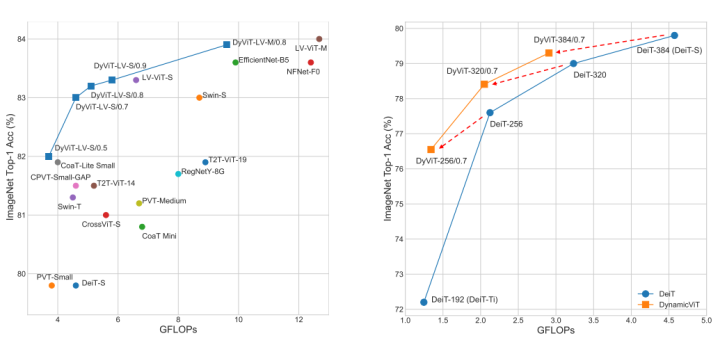
最終,在上述的稀疏化策略下,DynamicViT在原始的ViT基礎(chǔ)上取得了很好的加速,并在模型性能與推理速度之間達(dá)到了一個很好的平衡。
4.多模態(tài)中的輕量化Transformer
多模態(tài)模型往往同時參考了視覺模型與語言模型的設(shè)計,因此也會以Transformer作為其主流架構(gòu)。但多模態(tài)中的輕量化工作較少,筆者整理了比較有代表性的幾篇多模態(tài)輕量化工作供讀者參考。
MiniVLM: A Smaller and Faster Vision-Language Model
https://arxiv.org/pdf/2012.06946.pdf
MiniVLM是微軟在Oscar模型上的輕量化工作。MiniVLM的輕量化基于一個觀察假設(shè):即在大多數(shù)多模態(tài)任務(wù)中,多模態(tài)模型的視覺端不需要特別強的目標(biāo)檢測信息,而目標(biāo)檢測器往往是模型的瓶頸部分。因此,用一個不那么精確的目標(biāo)檢測器可以有效的壓縮模型的參數(shù)量與加快推理速度,同時盡可能的減少性能損失。
為了達(dá)到上述效果,MiniVLM采用了一個基于EfficientNet與Bi-FPN的輕量化目標(biāo)檢測器。同時,為了進(jìn)行進(jìn)一步壓縮,MiniVLM對多模態(tài)Tranformer端也進(jìn)行了壓縮,將原本的Bert結(jié)構(gòu)更換到了更加輕量化的MiniLM,其結(jié)構(gòu)如下所示:
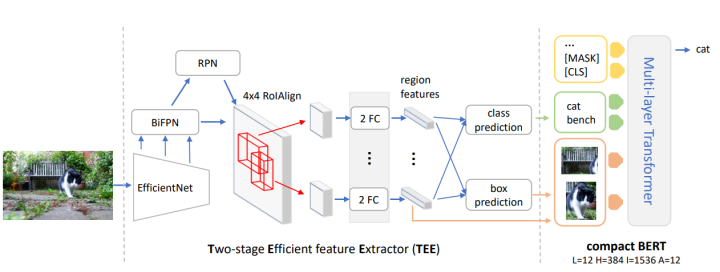
輕量化目標(biāo)檢測器
最終,在可接受的精度損失范圍內(nèi),相較于原本的OSCAR模型,MiniVLM對推理速度進(jìn)行了極大的提升:
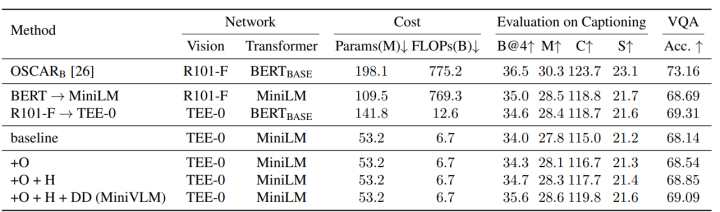
MiniVLM的加速效果與下游任務(wù)性能
Compressing Visual-linguistic Model via Knowledge Distillation
https://arxiv.org/pdf/2104.02096
DistilVLM是MiniVLM工作的延續(xù)。不同的是,在更換目標(biāo)檢測器與Transformer架構(gòu)的同時,DistilVLM同時采用了知識蒸餾來保持模型的性能。DistilVLM的蒸餾策略與TinyBERT相同,同樣是進(jìn)行預(yù)訓(xùn)練階段和微調(diào)階段的兩階段蒸餾:
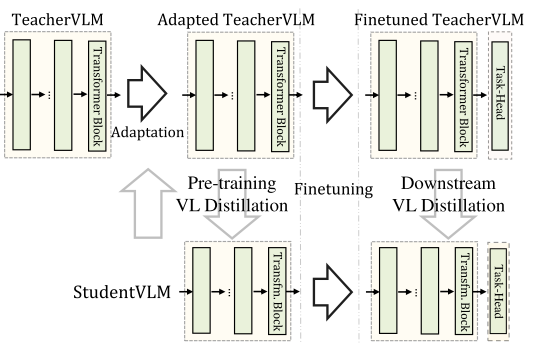
DistilVLM的蒸餾策略
由于采用了不同的目標(biāo)檢測器,在檢測得到的目標(biāo)區(qū)域不同的前提下,后續(xù)的知識蒸餾均是無效的。為了解決這個問題,DistilVLM采用了視覺token對齊的方式,老師模型和學(xué)生模型均采用相同的目標(biāo)檢測器,使得兩個模型的檢測區(qū)域?qū)R,保證了后續(xù)知識蒸餾的有效性。
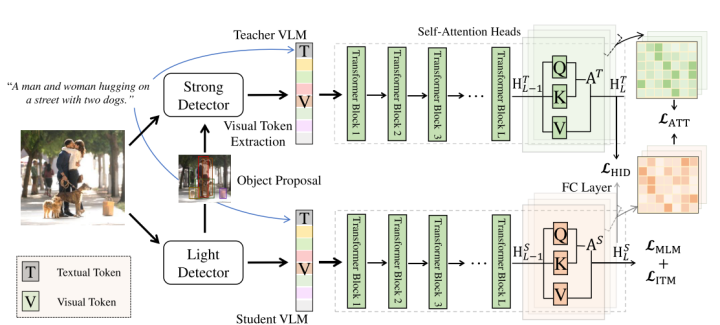
視覺對齊
最終,在與MiniVLM相同參數(shù)和推理速度的前提下,DistilVLM取得了不錯的性能提升。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7335瀏覽量
94773 -
計算機視覺
+關(guān)注
關(guān)注
9文章
1715瀏覽量
47630 -
Transformer
+關(guān)注
關(guān)注
0文章
156瀏覽量
6937
原文標(biāo)題:Fast and Effective!一文速覽輕量化Transformer各領(lǐng)域研究進(jìn)展
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
汽車輕量化丨2018上海國際汽車輕質(zhì)技術(shù)展覽會
碳纖維為何能實現(xiàn)汽車輕量化?
2018上海國際汽車輕質(zhì)技術(shù)展覽會(汽車輕量化)
汽車輕量化采用3D打印
客車車身輕量化分析
汽車輕量化技術(shù)
PACK輕量化設(shè)計介紹及電芯選擇
常見的輕量化材料的分類與汽車輕量化材料的應(yīng)用

低速電動車輕量化的作用和蘊含的技術(shù)分析
康得搭建碳纖維輕量化平臺來推動國內(nèi)纖維輕量化產(chǎn)業(yè)的發(fā)展
日產(chǎn)全新輕量化技術(shù)獲突破,減重75%
淺談輕量化設(shè)計:材料、創(chuàng)新技術(shù)及未來解決方案
分析汽車車燈輕量化技術(shù)研究

最新專利深入“輕量化”!華為這樣做?
5G輕量化網(wǎng)關(guān)是什么




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論