") 使用NVIDIA Triton解決人工智能推斷挑戰(zhàn)
使用NVIDIA Triton解決人工智能推斷挑戰(zhàn)

本節(jié)討論了 Triton 提供的一些開箱即用的關(guān)鍵新特性、工具和服務(wù),可應(yīng)用于生產(chǎn)中的模型部署、運(yùn)行和擴(kuò)展。
使用新管理服務(wù)建立業(yè)務(wù)流程模型
Triton 為高效的多模型推理帶來了一種新的模型編排服務(wù)。該軟件應(yīng)用程序目前處于早期使用階段,有助于以資源高效的方式簡(jiǎn)化 Kubernetes 中 Triton 實(shí)例的部署,其中包含許多模型。此服務(wù)的一些關(guān)鍵功能包括:
按需加載模型,不使用時(shí)卸載模型。
盡可能在單個(gè) GPU 服務(wù)器上放置多個(gè)模型,從而有效地分配 GPU 資源
管理單個(gè)模型和模型組的自定義資源需求
大型語(yǔ)言模型推理
在自然語(yǔ)言處理( NLP )領(lǐng)域,模型的規(guī)模呈指數(shù)級(jí)增長(zhǎng)(圖 1 )。具有數(shù)千億個(gè)參數(shù)的大型 transformer-based models 可以解決許多 NLP 任務(wù),例如文本摘要、代碼生成、翻譯或 PR 標(biāo)題和廣告生成。

圖 1.NLP 模型規(guī)模不斷擴(kuò)大
但這些型號(hào)太大了,無法安裝在單個(gè) GPU 中。例如,具有 17.2B 參數(shù)的圖靈 NLG 需要至少 34 GB 內(nèi)存來存儲(chǔ) FP16 中的權(quán)重和偏差,而具有 175B 參數(shù)的 GPT-3 需要至少 350 GB 內(nèi)存。要使用它們進(jìn)行推理,您需要多 GPU 和越來越多的多節(jié)點(diǎn)執(zhí)行來為模型服務(wù)。
Triton 推理服務(wù)器有一個(gè)稱為 Faster transformer 的后端,它為大型 transformer 模型(如 GPT 、 T5 等)帶來了多 GPU 多節(jié)點(diǎn)推理。大型語(yǔ)言模型通過優(yōu)化和分布式推理功能轉(zhuǎn)換為更快的 transformer 格式,然后使用 Triton 推理服務(wù)器跨 GPU 和節(jié)點(diǎn)運(yùn)行。
圖 2 顯示了使用 Triton 在 CPU 或一個(gè)和兩個(gè) A100 GPU 上運(yùn)行 GPT-J ( 6B )模型時(shí)觀察到的加速。
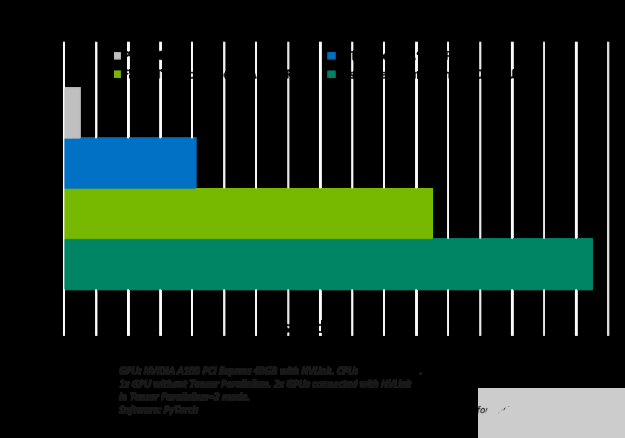
圖 2.Faster transformer 后端的模型加速
基于樹的模型推斷
Triton 可用于在 CPU 和 GPU 上部署和運(yùn)行 XGBoost 、 LightGBM 和 scikit learn RandomForest 等框架中基于樹的模型,并使用 SHAP 值進(jìn)行解釋。它使用去年推出的 Forest Inference Library ( FIL )后端實(shí)現(xiàn)了這一點(diǎn)。
使用 Triton 進(jìn)行基于樹的模型推理的優(yōu)點(diǎn)是在機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型之間的推理具有更好的性能和標(biāo)準(zhǔn)化。它特別適用于實(shí)時(shí)應(yīng)用程序,如欺詐檢測(cè),其中可以輕松使用較大的模型以獲得更好的準(zhǔn)確性。
使用模型分析器優(yōu)化模型配置
高效的推理服務(wù)需要為參數(shù)選擇最佳值,例如批大小、模型并發(fā)性或給定目標(biāo)處理器的精度。這些值指示吞吐量、延遲和內(nèi)存需求。在每個(gè)參數(shù)的值范圍內(nèi)手動(dòng)嘗試數(shù)百種組合可能需要數(shù)周時(shí)間。
Triton 模型分析器工具將找到最佳配置參數(shù)所需的時(shí)間從幾周減少到幾天甚至幾小時(shí)。它通過對(duì)給定的目標(biāo)處理器脫機(jī)運(yùn)行數(shù)百個(gè)具有不同批大小值和模型并發(fā)性的推理模擬來實(shí)現(xiàn)這一點(diǎn)。最后,它提供了如圖 3 所示的圖表,可以方便地選擇最佳部署配置。
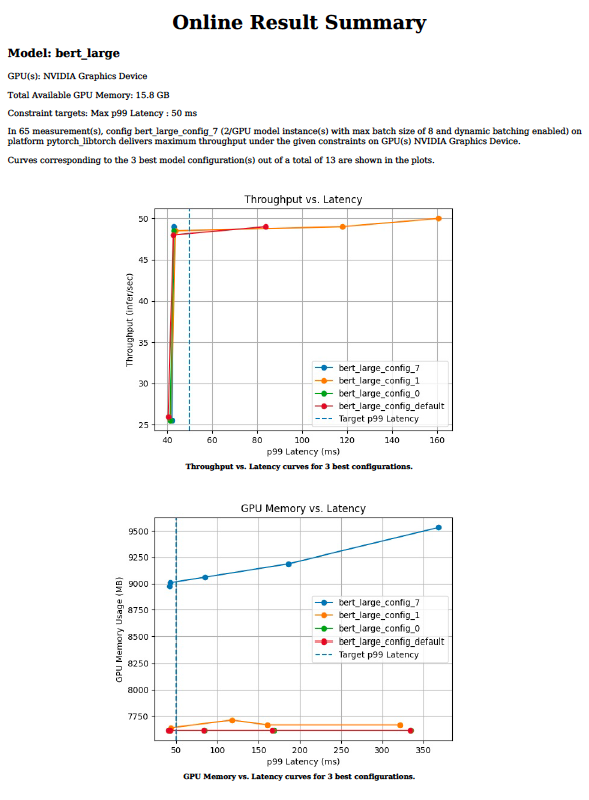
圖 3.模型分析器工具的輸出圖表
使用業(yè)務(wù)邏輯腳本為管道建模
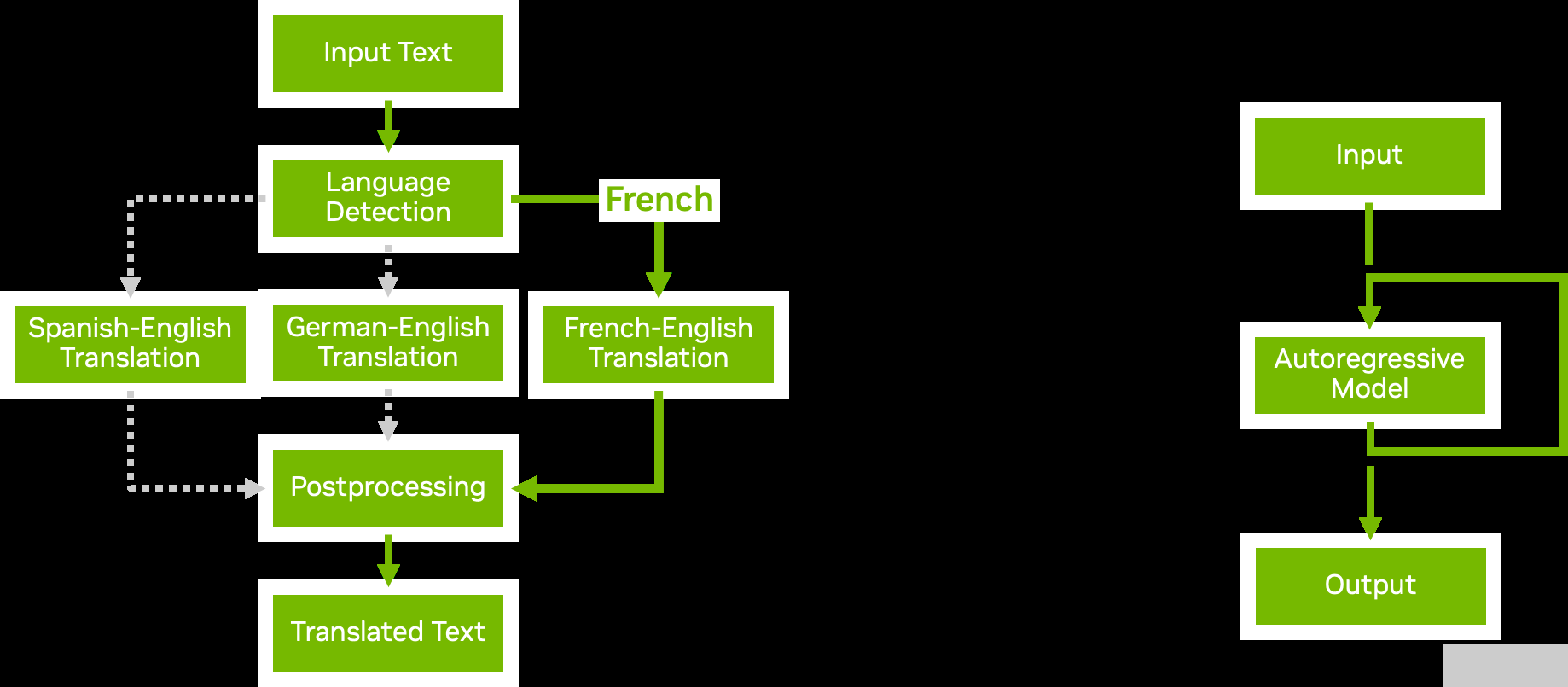
圖 4.模型集成與業(yè)務(wù)邏輯腳本
使用 Triton ?聲波風(fēng)廓線儀的模型集成功能,您可以構(gòu)建復(fù)雜的模型管道和集成,其中包含多個(gè)模型以及預(yù)處理和后處理步驟。業(yè)務(wù)邏輯腳本使您能夠在管道中添加條件、循環(huán)和步驟的重新排序。
使用 Python 或 C ++后端,您可以定義一個(gè)自定義腳本,該腳本可以根據(jù)您選擇的條件調(diào)用 Triton 提供的任何其他模型。 Triton 有效地將數(shù)據(jù)傳遞到新調(diào)用的模型,盡可能避免不必要的內(nèi)存復(fù)制。然后將結(jié)果傳遞回自定義腳本,您可以從中繼續(xù)進(jìn)一步處理或返回結(jié)果。
圖 4 顯示了兩個(gè)業(yè)務(wù)邏輯腳本示例:
Conditional execution 通過避免執(zhí)行不必要的模型,幫助您更有效地使用資源。
Autoregressive models 與 transformer 解碼一樣,要求模型的輸出反復(fù)反饋到自身,直到達(dá)到某個(gè)條件。業(yè)務(wù)邏輯腳本中的循環(huán)使您能夠?qū)崿F(xiàn)這一點(diǎn)。
自動(dòng)生成模型配置
Triton 可以自動(dòng)為您的模型生成配置文件,以加快部署速度。對(duì)于 TensorRT 、 TensorFlow 和 ONNX 模型,當(dāng) Triton 在存儲(chǔ)庫(kù)中未檢測(cè)到配置文件時(shí),會(huì)生成運(yùn)行模型所需的最低配置設(shè)置。
Triton 還可以檢測(cè)您的模型是否支持批推理。它將max_batch_size設(shè)置為可配置的默認(rèn)值。
您還可以在自己的自定義 Python 和 C ++后端中包含命令,以便根據(jù)腳本內(nèi)容自動(dòng)生成模型配置文件。當(dāng)您有許多模型需要服務(wù)時(shí),這些特性特別有用,因?yàn)樗苊饬耸謩?dòng)創(chuàng)建配置文件的步驟。
解耦輸入處理
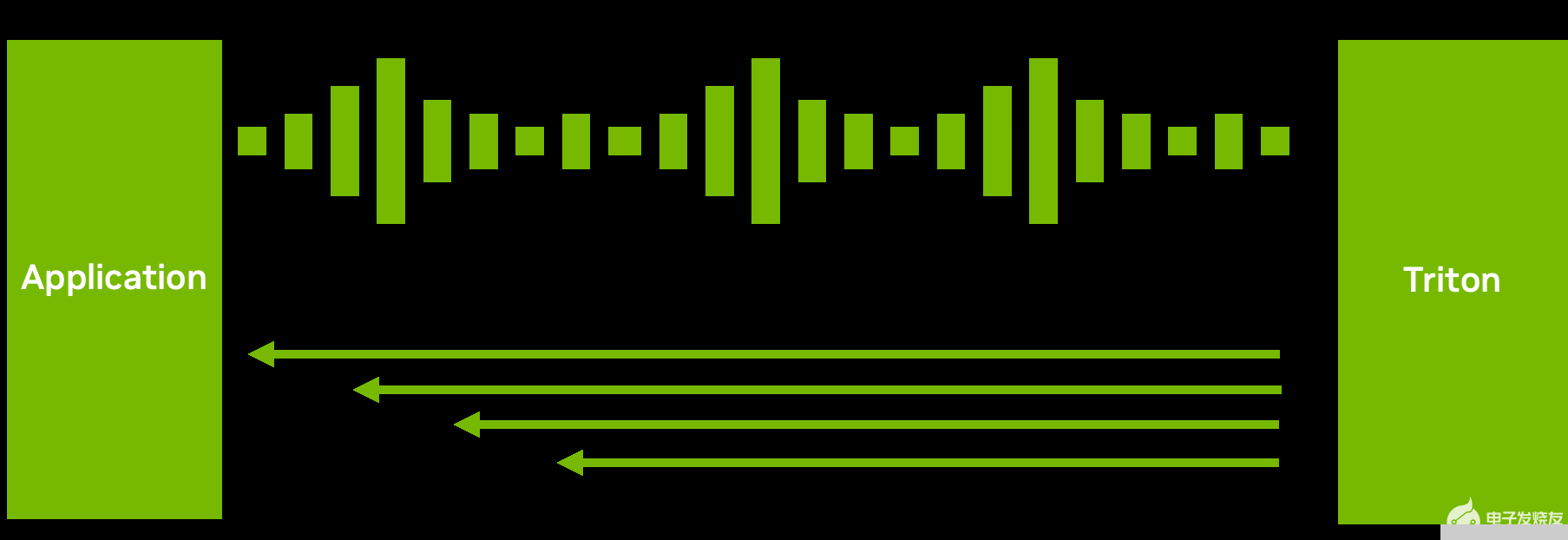
圖 5.通過解耦輸入處理實(shí)現(xiàn)的一個(gè)請(qǐng)求到多個(gè)響應(yīng)場(chǎng)景
雖然許多推理設(shè)置需要推理請(qǐng)求和響應(yīng)之間的一對(duì)一對(duì)應(yīng),但這并不總是最佳數(shù)據(jù)流。
例如,對(duì)于 ASR 模型,發(fā)送完整的音頻并等待模型完成執(zhí)行可能不會(huì)帶來良好的用戶體驗(yàn)。等待時(shí)間可能很長(zhǎng)。相反, Triton 可以將轉(zhuǎn)錄的文本以多個(gè)短塊的形式發(fā)送回來(圖 5 ),從而減少了第一次響應(yīng)的延遲和時(shí)間。
通過 C ++或 Python 后端的解耦模型處理,您可以為單個(gè)請(qǐng)求發(fā)送多個(gè)響應(yīng)。當(dāng)然,您也可以做相反的事情:分塊發(fā)送多個(gè)小請(qǐng)求,然后返回一個(gè)大響應(yīng)。此功能在如何處理和發(fā)送推理響應(yīng)方面提供了靈活性。
開始可擴(kuò)展 AI 模型部署
您可以使用 Triton 部署、運(yùn)行和縮放 AI 模型,以有效緩解您在多個(gè)框架、多樣化基礎(chǔ)設(shè)施、大型語(yǔ)言模型、優(yōu)化模型配置等方面可能面臨的 AI 推理挑戰(zhàn)。
Triton 推理服務(wù)器是開源的,支持所有主要模型框架,如 TensorFlow 、 PyTorch 、 TensorRT 、 XGBoost 、 ONNX 、 OpenVINO 、 Python ,甚至支持 GPU 和 CPU 系統(tǒng)上的自定義框架。探索將 Triton 與任何應(yīng)用程序、部署工具和平臺(tái)、云端、本地和邊緣集成的更多方法。
關(guān)于作者
Shankar Chandrasekaran 是 NVIDIA 數(shù)據(jù)中心 GPU 團(tuán)隊(duì)的高級(jí)產(chǎn)品營(yíng)銷經(jīng)理。他負(fù)責(zé) GPU 軟件基礎(chǔ)架構(gòu)營(yíng)銷,以幫助 IT 和 DevOps 輕松采用 GPU 并將其無縫集成到其基礎(chǔ)架構(gòu)中。在 NVIDIA 之前,他曾在小型和大型科技公司擔(dān)任工程、運(yùn)營(yíng)和營(yíng)銷職位。他擁有商業(yè)和工程學(xué)位。
Neal Vaidya 是 NVIDIA 深度學(xué)習(xí)軟件的技術(shù)營(yíng)銷工程師。他負(fù)責(zé)開發(fā)和展示以開發(fā)人員為中心的關(guān)于深度學(xué)習(xí)框架和推理解決方案的內(nèi)容。他擁有杜克大學(xué)統(tǒng)計(jì)學(xué)學(xué)士學(xué)位。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135455 -
服務(wù)器
+關(guān)注
關(guān)注
14文章
10253瀏覽量
91489 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5599瀏覽量
124398
發(fā)布評(píng)論請(qǐng)先 登錄
淺談人工智能(2)

開發(fā)智能體配置-內(nèi)容合規(guī)
Magna AI加入NVIDIA Inception計(jì)劃,推動(dòng)生產(chǎn)級(jí)人工智能規(guī)模化發(fā)展
利用超微型 Neuton ML 模型解鎖 SoC 邊緣人工智能
Lambda采用Supermicro NVIDIA Blackwell GPU服務(wù)器集群構(gòu)建人工智能工廠
“人工智能+”,走老路難賺到新錢

挖到寶了!人工智能綜合實(shí)驗(yàn)箱,高校新工科的寶藏神器
挖到寶了!比鄰星人工智能綜合實(shí)驗(yàn)箱,高校新工科的寶藏神器!
超小型Neuton機(jī)器學(xué)習(xí)模型, 在任何系統(tǒng)級(jí)芯片(SoC)上解鎖邊緣人工智能應(yīng)用.
迅為RK3588開發(fā)板Linux安卓麒麟瑞芯微國(guó)產(chǎn)工業(yè)AI人工智能
最新人工智能硬件培訓(xùn)AI 基礎(chǔ)入門學(xué)習(xí)課程參考2025版(大模型篇)
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實(shí)踐

維諦加速推進(jìn)人工智能基礎(chǔ)設(shè)施演進(jìn),助力NVIDIA 800 VDC 電源架構(gòu)發(fā)布

開售RK3576 高性能人工智能主板
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺(tái),加速企業(yè)人工智能應(yīng)用




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論