") 內(nèi)存池在棧結(jié)構(gòu)中的性能設(shè)計(jì)實(shí)現(xiàn)
內(nèi)存池在棧結(jié)構(gòu)中的性能設(shè)計(jì)實(shí)現(xiàn)

一、概述
在 C/C++ 中,內(nèi)存管理是一個(gè)非常棘手的問題,我們在編寫一個(gè)程序的時(shí)候幾乎不可避免的要遇到內(nèi)存的分配邏輯,這時(shí)候隨之而來的有這樣一些問題:是否有足夠的內(nèi)存可供分配?分配失敗了怎么辦? 如何管理自身的內(nèi)存使用情況? 等等一系列問題。在一個(gè)高可用的軟件中,如果我們僅僅單純的向操作系統(tǒng)去申請內(nèi)存,當(dāng)出現(xiàn)內(nèi)存不足時(shí)就退出軟件,是明顯不合理的。
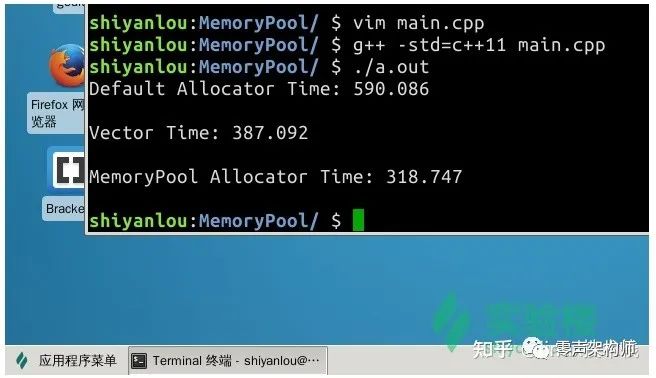
正確的思路應(yīng)該是在內(nèi)存不足的時(shí),考慮如何管理并優(yōu)化自身已經(jīng)使用的內(nèi)存,這樣才能使得軟件變得更加可用。本次項(xiàng)目我們將實(shí)現(xiàn)一個(gè)內(nèi)存池,并使用一個(gè)棧結(jié)構(gòu)來測試我們的內(nèi)存池提供的分配性能。最終,我們要實(shí)現(xiàn)的內(nèi)存池在棧結(jié)構(gòu)中的性能,要遠(yuǎn)高于使用 std::allocator 和 std::vector,如下圖所示:
項(xiàng)目涉及的知識點(diǎn)
C++ 中的內(nèi)存分配器 std::allocator
內(nèi)存池技術(shù)
手動實(shí)現(xiàn)模板鏈?zhǔn)綏?br />
鏈?zhǔn)綏:土斜項(xiàng)5男阅鼙容^
內(nèi)存池簡介
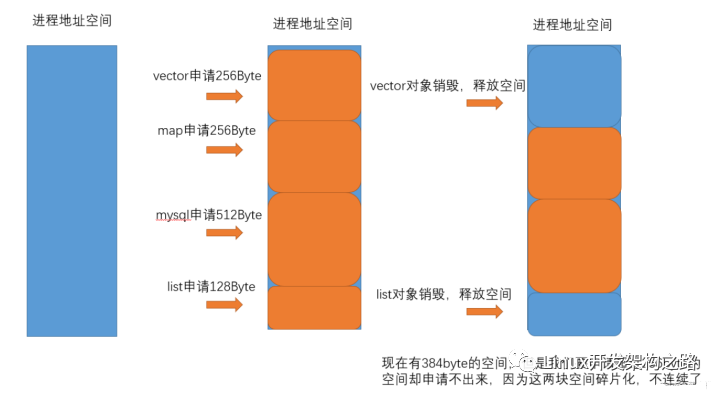
內(nèi)存池是池化技術(shù)中的一種形式。通常我們在編寫程序的時(shí)候回使用 new delete 這些關(guān)鍵字來向操作系統(tǒng)申請內(nèi)存,而這樣造成的后果就是每次申請內(nèi)存和釋放內(nèi)存的時(shí)候,都需要和操作系統(tǒng)的系統(tǒng)調(diào)用打交道,從堆中分配所需的內(nèi)存。如果這樣的操作太過頻繁,就會找成大量的內(nèi)存碎片進(jìn)而降低內(nèi)存的分配性能,甚至出現(xiàn)內(nèi)存分配失敗的情況。
而內(nèi)存池就是為了解決這個(gè)問題而產(chǎn)生的一種技術(shù)。從內(nèi)存分配的概念上看,內(nèi)存申請無非就是向內(nèi)存分配方索要一個(gè)指針,當(dāng)向操作系統(tǒng)申請內(nèi)存時(shí),
操作系統(tǒng)需要進(jìn)行復(fù)雜的內(nèi)存管理調(diào)度之后,才能正確的分配出一個(gè)相應(yīng)的指針。而這個(gè)分配的過程中,我們還面臨著分配失敗的風(fēng)險(xiǎn)。
所以,每一次進(jìn)行內(nèi)存分配,就會消耗一次分配內(nèi)存的時(shí)間,設(shè)這個(gè)時(shí)間為 T,那么進(jìn)行 n 次分配總共消耗的時(shí)間就是 nT;如果我們一開始就確定好我們可能需要多少內(nèi)存,那么在最初的時(shí)候就分配好這樣的一塊內(nèi)存區(qū)域,當(dāng)我們需要內(nèi)存的時(shí)候,直接從這塊已經(jīng)分配好的內(nèi)存中使用即可,那么總共需要的分配時(shí)間僅僅只有 T。當(dāng) n 越大時(shí),節(jié)約的時(shí)間就越多。
二、主函數(shù)設(shè)計(jì)
我們要設(shè)計(jì)實(shí)現(xiàn)一個(gè)高性能的內(nèi)存池,那么自然避免不了需要對比已有的內(nèi)存,而比較內(nèi)存池對內(nèi)存的分配性能,就需要實(shí)現(xiàn)一個(gè)需要對內(nèi)存進(jìn)行動態(tài)分配的結(jié)構(gòu)(比如:鏈表?xiàng)#瑸榇耍梢詫懗鋈缦碌拇a:


在上面的兩段代碼中,StackAlloc 是一個(gè)鏈表?xiàng)#邮軆蓚€(gè)模板參數(shù),第一個(gè)參數(shù)是棧中的元素類型,第二個(gè)參數(shù)就是棧使用的內(nèi)存分配器。
因此,這個(gè)內(nèi)存分配器的模板參數(shù)就是整個(gè)比較過程中唯一的變量,使用默認(rèn)分配器的模板參數(shù)為 std::allocator,而使用內(nèi)存池的模板參數(shù)為 MemoryPool。
std::allocator 是 C++標(biāo)準(zhǔn)庫中提供的默認(rèn)分配器,他的特點(diǎn)就在于我們在 使用 new 來申請內(nèi)存構(gòu)造新對象的時(shí)候,勢必要調(diào)用類對象的默認(rèn)構(gòu)造函數(shù),而使用 std::allocator 則可以將內(nèi)存分配和對象的構(gòu)造這兩部分邏輯給分離開來,使得分配的內(nèi)存是原始、未構(gòu)造的。
下面我們來實(shí)現(xiàn)這個(gè)鏈表?xiàng)!?/p>
三、模板鏈表?xiàng)?/p>
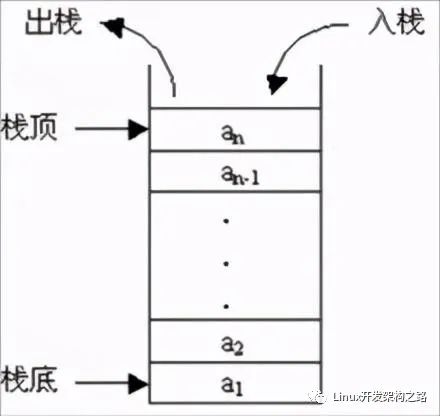
棧的結(jié)構(gòu)非常的簡單,沒有什么復(fù)雜的邏輯操作,其成員函數(shù)只需要考慮兩個(gè)基本的操作:入棧、出棧。為了操作上的方便,我們可能還需要這樣一些方法:判斷棧是否空、清空棧、獲得棧頂元素。


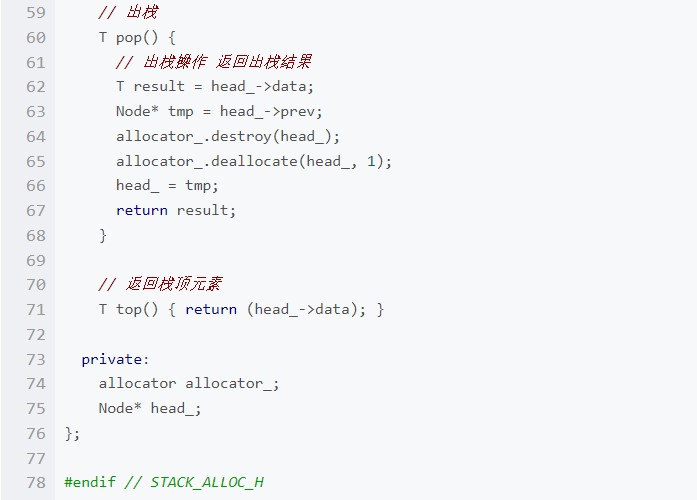
簡單的邏輯諸如構(gòu)造、析構(gòu)、判斷棧是否空、返回棧頂元素的邏輯都非常簡單,直接在上面的定義中實(shí)現(xiàn)了,下面我們來實(shí)現(xiàn) clear(), push() 和 pop() 這三個(gè)重要的邏輯:
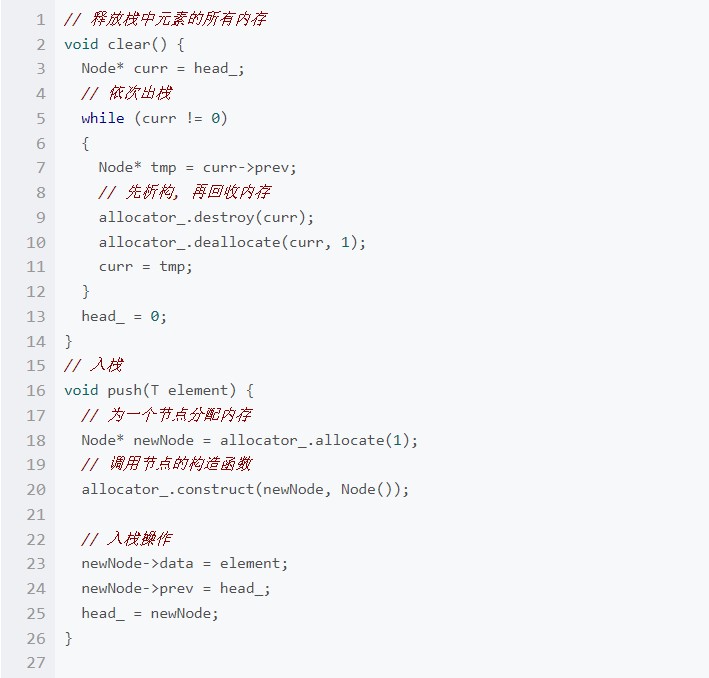

至此,我們完成了整個(gè)模板鏈表?xiàng)#F(xiàn)在我們可以先注釋掉 main() 函數(shù)中使用內(nèi)存池部分的代碼來測試這個(gè)連表?xiàng)5膬?nèi)存分配情況,我們就能夠得到這樣的結(jié)果:
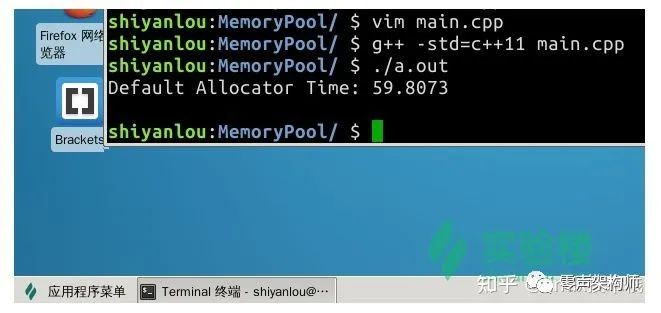
在使用 std::allocator 的默認(rèn)內(nèi)存分配器中,在
#define ELEMS 10000000 #define REPS 100
的條件下,總共花費(fèi)了近一分鐘的時(shí)間。
如果覺得花費(fèi)的時(shí)間較長,不愿等待,則你嘗試可以減小這兩個(gè)值
總結(jié)
本節(jié)我們實(shí)現(xiàn)了一個(gè)用于測試性能比較的模板鏈表?xiàng)#壳暗拇a如下。在下一節(jié)中,我們開始詳細(xì)實(shí)現(xiàn)我們的高性能內(nèi)存池。



二、設(shè)計(jì)內(nèi)存池
在上一節(jié)實(shí)驗(yàn)中,我們在模板鏈表?xiàng)V惺褂昧四J(rèn)構(gòu)造器來管理?xiàng)2僮髦械脑貎?nèi)存,一共涉及到了 rebind::other, allocate(), dealocate(), construct(), destroy()這些關(guān)鍵性的接口。所以為了讓代碼直接可用,我們同樣應(yīng)該在內(nèi)存池中設(shè)計(jì)同樣的接口:


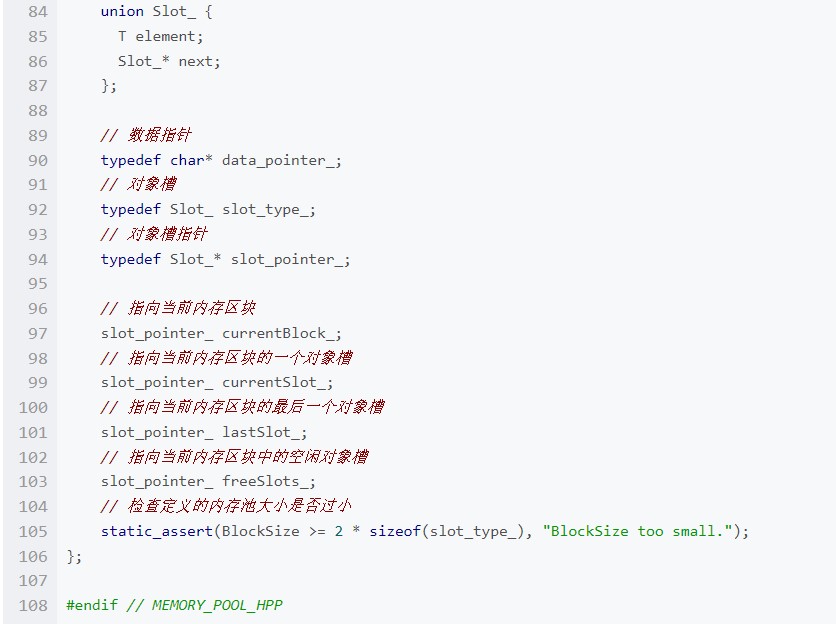
在上面的類設(shè)計(jì)中可以看到,在這個(gè)內(nèi)存池中,其實(shí)是使用鏈表來管理整個(gè)內(nèi)存池的內(nèi)存區(qū)塊的。內(nèi)存池首先會定義固定大小的基本內(nèi)存區(qū)塊(Block),然后在其中定義了一個(gè)可以實(shí)例化為存放對象內(nèi)存槽的對象槽(Slot_)和對象槽指針的一個(gè)聯(lián)合。然后在區(qū)塊中,定義了四個(gè)關(guān)鍵性質(zhì)的指針,它們的作用分別是:
currentBlock_: 指向當(dāng)前內(nèi)存區(qū)塊的指針
currentSlot_: 指向當(dāng)前內(nèi)存區(qū)塊中的對象槽
lastSlot_: 指向當(dāng)前內(nèi)存區(qū)塊中的最后一個(gè)對象槽
freeSlots_: 指向當(dāng)前內(nèi)存區(qū)塊中所有空閑的對象槽
梳理好整個(gè)內(nèi)存池的設(shè)計(jì)結(jié)構(gòu)之后,我們就可以開始實(shí)現(xiàn)關(guān)鍵性的邏輯了。
三、實(shí)現(xiàn)
MemoryPool::construct() 實(shí)現(xiàn)
MemoryPool::construct() 的邏輯是最簡單的,我們需要實(shí)現(xiàn)的,僅僅只是調(diào)用信件對象的構(gòu)造函數(shù)即可,因此:

MemoryPool::deallocate() 實(shí)現(xiàn)
MemoryPool::deallocate() 是在對象槽中的對象被析構(gòu)后才會被調(diào)用的,主要目的是銷毀內(nèi)存槽。其邏輯也不復(fù)雜:

MemoryPool::~MemoryPool() 實(shí)現(xiàn)
析構(gòu)函數(shù)負(fù)責(zé)銷毀整個(gè)內(nèi)存池,因此我們需要逐個(gè)刪除掉最初向操作系統(tǒng)申請的內(nèi)存塊:

MemoryPool::allocate() 實(shí)現(xiàn)
MemoryPool::allocate() 毫無疑問是整個(gè)內(nèi)存池的關(guān)鍵所在,但實(shí)際上理清了整個(gè)內(nèi)存池的設(shè)計(jì)之后,其實(shí)現(xiàn)并不復(fù)雜。具體實(shí)現(xiàn)如下:

四、與 std::vector 的性能對比
我們知道,對于棧來說,鏈棧其實(shí)并不是最好的實(shí)現(xiàn)方式,因?yàn)檫@種結(jié)構(gòu)的棧不可避免的會涉及到指針相關(guān)的操作,同時(shí),還會消耗一定量的空間來存放節(jié)點(diǎn)之間的指針。事實(shí)上,我們可以使用 std::vector 中的 push_back() 和 pop_back() 這兩個(gè)操作來模擬一個(gè)棧,我們不妨來對比一下這個(gè) std::vector 與我們所實(shí)現(xiàn)的內(nèi)存池在性能上誰高誰低,我們在 主函數(shù)中加入如下代碼:

這時(shí)候,我們重新編譯代碼,就能夠看出這里面的差距了:
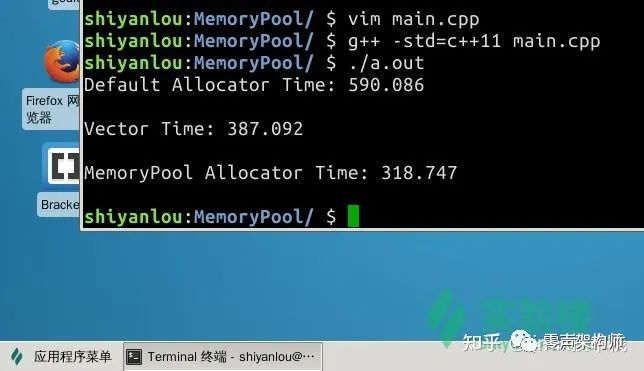
首先是使用默認(rèn)分配器的鏈表?xiàng)K俣茸盥浯问鞘褂?std::vector 模擬的棧結(jié)構(gòu),在鏈表?xiàng)5幕A(chǔ)上大幅度削減了時(shí)間。
std::vector 的實(shí)現(xiàn)方式其實(shí)和內(nèi)存池較為類似,在 std::vector 空間不夠用時(shí),會拋棄現(xiàn)在的內(nèi)存區(qū)域重新申請一塊更大的區(qū)域,并將現(xiàn)在內(nèi)存區(qū)域中的數(shù)據(jù)整體拷貝一份到新區(qū)域中。
最后,對于我們實(shí)現(xiàn)的內(nèi)存池,消耗的時(shí)間最少,即內(nèi)存分配性能最佳,完成了本項(xiàng)目。
總結(jié)
本節(jié)中,我們實(shí)現(xiàn)了我們上節(jié)實(shí)驗(yàn)中未實(shí)現(xiàn)的內(nèi)存池,完成了整個(gè)項(xiàng)目的目標(biāo)。 這個(gè)內(nèi)存池不僅精簡而且高效,整個(gè)內(nèi)存池的完整代碼如下:



審核編輯:劉清
-
分配器
+關(guān)注
關(guān)注
0文章
213瀏覽量
27310 -
內(nèi)存管理
+關(guān)注
關(guān)注
0文章
171瀏覽量
14882 -
C++語言
+關(guān)注
關(guān)注
0文章
147瀏覽量
7685
原文標(biāo)題:C++ 實(shí)現(xiàn)高性能內(nèi)存池項(xiàng)目實(shí)現(xiàn)
文章出處:【微信號:程序喵大人,微信公眾號:程序喵大人】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
C++內(nèi)存池的設(shè)計(jì)與實(shí)現(xiàn)
【原創(chuàng)】C語言中的動態(tài)內(nèi)存-----棧內(nèi)存
內(nèi)存池可以調(diào)節(jié)內(nèi)存的大小嗎
內(nèi)存池的概念和實(shí)現(xiàn)原理概述
關(guān)于RT-Thread內(nèi)存管理的內(nèi)存池簡析
RT-Thread內(nèi)存管理之內(nèi)存池實(shí)現(xiàn)分析
什么是棧?數(shù)據(jù)結(jié)構(gòu)中棧如何實(shí)現(xiàn)
C語言程序的動態(tài)內(nèi)存中棧內(nèi)存區(qū)域的概念
什么是內(nèi)存池

高并發(fā)內(nèi)存池項(xiàng)目實(shí)現(xiàn)
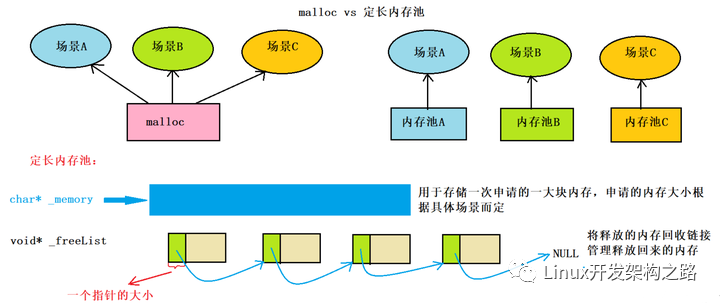
了解連接池、線程池、內(nèi)存池、異步請求池
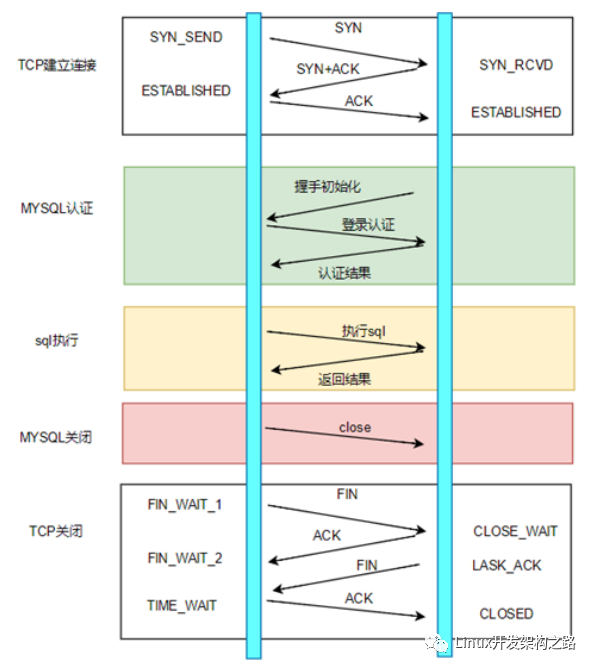
如何實(shí)現(xiàn)一個(gè)高性能內(nèi)存池
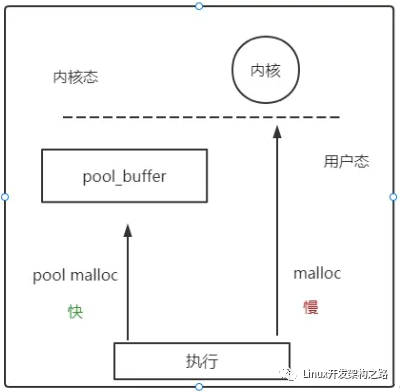
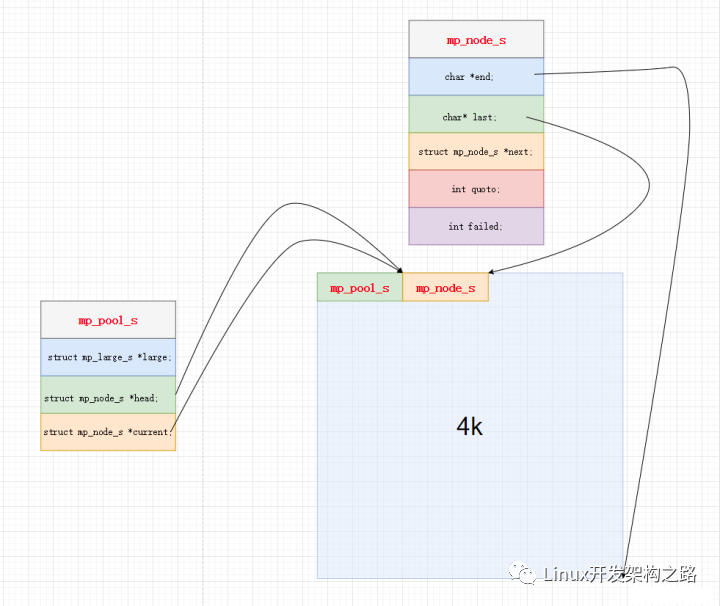
程序內(nèi)存分區(qū)中的堆與棧
內(nèi)存池主要解決的問題



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論