 對比學習在開放域段落檢索和主題挖掘中的應用
對比學習在開放域段落檢索和主題挖掘中的應用

引言
對比學習是一種無監督學習方法。它的改進方向主要包括兩個部分:1.改進正負樣本的抽樣策略 2.改進對比學習框架 本篇主要介紹了3篇源自ACL2022的有關對比學習的文章,前2篇文章涉及開放域段落檢索,最后一篇文章涉及主題挖掘。
文章概覽
1. Multi-View Document Representation Learning for Open-domain Dense Retrieval
開放域密集檢索的多視圖文檔表示學習 論文地址:https://arxiv.org/pdf/2203.08372.pdf 密集檢索通常使用bi-encoder生成查詢和文檔的單一向量表示。然而,一個文檔通常可以從不同的角度回答多個查詢。因此,文檔的單個向量表示很難與多個查詢相匹配,并面臨著語義不匹配的問題。文章提出了一種多視圖文檔表示學習框架,通過viewer生成多個嵌入。
2. Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval
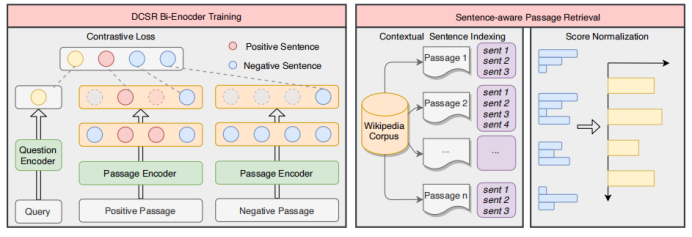
開放域段落檢索中的句子感知對比學習 論文地址:https://arxiv.org/pdf/2110.07524v3.pdf 一篇文章可能能夠回答多個問題,這在對比學習中會導致嚴重的問題,文中將其稱之為Contrastive Conflicts。基于此,文章提出了將段落表示分解為句子級的段落表示的方法,將其稱之為Dense Contextual Sentence Representation (DCSR)。
3. UCTopic: Unsupervised Contrastive Learning for Phrase Representations and Topic Mining
基于短語表示和主題挖掘的無監督對比學習 論文地址:https://arxiv.org/pdf/2202.13469v1.pdf 高質量的短語表示對于在文檔中尋找主題和相關術語至關重要。現有的短語表示學習方法要么簡單地以無上下文的方式組合單詞,要么依賴于廣泛的注釋來感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于上下文感知的短語表示和主題挖掘。
論文細節
1

1-1
動機
密集檢索在大規模文檔集合的第一階段檢索方面取得了很大的進展,這建立在bi-encoder生成查詢和文檔的單一向量表示的基礎上。然而,一個文檔通常可以從不同的角度回答多個查詢。因此,文檔的單個向量表示很難與多個查詢相匹配,并面臨著語義不匹配的問題。文章提出了一種多視圖文檔表示學習框架,旨在生成多視圖嵌入來表示文檔,并強制它們與不同的查詢對齊。為了防止多視圖嵌入變成同一個嵌入,文章進一步提出了一個具有退火溫度的全局-局部損失,以鼓勵多個viewer更好地與不同潛在查詢對齊。

1-2
模型
開放域段落檢索是給定一個由數百萬個段落組成的超大文本語料庫,其目的是檢索一個最相關的段落集合,作為一個給定問題的證據。密集檢索已成為開放域段落檢索的重要有效方法。典型的密集檢索器通常采用雙編碼器結構,雙編碼器受制于單向量表示,面臨表示能力的上界。在上圖中,我們還發現單個向量表示不能很好地匹配多視圖查詢。該文檔對應于反映不同觀點的四個不同的問題,每個問題都匹配不同的句子和答案。為了解決這個問題,文章提出了Multi-View document Representations learning framework, MVR。
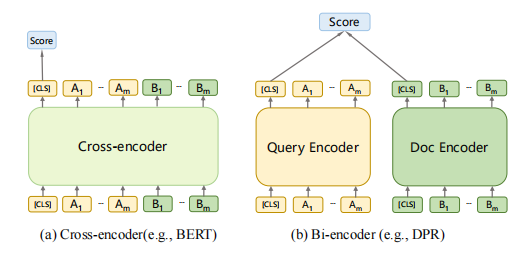
1-3 基于cross-encoder的模型需要計算昂貴的cross-attention,所以cross-encoder不用于第一階段的大規模檢索,而通常被用于第二階段的排序中。在第一階段檢索中,bi-encoder是最常被采用的架構,因為它可以使用ANN加速。
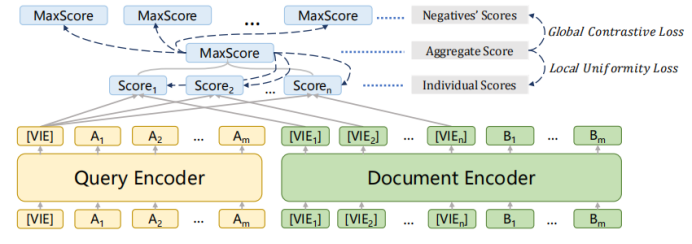
1-4 模型采用上述的bi-encoder結構,這種結構能夠預先計算好query和document的向量,提升檢索速度。Encoder采用bert。一些工作發現[CLS]能夠匯集整個句子/文檔的含義。為了獲得更加精細的語義表示,使用多個[VIE]來替代[CLS],將[VIE]添加在文檔的開頭,為了避免多個[VIE]對原始輸入句子位置編碼的影響,將的位置id設置為0。由于查詢比文檔短得多,并且通常表示一個具體的含義,因此只為查詢生成一個嵌入。查詢和文檔之間的相似度分數如下式計算,其中sim代表兩個向量的內積。 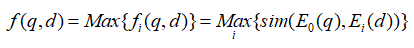 為了鼓勵多個viewer更好地適應不同的潛在查詢,文章提出了一個配備退火溫度的全局-局部損失。損失函數:
為了鼓勵多個viewer更好地適應不同的潛在查詢,文章提出了一個配備退火溫度的全局-局部損失。損失函數: 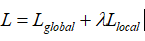 其中:
其中:
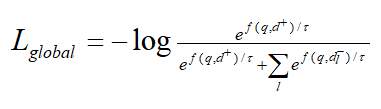
記文檔正樣本為d+,負樣本為。全局對比損失繼承自傳統的bi-encoder結構。
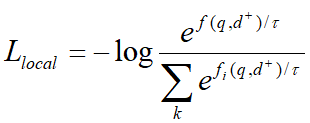
強制與query更加緊密的對齊,并與其他viewer區別開來。為了進一步鼓勵更多不同的viewer被激活,文章采用了下式中的退火溫度。 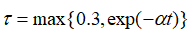 剛開始時,較大的能使得每個viewer被公平的選擇,并從訓練中返回梯度,隨著訓練的進行,?將降低,訓練更加穩定。在推理中,構建所有文檔嵌入的索引,然后利用近似最近鄰ANN檢索。 ?
剛開始時,較大的能使得每個viewer被公平的選擇,并從訓練中返回梯度,隨著訓練的進行,?將降低,訓練更加穩定。在推理中,構建所有文檔嵌入的索引,然后利用近似最近鄰ANN檢索。 ?
實驗
數據集
實驗采用的數據集包括Natural Questions ,TriviaQA,SQuAD Open。數據集 Natural Questions:是一個流行的開放域檢索數據集,其中的問題是真實的谷歌搜索查詢,答案是從維基百科中手動標注的。TriviaQA:包含了一系列瑣碎的問題,其答案最初是從網上提取出來的。SQuADOpen:包含了來自閱讀理解數據集的問題和答案,它已被廣泛應用于開放域檢索研究。
實驗結果
計算不同文檔對應的查閱數,在3個數據集上得到的平均值為2.7,1.5,1.2,這表明多視圖問題是常見的。
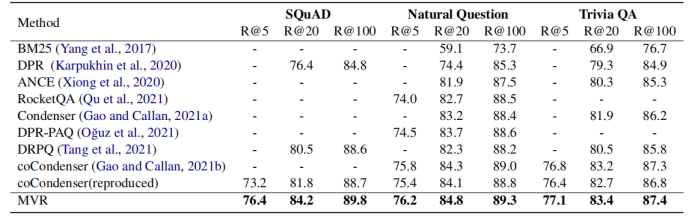
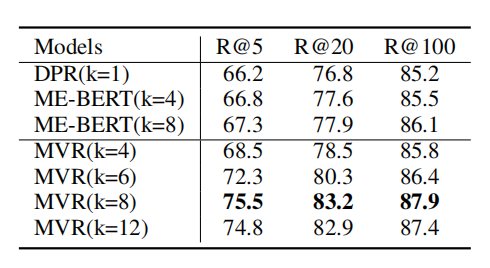
1-5 根據上表所示,MVR得到了最好的結果。MVR在SQuAD數據集上取得了最大的提升,這是因為該數據集單個文檔對應更多的查詢。這說明MVR比其他模型更能解決多視圖問題。
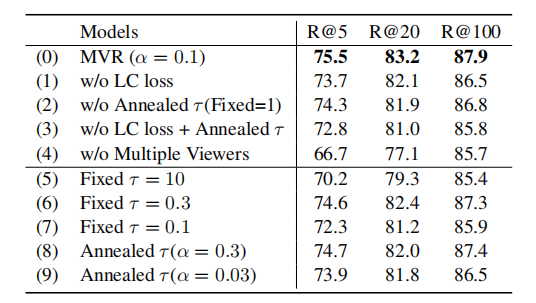
1-6
1-7
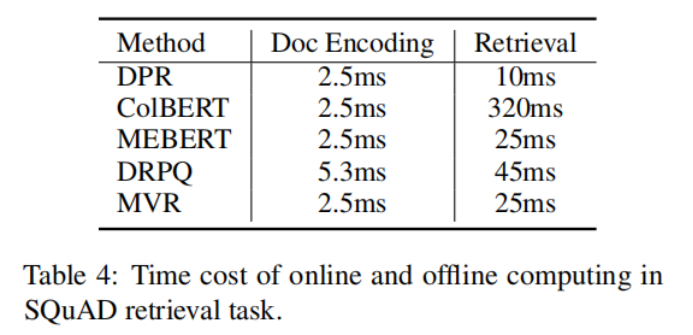
?1-8 上表說明了,MVR與其他方法相比,需要的編碼時間和檢索時間較小。
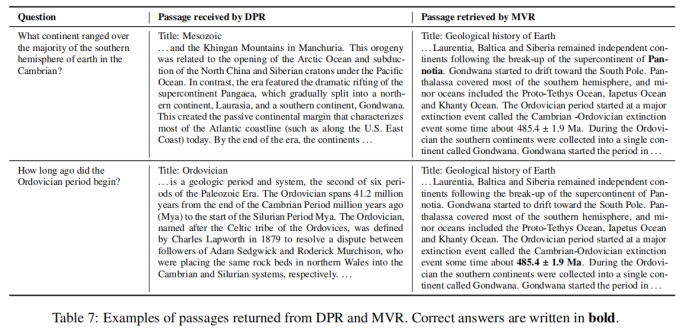
1-9 上表對DPR和MVR的檢索結果進行了比較,結果表明MVR能夠捕獲更加細粒度的語義信息,返回正確的答案。
2

2-1
動機
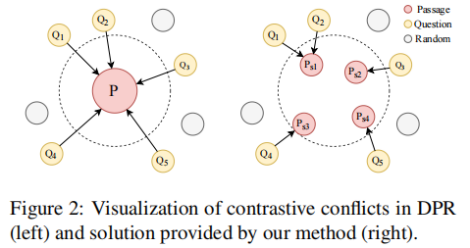
本文的動機與上文基本相同。一個段落可能能夠回答多個問題,這在對比學習框架中會導致嚴重的問題,文中將其稱之為Contrastive Conflicts。這主要包括兩個方面(1)相似性的轉移,由于一個段落可能是多個問題的答案,當最大化對應段落和問題的相似性時,會同時讓問題之間更為相似,但是這些問題在語義上不同。(2)在大批量上的多重標簽。在大批量處理時,可能出現使得同一個段落為正的多個問題,在當前采用的技術中,該段落將被同時作為這些問題的正樣本和負樣本,這在邏輯上是不合理的。由于一對多問題是Contrastive Conflicts的直接原因,文章提出了將密集的段落表示分解為句子級的段落表示的方法,將其稱之為Dense Contextual Sentence Representation (DCSR)。
2-2
模型
Encoder采用bert結構。
由于上下文信息在段落檢索中也很重要,因此簡單地將段落分解成句子并獨立編碼是不可行的。在輸入文章的句子之間插入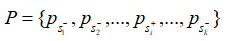 不包含答案的段落,將其表示為:
不包含答案的段落,將其表示為: 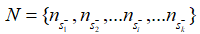 其中的+-代表句子中是否含有答案。文章使用BM25來檢索每個問題的負段落。文章將包含答案的句子視為正樣本(),并從BM25得到的負段落中隨機抽取1個句子作為負樣本。此外在包含答案的段落中隨機抽取1個句子作為另一個負樣本。 檢索: 對于檢索,使用FAISS來計算問題和所有段落句子之間的分數。由于一個段落在索引中含有多個鍵,則檢索返回100*k(k是每篇文章的平均句子數量)個句子。之后,針對這些句子的分數,對它們執行softmax,從而將分數轉化為概率。如果一篇passage中含有多個句子,,這些句子對應的概率為,則該篇passage為query答案的概率為:
其中的+-代表句子中是否含有答案。文章使用BM25來檢索每個問題的負段落。文章將包含答案的句子視為正樣本(),并從BM25得到的負段落中隨機抽取1個句子作為負樣本。此外在包含答案的段落中隨機抽取1個句子作為另一個負樣本。 檢索: 對于檢索,使用FAISS來計算問題和所有段落句子之間的分數。由于一個段落在索引中含有多個鍵,則檢索返回100*k(k是每篇文章的平均句子數量)個句子。之后,針對這些句子的分數,對它們執行softmax,從而將分數轉化為概率。如果一篇passage中含有多個句子,,這些句子對應的概率為,則該篇passage為query答案的概率為:
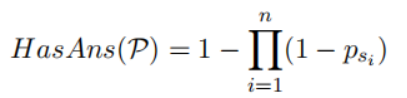
根據計算得到文章的概率,返回概率最高的top100 passage。
實驗
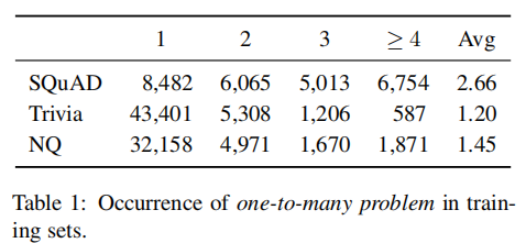
實驗在SQuAD, TriviaQA,Natural Questions數據集上進行。下表統計了數據集中段落對應的問題數量。在SQuAD上的平均值最大,該數據集上Contrastive Conflicts的情況最嚴重,這與DPR在SQuAD上表現最差的事實相符。
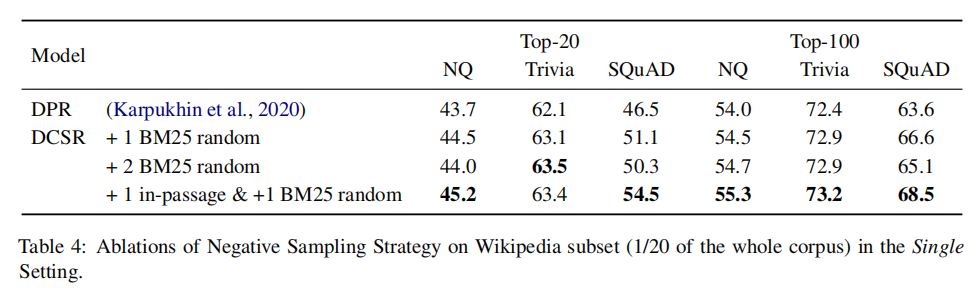
2-4 對于模型而言,DCSR采用了和DPR相同的模型結構,沒有引入額外的參數。在訓練時,采用的負樣本由隨機抽樣產生。因此DCSR帶來的額外時間負擔僅由抽樣引起,這可以忽略不計。
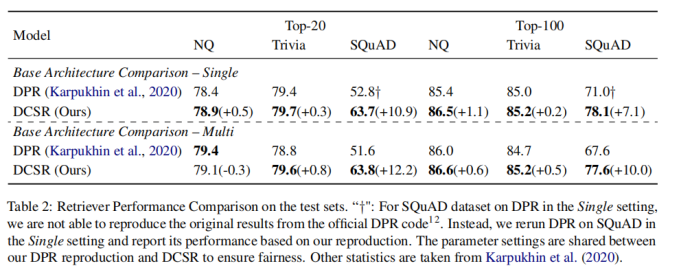
2-5 對在單數據集上的訓練結果而言,上表顯示DCSR取得了明顯優于DPR的結果,特別是在SQuAD這樣的受Contrastive Conflicts影響最嚴重的數據集上,對于受Contrastive Conflicts影響較小的數據集,也有較小的性能提升。對于在多數據集上的訓練結果而言,DPR較DCSR指標下降的幅度更大,這表明DCSR還捕獲了不同領域之間數據集的普遍性。
2-6
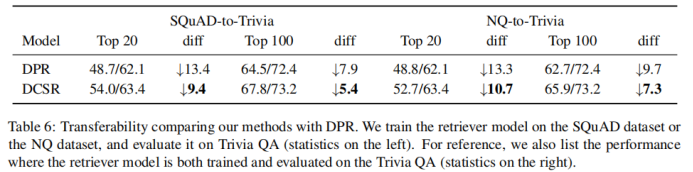
2-7 比較模型的可轉移性。將DPR和DCSR在一個數據集上訓練好后,遷移到另外一個數據集上做評估。可以發現,DCSR比DPR指標下降的幅度更小,模型的可轉移性更好。
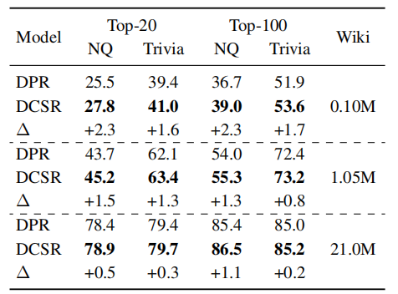
2-8 在不同大小的數據集上訓練模型,發現DCSR與DPR相比,在任何大小的數據集上都表現得更好。與更大的數據集相比,在小的數據集上DCSR改進更顯著。
3

3-1
動機
高質量的短語表示對于在文檔中尋找主題和相關術語至關重要。現有的短語表示學習方法要么簡單地以無上下文的方式組合單詞,要么依賴于廣泛的注釋來感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于感知上下文的短語表示和主題挖掘。UCTopic訓練的關鍵是正負樣本對的構建。文章提出了聚類輔助對比學習(CCL),它通過從聚類中選擇負樣本來減少噪聲,并進一步改進了關于主題的短語表示。
模型
編碼器結構
UCTopic的編碼器采用LUKE (Language Understanding with Knowledge-based Embeddings)。
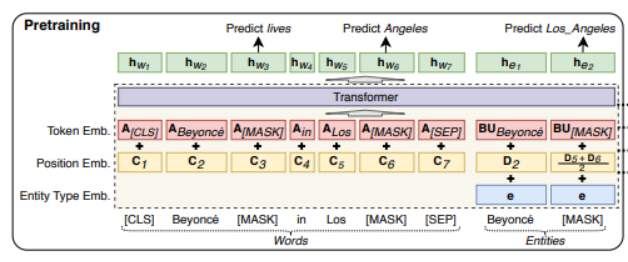
3-2 Luke采用transformer結構。它將文檔中的單詞和實體都作為輸入token,并為每個token計算presentation。形式上,給定一個由m個詞和n個實體組成的序列,為其計算,其中, 其中。Luke的輸入由三部分組成。Input embedding=position embedding+token embedding+entity type embedding (1)token embedding (2) position embedding 出現在序列中第i位的單詞和實體分別用和表示。如果一個實體包含多個單詞,則將相應位置的embedding進行平均來計算position embedding。(3)Entity type embedding 表示token是否一個實體。
Entity-aware Self-attention
因為luke處理兩種類型的標記,所以在計算注意力分數的時候考慮token的類型。
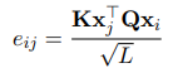
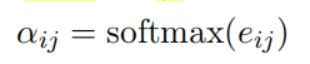
UCTopic
與預測實體的LUKE不同,UCTopic是通過短語上下文的對比學習訓練的。因此,來自UCTopic的短語表示具有上下文感知能力,并且對不同的領域非常健壯。
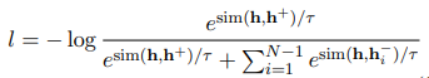
UCTopic采用對比學習的框架進行無監督學習。文中提出了關于短語語義的兩個假設來獲得正負樣本對:1.短語語義由它的上下文決定。mask所提到的短語會迫使模型從上下文中學習表示,從而防止過擬合和表示崩潰 2.相同的短語有相同的語義
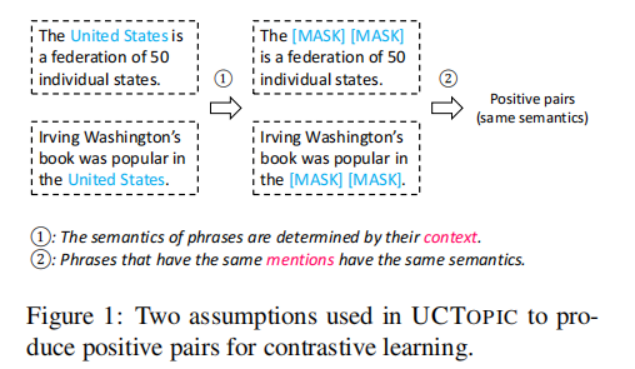
3-4
假設一個文檔內有3個主題,假設批量大小是32,因此一個批量內會有一些樣本來自同一個主題,但是在之前的處理方法中這些樣本都被處理成負樣本,這會導致性能下降。為了根據主題優化短語表示,減小噪聲。文章提出了聚類輔助對比學習(CCL),其基本思想是利用pre-trained representation和聚類的先驗知識來減少負樣本中存在的噪聲。具體來說,對預訓練的短語表示使用聚類算法。每一類的質心被認為是短語的主題表示。在計算了短語和質心之間的余弦距離后,選擇接近質心的t%實例,并為它們分配偽標簽。短語自身的偽標簽由包含該短語的實例的投票決定。假設一個主題集C,其中包含偽標簽和短語。對于主題,構造正樣本。隨機選擇來自其他主題的短語作為訓練的負樣本。微調時訓練的損失函數如下:
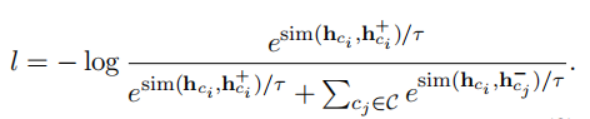
為了推斷短語實例x的主題y,計算短語表示h和主題表示之間的距離,與短語x最近的主題被認為是短語屬于的主題。
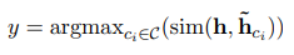
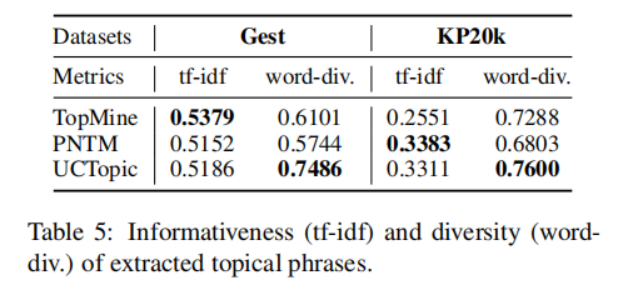
UCTopic的Pre-training與Finetuning示意圖如下:
3-5
實驗
訓練語料庫使用Wikipedia,并將其中帶有超鏈接的文本作為短語。經過處理后,預訓練數據集有1160萬個句子和1.088億個訓練實例。預訓練采用兩個損失函數:一個是masked language model loss,另一個是前面的對比學習損失。
實體聚類
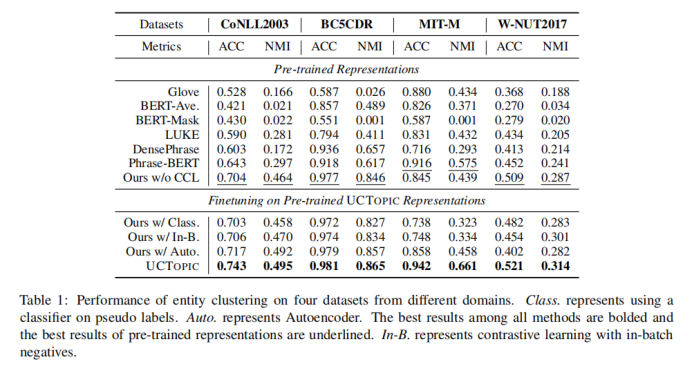
3-6
與其他的微調方法相比,CCL微調可以通過捕獲特定于數據的特征來進一步改進預先訓練好的短語表示。
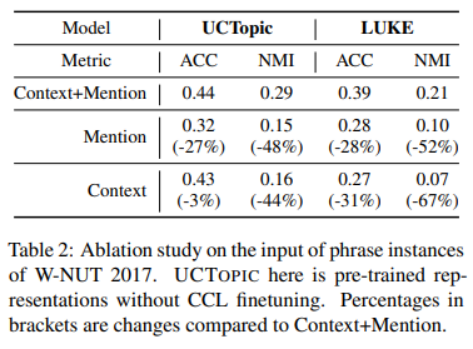
3-7
主題詞挖掘
通過計算輪廓系數來獲得每個數據集的主題數量。
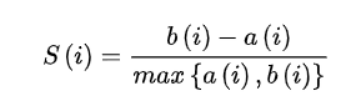
3-8 是第i個點到與i相同聚類中其他點的平均距離,是第i個點到下一個最近簇中的點的平均距離。具體來說,從數據集中隨機抽取10K個短語,并對預訓練過的短語應用K-means聚類。計算不同主題數量的輪廓系數得分;得分最大的數字將被用作數據集中的主題數量。之后利用CCL對數據集進行微調。主題短語評估:(1)主題分離:通過短語入侵任務來評估,具體來說,是從一系列短語中發掘與其他短語所屬主題不同的短語。(2)短語連貫性:要求注釋者評估一個主題中的前50個短語是否有連貫性。(3)短語信息量和多樣性。高信息量的短語不是語料庫中常見的短語。使用tf-idf來評估一個短語的信息量。短語的多樣性通過計算出現的詞的種類與出現詞的數量的比值來評估。UCtopic的多樣性最強,說明了UCtopic的短語表示具有上下文感知能力。
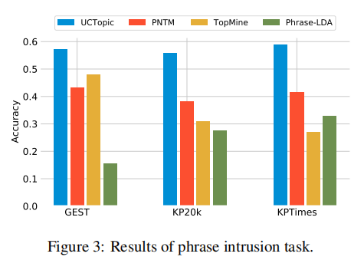
3-9
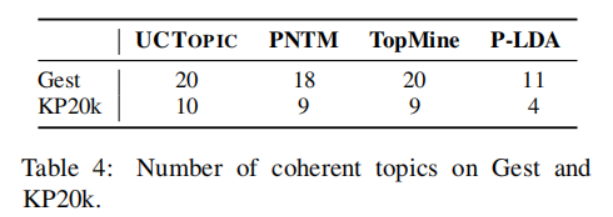
3-10
3-11
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3953瀏覽量
142638 -
模型
+關注
關注
1文章
3752瀏覽量
52109 -
檢索
+關注
關注
0文章
27瀏覽量
13415
原文標題:ACL2022 | 對比學習在開放域段落檢索和主題挖掘中的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
多合一空氣質量傳感器對比白皮書
RAG(檢索增強生成)原理與實踐
友思特案例 | 金屬行業視覺檢測案例四:挖掘機鋼板表面光學字符識別(OCR)檢測

格靈深瞳突破文本人物檢索技術難題
孔夫子舊書網開放平臺接口實戰:古籍圖書檢索與商鋪數據集成
阿里巴巴開放平臺關鍵字搜索商品接口實戰詳解:OAuth2.0 認證落地 + 檢索效率優化(附避坑代碼)
如何在嵌入式RF測試中實施多域信號分析
中創新航與廣汽高域深化戰略合作
是德科技邀您相約2025開放計算創新技術大會
【「零基礎開發AI Agent」閱讀體驗】+Agent的案例解讀
昱能科技“AI領航,光儲新程”主題開放日成功舉辦!




 工商網監
工商網監
評論