") 在Token中加入你感興趣的詞的邊界標(biāo)記
在Token中加入你感興趣的詞的邊界標(biāo)記

今天一起來看一篇騰訊和復(fù)旦大學(xué)合作的工作:MarkBERT: Marking Word Boundaries Improves Chinese BERT[1]
一句話概述:在 Token 中加入你感興趣的詞的邊界標(biāo)記。
MarkBERT 不是基于詞的 BERT,依然是基于字,但巧妙地將「詞的邊界標(biāo)記」信息融入模型。這樣可以統(tǒng)一處理任意詞,無論是不是 OOV。另外,MarkBERT 還有兩個額外的好處:
首先,在邊界標(biāo)記上添加單詞級別的學(xué)習(xí)目標(biāo)很方便,這是對傳統(tǒng)字符和句子級預(yù)訓(xùn)練任務(wù)的補(bǔ)充;
其次,可以通過用 POS 標(biāo)簽特定的標(biāo)記替換通用標(biāo)記來輕松合并更豐富的語義。
在 NER 任務(wù)上取得了 2 個點(diǎn)的提升,在文本分類、關(guān)鍵詞識別、語義相似任務(wù)上也取得了更好的精度。
這個簡單但有效的中文預(yù)訓(xùn)練模型 MarkBERT,考慮了詞信息但沒有 OOV 問題。具體有以下優(yōu)勢:
統(tǒng)一的方式處理常用詞和低頻詞,沒有 OOV 問題。
Marker 的引入允許設(shè)計(jì)詞級別的預(yù)訓(xùn)練任務(wù),這是對字級別的 MLM 和句子級別的 NSP 的補(bǔ)充。
容易擴(kuò)展加入更多單詞語義(詞性、詞法等)。
預(yù)訓(xùn)練階段有兩個任務(wù):
MLM:對 Marker 也進(jìn)行了 MASK,以便模型能學(xué)習(xí)到邊界知識。
替換詞檢測:人工替換一個詞,然后讓模型分辨標(biāo)記前面的詞是不是正確的。
MarkBERT預(yù)訓(xùn)練
MarkBERT
如下圖所示:
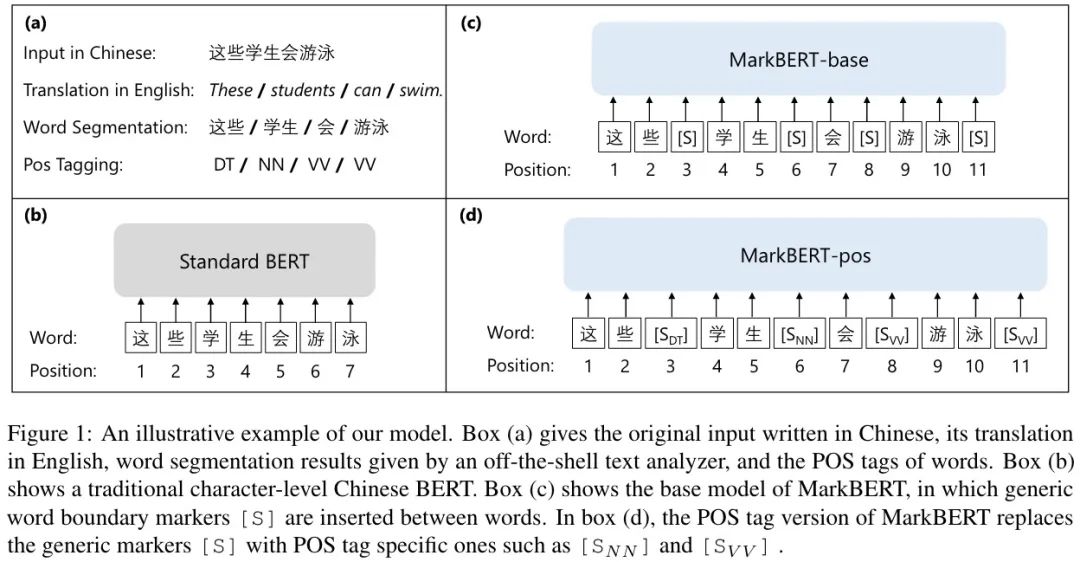
首先分詞,在詞中間插入特殊標(biāo)記,這些標(biāo)記也會被當(dāng)做普通的字符處理。有位置,也會被 MASK,這樣編碼時就需要注意詞的邊界,而不是簡單地填充,MASK 預(yù)測任務(wù)變得更有挑戰(zhàn)(預(yù)測需要更好地理解單詞邊界)。這樣,模型依然是字符級別的,但它知道了單詞的邊界(因?yàn)閱卧~的信息是顯式給出的)。
替換詞檢測
具體而言,當(dāng)一個詞被替換成混淆詞,標(biāo)記應(yīng)該做出「被替換」的預(yù)測,標(biāo)簽為 False,否則為 True。
該損失函數(shù)會和 MLM 的損失函數(shù)加在一起作為多任務(wù)訓(xùn)練過程。混淆詞來自同義詞或讀音相似的詞,通過這個任務(wù),標(biāo)記可以對上下文中的單詞跨度更敏感。使用 POS 做標(biāo)記的模型稱為 MarkBERT-POS。
預(yù)訓(xùn)練
MASK 的比例依然是 15%,30% 的時間不插入任何標(biāo)記(原始的 BERT);50% 的時間執(zhí)行 WWM 預(yù)測任務(wù);其余時間執(zhí)行 MLM 預(yù)測任務(wù)。
在插入標(biāo)記中,30% 的時間將詞替換為基于讀音的混淆詞或基于同義詞的混淆詞,標(biāo)記預(yù)測讀音混淆標(biāo)記或同義詞混淆標(biāo)記;其他時間標(biāo)記預(yù)測正常單詞標(biāo)記。為了避免不平衡標(biāo)簽,只計(jì)算正常標(biāo)記上 15% 的損失。
實(shí)驗(yàn)
在 NER 任務(wù)上的效果如下表所示:
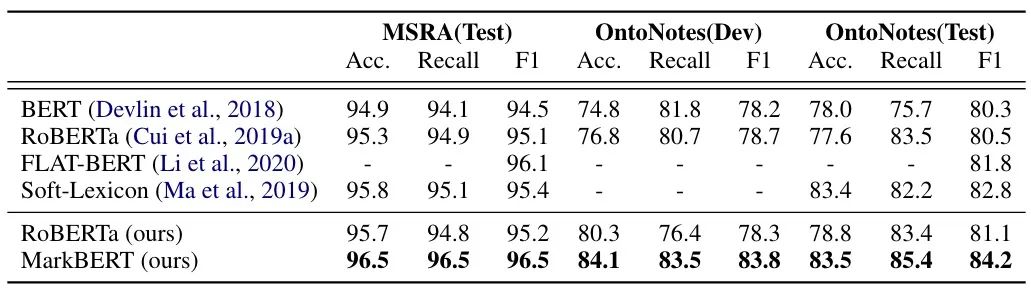
可以看到,效果提升還是很明顯的。
在三個任務(wù)上做了消融實(shí)驗(yàn):
MarkBERT-MLM:只有 MLM 任務(wù)
MarkBERT-rwd:在替換詞檢測時,分別移除近音詞或同義詞
MarkBERT-w/o:在下游任務(wù)微調(diào)時去掉 Marker(和原始 BERT 一樣用法)
結(jié)果如下表所示:
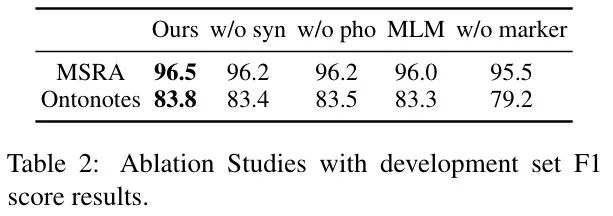
結(jié)論如下:
MarkBERT-MLM 在 NER 任務(wù)中獲得顯著提升,說明單詞邊界信息在細(xì)粒度任務(wù)中很重要。
不插入標(biāo)記,MarkBERT-w/o 也達(dá)到了和 baseline 相近的效果,說明 MarkBERT 可以像 BERT 一樣使用。
對 NER 任務(wù)來說,插入標(biāo)記依然重要,表明 MarkBERT 結(jié)構(gòu)在學(xué)習(xí)需要這種細(xì)粒度表示的任務(wù)的單詞邊界方面是有效的。
討論
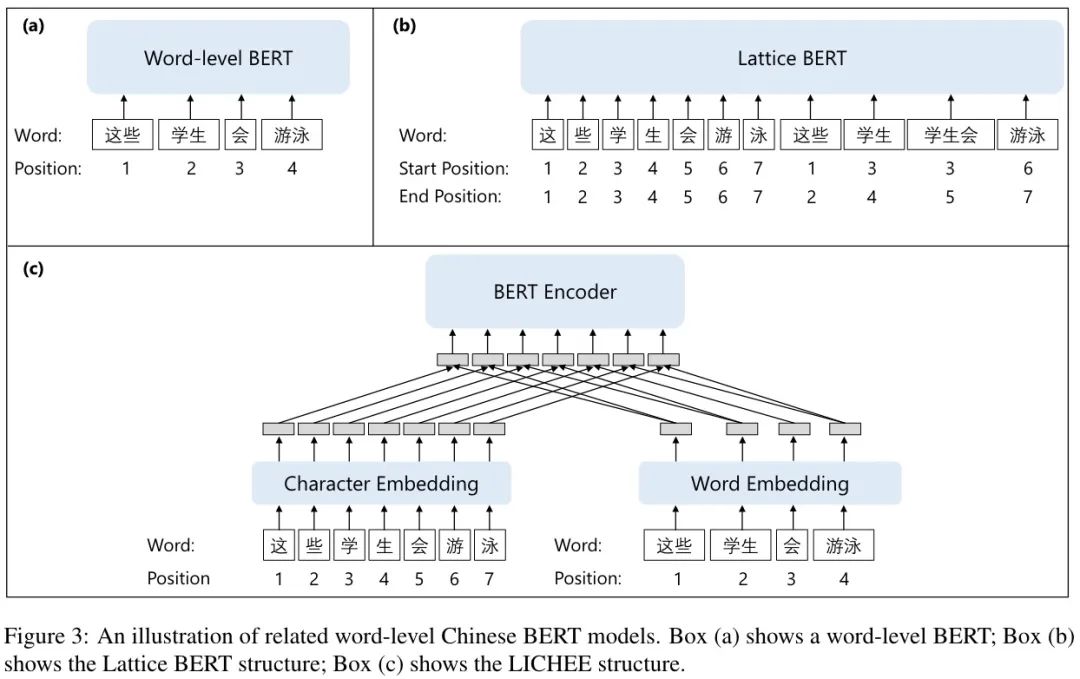
已有的中文 BERT 融入詞信息有兩個方面的策略:
在預(yù)訓(xùn)練階段使用詞信息,但在下游任務(wù)上使用字符序列,如 Chinese-BERT-WWM,Lattice-BERT。
在下游任務(wù)中使用預(yù)訓(xùn)練模型時使用單詞信息,如 WoBERT,AmBERT,Lichee。
另外在與實(shí)體相關(guān)的 NLU 任務(wù),特別是關(guān)系分類中有探討插入標(biāo)記的想法。給定一個主語實(shí)體和賓語實(shí)體,現(xiàn)有工作注入非類型標(biāo)記或?qū)嶓w特定標(biāo)記,并對實(shí)體之間的關(guān)系做出更好的預(yù)測。
這篇論文當(dāng)時刷到時覺得真心不錯,方法很簡單但很巧妙,一下子解決了中文預(yù)訓(xùn)練模型「詞」的處理,非常方便地就可以引入詞級別的任務(wù),以及豐富的詞語義。其實(shí),我們甚至可以只針對「部分感興趣的詞」添加標(biāo)記,剩下的依然按字處理。
本文參考資料
[1]
MarkBERT: Marking Word Boundaries Improves Chinese BERT: https://arxiv.org/abs/2203.06378
審核編輯 :李倩
-
編碼
+關(guān)注
關(guān)注
6文章
1039瀏覽量
56980 -
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111
原文標(biāo)題:MarkBERT:巧妙地將詞的邊界標(biāo)記信息融入模型
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
軟通動力打造“算力基建+睿動Token經(jīng)濟(jì)+OpenClaw”的算力運(yùn)營新體系

11 月的 KiCon Asia 前開發(fā)者希望了解下中國用戶最感興趣的功能、需求
薄膜電容的關(guān)鍵詞是什么你知道嗎?

零基礎(chǔ)在智能硬件上克隆原神可莉?qū)崿F(xiàn)桌面陪伴(提供人設(shè)提示詞、知識庫、固件下載)
PCB絲印極性標(biāo)記的實(shí)用設(shè)計(jì)技巧




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論