") 基于Entity-Linking及基于Retreval的方法
基于Entity-Linking及基于Retreval的方法

NLP預(yù)訓(xùn)練模型需要非常大的參數(shù)量以及非常多的語料信息,這些都是希望能盡可能多的記住文本中的知識(shí),以此提升下游任務(wù)效果。相比而言,直接從數(shù)據(jù)庫(kù)、知識(shí)圖譜、搜索引擎等引入外部知識(shí)進(jìn)行知識(shí)增強(qiáng),是一種更直接、節(jié)省資源的方法。知識(shí)增強(qiáng)也是NLP未來的重要發(fā)展方向,由于在NLU這種需要理解、常識(shí)性知識(shí)的領(lǐng)域,知識(shí)增強(qiáng)更加重要。
ACL 2022的一篇Tutorial:Knowledge-Augmented Methods for Natural Language Understanding,對(duì)知識(shí)增強(qiáng)在NLU中的方法進(jìn)行了詳細(xì)匯總。本文整理了這篇Tutorial中重點(diǎn)介紹知識(shí)增強(qiáng)模型的10篇工作,包括基于Entity-Linking的方法以及基于Retreval的方法兩大類。
Entity-Linking based methodsERNIE: Enhanced Language Representation with Informative Entities(ACL 2019)
ERNIE利用知識(shí)圖譜中的實(shí)體信息給BERT模型引入外部知識(shí),提升預(yù)訓(xùn)練語言模型效果。模型主要包括Text-Encoder和Knowledge-Encoder兩個(gè)部分。在輸入部分,除了原始的文本維度embedding,還會(huì)引入實(shí)體embedding,實(shí)體embedding利用TrasE算法基于知識(shí)圖譜進(jìn)行預(yù)訓(xùn)練。Text-Encoder和BERT相同,對(duì)原始的文本輸入進(jìn)行處理生成文本表示。Knowledge-Encoder將文本和對(duì)應(yīng)位置的entity表示進(jìn)行融合,得到實(shí)體知識(shí)增強(qiáng)的表示。Knowledge-Encoder的整個(gè)計(jì)算過程如下圖,首先利用兩個(gè)獨(dú)立的multi-head attention生成文本word embedding和entity embedding,再將實(shí)體和對(duì)應(yīng)位置的文本進(jìn)行對(duì)齊,輸入到融合層,再通過融合層生成新的word embedding和entity embedding,這樣循環(huán)多層得到最終結(jié)果。
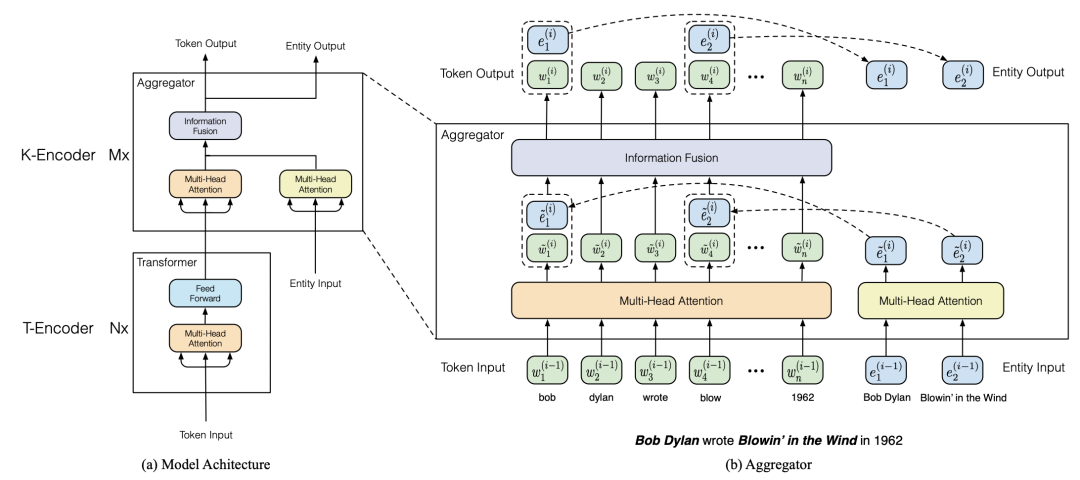
在預(yù)訓(xùn)練階段,ERNIE增加了一個(gè)entity denoising的任務(wù):mask掉或者隨機(jī)打亂某些word和entity之間的對(duì)齊關(guān)系,讓模型去預(yù)測(cè)。這種預(yù)訓(xùn)練任務(wù)起到了將實(shí)體知識(shí)融入到語言模型中的作用。
KEAR: Augmenting Self-Attention with External Attention(IJCAI 2022)
為了讓Transformer存儲(chǔ)更多的知識(shí)來提升下游任務(wù)效果,一般都會(huì)采用更大的模型尺寸、更多的訓(xùn)練數(shù)據(jù)。而KEAR提出引入外部知識(shí)的方法,這樣即使在中等尺寸的Transformer上也能由于這些外部知識(shí)增益帶來顯著效果提升。
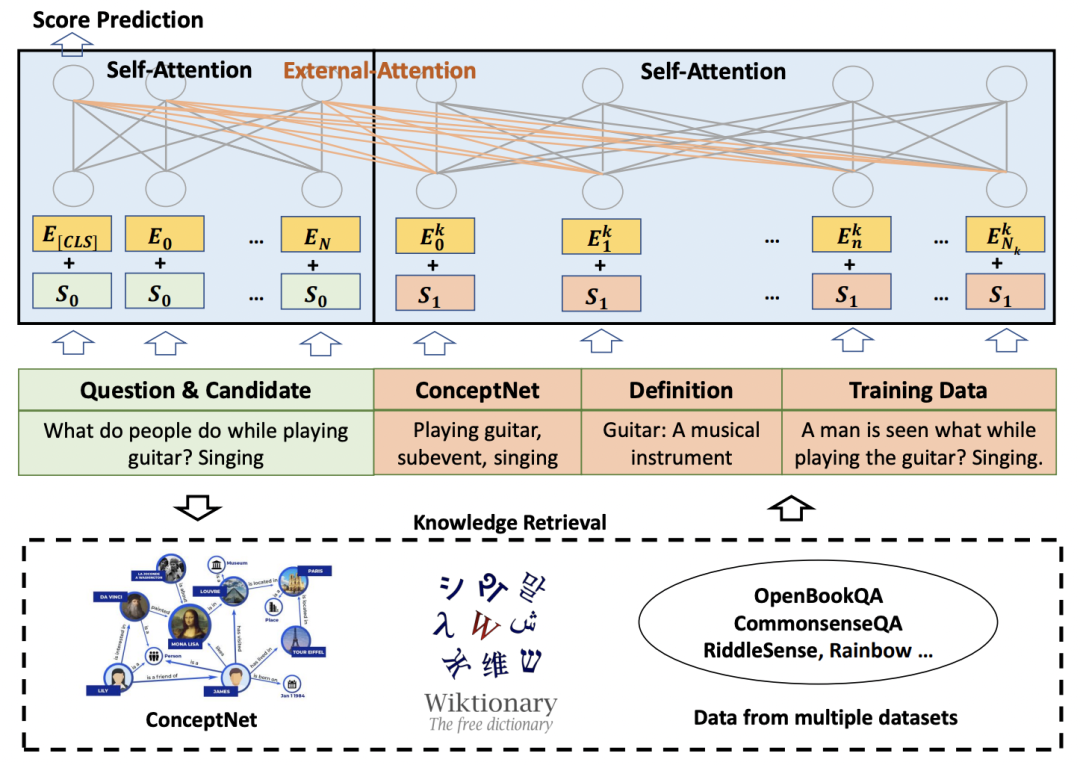
本文主要關(guān)注QA任務(wù),給定一個(gè)問題和一組答案,從中選擇正確答案。模型的結(jié)構(gòu)比較簡(jiǎn)單,將輸入的文本,以及從各種外部知識(shí)庫(kù)中檢索到和原始輸入相關(guān)的知識(shí)信息,都以文本的形式拼接到一起,輸入到Transformer中。
外部知識(shí)主要來源于三個(gè)渠道,第一個(gè)渠道是知識(shí)圖譜,從問題和答案中提取entity,然后從ConcepNet中提取包含對(duì)應(yīng)entity的三元組;第二個(gè)渠道是從字典中檢索相應(yīng)實(shí)體的描述性定義,來彌補(bǔ)模型對(duì)于低頻詞的embedding可能學(xué)的不好的情況;第三個(gè)渠道是從訓(xùn)練數(shù)據(jù)中檢索和當(dāng)前輸入相關(guān)的信息作為補(bǔ)充,緩解模型由于對(duì)某些訓(xùn)練數(shù)據(jù)中的信息記憶不全導(dǎo)致的信息缺失。
Entities as Experts: Sparse Memory Access with Entity Supervision(2020,EaE)
這篇文章在Transformer模型中引入了一個(gè)Entity Memory Layer組件,用來從已經(jīng)訓(xùn)練好的entity embedding memory中引入和輸入相關(guān)的外部知識(shí)。Entity Memory Layer模塊可以非常靈活的嵌套在Transformer等序列模型中。
具體做法為,首先要有一個(gè)已經(jīng)訓(xùn)練好的entity embedding存儲(chǔ)起來。在Transformer的一層輸出結(jié)果后,對(duì)于輸入文本中的每個(gè)entity mention,使用這個(gè)entity span的起始位置和終止位置的embedding拼接+全連接得到一個(gè)虛擬的entity embedding。利用這個(gè)虛擬的entity embedding去entity embedding memory中,利用內(nèi)積檢索出最相關(guān)的top K個(gè)實(shí)體的embedding,最后加權(quán)融合,得到這個(gè)entity對(duì)應(yīng)的實(shí)體表示,公式如下。這個(gè)表示會(huì)和Transformer上層輸入融合,作為下一層的輸入。
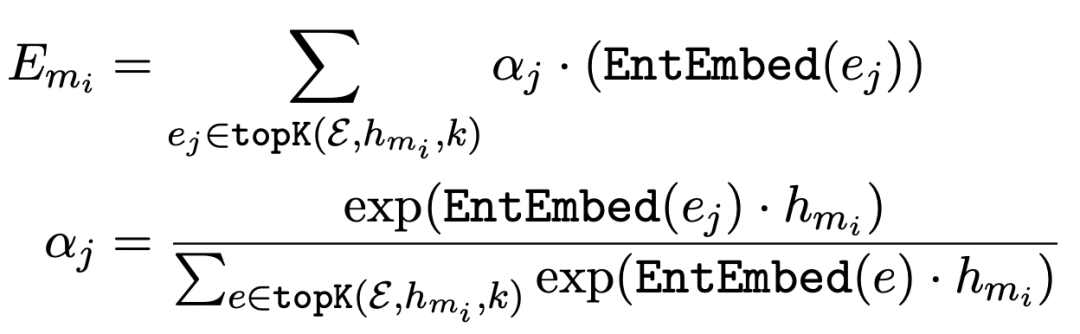
預(yù)訓(xùn)練任務(wù)除了MLM外,還包括Mention Detection和Entity Linking兩個(gè)優(yōu)化任務(wù)。其中,Mention Detection用來預(yù)測(cè)每個(gè)實(shí)體的start和end,采用BIO classification的方式;而Entity Limking任務(wù)主要為了拉近Transformer生成的虛擬entity embedding和其對(duì)應(yīng)的entity embedding memory的距離。
FILM: Adaptable and Interpretable Neural Memory Over Symbolic Knowledge(NAACL 2021)
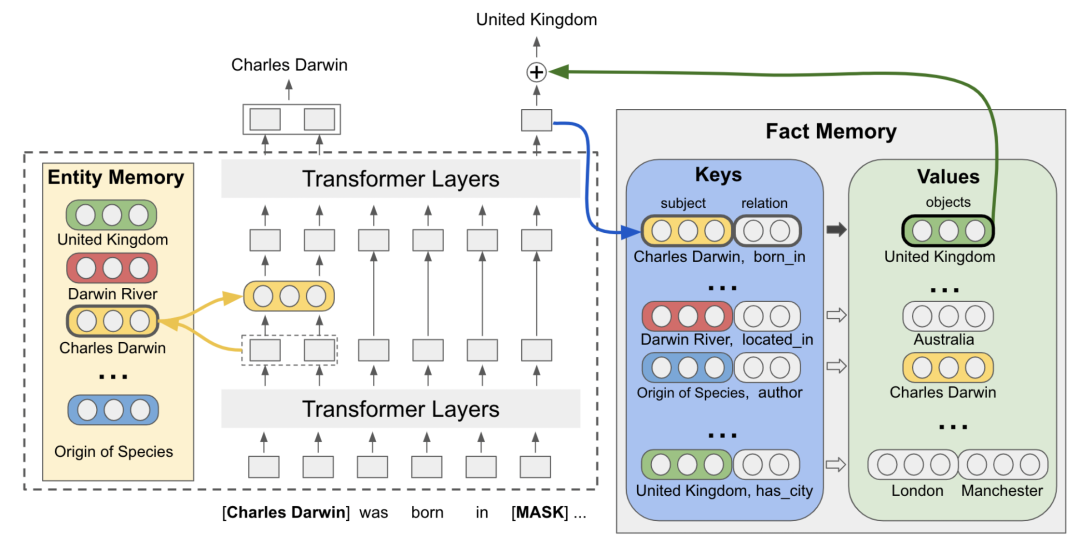
FILM在上一篇文章中的entity embedding memory基礎(chǔ)上,引入了Fact Memory模塊,entity embedding layer部分的實(shí)現(xiàn)和EaE中相同。
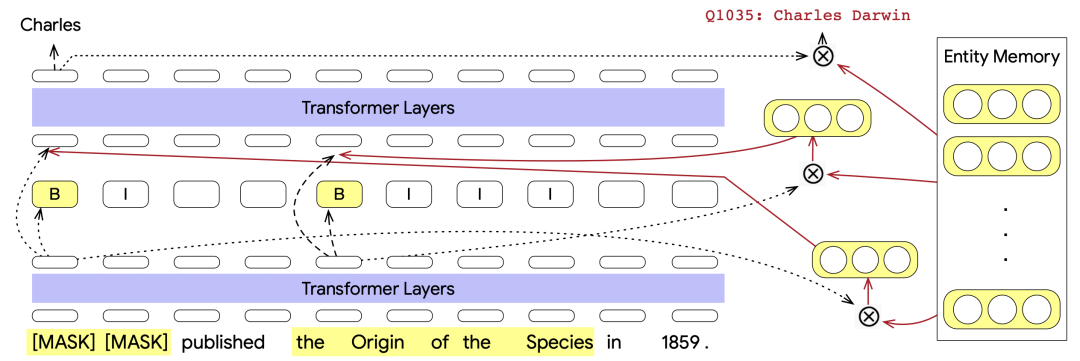
Fact Memory模塊和Entity Memory使用的是相同的embedding。Fact Memory模塊由Keys和Values兩個(gè)部分組成,Keys對(duì)應(yīng)的是知識(shí)圖譜中的subject和relation,而Values是同一個(gè)subject和relation下的所有object的集合。使用subject和relation的表示拼接轉(zhuǎn)換得到每個(gè)Keys的embedding表示。當(dāng)需要預(yù)測(cè)輸入文本被mask部分的答案時(shí),使用Transformer在mask位置生成的embedding作為query,在Fact Memory中和各個(gè)Keys的embedding做內(nèi)積,檢索相關(guān)的object。這些檢索出的object信息的embedding會(huì)和被mask部分的embedding融合,用于進(jìn)行答案的預(yù)測(cè)。
下圖是一個(gè)例子,被mask部分的embedding包含了句子中的關(guān)鍵信息,利用該embedding在fact memory中可以實(shí)現(xiàn)相關(guān)信息的檢索,對(duì)于QA有比較大的幫助。
K-BERT: Enabling Language Representation with Knowledge Graph(2019)
K-BERT首先將輸入文本的實(shí)體識(shí)別出來,然后去知識(shí)圖譜中搜索和該實(shí)體相關(guān)的子圖,用這個(gè)子圖插入到輸入句子的對(duì)應(yīng)位置,形成一個(gè)句子樹。比如下面的圖中,Tim Cook從知識(shí)圖譜檢索出是蘋果CEO,就將對(duì)應(yīng)文本插入到Tim Cook后面的位置。
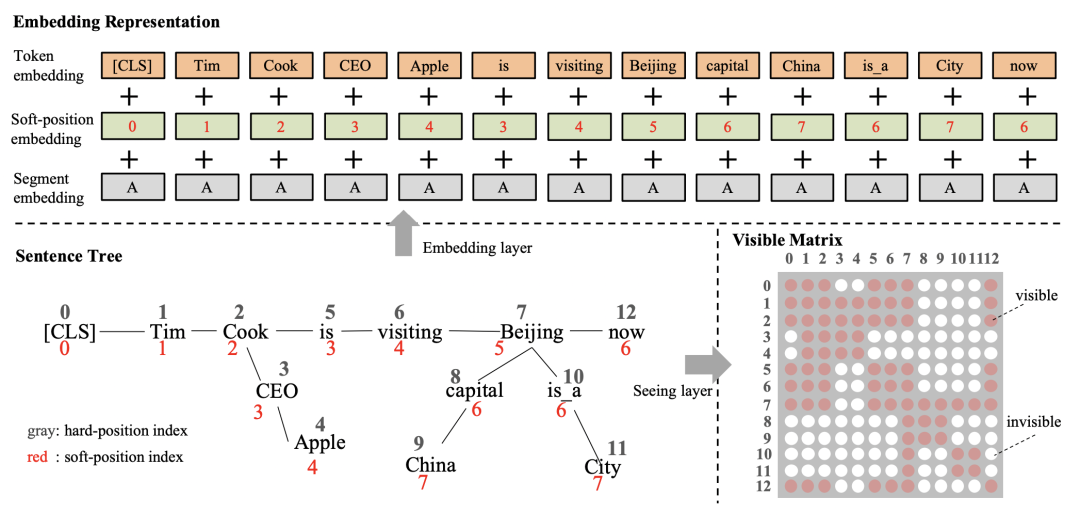
一個(gè)核心問題在于,新引入的知識(shí)圖譜文本會(huì)影響原來輸入句子的語義。另外,文中采用的是將知識(shí)圖譜引入的文本直接插入到對(duì)應(yīng)實(shí)體后面,其他文本位置對(duì)應(yīng)后移,如何設(shè)置position embedding也是個(gè)問題。如果直接按照順序設(shè)定position embedding,會(huì)讓原本距離比較近的單詞之間的position embedding變遠(yuǎn),也會(huì)影響原始語義。為了解決這個(gè)問題,插入的知識(shí)圖譜文本不會(huì)影響原來句子各個(gè)單詞的posistion編號(hào)。同時(shí)引入了Visible Matrix,讓原始輸入中和引入的知識(shí)信息不相關(guān)的文本在計(jì)算attention時(shí)不可見。通過這種方式,引入的知識(shí)信息只會(huì)直接影響與其相關(guān)的實(shí)體的表示生成,不會(huì)直接影響原始句子中其他文本的表示生成。引入的知識(shí)通過影響對(duì)應(yīng)實(shí)體的表示生成,間接影響其他文本的表示生成過程。
2
Retrieval based methodsDense Passage Retrieval for Open-Domain Question Answering(2020)
這篇文章采用的是一種最基礎(chǔ)的基于檢索的QA解決方法。離線訓(xùn)練一個(gè)passage encoder和一個(gè)question encoder,目標(biāo)是讓question和包含其答案的passage的表示的內(nèi)積最大。訓(xùn)練過程中的負(fù)樣本構(gòu)造采用了隨機(jī)采樣、BM25和question高相關(guān)性但不包含答案的passage、訓(xùn)練樣本中包含答案但不包含當(dāng)前question答案的passage三種方法。在在線使用時(shí),通過計(jì)算question和passage表示內(nèi)積的方式,檢索出高相關(guān)性的passage解析出問題答案。
REALM: Retrieval-Augmented Language Model Pre-Training(2020)
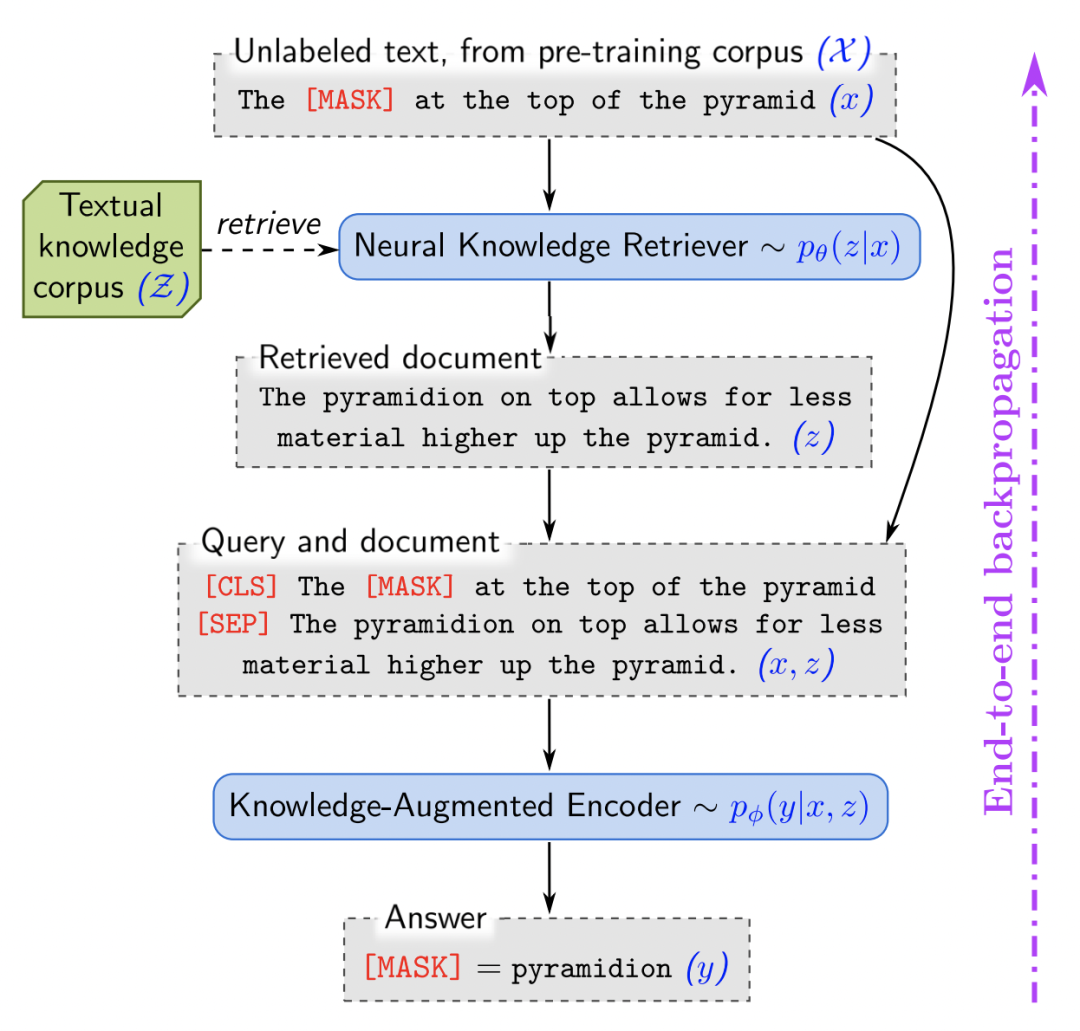
REALM在預(yù)訓(xùn)練語言模型中引入了外部知識(shí)檢索模塊,讓模型在進(jìn)行預(yù)測(cè)時(shí),不僅能夠根據(jù)自身參數(shù)保存的信息,也能根據(jù)豐富的外部信息給出答案。整個(gè)預(yù)測(cè)過程包括兩個(gè)部分:檢索階段和預(yù)測(cè)階段。檢索階段根據(jù)輸入句子從外部知識(shí)中檢索相關(guān)的文檔;預(yù)測(cè)階段根據(jù)輸入句子以及檢索到的信息進(jìn)行最終結(jié)果的預(yù)測(cè)。
在檢索階段,跟上一篇文章類似,使用預(yù)訓(xùn)練的兩個(gè)BERT的表示計(jì)算內(nèi)積求得輸入和各個(gè)文檔的相關(guān)性,并進(jìn)行高相關(guān)文檔的檢索。檢索到的文檔和原始輸入拼接到一起,輸入到BERT模型中進(jìn)行結(jié)果預(yù)測(cè)。
RETRO: Improving language models by retrieving from trillions of tokens(2022)
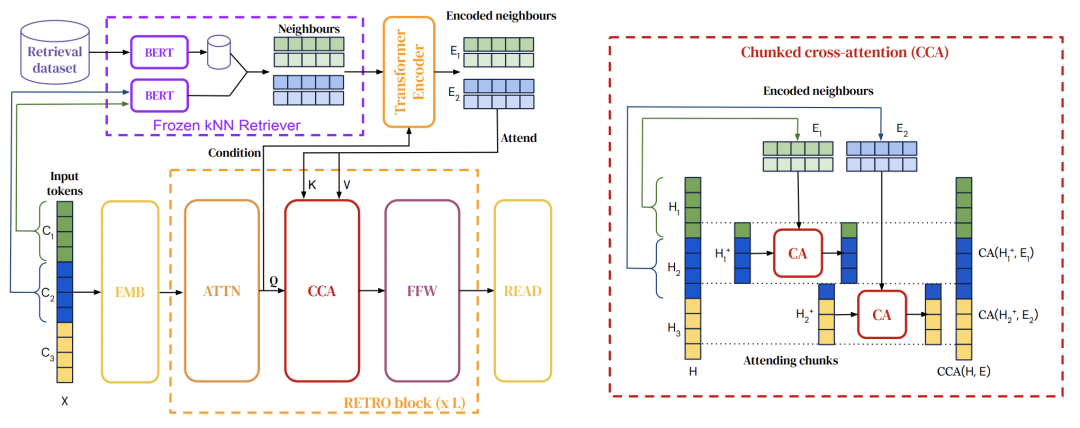
RETRO相比REALM,采用的是chunks維度的檢索。首先構(gòu)造一個(gè)數(shù)據(jù)庫(kù),存儲(chǔ)文本chunks以及它們的embedding,embedding是由一個(gè)預(yù)訓(xùn)練BERT產(chǎn)出的。接下來在訓(xùn)練語言模型時(shí),對(duì)于每個(gè)輸入文本,將其切分成多個(gè)chunk,每個(gè)chunk利用向量檢索從數(shù)據(jù)庫(kù)中檢索出k個(gè)最近鄰chunks。這些被檢索出來的相關(guān)chunks會(huì)利用attention和原始輸入進(jìn)行融合,增強(qiáng)原始輸入信息。原始輸入的每個(gè)chunk都和該chunk檢索出的chunks以及其鄰居檢索出的chunks進(jìn)行attention。
WebGPT: Browser-assisted question-answering with human feedback(2022)
WebGPT實(shí)現(xiàn)了利用GPT模型使用搜索引擎檢索答案。人們?cè)跒g覽器中搜索的操作可以表述成例如下面的這些文本。預(yù)先定義一些下表中的command,訓(xùn)練GPT模型讓它根據(jù)已經(jīng)進(jìn)行的搜索操作,生成下一個(gè)command。這個(gè)過程一直執(zhí)行到某個(gè)終止條件位置(例如生成end command、執(zhí)行次數(shù)超過一定長(zhǎng)度)。某些command代表著采用這些文檔作為reference。在執(zhí)行完所有command后,根據(jù)收集到的reference以及問題,生成最終的答案。比如下圖b中就是已經(jīng)執(zhí)行的command以及問題等信息,這些信息組成了當(dāng)前搜索的上下文,以文本形式輸入GPT中,讓模型生成下一個(gè)command。
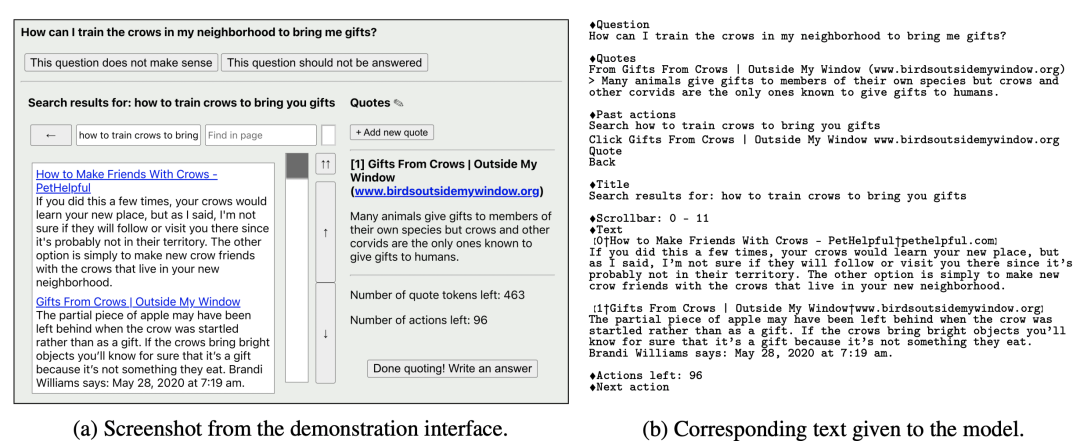

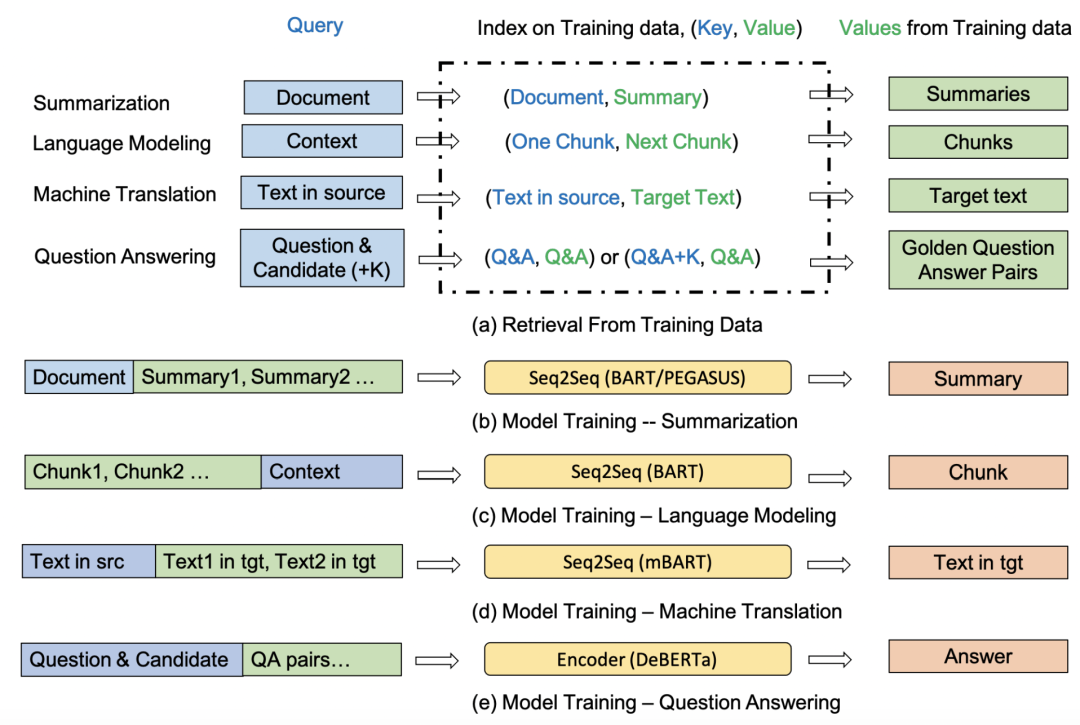
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data(2022)
這篇文章通過檢索+拼接的方法擴(kuò)充原始輸入文本的信息,提升多項(xiàng)任務(wù)上的效果。整個(gè)檢索過程在訓(xùn)練數(shù)據(jù)中進(jìn)行,將訓(xùn)練數(shù)據(jù)構(gòu)造成key-value對(duì)。對(duì)于輸入樣本,從訓(xùn)練數(shù)據(jù)中檢索出高相關(guān)性的樣本,作為知識(shí)信息拼接到原始輸入中。不同任務(wù)會(huì)采用不同的檢索對(duì)象以及拼接方法,如下圖。
3
總結(jié)知識(shí)增強(qiáng)方法是解決自然語言理解的核心方法,重點(diǎn)在于研究從哪獲取知識(shí)、如何獲取知識(shí)以及如何融合知識(shí)。使用知識(shí)增強(qiáng)的方法可以幫助模型更直接獲取預(yù)測(cè)需要用到的外部知識(shí),也能緩解需要越來越大的預(yù)訓(xùn)練模型提升下游任務(wù)效果的問題。知識(shí)增強(qiáng)+預(yù)訓(xùn)練語言模型起到互補(bǔ)的作用,知識(shí)增強(qiáng)方法可以給模型提供預(yù)訓(xùn)練階段沒見過或者忘記的信息,提升預(yù)測(cè)效果。
原文標(biāo)題:ACL 2022 Tutorial解析——知識(shí)增強(qiáng)自然語言理解
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52112 -
nlp
+關(guān)注
關(guān)注
1文章
491瀏覽量
23281 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
8315
原文標(biāo)題:ACL 2022 Tutorial解析——知識(shí)增強(qiáng)自然語言理解
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
微電網(wǎng)暫態(tài)穩(wěn)定分析方法有哪些?
射頻SMA安裝方法

SMA接口安裝方法詳解
ALTAIR HYPERLIFE焊接疲勞方法及案例

按鍵消抖的方法
利用軟件的方法解決EMC問題

使用jQuery的常用方法與返回值分析
studio編譯過程中報(bào)錯(cuò):syntax error: unexpected如何解決?
車機(jī)DAB功能驗(yàn)證方法論及測(cè)試三神器簡(jiǎn)介
ANSA中CFD網(wǎng)格細(xì)化方法
錫膏的儲(chǔ)存及使用方法詳解




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論