 用于有效使用TinyML的隨機計算架構
用于有效使用TinyML的隨機計算架構

神經網絡是一種流行的機器學習模型,但它們需要更高的能耗和更復雜的硬件設計。隨機計算是平衡硬件效率和計算性能之間權衡的一種有效方式。然而,由于算術單元的低數據精度和不準確性,隨機計算見證了 ML 工作負載的低準確性。
為了解決與傳統隨機計算方法相關的問題,并通過更高的精度和更低的功耗來提高性能,正在進行的研究提出了一種改進的基于塊的隨機計算架構。通過在輸入層中引入塊,可以通過利用高數據并行性來減少延遲。更重要的是確定全局優化方法所需要的塊數。
現有的方法包括增加比特流的長度以提高數據精度,甚至使用指數比特來獲得準確的結果。然而,這引入了較長的計算延遲,這對于 TinyML 應用程序來說是不合理的。因此,為了應對這種不斷上升的計算延遲,比特流被分成塊然后并行執行。結合塊內算術單元和輸出修正 (OUR) 方案可緩解塊間不準確問題,從而提供高計算效率。
基于塊的隨機計算架構
研究提供了一種新穎的架構,其中輸入被劃分為塊并使用優化的塊內算術單元并行執行乘法和加法。此外,在 TinyML 應用程序的延遲-功耗權衡方面,所提出的模型是一個出色的架構。
架構劃分如下:
塊劃分
如上圖所示,輸入比特流被劃分為“k”個值塊。所提出的想法是,為比特流選擇大量塊并不能保證是最佳的,但可以用于接近近似值。如果在選擇塊數時出現錯誤,這可能會自相矛盾地導致大錯誤。在確定來自輸入比特流的正和負部分的兩個平均值的概率方面存在復雜的計算。
塊內計算
緩解了傳統加法器面臨的OR加法器相關問題和分離加法器溢出問題。新修改的架構設計在輸入之間帶有 XNOR+AND 門,以消除雙極計算的相關性。
每個輸入位都在并行計數器 (PC) 中獲取,對于正負部分 (Ap, An) 分別進行處理。有兩個專用累加器用于處理有符號位。取輸入位后,累加器之間發生減法,如正負部分所示。目標是獲得所有輸入的累積 1 的數量。進一步地,比較取時間輸出(Sop,Son)中的一位,在多個“n”個循環之后,計算符號位,并根據符號位Ap和An,選擇Sop和Son的輸出結果。
這種新的基于累加器的符號幅度格式加法器利用 unNSADD 加法器來比較輸出和輸入中的實際累加 1 以確定輸出位。這種方法消除了相關性和快速溢出問題的影響。
塊間??輸出修正方案
盡管塊內加法器解決了相關性和溢出問題,但塊劃分引入了新的塊間不準確錯誤。乘法器不會發生這種情況,因為輸入是 XNORed 和 ANDed。但是對于加法器,輸出中 1 的數量可能會偏離所產生的不準確性。輸出修訂方案在并行塊內計算階段之后添加或刪除 1s,而不會引入任何額外的延遲來解決這些塊間不準確錯誤。
新穎的基于塊的隨機計算架構旨在提高隨機計算運算電路的精度,同時降低計算延遲和能源效率。根據研究結果,該方法比現有方法的準確度提高了 10% 以上,并節省了 6 倍以上的功率。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107839 -
機器學習
+關注
關注
66文章
8554瀏覽量
136982
發布評論請先 登錄
如何在LTspice仿真中實現偽隨機數和真隨機數的生成
雙口SRAM靜態隨機存儲器存儲原理
龍架構計算機系統能力核心課程教學研討會圓滿舉行
用于RISCV的F指令集實現的浮點計算單元(FPU)設計方案
【PZ-ZU15EG-KFB】——ZYNQ UltraScale + 異構架構下的智能邊緣計算標桿

知合計算:RISC-V架構創新,阿基米德系列劍指高性能計算

異構計算解決方案(兼容不同硬件架構)
如何釋放異構計算的潛能?Imagination與Baya Systems的系統架構實踐啟示

GPU架構深度解析
能效提升3倍!異構計算架構讓AI跑得更快更省電
Arm架構何以成為現代計算的基礎
讓智能遍布人形機器人全身,這家國產MCU企業探索MCU+AI(TinyML)

STM32U5?(超低功耗MCU,支持TinyML)全面解析
基于玻色量子相干光量子計算機的混合量子經典計算架構
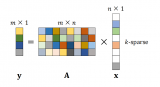



 工商網監
工商網監
評論