 表示學習中7大損失函數的發展歷程及設計思路
表示學習中7大損失函數的發展歷程及設計思路

表示學習的目的是將原始數據轉換成更好的表達,以提升下游任務的效果。在表示學習中,損失函數的設計一直是被研究的熱點。損失指導著整個表示學習的過程,直接決定了表示學習的效果。這篇文章總結了表示學習中的7大損失函數的發展歷程,以及它們演進過程中的設計思路,主要包括contrastive loss、triplet loss、n-pair loss、infoNce loss、focal loss、GHM loss、circle loss。
1. Contrastive Loss
Dimensionality Reduction by Learning an Invariant Mapping(CVPR 2006)提出contrastive loss,模型中輸入兩個樣本,經過相同的編碼器得到兩個樣本的編碼。如果兩個樣本屬于同一類別,則優化目標為讓兩個樣本在某個空間內的距離小;如果兩個樣本不屬于同一類別,并且兩個樣本之間的距離小于一個超參數m,則優化目標為讓兩個樣本距離接近m。損失函數可以表示為:
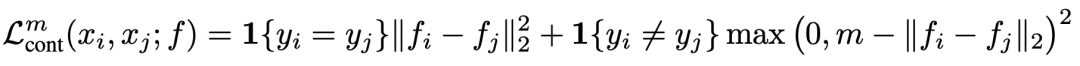
Contrastive Loss是后面很多表示學習損失函數的基礎,通過這種對比的方式,讓模型生成的表示滿足相似樣本距離近,不同樣本距離遠的條件,實現更高質量的表示生成。
2. Triplet Loss
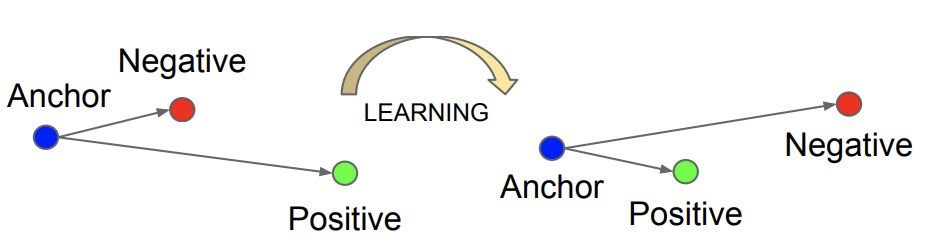
FaceNet: A unified embedding for face recognition and clustering(CVPR 2015)提出triplet loss,計算triplet loss需要比較3個樣本,這3個樣本分別為anchor、position和negtive。其目標為讓anchor和positive樣本(類別相同)的距離盡可能近,而和negtive樣本(類別不同)的距離盡可能遠。因此triplet loss設計為,讓anchor和positive樣本之間的距離比anchor和negtive樣本要小,并且要小至少一個margin的距離才不計入loss。
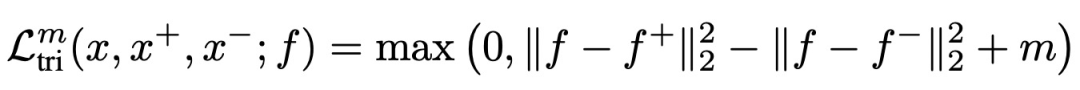
3. N-pair Loss
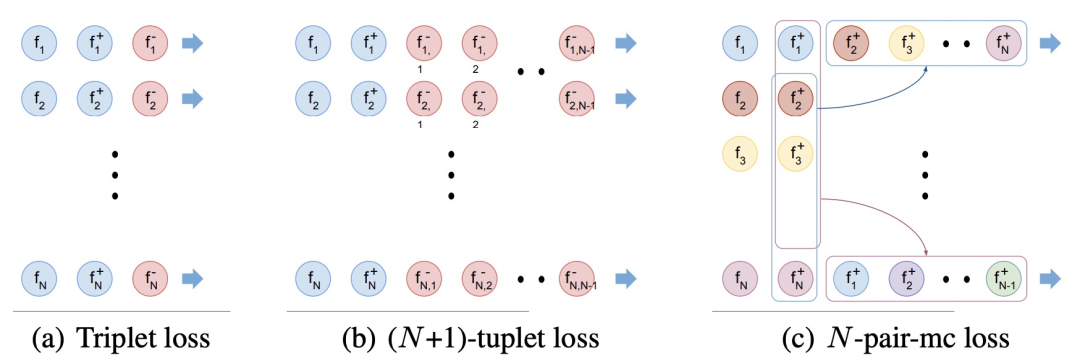
Improved Deep Metric Learning with Multi-class N-pair Loss Objective(NIPS 2016)提出N-pairLoss。在之前提出的contrastive loss和triplet loss中,每次更新只會使用一個負樣本,而無法見到多種其他類型負樣本信息,因此模型優化過程只會保證當前樣本的embedding和被采樣的負樣本距離遠,無法保證和所有類型的負樣本都遠,會影響模型收斂速度和效果。即使多輪更新,但是這種情況仍然會導致每輪更新的不穩定性,導致學習過程持續震蕩。
為了解決這個問題,讓模型在每輪更新中見到更多的負樣本,本文提出了N-pair loss,主要改進是每次更新的時候會使用多個負樣本的信息。N-pair loss可以看成是一種triplet loss的擴展,兩個的關系如下圖,當我們有1個正樣本和N-1個負樣本時,N-pair loss的計算方式:
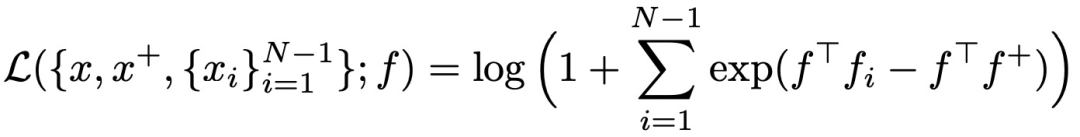
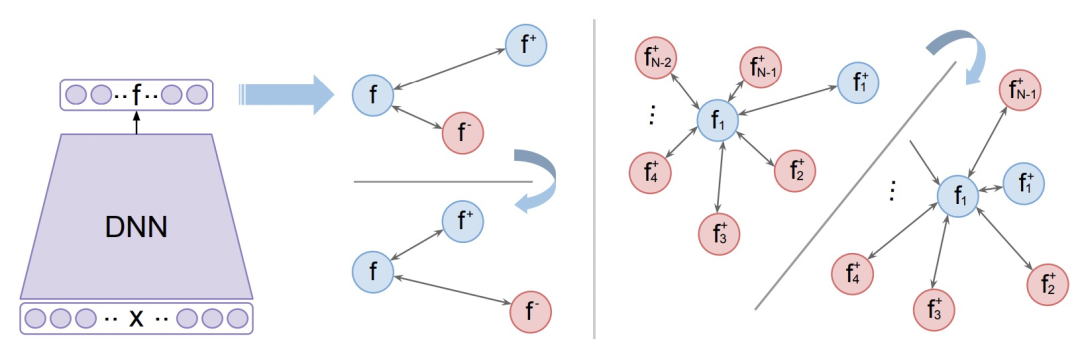
擴大負樣本數量的問題在于,原來每個batch內只需要計算N*3個樣本,現在需要計算N*(N+1)個樣本,運算量大幅度提高,難以實現。為了解決這個問題,文中提出將一個batch內不同樣本的負樣本數據共享,這樣只需要計算3*N個樣本的embedding即可,實現了效率提升。
4. InfoNceLoss
Representation learning with contrastive predictive coding(2018)提出infoNce loss,是對比學習中最常用的loss之一,它和softmax的形式很相似,主要目標是給定一個query,以及k個樣本,k個樣本中有一個是和query匹配的正樣本,其他都是負樣本。當query和正樣本相似,并且和其他樣本都不相似時,loss更小。InfoNCE loss可以表示為如下形式,其中r代表temperature,采用內積的形式度量兩個樣本生成向量的距離,InfoNCE loss也是近兩年比較火的對比學習中最常用的損失函數之一:
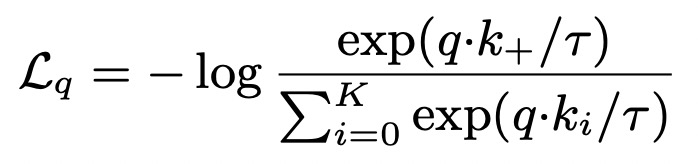
相比softmax,InfoNCE loss使用了temperature參數,以此將樣本的差距拉大,提升模型的收斂速度。
5. Focal Loss
Focal Loss for Dense Object Detection(2018)提出Focal Loss,最開始主要是為了解決目標檢測中的問題,但是在很多其他領域也可以適用。Focal Loss解決的核心問題是,當數據中有很多容易學習的樣本和較少的難學習樣本時,如何調和難易樣本的權重。如果數據中容易的樣本很多,難的樣本很少,容易的樣本就會對主導整體loss,對難樣本區分能力弱。
為了解決這個問題,Focal Loss根據模型對每個樣本的打分結果給該樣本的loss設置一個權重,減小容易學的樣本(即模型打分置信的樣本)的loss權重。在交叉熵的基礎上,公式可以表示如下:
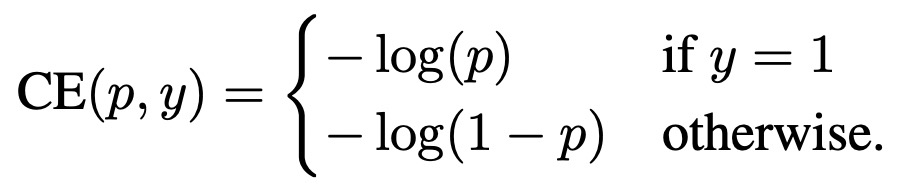
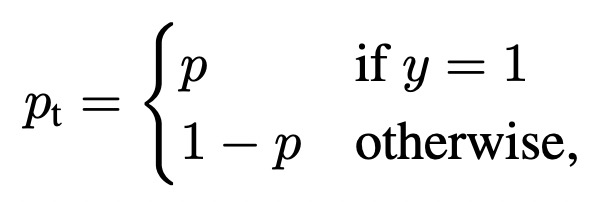
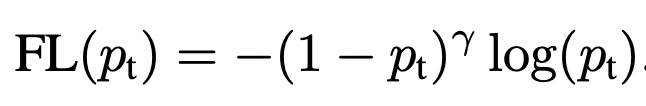
其中pt表示,當label為1時模型的預測值,當label為0時1-模型的預測值。通過對這個loss公式的分析可以看出,對于label為1的樣本,且模型預測值接近1,這個時候該樣本分類正確且容易預測,則第一項權重接近0,顯著減小了這種易分類樣本的loss權重。當label為0,模型預測值接近1時,屬于預測錯誤,loss的權重也是接近1的,對該樣本的loss基本沒有影響。
6. GHM Loss
在Focal Loss中強制讓模型關注難分類的樣本,但是數據中可能也存在一些異常點,過度關注這些難分類樣本,反而會讓模型效果變差。Gradient Harmonized Single-stage Detector(AAAI 2019)提出了GHM Loss,
首先分析了一個收斂的目標檢測模型中,所有樣本梯度模長的分布情況。梯度模長衡量了一個樣本對模型梯度的影響大小(不考慮方向),反映了一個樣本的難以程度,g越大模型因為此樣本需要更新的梯度越大,預測難度越大。基于交叉熵和模型輸出,梯度模長g定義如下:
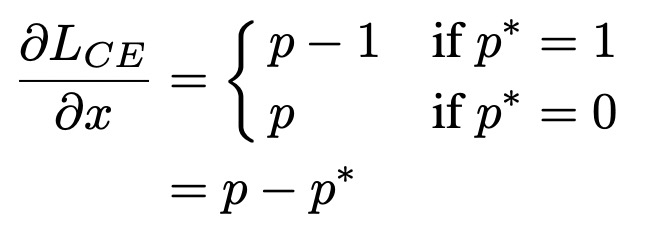
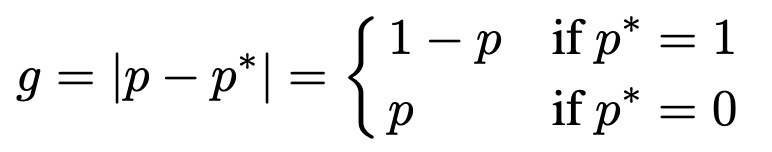
一個收斂的目標檢測模型的梯度模長分布如下,簡單樣本(即g很小的樣本)占絕大多數,這部分樣本是我們希望減小其loss權重的;同時還有很多難樣本,它們的g非常大,這部分可以被視作異常點,因為它們的梯度不符合大多數樣本,對于這部分極難樣本也應該減小權重。
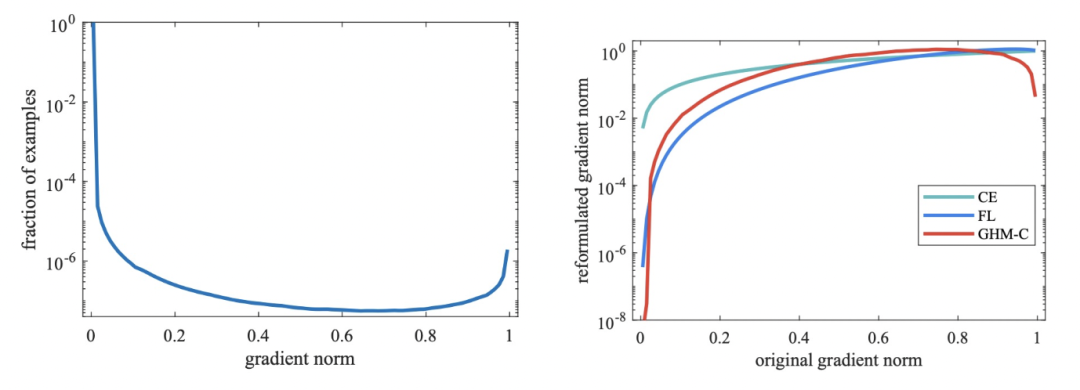
為了同時減小易學習樣本和異常點樣本的權重,文中引入了梯度密度的概念(GD),衡量單位梯度模長的樣本密度。這個梯度密度用來作為交叉熵loss中的樣本權重,公式如下:
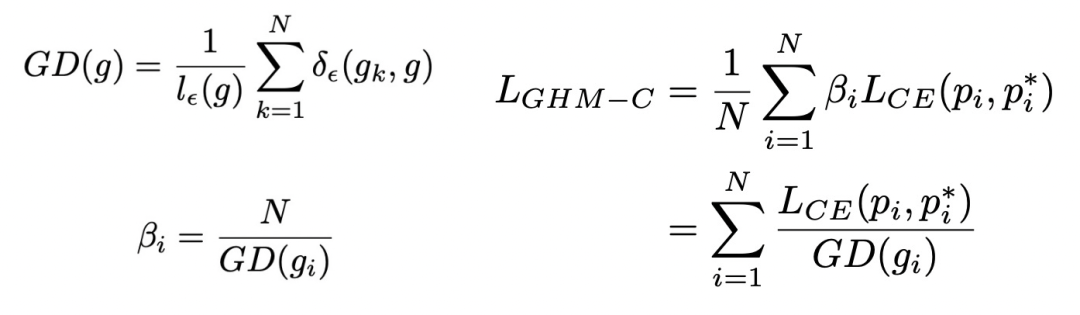
上面右側的圖對比了各種loss對不同梯度模長樣本的影響情況,可以看到GHM對于簡單樣本和困難樣本都進行了一定的loss抑制,而Focal Loss只能對簡單樣本進行loss抑制,普通loss對這兩類樣本都沒有抑制作用。
7. Circle Loss
Circle Loss: A Unified Perspective of Pair Similarity Optimization(CVPR 2020)提出circle loss,從一個統一的視角融合了class-level loss和pair-wise loss。這兩種優化目標,其實都是在最小化sn-sp,其中sn表示between-class similarity,即不同類別的樣本表示距離應該盡可能大;sp表示within-class similarity,即相同類別的樣本表示距離盡可能小。因此,兩種類型的loss都可以寫成如下統一形式:
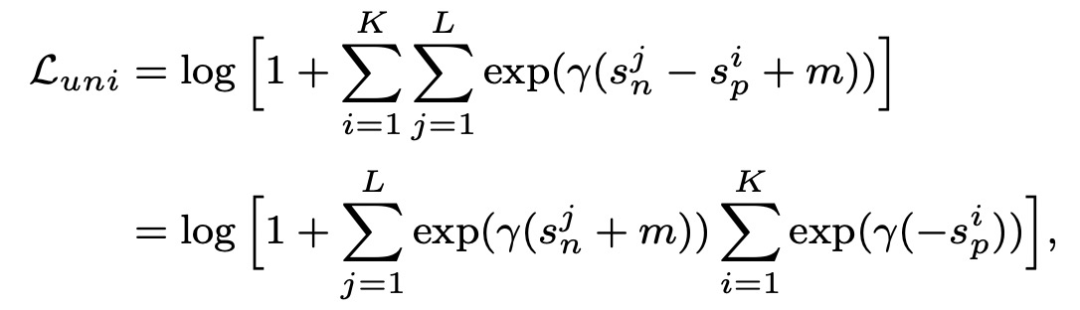
基于sn-sp這種loss存在的問題是,優化過程中對sn和sp的懲罰力度是一樣的。例如下面左圖中,A點的sn已經很小了,滿足要求了,而sp還不夠大,sn-sp這種優化方法讓sn和sp的更新幅度相同。而更好的方法是多更新一些sp,少更新一些sn。此外,這種loss在優化過程中也會導致模棱兩可的情況,導致收斂狀態不明確。例如T和T'這兩個點,都滿足給定margin的情況下的優化目標,但卻存在不同的優化點。
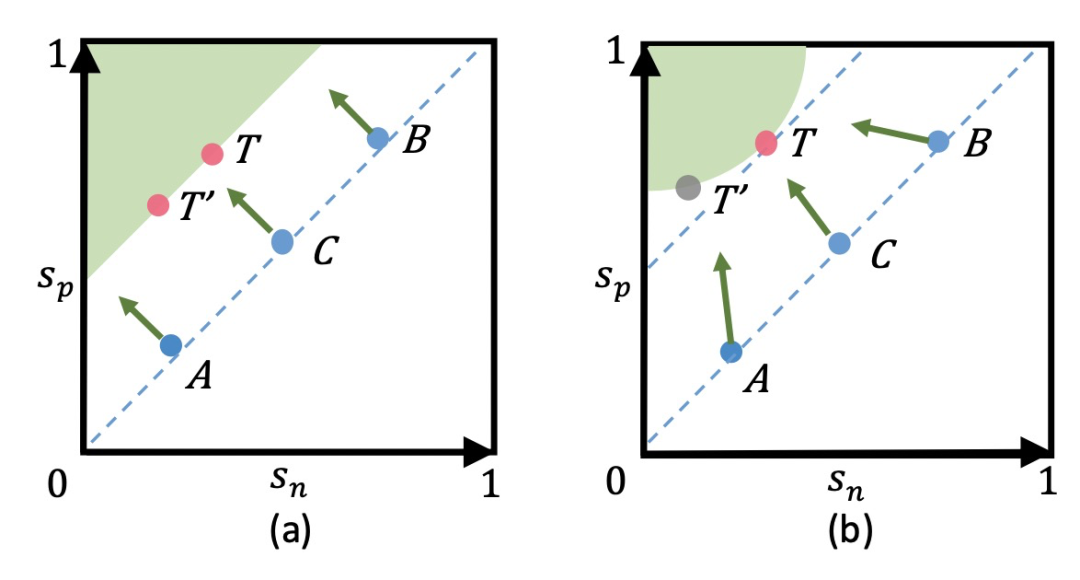
為了解決這個問題,circle loss在sn和sp分別增加了權重,用來動態確定sn和sp更新的力度,實現sn和sp以不同步調學習,circle loss的公式如下。當sn或sp相似度結果距離各自的最優點較遠時,會以一個更大的權重進行更新。同時,在這種情況下loss不再是對稱的,需要對sn和sp分別引入各自的margin。
8. 總結
損失函數是影響表示學習效果的關鍵因素之一,本文介紹了表示學習中7大損失函數的發展歷程,核心思路都是通過對比的方式約束模型生成的表示滿足相似樣本距離近,不同樣本距離遠的原則。 審核編輯:郭婷
-
編碼器
+關注
關注
45文章
3953瀏覽量
142642
原文標題:表示學習中的7大損失函數梳理
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「芯片設計基石——EDA產業全景與未來展望」閱讀體驗】--EDA了解與發展概況
C語言回調函數原來這么簡單
新思科技在中國30周年的發展歷程回顧
【精選直播】無感FOC控制中滑模觀測器估算轉子角度思路分享

寶馬集團車載總線技術的發展歷程
鴻蒙發展歷程
智能氮氣柜的發展歷程和前景展望




 工商網監
工商網監
評論