 基于自動駕駛場景Occupancy和Flow的運動預測
基于自動駕駛場景Occupancy和Flow的運動預測

摘要:近年來自動駕駛場景中的預測任務逐漸興起一種新形式,即預測未來基于鳥瞰圖的空間占有柵格(occupancy)和光流(flow)。此類預測任務與傳統預測軌跡的任務相比在很多場景下會提供更多的信息,作為自動駕駛上下游的一環,有著更廣泛的應用場景。在今年的Waymo Open Dataset Challenge 2022上,Waymo推出了此任務的全新挑戰賽。地平線在這個項目上研發出了一種全新的利用時空信息進行編碼解碼的層級網絡,通過多重編碼網絡,多尺度時空融合,預測隱變量以及聯合柵格占有和光流的損失函數等創新性技術,將這一任務的精度推上新的高度。
背景
預測任務是自動駕駛場景中至關重要的一項任務,其目的是通過對運動物體的歷史軌跡和運動狀態的觀測,結合道路信息,推測其未來的行為,為下游的規劃控制提供更豐富的預測信息。其表征形式通常為多條未來可能的軌跡。近年來,越來越多的研究表明,基于鳥瞰圖的空間占有柵格和光流的表征形式相比多條軌跡預測有更強的表征能力。相比于軌跡的形式,占有柵格有更豐富的空間分布信息,能更好的表征動態物體的位置,形狀,身份的不確定性;其聯合概率分布的形式在一定程度上可以處理物體之間的交互的能力;同時,所有的動態物體可以同時并行處理,極大地提升了處理的效率;另外,此種方法還具有推測被遮擋物體的能力,能有效預防諸如“鬼探頭”等的情況;最后,其鳥瞰圖下的表征形式能更好地與上下游相結合。基于這個趨勢,Waymo于今年推出了全新的自動駕駛挑戰賽項目,即Occupancy and Flow Prediction Challenge。此挑戰賽給定過去一秒中動態物體(車輛,自行車和行人)的運動軌跡,要求對未來八秒的可觀測物體的柵格占有、遮擋物體的柵格占有以及對應光流做預測。本方法結合了CNN、transformer、三維稀疏卷積等優勢,利用隱變量豐富了未來的信息,創新性地引入了層級時序解碼機制,在此次Waymo挑戰賽中取得了極佳的成績。
方法
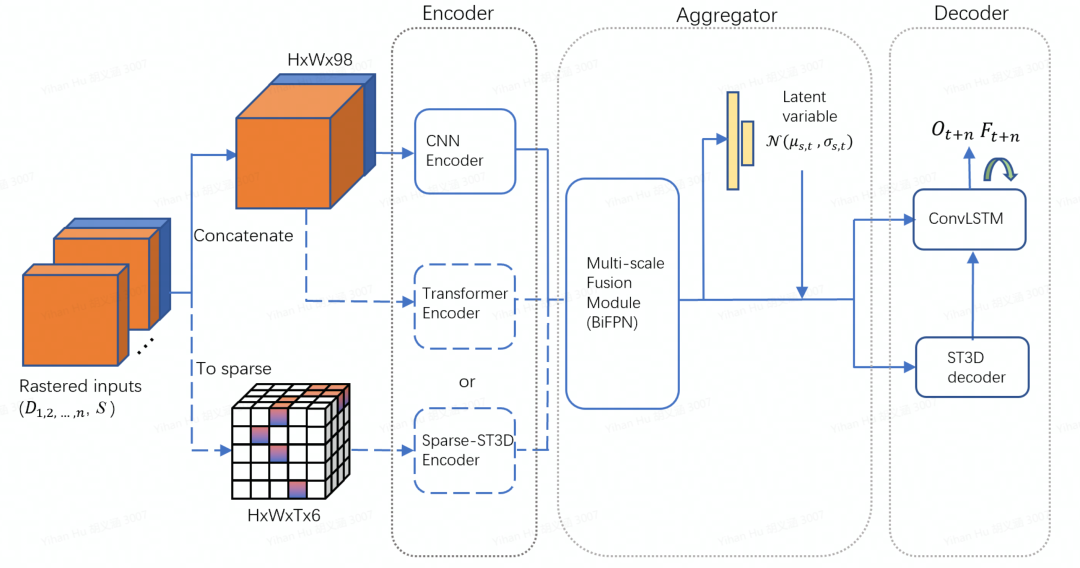
輸入
模型的輸入包含了動態信息和靜態信息。其中動態信息包含了歷史幀和當前幀的動態物體(車輛,自行車和行人)的空間占有柵格信息以及對應物體的屬性信息(比如物體檢測框的長寬高和速度等信息),靜態信息包含了整個場景的路面相關信息(比如道路中線,道路邊緣,路面其他特征等)。所有信息都被處理成二維鳥瞰圖并進一步進行時間尺度上的聚合。我們同時使用了2D編碼器和3D編碼器,其中針對2D編碼器,動態信息輸入會直接在特征維上進行時間拼接;而針對3D編碼器,時間會作為額外的維度(靜態信息在每一幀上進行復制),并且輸入會作稀疏化處理。 編碼器
編碼器一共分為三種,分別是基本編碼器,注意力編碼器以及時空編碼器
基本編碼器:作為整個框架的基本編碼器,我們選擇使用了RegNet[1]模型。RegNet是一個設計完備且效率很高的模型。編碼器經過層層降采樣編碼,生成了5個維度上的特征,對應的尺度分別是輸入的1/2,1/4,1/8,1/16和1/32。
注意力編碼器:近年來,在檢測和分割任務中,SwinTransformer及其升級版SwinTransformerV2[2]取得了很好的結果。基于其獨特的局部窗口注意力機制,不僅能很好地編碼動態物體和路面間的交互,還大量地減少了網絡計算量,因此我們使用了SwinTransformerV2來作為整個網絡的注意力編碼器。為了可以和基本編碼器輸出特征的尺度相對應,我們將每個patch的尺寸由4改成了2,由此注意力編碼器可以輸出和基本編碼器尺度相同的5個特征。
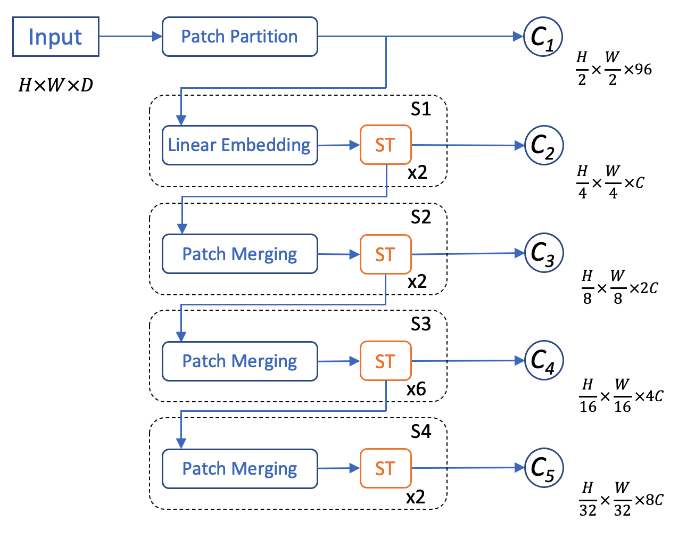
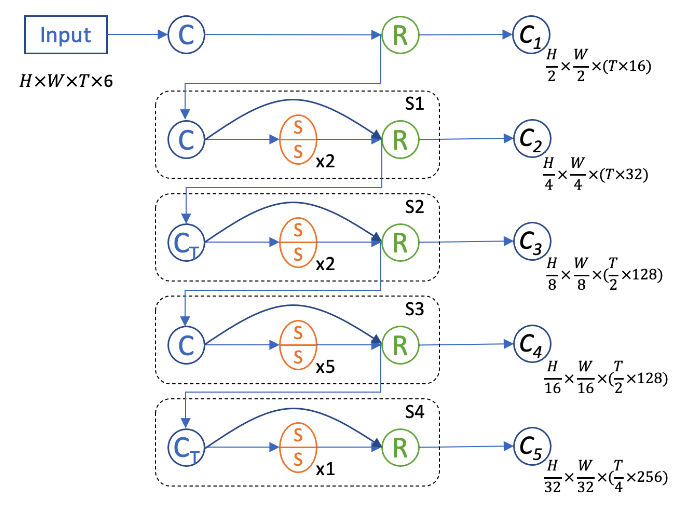
時空編碼器:為了更好地進行幀間信息交互提取,我們設計了一個3D時空編碼器來額外捕捉時間尺度上的信息。因為我們的輸入信息在鳥瞰圖上有著很高的稀疏度,我們選擇使用3D稀疏卷積和子流形稀疏卷積[3]來搭建網絡。這樣既可以大量地加速3D卷積的計算也可以有效防止稀疏特征在早期過快地膨脹(dilation)。我們對應其他編碼器,設計了5階段網絡,其中時間維在2和4階段進行下采樣。針對網絡的每個輸出特征,我們將時間維和特征維進行合并來使特征降維。
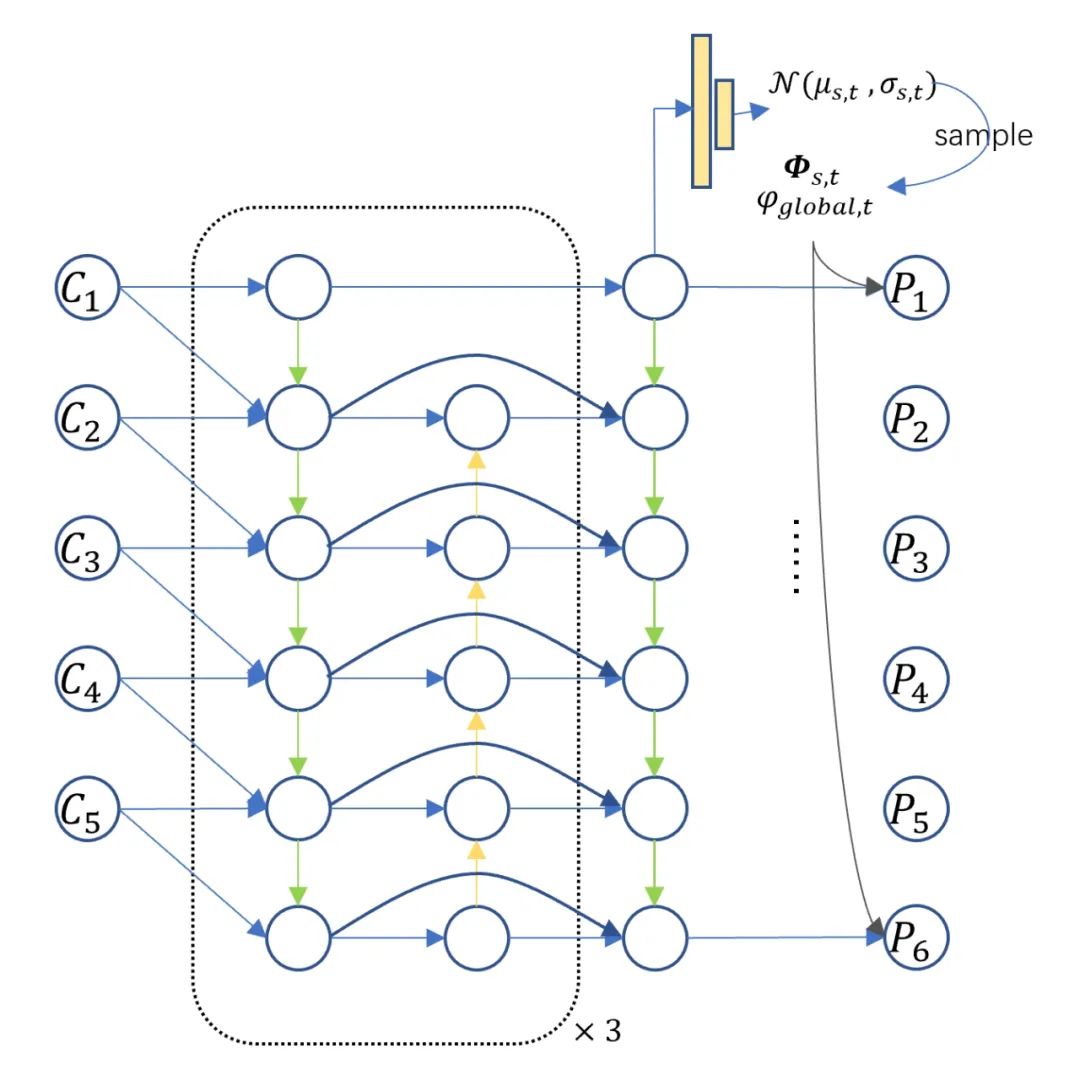
聚合器
聚合器由兩部分組成,在空間尺度上,我們利用BiFPN做多尺度的聚合;在時間尺度上,我們利用隱變量模型來豐富未來的信息。類比于條件變分器,我們在每一個尺度,每一個空間位置都對未來的概率進行建模。在訓練階段,我們基于現在時刻的概率分布做采樣。推理階段,我們直接采用概率分布均值。為了保證預測分布和已觀測分布的一致性,我們采用Kullback-Leibler divergence損失函數作為監督信號。
解碼器
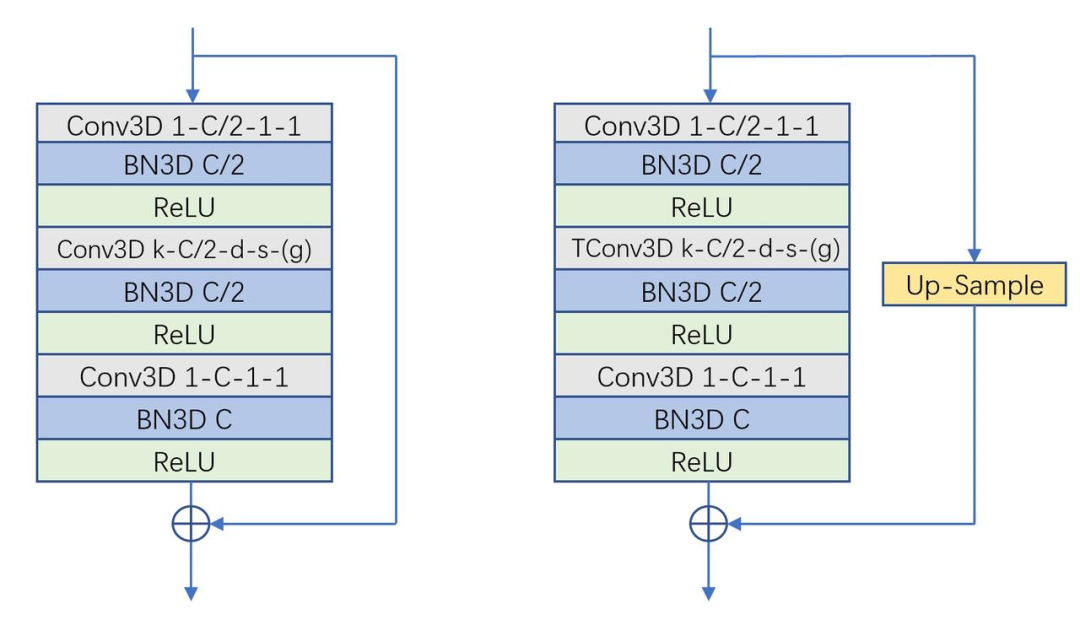
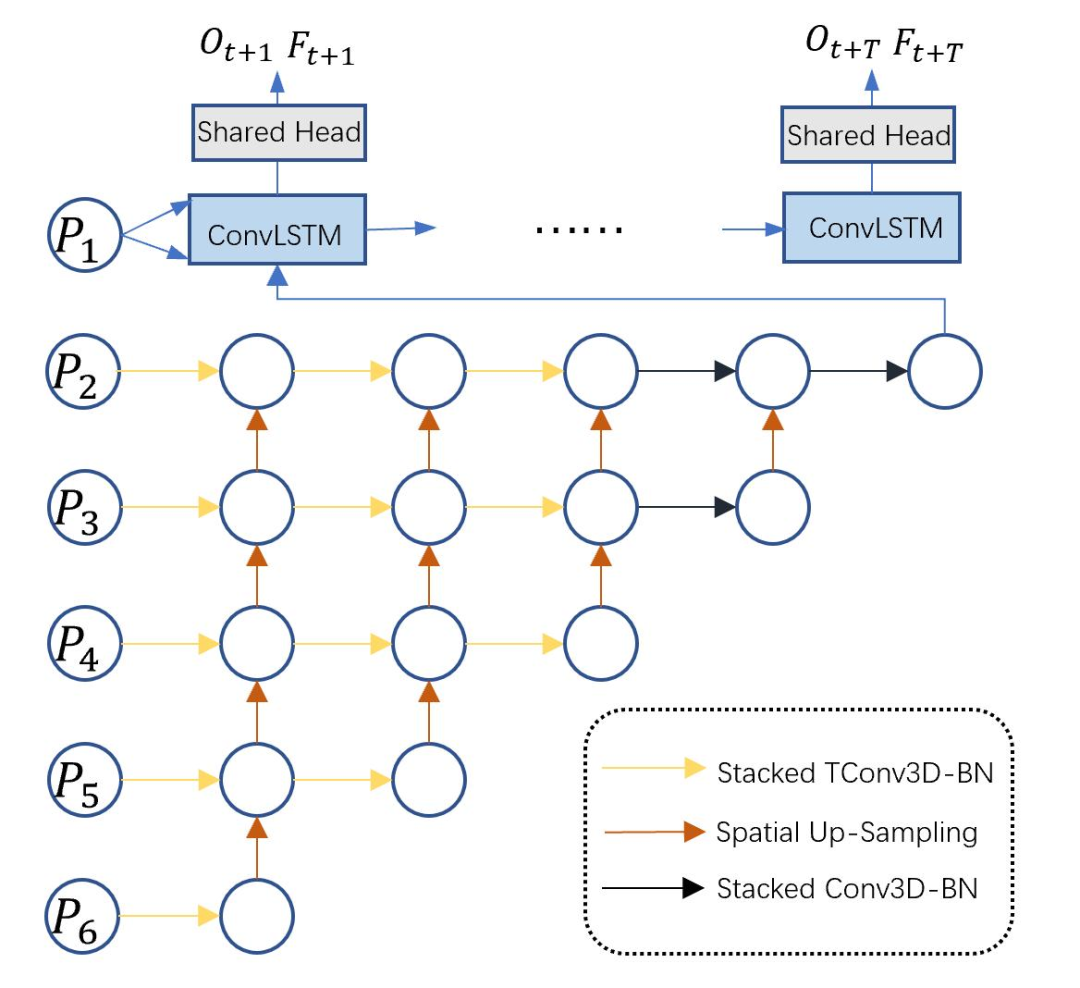
解碼器采用多層級多尺度的特征金字塔形式,基本的組成單元為3D卷積Bottleneck結構。3D bottleneck中采用了膨脹卷積和分組卷積,可以極大地擴大感受野并節省計算量。同時,為了將編碼后的2D特征做時序展開,我們引入了3D轉置卷積Bottleneck。這些堆疊的bottleneck通過上采樣進行多尺度的鏈接,有效地融合了多尺度的信息。同時,為了節省計算量,我們在輸出尺度上用ConvLSTM做時序上的修正。
損失函數
對于可觀測占有柵格和被遮擋占有柵格的預測,我們采用Focal Loss作為其監督信號,兩者采用相同的權重進行加權。
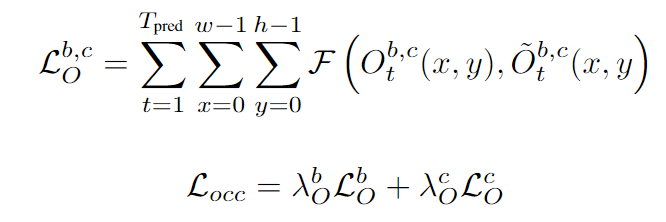
對于光流的預測,我們采用Smooth L1損失函數。為了將光流和占有率的預測解耦,我們利用占有率的真值做加權。
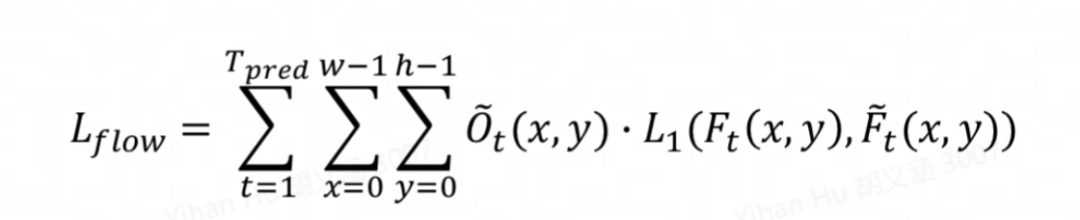
為了保證柵格占有率和光流預測的一致性,我們采用跟蹤損失函數進行進一步監督。利用光流的預測,我們可以對前一幀的柵格占有率進行空間變形來得到當前幀的基于光流的空間占有預測。
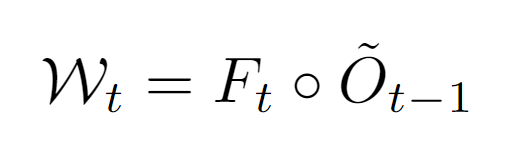
最后將基于光流的空間占有預測和當前幀柵格占有預測相乘,來得到當前幀的空間占有-光流聯合預測,并用此聯合預測和當前幀的柵格占有真值來計算損失函數traced loss。我們同時采用Focal loss和交叉熵損失函數進行監督[4]。
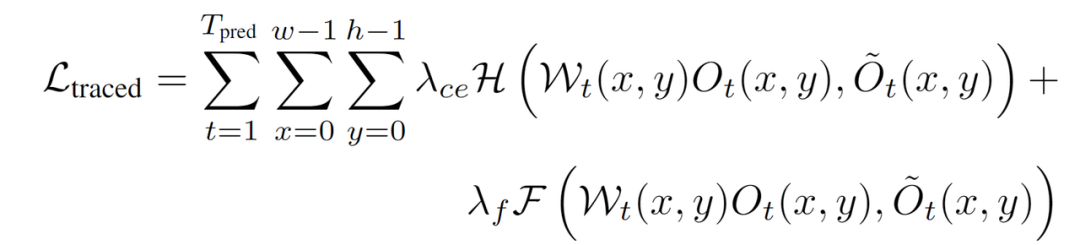
為保證聚合器中隱變量中現在和未來的一致性,我們采用Kullback-Leibler divergence損失函數作為監督信號[5]來監督預測的概率分布函數參數。
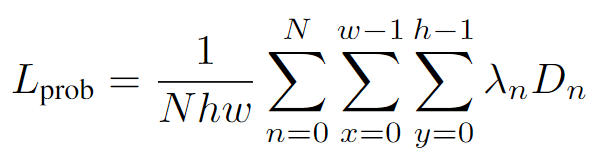
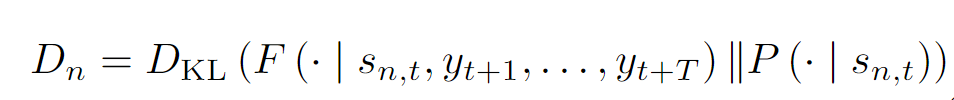
最后,所有的損失函數進行加權和作為最后的損失函數。
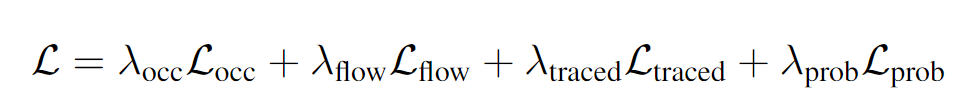
實驗結果
消融實驗
本表展示了在Waymo數據集上的消融實驗結果,灰色的一列為評測的主指標。可以看出,loss的改進,如focal loss和traced loss分別帶來了2.01%和0.46%的提升。同時,更豐富的柵格化輸入帶來了1.23%的提升。同時,結構化的改進,包括隱變量,時空解碼器,以及解碼器的改進帶來了約1.21%的提升。最后TTA帶來了約0.40%的提升。值得一提的是,所有的實驗都是在十分之一的數據集上做的驗證。這些結果充分的說明了我們方法的有效性。
測試集表現
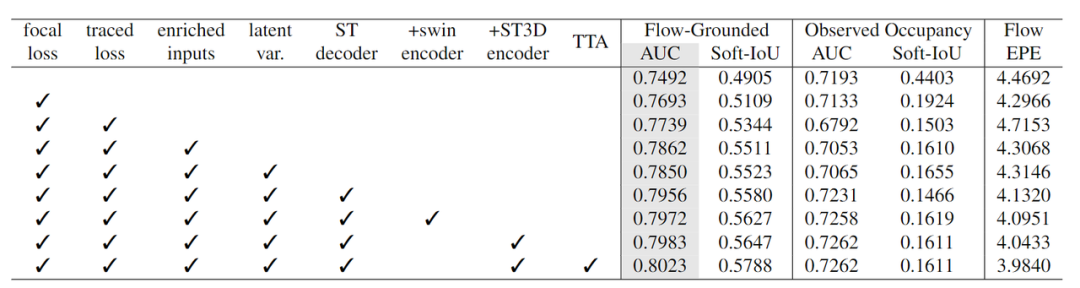
下表展示了我們方法在waymo測試集上的排名,灰色的一列代表評測的主指標,可以看出,我們的結果在主指標上大幅領先對手,充分說明我們方法的優越性。

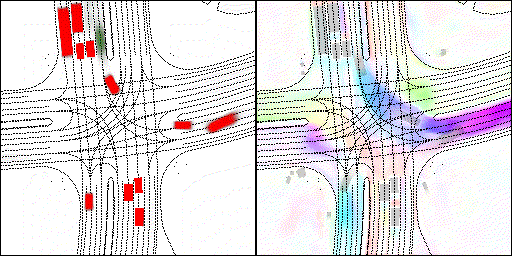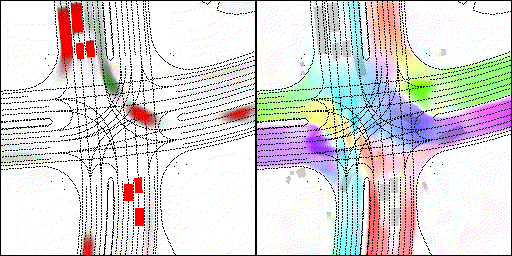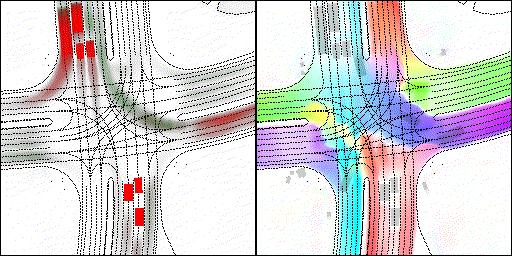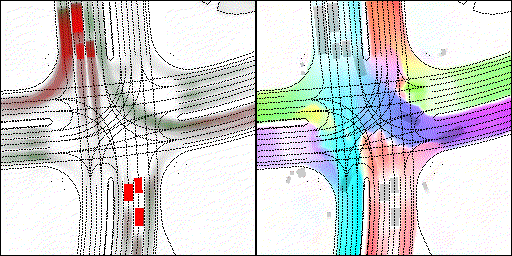
結果可視化
下面展示我們的方法在特定場景下的對接下來8秒占有柵格(左)和光流(右)的可視化結果。下面列出了直行,紅綠燈路口左轉右轉掉頭,無保護左轉,4-way-stop,無保護左轉,自主避障,停車入庫,被遮擋物體的猜測等場景。可以看出,我們的方法能有效地處理復雜場景,能實現多動態物體的交互,交通信息和規則的理解,自主避障,對被遮擋物體的推測等功能。
普通路面:主要展示對不同車速/加速減速情況的車流預測,可以看出HOPE能對未來軌跡的不確定性進行很好的建模
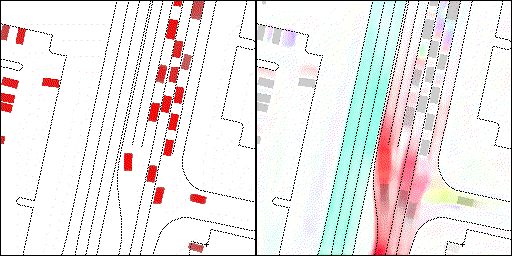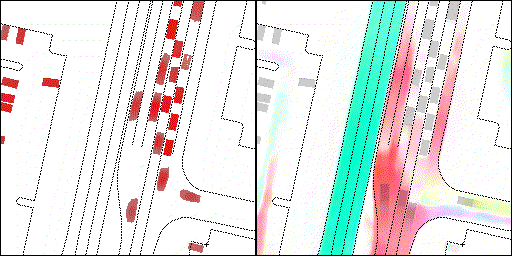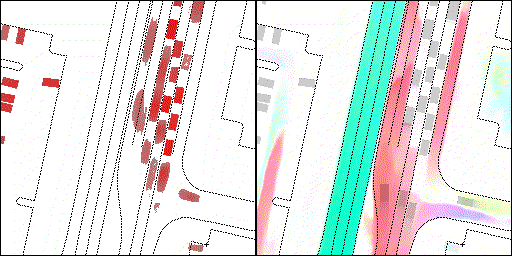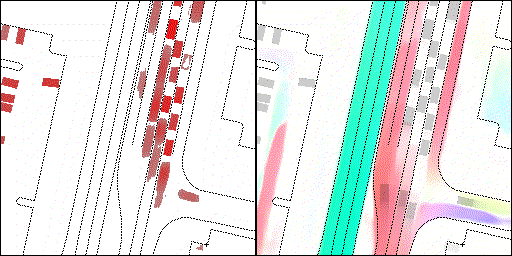
交叉路口:主要展示對不同轉彎,停車等待的車流預測
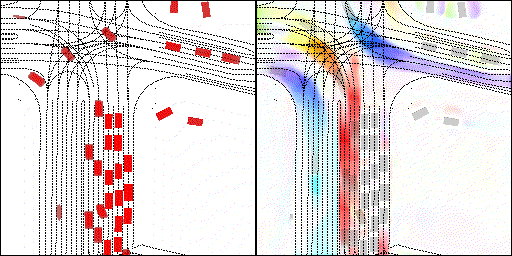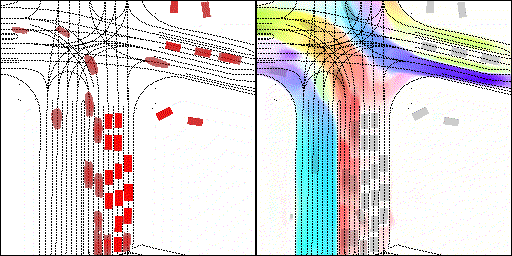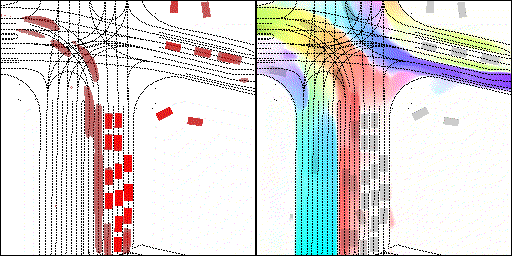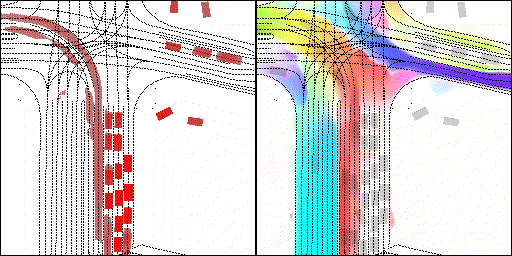
掉頭場景:復雜路口
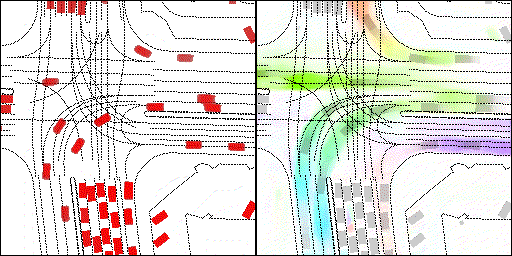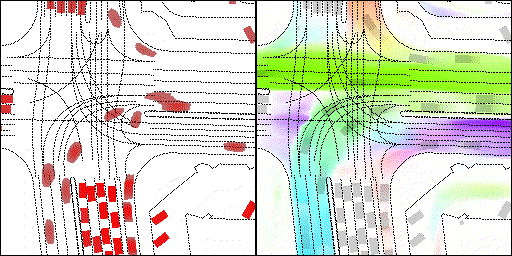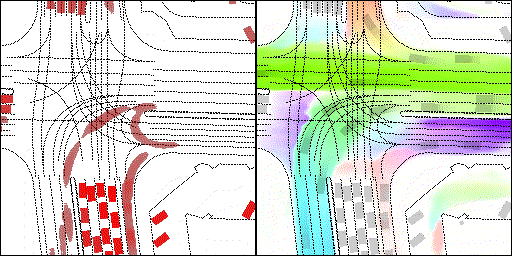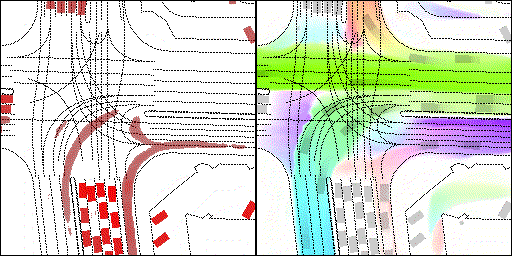
不確定場景:直行、右轉兩條車道都有可能駛入
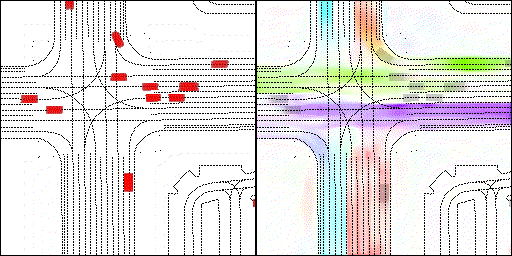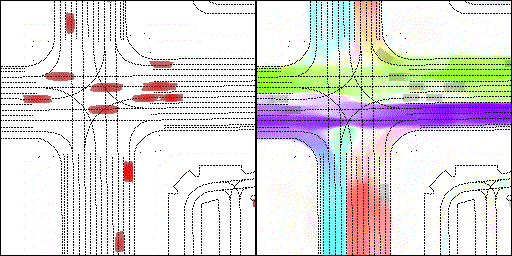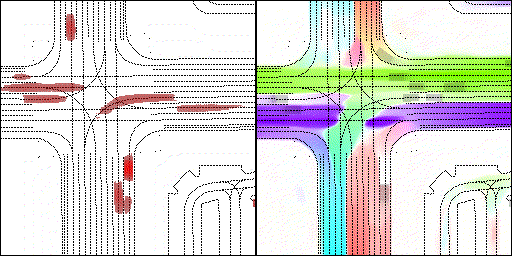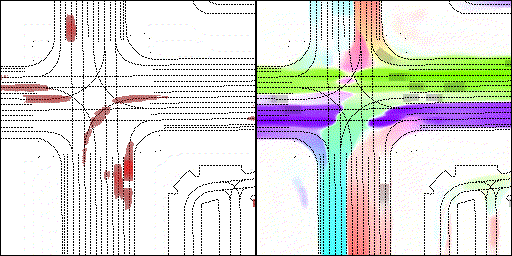
右轉:右轉車輛對直行車輛進行了避讓
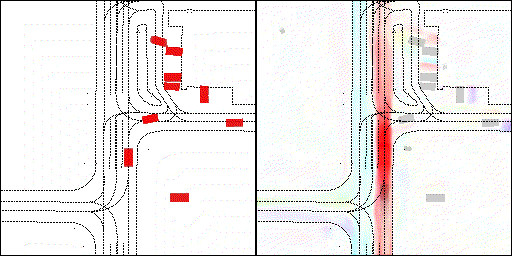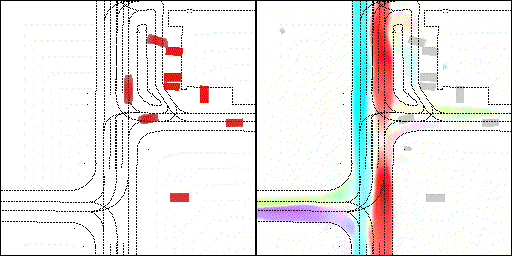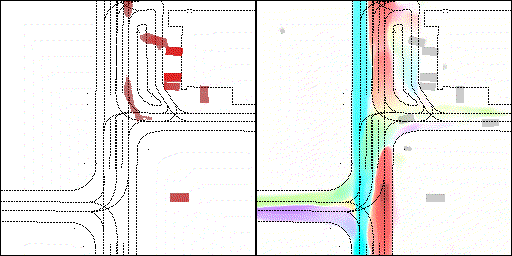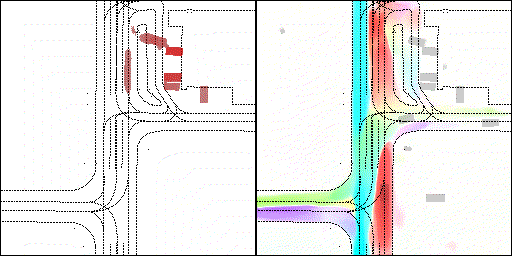
左轉:根據路口紅綠燈、交通規則等綜合信息對路權進行判斷
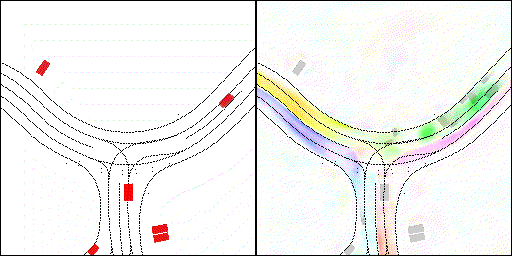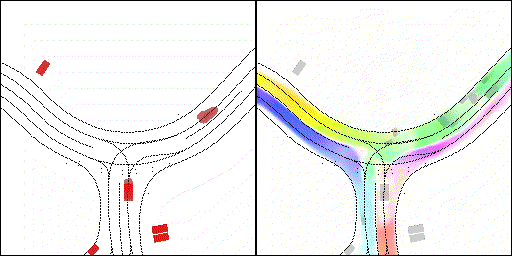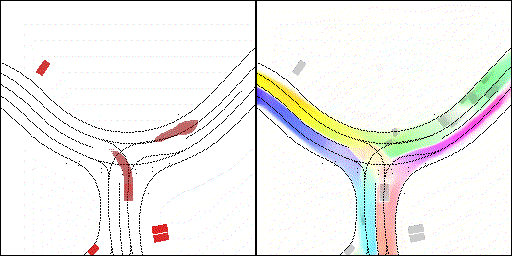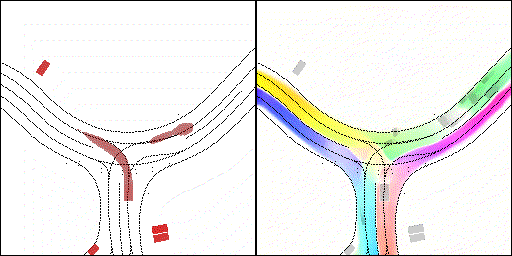
無保護左轉:左轉車輛對直行車輛進行了避讓
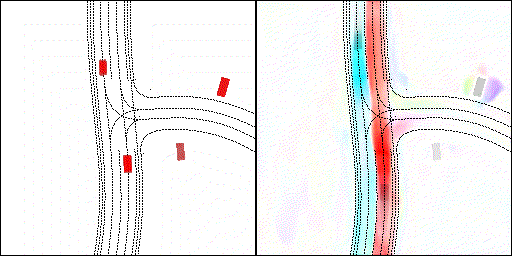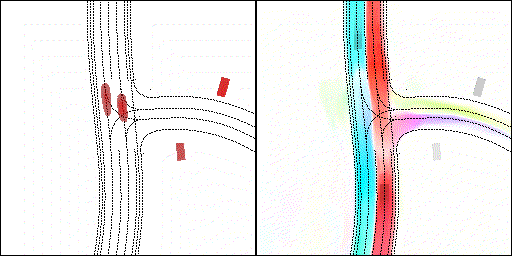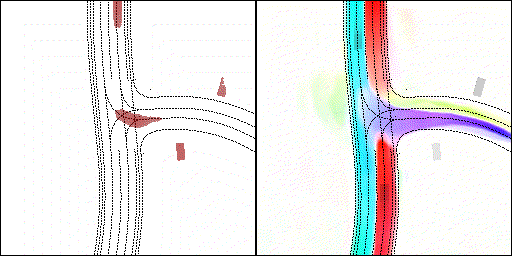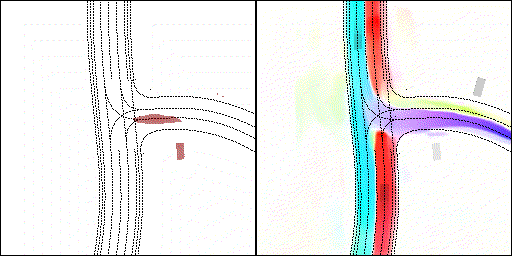
2 way stop:可以看見車輛交互,處理先來后到順序

遮擋繞行:可以看見車輛對前方靜止車輛進行了繞行

停車入庫:小樣本、低速場景預測,可以看見低速場景下軌跡的不確定性更高,模型可以有多種可能的軌跡預測

遮擋物體的猜測:綠色的為被遮擋物體
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3953瀏覽量
142638 -
3D
+關注
關注
9文章
3011瀏覽量
115048 -
自動駕駛
+關注
關注
793文章
14882瀏覽量
179854
發布評論請先 登錄
自動駕駛端到端為什么會出現黑盒現象?

自動駕駛汽車如何實現自動駕駛
自動駕駛場景生成方法及優選方案:康謀aiSim 3DGS方案重塑行業標準
如何設計好自動駕駛ODD?
世界模型是讓自動駕駛汽車理解世界還是預測未來?


自動駕駛為什么要重視軌跡預測?

無引導線的左轉場景下,自動駕駛如何規劃軌跡?
自動駕駛汽車如何處理“鬼探頭”式的邊緣場景?
低速和高速自動駕駛的應用場景和技術方向有何不同?
卡車、礦車的自動駕駛和乘用車的自動駕駛在技術要求上有何不同?
自動駕駛安全基石:ODD
新能源車軟件單元測試深度解析:自動駕駛系統視角





 工商網監
工商網監
評論