 Trie樹數據結構的實現原理和題目實踐
Trie樹數據結構的實現原理和題目實踐

作者:labuladong
公眾號:labuladong
讀完本文,可以去力扣解決如下題目:
208. 實現 Trie (前綴樹)(Medium)
1804. 實現 Trie (前綴樹) II(Medium)
648. 單詞替換(Medium)
211. 添加與搜索單詞(Medium)
677. 鍵值映射(Medium)
Trie 樹又叫字典樹、前綴樹、單詞查找樹,是一種二叉樹衍生出來的高級數據結構,主要應用場景是處理字符串前綴相關的操作。
后臺有挺多讀者說今年的面試筆試題涉及到這種數據結構了,所以請我講一講。
幾年前我在《算法 4》第一次學到這種數據結構,不過個人認為講解不是特別通俗易懂,所以本文按照我的邏輯幫大家重新梳理一遍 Trie 樹的原理,并基于《算法 4》的代碼實現一套更通用易懂的代碼模板,用于處理力扣上一系列字符串前綴問題。
閱讀本文之前希望你讀過我舊文講過的回溯算法代碼模板和手把手刷二叉樹(總結篇)。
本文主要分三部分:
1、講解 Trie 樹的工作原理。
2、給出一套TrieMap和TrieSet的代碼模板,實現幾個常用 API。
3、實踐環節,直接套代碼模板秒殺 5 道算法題。本來可以秒殺七八道題,篇幅考慮,剩下的我集成到刷題插件中。
關于Map和Set,是兩個抽象數據結構(接口),Map存儲一個鍵值對集合,其中鍵不重復,Set存儲一個不重復的元素集合。
常見的Map和Set的底層實現原理有哈希表和二叉搜索樹兩種,比如 Java 的 HashMap/HashSet 和 C++ 的 unorderd_map/unordered_set 底層就是用哈希表實現,而 Java 的 TreeMap/TreeSet 和 C++ 的 map/set 底層使用紅黑樹這種自平衡 BST 實現的。
而本文實現的 TrieSet/TrieMap 底層則用 Trie 樹這種結構來實現。
了解數據結構的讀者應該知道,本質上Set可以視為一種特殊的Map,Set其實就是Map中的鍵。
所以本文先實現TrieMap,然后在TrieMap的基礎上封裝出TrieSet。
PS:為了模板通用性的考慮,后文會用到 Java 的泛型,也就是用尖括號
<>指定的類型變量。這些類型變量的作用是指定我們實現的容器中存儲的數據類型,類比 Java 標準庫的那些容器的用法應該不難理解。
前文學習數據結構的框架思維說過,各種亂七八糟的結構都是為了在「特定場景」下盡可能高效地進行增刪查改。
你比如HashMap的優勢是能夠在 O(1) 時間通過鍵查找對應的值,但要求鍵的類型K必須是「可哈希」的;而TreeMap的特點是方便根據鍵的大小進行操作,但要求鍵的類型K必須是「可比較」的。
本文要實現的TrieMap也是類似的,由于 Trie 樹原理,我們要求TrieMap的鍵必須是字符串類型,值的類型V可以隨意。
接下來我們了解一下 Trie 樹的原理,看看為什么這種數據結構能夠高效操作字符串。
Trie 樹原理
Trie 樹本質上就是一棵從二叉樹衍生出來的多叉樹。
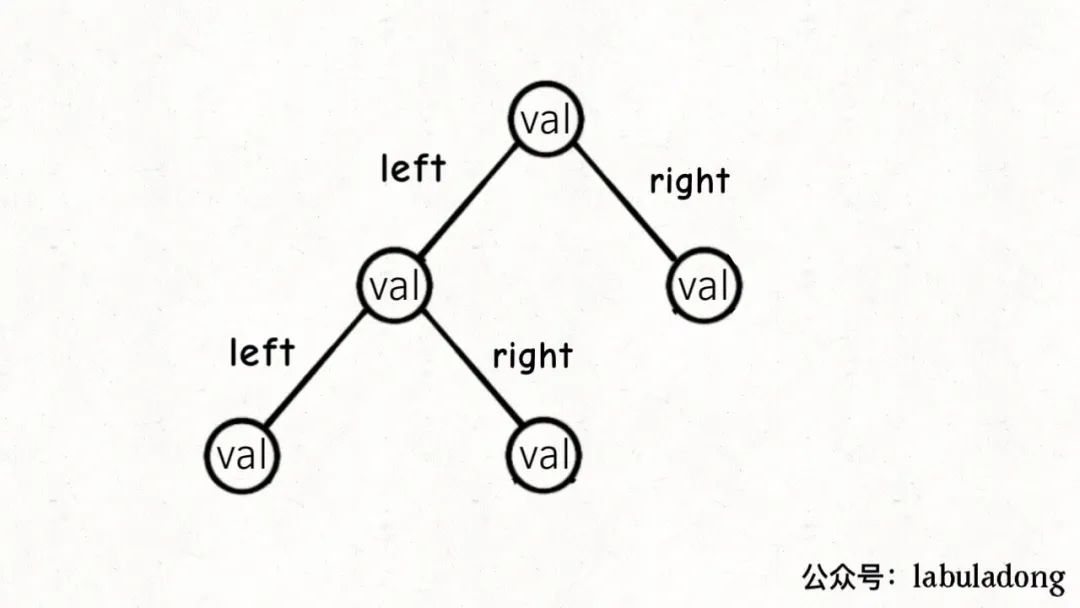
二叉樹節點的代碼實現是這樣:
/*基本的二叉樹節點*/
classTreeNode{
intval;
TreeNodeleft,right;
}
其中left, right存儲左右子節點的指針,所以二叉樹的結構是這樣:
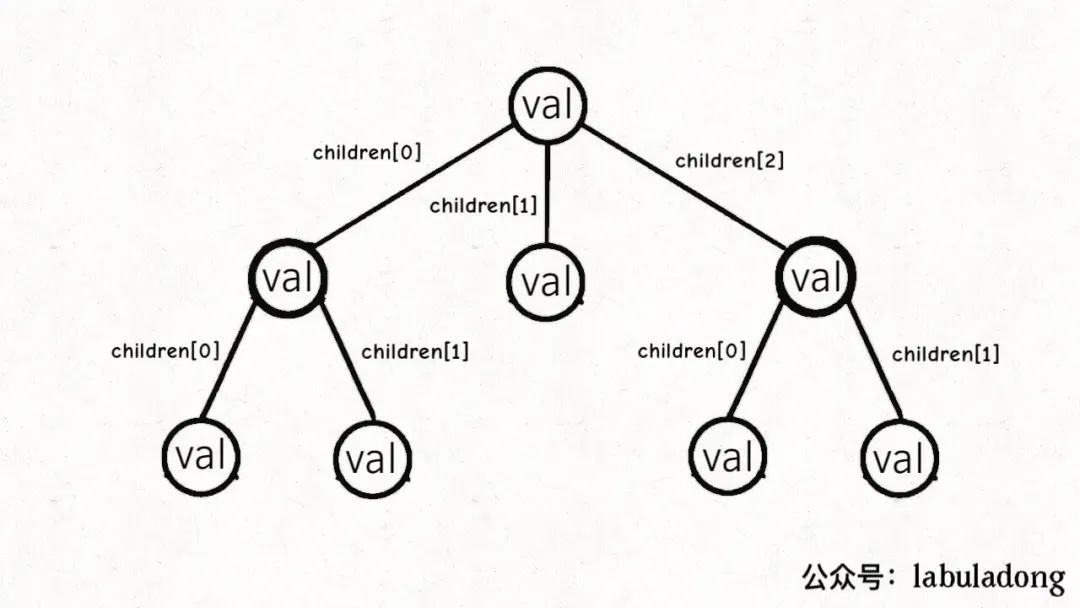
多叉樹節點的代碼實現是這樣:
/*基本的多叉樹節點*/
classTreeNode{
intval;
TreeNode[]children;
}
其中children數組中存儲指向孩子節點的指針,所以多叉樹的結構是這樣:
而TrieMap中的樹節點TrieNode的代碼實現是這樣:
/*Trie樹節點實現*/
classTrieNode<V>{
Vval=null;
TrieNode[]children=newTrieNode[256];
}
這個val字段存儲鍵對應的值,children數組存儲指向子節點的指針。
但是和之前的普通多叉樹節點不同,TrieNode中children數組的索引是有意義的,代表鍵中的一個字符。
比如說children[97]如果非空,說明這里存儲了一個字符'a',因為'a'的 ASCII 碼為 97。
我們的模板只考慮處理 ASCII 字符,所以children數組的大小設置為 256。不過這個可以根據具體問題修改,比如改成更小的數組或者HashMap都是一樣的效果。
有了以上鋪墊,Trie 樹的結構是這樣的:
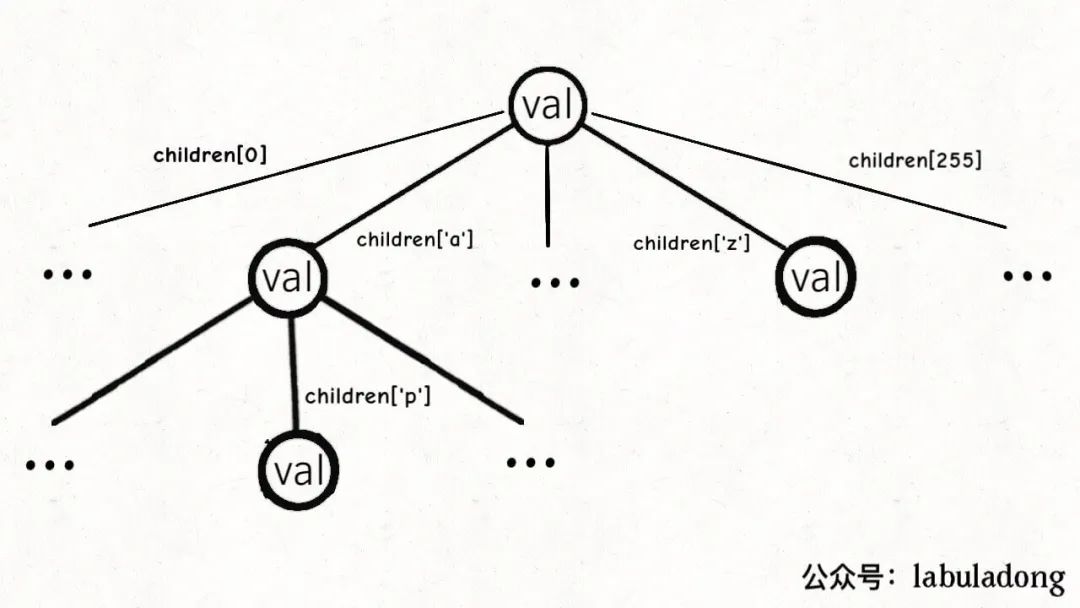
一個節點有 256 個子節點指針,但大多數時候都是空的,可以省略掉不畫,所以一般你看到的 Trie 樹長這樣:
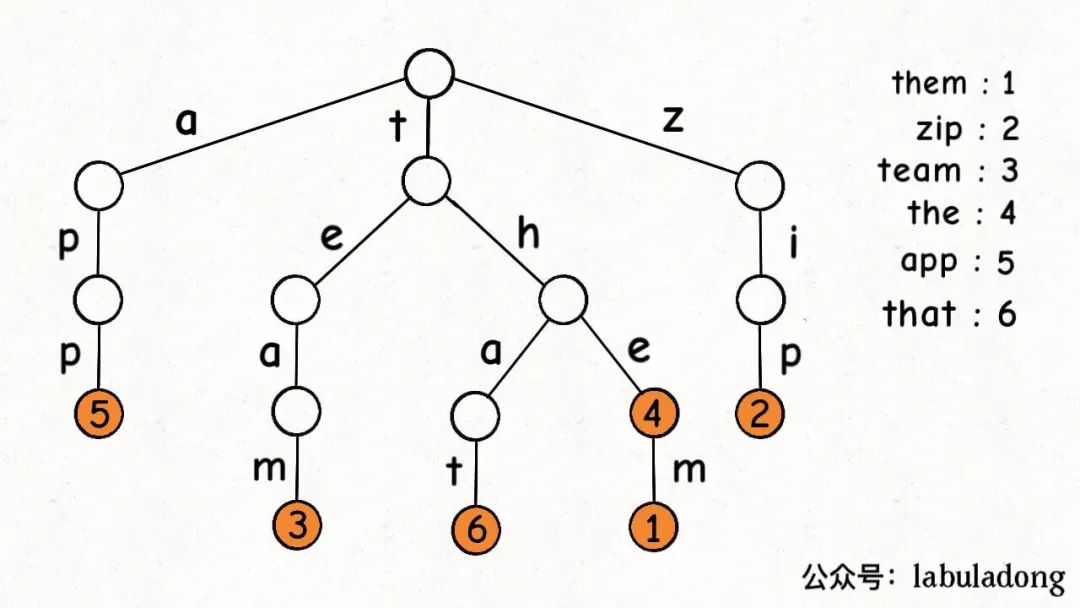
這是在TrieMap中插入一些鍵值對后的樣子,白色節點代表val字段為空,橙色節點代表val字段非空。
這里要特別注意,TrieNode節點本身只存儲val字段,并沒有一個字段來存儲字符,字符是通過子節點在父節點的children數組中的索引確定的。
形象理解就是,Trie 樹用「樹枝」存儲字符串(鍵),用「節點」存儲字符串(鍵)對應的數據(值)。所以我在圖中把字符標在樹枝,鍵對應的值val標在節點上:
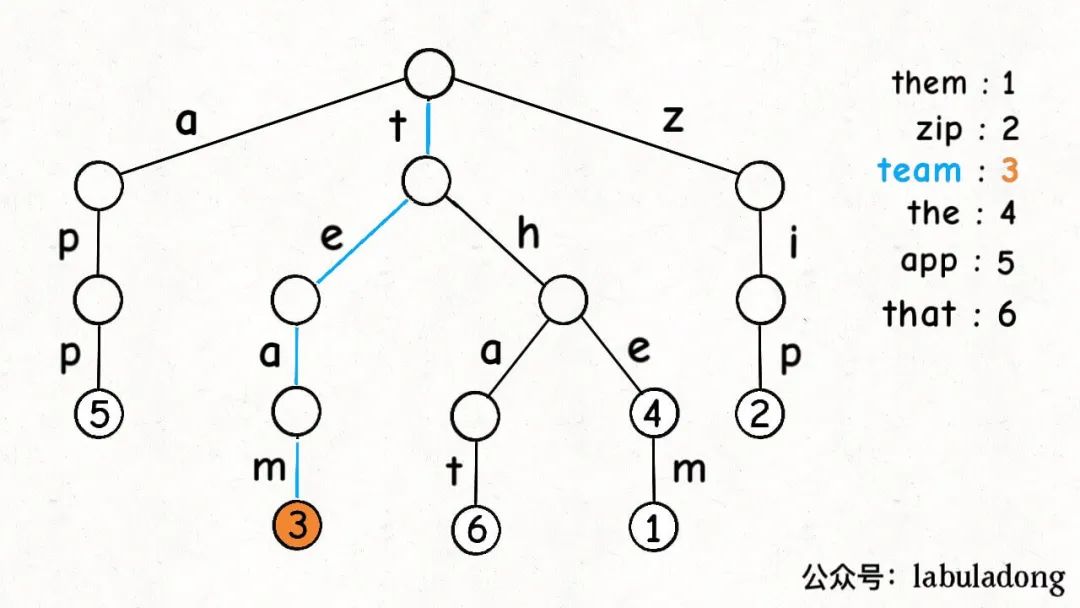
明白這一點很重要,有助于之后你理解代碼實現。
PS:《算法 4》以及網上講 Trie 樹的很多文章中都是把字符標在節點上,我認為這樣很容易讓初學者產生誤解,所以建議大家按照我的這種理解來記憶 Trie 樹結構。
現在你應該知道為啥 Trie 樹也叫前綴樹了,因為其中的字符串共享前綴,相同前綴的字符串集中在 Trie 樹中的一個子樹上,給字符串的處理帶來很大的便利。
TrieMap/TrieSet API 及實現
首先我們看一下本文實現的TrieMap的 API,為了舉例 API 的功能,假設 TrieMap 中已經存儲了如下鍵值對:
//底層用Trie樹實現的鍵值映射 //鍵為String類型,值為類型VclassTrieMap<V>{ /*****增/改*****/ //在Map中添加key publicvoidput(Stringkey,Vval); /*****刪*****/ //刪除鍵key以及對應的值 publicvoidremove(Stringkey); /*****查*****/ //搜索key對應的值,不存在則返回null //get("the")->4 //get("tha")->null publicVget(Stringkey); //判斷key是否存在在Map中 //containsKey("tea")->false //containsKey("team")->true publicbooleancontainsKey(Stringkey); //在Map的所有鍵中搜索query的最短前綴 //shortestPrefixOf("themxyz")->"the" publicStringshortestPrefixOf(Stringquery); //在Map的所有鍵中搜索query的最長前綴 //longestPrefixOf("themxyz")->"them" publicStringlongestPrefixOf(Stringquery); //搜索所有前綴為prefix的鍵 //keysWithPrefix("th")->["that","the","them"] publicListkeysWithPrefix(Stringprefix) ; //判斷是和否存在前綴為prefix的鍵 //hasKeyWithPrefix("tha")->true //hasKeyWithPrefix("apple")->false publicbooleanhasKeyWithPrefix(Stringprefix); //通配符.匹配任意字符,搜索所有匹配的鍵 //keysWithPattern("t.a.")->["team","that"] publicListkeysWithPattern(Stringpattern) ; //通配符.匹配任意字符,判斷是否存在匹配的鍵 //hasKeyWithPattern(".ip")->true //hasKeyWithPattern(".i")->false publicbooleanhasKeyWithPattern(Stringpattern); //返回Map中鍵值對的數量 publicintsize(); }
至于TrieSet的 API 大同小異,所以這里不重復列舉,后文直接給出實現。
接下來是重頭戲,我們一個一個實現TrieMap的上述 API 函數。
首先,TrieMap類中一定需要記錄 Trie 的根節點root,以及 Trie 樹中的所有節點數量用于實現size()方法:
classTrieMap<V>{
//ASCII碼個數
privatestaticfinalintR=256;
//當前存在Map中的鍵值對個數
privateintsize=0;
privatestaticclassTrieNode<V>{
Vval=null;
TrieNode[]children=newTrieNode[R];
}
//Trie樹的根節點
privateTrieNoderoot=null;
/*其他API的實現...*/
publicintsize(){
returnsize;
}
}
另外,我們再實現一個工具函數getNode:
//從節點node開始搜索key,如果存在返回對應節點,否則返回null
privateTrieNodegetNode(TrieNodenode,Stringkey) {
TrieNodep=node;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
returnnull;
}
//向下搜索
charc=key.charAt(i);
p=p.children[c];
}
returnp;
}
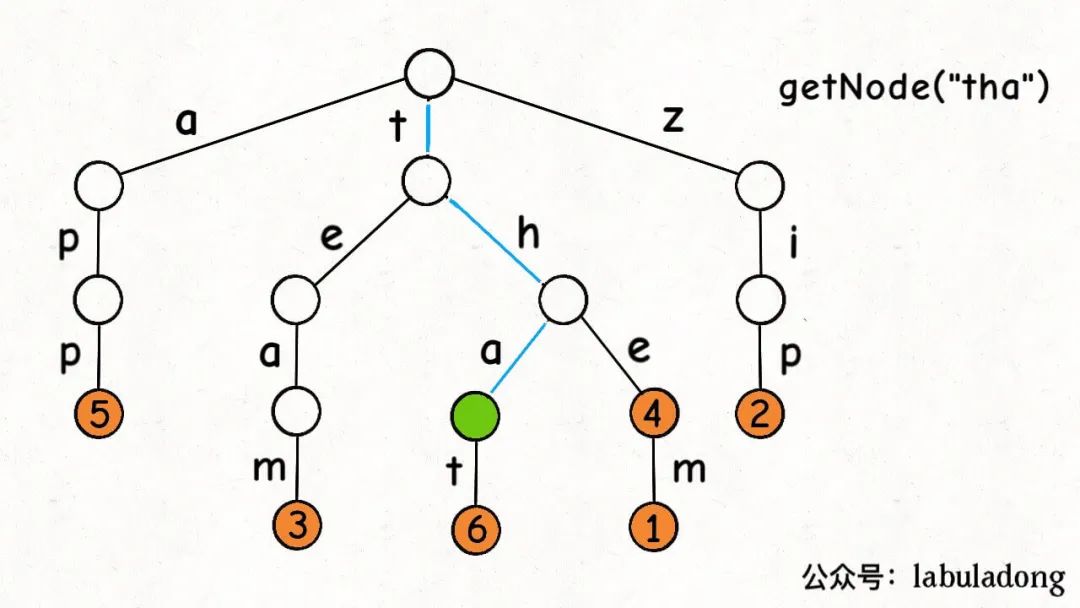
有了這個getNode函數,就能實現containsKey方法和get方法了:
//搜索key對應的值,不存在則返回null
publicVget(Stringkey){
//從root開始搜索key
TrieNodex=getNode(root,key);
if(x==null||x.val==null){
//x為空或x的val字段為空都說明key沒有對應的值
returnnull;
}
returnx.val;
}
//判斷key是否存在在Map中
publicbooleancontainsKey(Stringkey){
returnget(key)!=null;
}
這里需要注意,就算getNode(key)的返回值x非空,也只能說字符串key是一個「前綴」;除非x.val同時非空,才能判斷鍵key存在。
不過,這個特性恰好能夠幫我們實現hasKeyWithPrefix方法:
//判斷是和否存在前綴為prefix的鍵
publicbooleanhasKeyWithPrefix(Stringprefix){
//只要能找到 prefix 對應的節點,就是存在前綴
returngetNode(root,prefix)!=null;
}
類似getNode方法的邏輯,我們可以實現shortestPrefixOf方法,只要在第一次遇到存有val的節點的時候返回就行了:
//在所有鍵中尋找query的最短前綴
publicStringshortestPrefixOf(Stringquery){
TrieNodep=root;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
return"";
}
if(p.val!=null){
//找到一個鍵是query的前綴
returnquery.substring(0,i);
}
//向下搜索
charc=query.charAt(i);
p=p.children[c];
}
if(p!=null&&p.val!=null){
//如果query本身就是一個鍵
returnquery;
}
return"";
}
這里需要注意的是 for 循環結束之后我們還需要額外檢查一下。
因為之前說了 Trie 樹中「樹枝」存儲字符串,「節點」存儲字符串對應的值,for 循環相當于只遍歷了「樹枝」,但漏掉了最后一個「節點」,即query本身就是TrieMap中的一個鍵的情況。
如果你理解了shortestPrefixOf的實現,那么longestPrefixOf也是非常類似的:
//在所有鍵中尋找query的最長前綴
publicStringlongestPrefixOf(Stringquery){
TrieNodep=root;
//記錄前綴的最大長度
intmax_len=0;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
break;
}
if(p.val!=null){
//找到一個鍵是query的前綴,更新前綴的最大長度
max_len=i;
}
//向下搜索
charc=query.charAt(i);
p=p.children[c];
}
if(p!=null&&p.val!=null){
//如果query本身就是一個鍵
returnquery;
}
returnquery.substring(0,max_len);
}
每次遇到p.val非空的時候說明找到一個鍵,但是我們不急著返回,而是更新max_len變量,記錄最長前綴的長度。
同樣的,在 for 循環結束時還是要特殊判斷一下,處理query本身就是鍵的情況。
接下來,我們來實現keysWithPrefix方法,得到所有前綴為prefix的鍵。
看過前文手把手刷二叉樹(總結篇)的讀者應該可以想到,先利用getNode函數在 Trie 樹中找到prefix對應的節點x,然施展多叉樹的遍歷算法,遍歷以x為根的這棵 Trie 樹,找到所有鍵值對:
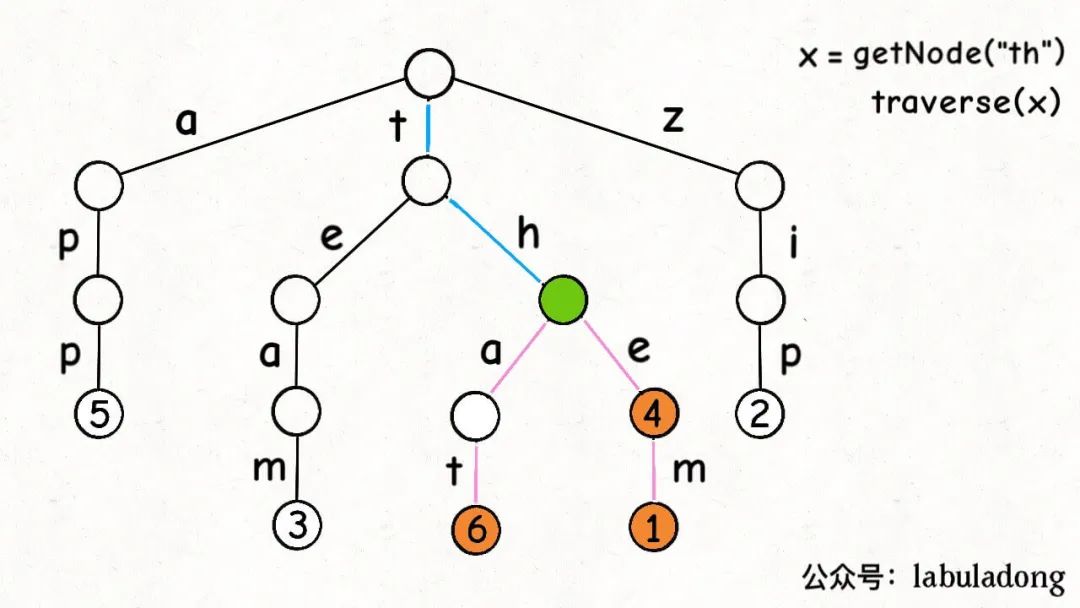
代碼實現如下:
//搜索前綴為prefix的所有鍵
publicListkeysWithPrefix(Stringprefix) {
Listres=newLinkedList<>();
//找到匹配prefix在Trie樹中的那個節點
TrieNodex=getNode(root,prefix);
if(x==null){
returnres;
}
//DFS遍歷以x為根的這棵Trie樹
traverse(x,newStringBuilder(prefix),res);
returnres;
}
//遍歷以node節點為根的Trie樹,找到所有鍵
privatevoidtraverse(TrieNodenode,StringBuilderpath,Listres) {
if(node==null){
//到達Trie樹底部葉子結點
return;
}
if(node.val!=null){
//找到一個key,添加到結果列表中
res.add(path.toString());
}
//回溯算法遍歷框架
for(charc=0;c//做選擇
path.append(c);
traverse(node.children[c],path,res);
//撤銷選擇
path.deleteCharAt(path.length()-1);
}
}
這段代碼中traverse函數你可能看起來特別熟悉,就是回溯算法核心套路中講的回溯算法代碼框架。
關于回溯算法框架和標準多叉樹框架的區別我在圖論算法基礎中探討過,關鍵在于遍歷「節點」和遍歷「樹枝」的區別。由于 Trie 樹將字符存儲在「樹枝」上,traverse函數是在遍歷樹枝上的字符,所以采用的是回溯算法框架。
另外,再注意一下這段邏輯:
//回溯算法遍歷框架
for(charc=0;c//做選擇
path.append(c);
traverse(node.children[c],path,res);
//撤銷選擇
path.deleteCharAt(path.length()-1);
}
回顧一下我們 Trie 樹的圖:
你是否會有疑問:代碼中 for 循環會執行 256 次,但是圖中的一個節點只有幾個子節點,也就是說每個節點的children數組中大部分都是空指針,這不會有問題嗎?
是不是應該把代碼改成這樣:
//回溯算法遍歷框架
for(charc=0;c//做選擇
path.append(c);
if(node.children[c]!=null){
traverse(node.children[c],path,res);
}
//撤銷選擇
path.deleteCharAt(path.length()-1);
}
答案是,改不改都行,這兩種寫法從邏輯上講完全相同,因為traverse函數開始的時候如果發現node == null也會直接返回。
我為了保持框架的一致性,就沒有在 for 循環中判斷子節點是否為空,而是依賴遞歸函數的 base case。當然你完全可以按照自己的喜好來實現。
下面來實現keysWithPattern方法,使用通配符來匹配多個鍵,其關鍵就在于通配符.可以匹配所有字符。
在代碼實現上,用path變量記錄匹配鍵的路徑,遇到通配符時使用類似回溯算法的框架就行了:
//通配符.匹配任意字符
publicListkeysWithPattern(Stringpattern) {
Listres=newLinkedList<>();
traverse(root,newStringBuilder(),pattern,0,res);
returnres;
}
//遍歷函數,嘗試在「以node為根的Trie樹中」匹配pattern[i..]
privatevoidtraverse(TrieNodenode,StringBuilderpath,Stringpattern,inti,Listres) {
if(node==null){
//樹枝不存在,即匹配失敗
return;
}
if(i==pattern.length()){
//pattern匹配完成
if(node.val!=null){
//如果這個節點存儲著val,則找到一個匹配的鍵
res.add(path.toString());
}
return;
}
charc=pattern.charAt(i);
if(c=='.'){
//pattern[i]是通配符,可以變化成任意字符
//多叉樹(回溯算法)遍歷框架
for(charj=0;j1,res);
path.deleteCharAt(path.length()-1);
}
}else{
//pattern[i]是普通字符c
path.append(c);
traverse(node.children[c],path,pattern,i+1,res);
path.deleteCharAt(path.length()-1);
}
}
下面這個 GIF 畫了匹配"t.a."的過程,應該就容易理解上述代碼的邏輯了:
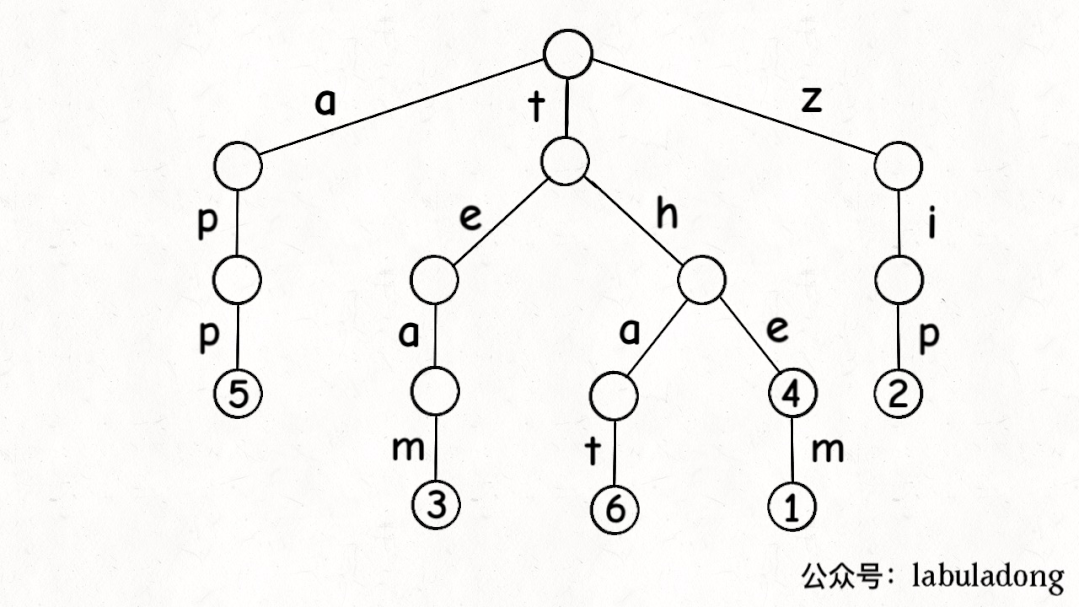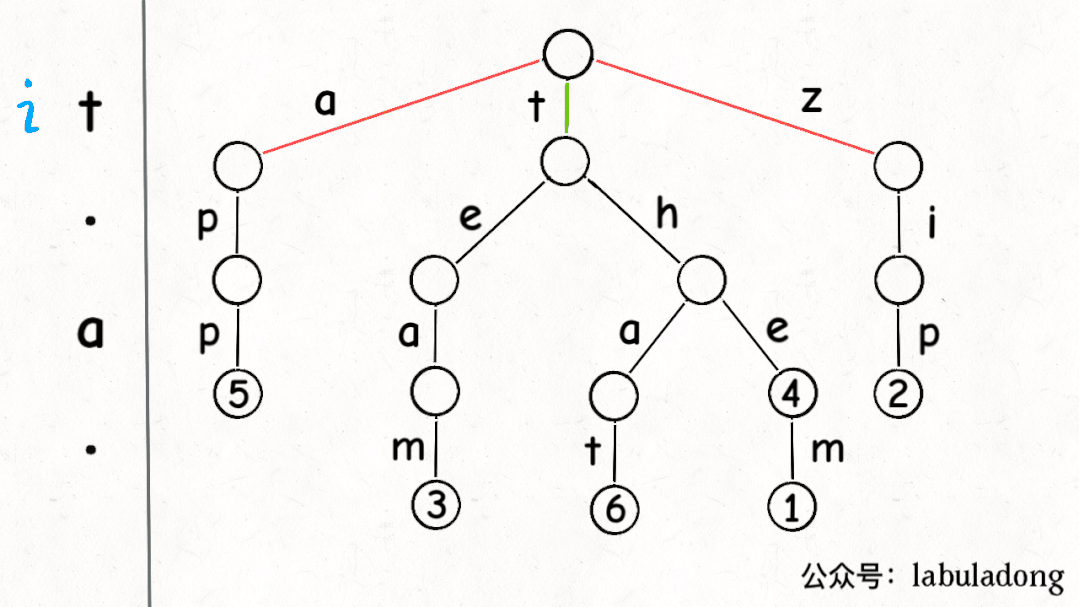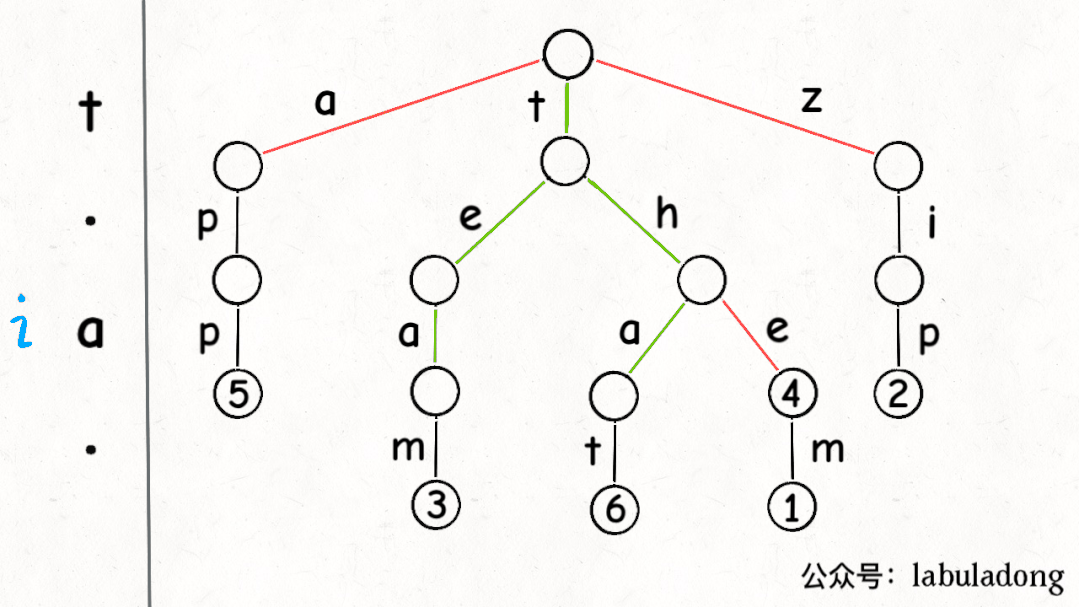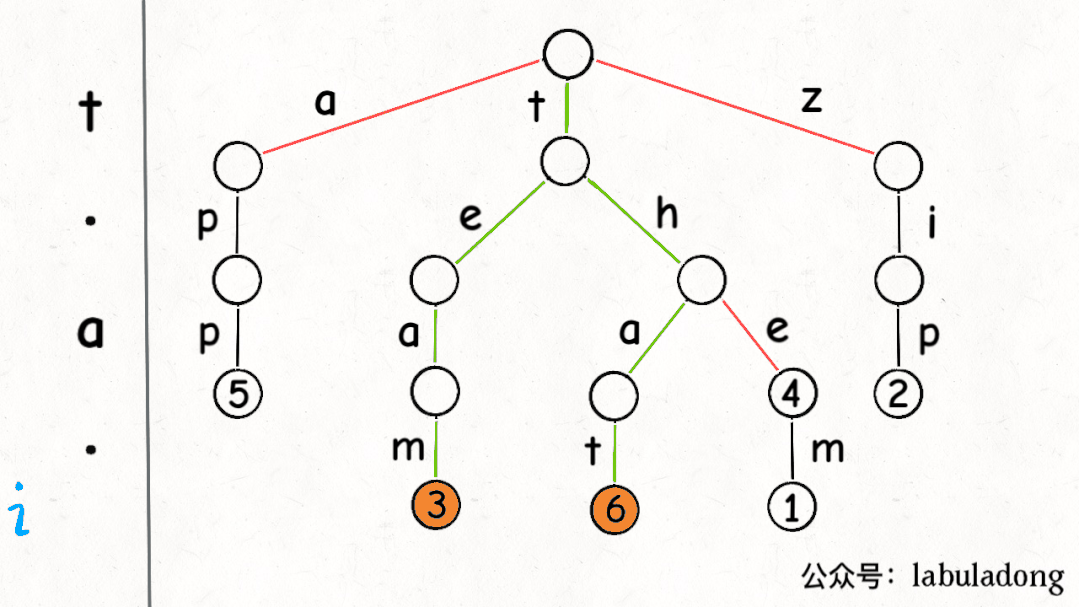
可以看到,keysWithPattern和keysWithPrefix的實現是有些類似的,而且這兩個函數還有一個潛在的特性:它們返回的結果列表一定是符合「字典序」的。
原因應該不難理解,每一個節點的children數組都是從左到右進行遍歷,即按照 ASCII 碼從小到大的順序遞歸遍歷,得到的結果自然是符合字典序的。
好,現在我們實現了keysWithPattern方法得到模式串匹配的所有鍵,那你是否可以實現hasKeyWithPattern方法,僅僅判斷是否存在鍵匹配模式串?
//一個偷懶的實現
publicbooleanhasKeyWithPattern(Stringpattern){
return!keysWithPattern(pattern).isEmpty();
}
這是一個偷懶的實現,因為它的復雜度比較高。我們的目的僅僅是判斷是否存在匹配模式串的鍵,你卻把所有匹配的鍵都算出來了,這顯然是沒有必要的。
我們只需稍微改寫一下keysWithPattern方法就可以高效實現hasKeyWithPattern方法:
//判斷是和否存在前綴為prefix的鍵
publicbooleanhasKeyWithPattern(Stringpattern){
//從root節點開始匹配pattern[0..]
returnhasKeyWithPattern(root,pattern,0);
}
//函數定義:從 node 節點開始匹配 pattern[i..],返回是否成功匹配
privatebooleanhasKeyWithPattern(TrieNodenode,Stringpattern,inti) {
if(node==null){
//樹枝不存在,即匹配失敗
returnfalse;
}
if(i==pattern.length()){
//模式串走到頭了,看看匹配到的是否是一個鍵
returnnode.val!=null;
}
charc=pattern.charAt(i);
//沒有遇到通配符
if(c!='.'){
//從node.children[c]節點開始匹配pattern[i+1..]
returnhasKeyWithPattern(node.children[c],pattern,i+1);
}
//遇到通配符
for(intj=0;j//pattern[i]可以變化成任意字符,嘗試所有可能,只要遇到一個匹配成功就返回
if(hasKeyWithPattern(node.children[j],pattern,i+1)){
returntrue;
}
}
//都沒有匹配
returnfalse;
}
有之前的鋪墊,這個實現應該是不難理解的,類似于回溯算法解數獨游戲中找到一個可行解就提前結束遞歸的做法。
到這里,TrieMap的所有和前綴相關的方法都實現完了,還剩下put和remove這兩個基本方法了,其實它們的難度不大,就是遞歸修改數據結構的那一套,如果不熟悉的話可以參見二叉搜索樹基本操作。
先說put方法的實現吧,直接看代碼:
//在map中添加或修改鍵值對
publicvoidput(Stringkey,Vval){
if(!containsKey(key)){
//新增鍵值對
size++;
}
//需要一個額外的輔助函數,并接收其返回值
root=put(root,key,val,0);
}
//定義:向以 node 為根的 Trie 樹中插入 key[i..],返回插入完成后的根節點
privateTrieNodeput(TrieNodenode,Stringkey,Vval,inti) {
if(node==null){
//如果樹枝不存在,新建
node=newTrieNode<>();
}
if(i==key.length()){
//key的路徑已插入完成,將值val存入節點
node.val=val;
returnnode;
}
charc=key.charAt(i);
//遞歸插入子節點,并接收返回值
node.children[c]=put(node.children[c],key,val,i+1);
returnnode;
}
因為是遞歸修改數據結構,所以我們必須額外創建一個返回類型為TrieNode的輔助函數,并且在遞歸調用的時候接收其返回值,拼接到父節點上。
前文說了,Trie 樹中的鍵就是「樹枝」,值就是「節點」,所以插入的邏輯就是沿路新建「樹枝」,把key的整條「樹枝」構建出來之后,在樹枝末端的「節點」中存儲val:
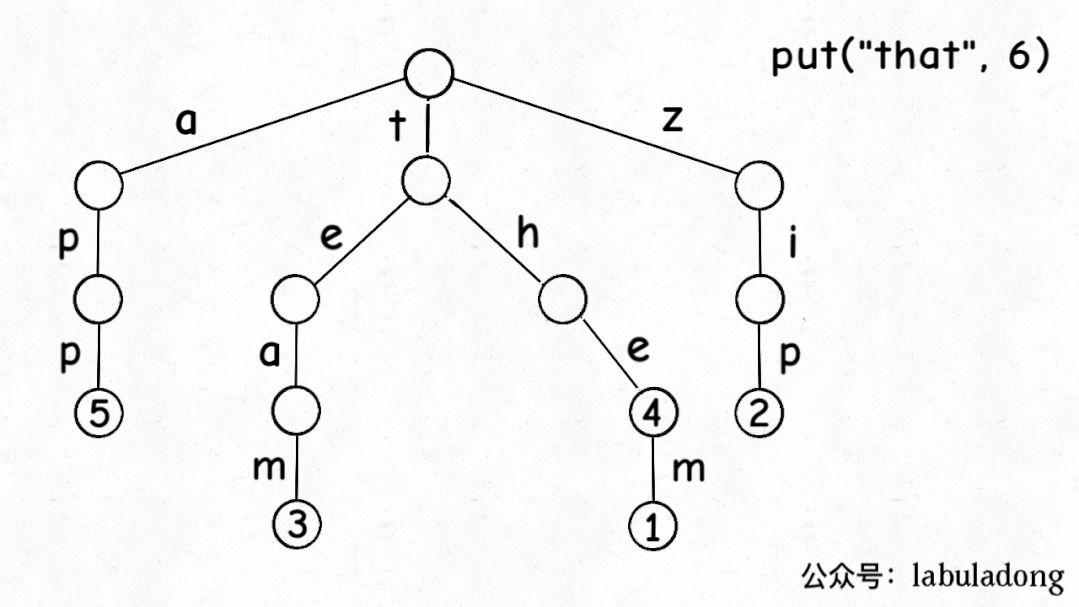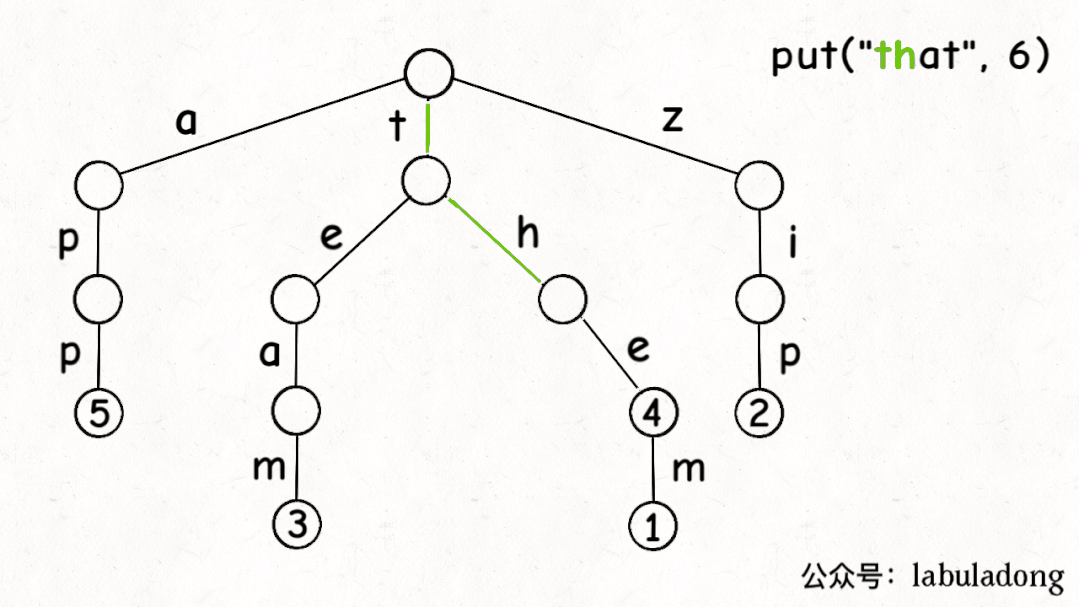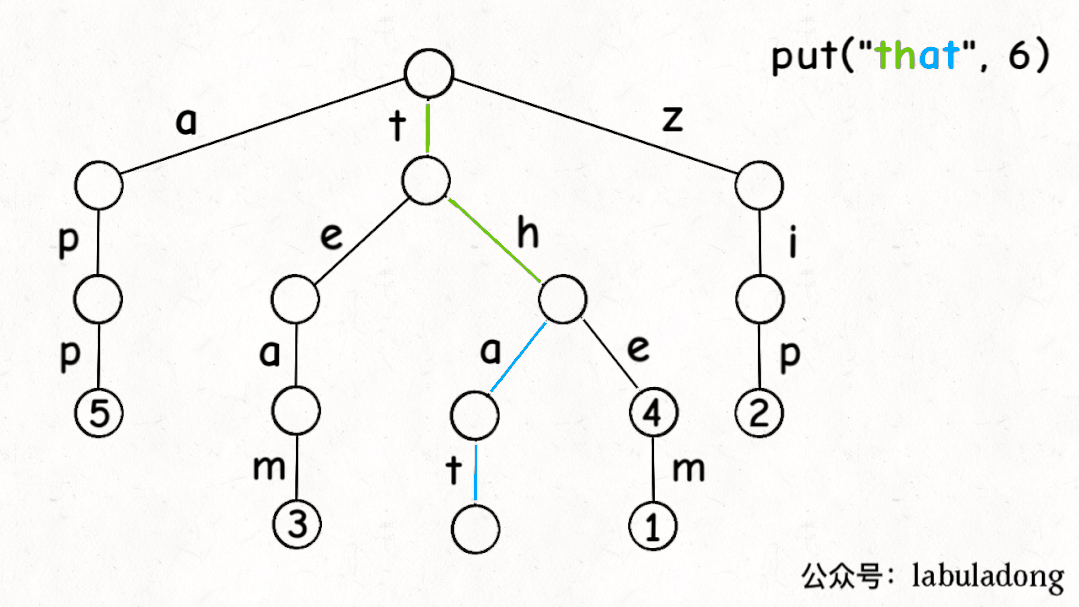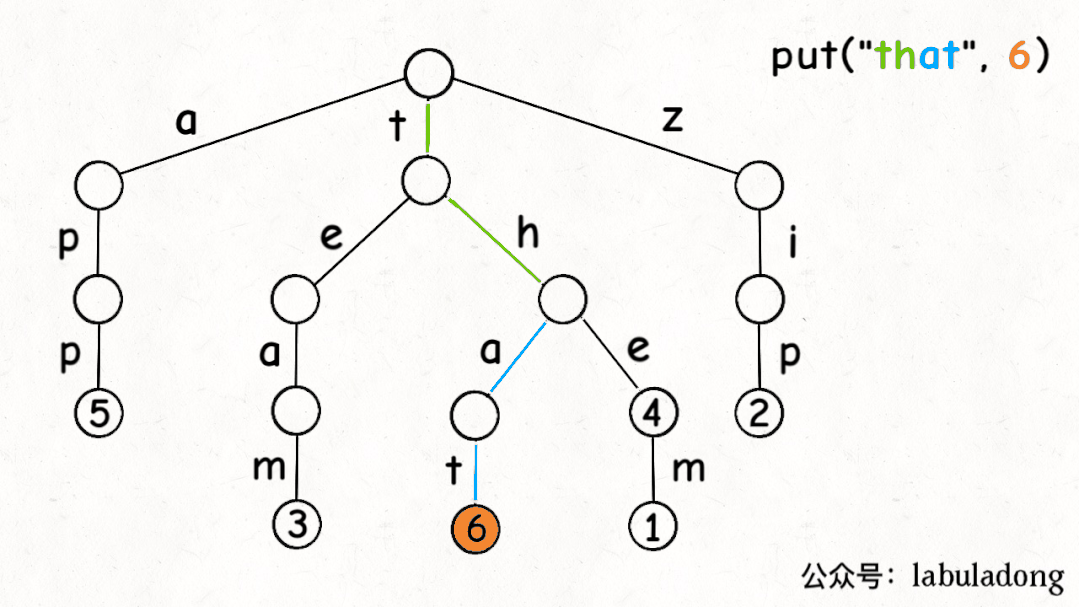
最后,我們說一下remove函數,似乎所有數據結構的刪除操作相對其他操作都會更復雜一些。
比如說下圖這個場景,如果你想刪除鍵"team",那么需要刪掉"eam"這條樹枝才是符合邏輯的:
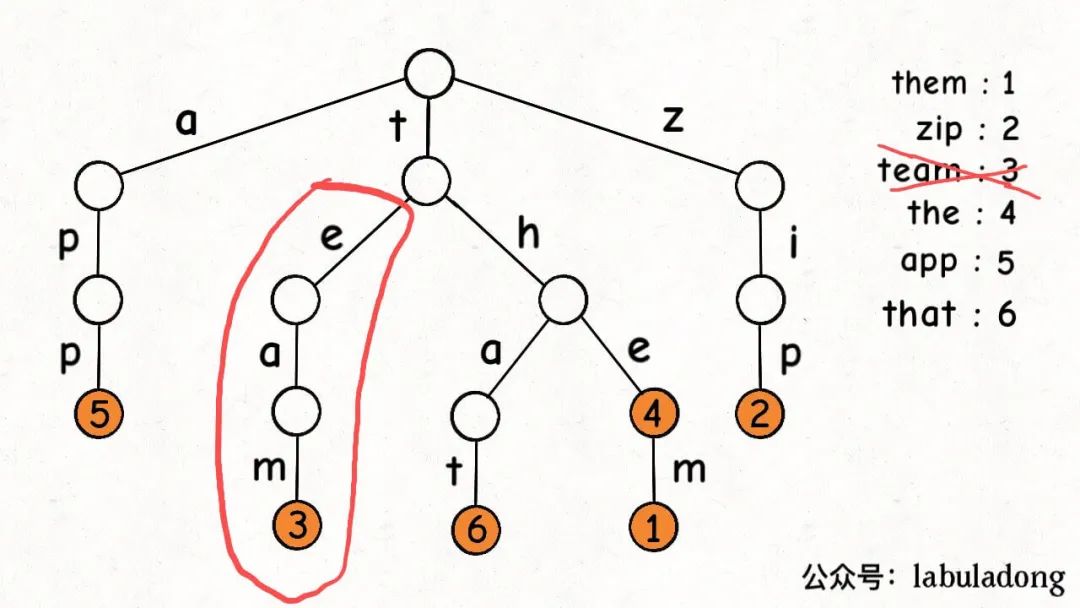
刪多了肯定不行,但刪少了也不行,否則前文實現的hasKeyWithPrefix就會出錯。
那么如何控制算法來正確地進行刪除呢?
首先,遞歸修改數據結構的時候,如果一個節點想刪掉自己,直接返回空指針就行了。
其次,一個節點如何知道自己是否需要被刪除呢?主要看自己的val字段是否為空以及自己的children數組是否全都是空指針。
這里就要利用前文手把手刷二叉樹(總結篇)中說到的后序位置的特點了:
一個節點要先遞歸處理子樹,然后在后序位置檢查自己的val字段和children列表,判斷自己是否需要被刪除。
如果自己的val字段為空,說明自己沒有存儲值,如果同時自己的children數組全是空指針,說明自己下面也沒有接樹枝,即不是任何一個鍵的前綴。這種情況下這個節點就沒有存在的意義了,應該刪掉自己。
直接看代碼:
//在Map中刪除key
publicvoidremove(Stringkey){
if(!containsKey(key)){
return;
}
//遞歸修改數據結構要接收函數的返回值
root=remove(root,key,0);
size--;
}
//定義:在以 node 為根的 Trie 樹中刪除 key[i..],返回刪除后的根節點
privateTrieNoderemove(TrieNodenode,Stringkey,inti) {
if(node==null){
returnnull;
}
if(i==key.length()){
//找到了key對應的TrieNode,刪除val
node.val=null;
}else{
charc=key.charAt(i);
//遞歸去子樹進行刪除
node.children[c]=remove(node.children[c],key,i+1);
}
//后序位置,遞歸路徑上的節點可能需要被清理
if(node.val!=null){
//如果該TireNode存儲著val,不需要被清理
returnnode;
}
//檢查該TrieNode是否還有后綴
for(intc=0;cif(node.children[c]!=null){
//只要存在一個子節點(后綴樹枝),就不需要被清理
returnnode;
}
}
//既沒有存儲val,也沒有后綴樹枝,則該節點需要被清理
returnnull;
}
到這里,TrieMap的所有 API 就實現完了,完整代碼如下:
classTrieMap<V>{
//ASCII碼個數
privatestaticfinalintR=256;
//當前存在Map中的鍵值對個數
privateintsize=0;
//Trie樹的根節點
privateTrieNoderoot=null;
privatestaticclassTrieNode<V>{
Vval=null;
TrieNode[]children=newTrieNode[R];
}
/*****增/改*****/
//在map中添加或修改鍵值對
publicvoidput(Stringkey,Vval){
if(!containsKey(key)){
//新增鍵值對
size++;
}
//需要一個額外的輔助函數,并接收其返回值
root=put(root,key,val,0);
}
//定義:向以 node 為根的 Trie 樹中插入 key[i..],返回插入完成后的根節點
privateTrieNodeput(TrieNodenode,Stringkey,Vval,inti) {
if(node==null){
//如果樹枝不存在,新建
node=newTrieNode<>();
}
if(i==key.length()){
//key的路徑已插入完成,將值val存入節點
node.val=val;
returnnode;
}
charc=key.charAt(i);
//遞歸插入子節點,并接收返回值
node.children[c]=put(node.children[c],key,val,i+1);
returnnode;
}
/*****刪*****/
//在Map中刪除key
publicvoidremove(Stringkey){
if(!containsKey(key)){
return;
}
//遞歸修改數據結構要接收函數的返回值
root=remove(root,key,0);
size--;
}
//定義:在以 node 為根的 Trie 樹中刪除 key[i..],返回刪除后的根節點
privateTrieNoderemove(TrieNodenode,Stringkey,inti) {
if(node==null){
returnnull;
}
if(i==key.length()){
//找到了key對應的TrieNode,刪除val
node.val=null;
}else{
charc=key.charAt(i);
//遞歸去子樹進行刪除
node.children[c]=remove(node.children[c],key,i+1);
}
//后序位置,遞歸路徑上的節點可能需要被清理
if(node.val!=null){
//如果該TireNode存儲著val,不需要被清理
returnnode;
}
//檢查該TrieNode是否還有后綴
for(intc=0;cif(node.children[c]!=null){
//只要存在一個子節點(后綴樹枝),就不需要被清理
returnnode;
}
}
//既沒有存儲val,也沒有后綴樹枝,則該節點需要被清理
returnnull;
}
/*****查*****/
//搜索key對應的值,不存在則返回null
publicVget(Stringkey){
//從root開始搜索key
TrieNodex=getNode(root,key);
if(x==null||x.val==null){
//x為空或x的val字段為空都說明key沒有對應的值
returnnull;
}
returnx.val;
}
//判斷key是否存在在Map中
publicbooleancontainsKey(Stringkey){
returnget(key)!=null;
}
//判斷是和否存在前綴為prefix的鍵
publicbooleanhasKeyWithPrefix(Stringprefix){
//只要能找到一個節點,就是存在前綴
returngetNode(root,prefix)!=null;
}
//在所有鍵中尋找query的最短前綴
publicStringshortestPrefixOf(Stringquery){
TrieNodep=root;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
return"";
}
if(p.val!=null){
//找到一個鍵是query的前綴
returnquery.substring(0,i);
}
//向下搜索
charc=query.charAt(i);
p=p.children[c];
}
if(p!=null&&p.val!=null){
//如果query本身就是一個鍵
returnquery;
}
return"";
}
//在所有鍵中尋找query的最長前綴
publicStringlongestPrefixOf(Stringquery){
TrieNodep=root;
//記錄前綴的最大長度
intmax_len=0;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
break;
}
if(p.val!=null){
//找到一個鍵是query的前綴,更新前綴的最大長度
max_len=i;
}
//向下搜索
charc=query.charAt(i);
p=p.children[c];
}
if(p!=null&&p.val!=null){
//如果query本身就是一個鍵
returnquery;
}
returnquery.substring(0,max_len);
}
//搜索前綴為prefix的所有鍵
publicListkeysWithPrefix(Stringprefix) {
Listres=newLinkedList<>();
//找到匹配prefix在Trie樹中的那個節點
TrieNodex=getNode(root,prefix);
if(x==null){
returnres;
}
//DFS遍歷以x為根的這棵Trie樹
traverse(x,newStringBuilder(prefix),res);
returnres;
}
//遍歷以node節點為根的Trie樹,找到所有鍵
privatevoidtraverse(TrieNodenode,StringBuilderpath,Listres) {
if(node==null){
//到達Trie樹底部葉子結點
return;
}
if(node.val!=null){
//找到一個key,添加到結果列表中
res.add(path.toString());
}
//回溯算法遍歷框架
for(charc=0;c//做選擇
path.append(c);
traverse(node.children[c],path,res);
//撤銷選擇
path.deleteCharAt(path.length()-1);
}
}
//通配符.匹配任意字符
publicListkeysWithPattern(Stringpattern) {
Listres=newLinkedList<>();
traverse(root,newStringBuilder(),pattern,0,res);
returnres;
}
//遍歷函數,嘗試在「以node為根的Trie樹中」匹配pattern[i..]
privatevoidtraverse(TrieNodenode,StringBuilderpath,Stringpattern,inti,Listres) {
if(node==null){
//樹枝不存在,即匹配失敗
return;
}
if(i==pattern.length()){
//pattern匹配完成
if(node.val!=null){
//如果這個節點存儲著val,則找到一個匹配的鍵
res.add(path.toString());
}
return;
}
charc=pattern.charAt(i);
if(c=='.'){
//pattern[i]是通配符,可以變化成任意字符
//多叉樹(回溯算法)遍歷框架
for(charj=0;j1,res);
path.deleteCharAt(path.length()-1);
}
}else{
//pattern[i]是普通字符c
path.append(c);
traverse(node.children[c],path,pattern,i+1,res);
path.deleteCharAt(path.length()-1);
}
}
//判斷是和否存在前綴為prefix的鍵
publicbooleanhasKeyWithPattern(Stringpattern){
//從root節點開始匹配pattern[0..]
returnhasKeyWithPattern(root,pattern,0);
}
//函數定義:從 node 節點開始匹配 pattern[i..],返回是否成功匹配
privatebooleanhasKeyWithPattern(TrieNodenode,Stringpattern,inti) {
if(node==null){
//樹枝不存在,即匹配失敗
returnfalse;
}
if(i==pattern.length()){
//模式串走到頭了,看看匹配到的是否是一個鍵
returnnode.val!=null;
}
charc=pattern.charAt(i);
//沒有遇到通配符
if(c!='.'){
//從node.children[c]節點開始匹配pattern[i+1..]
returnhasKeyWithPattern(node.children[c],pattern,i+1);
}
//遇到通配符
for(intj=0;j//pattern[i]可以變化成任意字符,嘗試所有可能,只要遇到一個匹配成功就返回
if(hasKeyWithPattern(node.children[j],pattern,i+1)){
returntrue;
}
}
//都沒有匹配
returnfalse;
}
//從節點node開始搜索key,如果存在返回對應節點,否則返回null
privateTrieNodegetNode(TrieNodenode,Stringkey) {
TrieNodep=node;
//從節點node開始搜索key
for(inti=0;iif(p==null){
//無法向下搜索
returnnull;
}
//向下搜索
charc=key.charAt(i);
p=p.children[c];
}
returnp;
}
publicintsize(){
returnsize;
}
}
接下來我們只要對TrieMap做簡單的封裝,即可實現TrieSet:
classTrieSet{
//底層用一個TrieMap,鍵就是TrieSet,值僅僅起到占位的作用
//值的類型可以隨便設置,我參考Java標準庫設置成Object
privatefinalTrieMap
有了TrieMap和TrieSet,力扣上所有前綴樹相關的題目都可以直接套用了,下面我舉幾個題目實踐一下。
秒殺題目
首先需要說明,上文實現的算法模板的執行效率在具體的題目里面肯定是有優化空間的。
比如力扣前綴樹相關題目的輸入都被限制在小寫英文字母a-z,所以TrieNode其實不用維護一個大小為 256 的children數組,大小設置為 26 就夠了,可以減小時間和空間上的復雜度。
不過本文只考慮模板的通用性,重在思路,所以就直接套用上文給出的算法模板解題,具體實現上的細節優化我集成在刷題插件的「思路」按鈕中。
先看下力扣第 208 題「實現前綴樹」:

題目讓我們實現的幾個函數其實就是TrieSet的部分 API,所以直接封裝一個TrieSet就能解決這道題了:
classTrie{
//直接封裝TrieSet
TrieSetset=newTrieSet();
//插入一個元素
publicvoidinsert(Stringword){
set.add(word);
}
//判斷元素是否在集合中
publicbooleansearch(Stringword){
returnset.contains(word);
}
//判斷集合中是否有前綴為prefix的元素
publicbooleanstartsWith(Stringprefix){
returnset.hasKeyWithPrefix(prefix);
}
}
classTrieSet{/*見上文*/}
classTrieMap{/*見上文*/}
接下來看下力扣第 648 題「單詞替換」:

現在你學過 Trie 樹結構,應該可以看出來這題就在考察最短前綴問題。
所以可以把輸入的詞根列表dict存入TrieSet,然后直接復用我們實現的shortestPrefixOf函數就行了:
StringreplaceWords(Listdict,Stringsentence) {
//先將詞根都存入TrieSet
TrieSetset=newTrieSet();
for(Stringkey:dict){
set.add(key);
}
StringBuildersb=newStringBuilder();
String[]words=sentence.split("");
//處理句子中的單詞
for(inti=0;i//在Trie樹中搜索最短詞根(最短前綴)
Stringprefix=set.shortestPrefixOf(words[i]);
if(!prefix.isEmpty()){
//如果搜索到了,改寫為詞根
sb.append(prefix);
}else{
//否則,原樣放回
sb.append(words[i]);
}
if(i!=words.length-1){
//添加單詞之間的空格
sb.append('');
}
}
returnsb.toString();
}
classTrieSet{/*見上文*/}
classTrieMap{/*見上文*/}
繼續看力扣第 211 題「添加與搜索單詞 - 數據結構設計」:
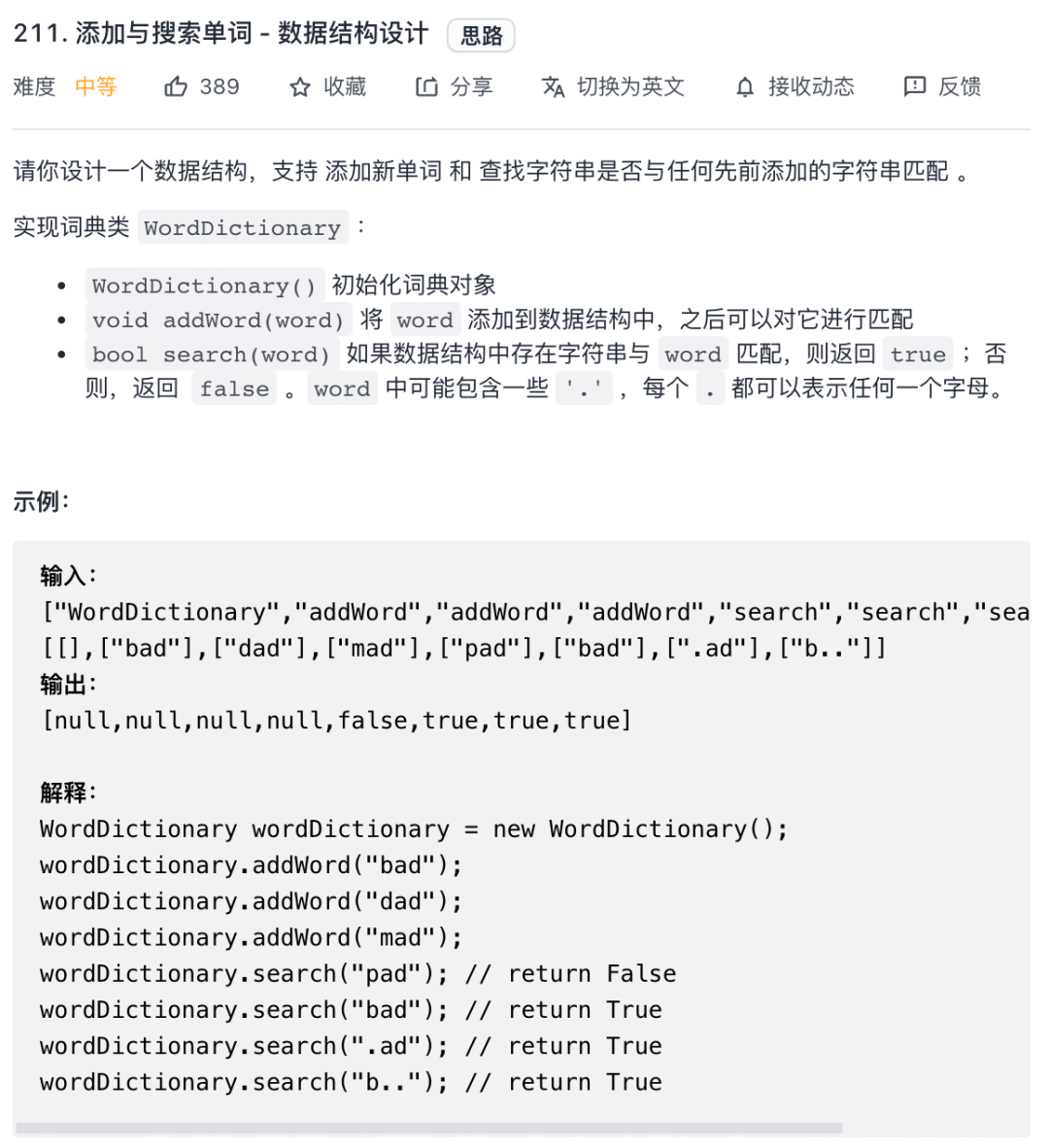
這道題的考點就在于這個search函數進行通配符匹配,其實就是我們給TrieSet實現的hasKeyWithPattern方法,直接套就行了:
classWordDictionary{
TrieSetset=newTrieSet();
//在TrieSet中添加元素
publicvoidaddWord(Stringword){
set.add(word);
}
//通配符匹配元素
publicbooleansearch(Stringword){
returnset.hasKeyWithPattern(word);
}
}
classTrieSet{/*見上文*/}
classTrieMap{/*見上文*/}
上面列舉的這幾道題用的都是TrieSet,下面來看看TrieMap的題目。
先看力扣第 1804 題「實現前綴樹 II」:

這題就可以用到TrieMap,每個插入的word就是鍵,插入的次數就是對應的值,然后復用TrieMap的 API 就能實現題目要求的這些函數:
classTrie{
//封裝我們實現的TrieMap
TrieMapmap=newTrieMap<>();
//插入word并記錄插入次數
publicvoidinsert(Stringword){
if(!map.containsKey(word)){
map.put(word,1);
}else{
map.put(word,map.get(word)+1);
}
}
//查詢word插入的次數
publicintcountWordsEqualTo(Stringword){
if(!map.containsKey(word)){
return0;
}
returnmap.get(word);
}
//累加前綴為prefix的鍵的插入次數總和
publicintcountWordsStartingWith(Stringprefix){
intres=0;
for(Stringkey:map.keysWithPrefix(prefix)){
res+=map.get(key);
}
returnres;
}
//word的插入次數減一
publicvoiderase(Stringword){
intfreq=map.get(word);
if(freq-1==0){
map.remove(word);
}else{
map.put(word,freq-1);
}
}
}
classTrieMap{/*見上文*/}
反正都是直接套模板,也沒什么意思,再看最后一道題目吧,這是力扣第 677 題「鍵值映射」:

這道題還是標準的TrieMap的應用,直接看代碼吧:
classMapSum{
//封裝我們實現的TrieMap
TrieMapmap=newTrieMap<>();
//插入鍵值對
publicvoidinsert(Stringkey,intval){
map.put(key,val);
}
//累加所有前綴為prefix的鍵的值
publicintsum(Stringprefix){
Listkeys=map.keysWithPrefix(prefix);
intres=0;
for(Stringkey:keys){
res+=map.get(key);
}
returnres;
}
}
classTrieMap{/*見上文*/}
Trie 樹這種數據結構的實現原理和題目實踐就講完了,如果你能夠看到這里,真得給你鼓掌。
可以看到,我最近寫的圖論算法以及本文講的 Trie 樹算法,都和「樹」這種基本數據結構相關,所以我才會在刷題插件中集成手把手刷 100 道二叉樹題目的功能。
最后,紙上得來終覺淺,絕知此事要躬行,我建議最好親手實現一遍上面的代碼,去把題目刷一遍,才能對 Trie 樹有更深入的理解。
之后我準備繼續講解一些基本數據結構在高級數據結構或實際算法題中的應用,大家期待就好。
原文標題:前綴樹算法模板秒殺 5 道算法題
文章出處:【微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
-
算法
+關注
關注
23文章
4790瀏覽量
98427 -
代碼
+關注
關注
30文章
4974瀏覽量
74296 -
數據結構
+關注
關注
3文章
573瀏覽量
41667
原文標題:前綴樹算法模板秒殺 5 道算法題
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPIB命令的數據結構
收藏 | 程序員面試,你必須知道的8大數據結構
常見的數據結構
GPIB命令的數據結構
GPIB命令的數據結構
什么是數據結構?為什么要學習數據結構?數據結構的應用實例分析
Linux 內核里的數據結構關鍵:基數樹
Linux內核數據結構:Radix 樹
新數據結構“樹”的詳細介紹



 工商網監
工商網監
評論