 用NVIDIA Riva和Rasa創建基于語音的虛擬應用程序
用NVIDIA Riva和Rasa創建基于語音的虛擬應用程序

虛擬助理已經成為我們日常生活的一部分。我們問虛擬助理幾乎任何我們想知道的事情。除了為我們的日常生活提供便利之外,虛擬助手在企業應用程序方面也有巨大的幫助。例如,我們使用在線虛擬代理來幫助解決復雜的技術問題、提交保險索賠或預訂酒店。我們還使用全自動呼叫來幫助擴展客戶關系管理。所有這些應用程序都要求企業部署一個生產級、健壯、基于語音的虛擬助手,以擴展到數億最終用戶。
由于其自然性,語音界面已成為促進高質量人機界面的關鍵因素。然而,對于許多開發人員來說,基于語音的虛擬助理仍然是一個重大的技術挑戰,尤其是在大規模部署時。
要成功部署基于語音的生產級虛擬助手,必須確保完全支持以下方面:
高質量– 質量與最終用戶體驗直接相關。確保語音界面能夠理解各種語言、方言和行話,并以準確、可靠的方式進行。此外,一個典型的智能對話可以進行多次輪換,并且具有高度的上下文關聯性。虛擬助理必須能夠瀏覽對話的復雜動態,并能夠識別正確的意圖、領域或上下文,以推動對話取得成功。
高性能和可擴展性– 除了嚴格的質量要求外,虛擬助理還必須能夠幾乎實時地給出準確的答案。額外的 200 毫秒延遲可能會導致任何人感知到延遲并妨礙最終用戶體驗。當虛擬助手部署到數億并發用戶的規模時,作為性能權衡的一部分,延遲往往會增加。在很大程度上控制延遲是另一個工程挑戰。
這篇文章的目的是讓您了解兩個生產級、企業級、虛擬助手解決方案: NVIDIA Riva 和 Rasa 的示例應用程序。我們展示了您可以輕松構建第一個基于語音的虛擬應用程序,這些應用程序可以部署和擴展。此外,我們還演示了 Riva 的性能,以展示其生產級功能。
虛擬助手系統包括以下組件:
對話管理( DM )
自動語音識別( ASR )
自然語言處理( NLP )或自然語言理解( NLU )
文本到語音( TTS )
NLU 和 DM 組件來自 Rasa ,而 Riva 提供 TTS 和 ASR 功能。
Rasa 概述
Rasa 是一個開源的機器學習框架,用于構建基于文本和語音的 AI 助手。在最基本的層面上,助理必須能夠做兩件事:
理解用戶在說什么。
作出相應的反應。
Rasa 助理使用機器學習來完成這兩項任務。 Rasa 允許您構建健壯的助手,從真實用戶對話中學習,以大規模處理關鍵任務。
對于此虛擬助手,您可以使用 Rasa NLU 和 DM 功能。有關更多信息,請參閱 Rasa documentation 。
Riva 概述
Riva 是用于構建會話式 AI 應用的英偉達 AI 語音 SDK 。 Riva 提供 ASR 和 TTS 功能,您可以使用這些功能來向虛擬助手提供語音接口。 Riva SDK 在 NVIDIA GPU 上運行,在高吞吐量水平下提供最快的推斷時間。
對于這個虛擬助手, ASR 解決方案必須具有低延遲和高精度,同時能夠支持高吞吐量。 TTS 必須具有低延遲和支持自定義語音字體。 Riva 提供了這兩種字體,非常適合構建基于語音的虛擬助手。有關 Riva 性能的更多信息,請參閱 NVIDIA Riva Speech Skills 。
架構概述
以下是四個組件如何交互以創建基于語音的虛擬助手。圖 1 顯示了虛擬助手的體系結構。
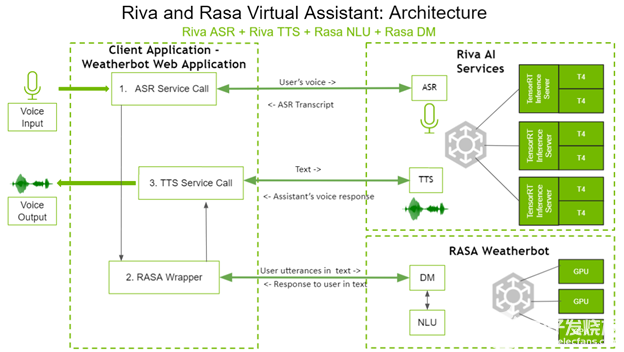
圖 1 。 Riva 和具有 Rasa NLU 體系結構的 Rasa 虛擬助手。
在左側,客戶端應用程序是 weatherbot web 應用程序。用戶通過語音直接與客戶端應用程序交互,并通過揚聲器接收答案。
用戶所說的問題通過調用 Riva ASR 服務進行轉錄。這個轉錄的文本將被發送到 Rasa 包裝器,該包裝器反過來對 Rasa DM 和 Rasa NLU 進行 API 調用,以決定適當的下一個操作。根據選擇的下一個操作, Rasa DM 還可以在需要時處理實現。 Rasa 服務器的文本響應通過 gRPC 調用發送到 Riva TTS 服務器, gRPC 調用將相應的音頻返回給用戶。
如您所見, Riva AI 服務和 Rasa 都部署在具有 GPU 的系統上,以獲得更好的性能。
構建虛擬助手
在這篇文章中,我們將引導您完成為天氣領域構建虛擬助手的過程。本文的重點不是用 Rasa NLU 和 DM 構建聊天機器人,而是展示 Rasa NLU 和 Rasa DM 與 Riva ASR 和 TTS 的集成,以構建基于語音的虛擬助手。
虛擬助手需要一個用戶界面,因此您可以使用 Python 的 Flask 框架創建一個簡單的網站。
有關此解決方案的更多信息以及代碼,請參閱 Riva documentation 中的 Virtual Assistant (with Rasa) section 。
先決條件
要使虛擬助手正常工作,必須啟動并運行 Riva 服務器。要使 Riva AI 服務啟動、運行并可通過 gRPC 端點訪問,請遵循 Riva Quick Start Guide 中的說明。
將 Riva ASR 集成到 Rasa assistant 中
在本節中,將 Riva ASR 與 Rasa 助手集成,如 ASR 。 py 文件中所示。
Riva ASR 可在流式或批處理模式下使用。在流模式下,捕獲并識別連續的音頻流,生成轉錄文本流。在批處理模式下,設置長度的音頻剪輯被轉錄為文本。對于這個用例,在流模式下使用 Riva ASR 。
代碼概述
import grpc import riva.modules.client.src.riva_proto.audio_pb2 as ri import riva.modules.client.src.riva_proto.riva_asr_pb2 as risr import riva.modules.client.src.riva_proto.riva_asr_pb2_grpc as risr_srv
首先導入必要的 Riva 客戶端依賴項:
class ASRPipe(object): def __init__(self): . . . . self.chunk = int(self.sampling_rate / 10) # 100ms self._buff = queue.Queue() self._transcript = queue.Queue() self.closed = False
創建ASRPipe類來處理 Riva ASR 操作。在__init__方法中,分別為音頻流和轉錄文本流創建_buff和_transcript隊列。
def start(self): . . . . self.channel = grpc.insecure_channel(riva_config["RIVA_SPEECH_API_URL"]) self.asr_client = risr_srv.RivaSpeechRecognitionStub(self.channel)
調用start函數以建立到 Riva 服務器的 gRPC 通道。
def fill_buffer(self, in_data): """Continuously collect data from the audio stream, into the buffer.""" self._buff.put(in_data)
虛擬助手中的 ASR 是一個后臺過程,因為您始終需要網站收聽用戶音頻。通過調用fill_buffer函數,音頻流中的音頻將連續添加到音頻緩沖區_buff。
def main_asr(self): . . . . config = risr.RecognitionConfig( encoding=ri.AudioEncoding.LINEAR_PCM, sample_rate_hertz=self.sampling_rate, language_code=self.language_code, max_alternatives=1, enable_automatic_punctuation=self.enable_automatic_punctuation ) streaming_config = risr.StreamingRecognitionConfig( config=config, interim_results=self.stream_interim_results) if self.verbose: print("[Riva ASR] Starting Background ASR process") self.request_generator = self.build_request_generator() requests = (risr.StreamingRecognizeRequest(audio_content=content) for content in self.request_generator) def build_generator(cfg, gen): yield risr.StreamingRecognizeRequest(streaming_config=cfg) for x in gen: yield x yield cfg if self.verbose: print("[Riva ASR] StreamingRecognize Start") responses = self.asr_client.StreamingRecognize(build_generator( streaming_config, requests)) # Now, put the transcription responses to use. self.listen_print_loop(responses)
獲得音頻后,使用main_asr函數生成轉錄本。
在main_asr函數中,設置 Riva ASR 調用所需的配置參數,如語言、通道數、音頻編碼、采樣率等。main_asr函數隨后定義了build_generator函數:一個生成器,用于使用音頻剪輯和 ASR 配置迭代調用 Riva ASRStreamingRecognizeRequest函數。最后,main_asr調用 Riva ASRStreamingRecognize函數。該函數返回一個文本轉錄本流,其中包含指示中間和最終轉錄本的標志,然后返回給調用方。
將 Riva TTS 集成到 Rasa 助手中
在本節中,您將 Riva TTS 與 Rasa 助手集成,如 tts.py 和 tts_stream.py 文件中所示。
與 ASR 一樣, TTS 也可以在流式或批處理模式下使用。使用 tts.py 中的批處理模式,可以將文本作為輸入并生成音頻剪輯。使用 tts_stream.py 中的流模式,可以將文本作為輸入并生成音頻流。
代碼概述
import grpc import riva.modules.client.src.riva_proto.audio_pb2 as ri import riva.modules.client.src.riva_proto.riva_tts_pb2 as rtts import riva.modules.client.src.riva_proto.riva_tts_pb2_grpc as rtts_srv from riva.tts.tts_processing.main_pronunciation import RunPronunciation
首先導入必要的 Riva 客戶端依賴項。
class TTSPipe(object): def __init__(self): . . . . self._buff = queue.Queue() self._flusher = bytes(np.zeros(dtype=np.int16, shape=(self.sample_rate, 1))) # Silence audio self.pronounce = RunPronunciation(pronounce_dict_path)
創建TTSPipe類來處理 Riva TTS 操作。在__init__方法中,創建_buff隊列以保存輸入文本。
def start(self): . . . . self.channel = grpc.insecure_channel( riva_config["Riva_SPEECH_API_URL"]) self.tts_client = rtts_srv.RivaSpeechSynthesisStub(self.channel)
調用start函數以建立到 Riva 服務器的 gRPC 通道。
def fill_buffer(self, in_data): """To collect text responses and fill TTS buffer.""" if len(in_data): self._buff.put(in_data)
要轉換為音頻的文本通過調用fill_buffer方法添加到緩沖區_buff。
def get_speech(self): . . . . while not self.closed: if not self._buff.empty(): # Enter if queue/buffer is not empty. try: text = self._buff.get(block=False, timeout=0) req = rtts.SynthesizeSpeechRequest() req.text = self.pronounce.get_text(text) req.language_code = self.language_code req.encoding = self.audio_encoding req.sample_rate_hz = self.sample_rate req.voice_name = self.voice_name duration = 0 self.current_tts_duration = 0 responses = self.tts_client.SynthesizeOnline(req) for resp in responses: datalen = len(resp.audio) // 4 data32 = np.ndarray(buffer=resp.audio, dtype=np.float32, shape=(datalen, 1)) data16 = np.int16(data32 * 23173.26) speech = bytes(data16.data) duration += len(data16)*2/(self.sample_rate*1*16/8) self.current_tts_duration += duration yield speech except Exception as e: print('[Riva TTS] ERROR:', e) . . . .
get_speech方法用于執行 TTS 。
在get_speech方法中,設置 Riva TTS 調用所需的配置參數,如語言、音頻編碼、采樣率和語音名稱。然后get_speech方法調用 Riva TTSSynthesizeOnline方法,將文本作為輸入,并返回生成的音頻流。循環此響應并以可配置的持續時間產生音頻輸出塊,從而產生流式音頻輸出。
把它們放在一起
現在,您將使用rasa.py文件調用 NLU 和 DM 的 Rasa 服務器。
class RASAPipe(object): def __init__(self, user_conversation_index): . . . . self.user_conversation_index = user_conversation_index
創建RASAPipe類以處理對 NLU 和 DM 的 Rasa 服務器的所有調用。
def request_rasa_for_question(self, message): rasa_requestdata = {"message": message, "sender": self.user_conversation_index} x = requests.post(self.messages_url, json = rasa_requestdata) rasa_response = x.json() processed_rasa_response = self.process_rasa_response(rasa_response) return processed_rasa_response
此類的主要函數是request_rasa_for_question方法,它將用戶輸入作為文本,使用此文本和公開的 Rasa API 上的發送方 ID 調用 Rasa ,從 Rasa 獲取響應,然后將此響應返回給調用方。
接下來,創建推斷管道,如chatbot.py文件所述。
class ChatBot(object): def __init__(self, user_conversation_index, verbose=False): self.id = user_conversation_index self.asr = ASRPipe() self.rasa = RASAPipe(user_conversation_index) self.tts = TTSPipe() self.thread_asr = None self.pause_asr_flag = False self.enableTTS = False
在chatbot.py中,有ChatBot類。每個會話有一個ChatBot實例,負責處理該會話的所有 ASR 、 TTS 和 Rasa 操作。創建ChatBot類的實例時,您將在其初始化期間創建 ASR 、 Rasa 和 TTS 類的實例。
def server_asr(self): self.asr.main_asr() def start_asr(self, sio): self.thread_asr = sio.start_background_task(self.server_asr)
首先調用start_asr方法,該方法負責在單獨的專用線程中作為后臺進程啟動 ASR 操作。
def asr_fill_buffer(self, audio_in): if not self.pause_asr_flag: self.asr.fill_buffer(audio_in) def get_asr_transcript(self): return self.asr.get_transcript()
然后,asr_fill_buffer函數調用 ASRPipe 實例fill_buffer函數,將來自用戶的輸入音頻流添加到 ASR 緩沖區。當 Riva ASR 開始將轉錄文本流式傳輸回來時,get_asr_transcript函數被調用,將轉錄文本返回給調用者。
def rasa_tts_pipeline(self, text): response_text = self.rasa.request_rasa_for_question(text) if len(response_text) and self.enableTTS == True: self.tts_fill_buffer(response_text) return response_text
對于轉錄的文本,調用rasa_tts_pipeline方法,負責管道化 Rasa 和 Riva TTS 功能。該方法首先調用 R ASAP ipe 實例request_rasa_for_question方法。這會將用戶輸入文本發送到 Rasa ,其中 Rasa NLP 和 Rasa DM 確定適當的操作并以文本消息的形式返回回復。然后將此文本消息傳遞給tts_fill_buffer并返回給調用者。
def tts_fill_buffer(self, response_text): if self.enableTTS: self.tts.fill_buffer(response_text) def get_tts_speech(self): return self.tts.get_speech()
前面調用的tts_fill_buffer依次調用 TTSPipe 實例fill_buffer方法,用輸入文本填充 TTS 緩沖區。當 TTS 準備好音頻流時,調用get_tts_speech方法,并將此音頻流回到調用者。
如您所見,您已經將 Rasa 和 TTS 功能管道化為一個簡單的方法rasa_tts_pipeline。
啟動虛擬助手
在啟動 virtual assistant 服務器之前,必須按照 Network Configuration 部分中的說明正確配置 API 端點。
要啟動基于語音的虛擬助手,請按照 Running the Demo 部分中的說明操作。
在執行上述步驟的同時,初始化 Rasa 操作服務器和 Rasa 服務器的各個容器。這一過程漫長而繁瑣。有關更簡單方法的更多信息,請參閱 Rasa 的 Docker Compose Installation 。
提高準確性
您可以通過兩個關鍵方法提高上述基于語音的虛擬助手的準確性。
Rasa 對話驅動開發和 Rasa X
對話驅動開發( CDD )是傾聽用戶意見并利用這些見解改進 AI 助手的過程。開發優秀的人工智能助手是一項挑戰,因為用戶會說出你無法預料的事情。然而,機會在于,在每次對話中,用戶都會準確地告訴你他們想要什么。通過在對話 AI 開發的每個階段練習 CDD ,您可以讓您的助手從真實的用戶語言和行為中學習。
Rasa X 是一種實踐 CDD 的工具。以下是使用 Rasa X 的 CDD 中的每個步驟:
共有:盡早將原型交給用戶進行測試。除了與外部通道連接外,您還可以通過從 Rasa X 向用戶發送鏈接來與他們共享您的原型。這會讓您的助手盡快掌握在測試用戶手中,甚至在您將其連接到外部通道之前。
回顧:花時間通讀人們與助手的對話。它在項目的每個階段都很有用,從原型到生產。所有來自 Rasa X 內部和您連接的任何頻道的對話都會顯示在您的對話屏幕中。
注釋:根據真實對話中的消息改進 NLU 模型。每當您收到新消息時,側欄中的徽章表示您有新數據要處理。您可以將消息標記為正確,修復錯誤的響應,并添加反映真實用戶對助手所說內容的數據。
測驗:專業團隊不會在未經測試的情況下發布應用程序。您可以將真實對話保存為 RASAX 中的測試,以便成功的對話可以立即成為測試。將 Rasa X 部署到服務器后,設置一個持續集成( CI )管道以自動化測試。 Rasa X 中的集成版本控制可以觸發 CI 管道中的測試,該管道在您推送更改時自動運行。
軌道:識別成功和不成功的對話,以衡量助理的表現。要使此過程自動化,請使用 RASAXAPI 根據您的用例自動標記某些操作。例如,標記指示器,例如用戶注冊您的服務或請求路由到人工代理。
修理:按照每個步驟進行操作,您可以看到助手的表現如何,以及在哪里出錯,這樣您就可以修復這些錯誤,并隨著時間的推移不斷改進助手。
CDD 不是一個線性過程。你會發現自己在每一個動作之間來回跳躍。這是一個產品、設計和開發之間的協作過程,揭示了用戶的需求。隨著時間的推移,它可以確保您的助手適應用戶的需求,而不是期望用戶調整他們的行為,這樣助手就不會崩潰。有關更多信息,請參閱 Rasa X Installation Guide 。
因維迪亞陶工具包
在許多情況下,您必須針對特定用例培訓、調整和優化模型。定制模型的最重要的方法是提高準確性,它是在預訓練的 Riva 模型中使用自定義數據和英偉達 TAO 工具包進行傳輸學習。
NVIDIA TAO Toolkit 是一個人工智能模型自適應框架,使您能夠使用自定義數據微調預訓練模型,而無需大型訓練數據集或深入的人工智能專業知識。 TAO 工具包支持對話 AI 管道所需的各種模型,從語音識別和自然語言理解到文本到語音。
TAO 工具包最重要的區別在于,它借助預定義的 Python 腳本抽象出 AI / DL 框架的復雜性。用戶在專用的預制 Docker 容器中執行所有操作。腳本以清晰的層次結構組織,遵循與支持的模型相關聯的域和特定于域的任務。對于每個模型,工具箱組織用戶應該遵循的操作順序,從數據準備、培訓和模型微調到導出進行推理。
結論
在本文中,您構建了一個基于語音的虛擬助手,并了解了如何將 Riva ASR 和 TTS 與 Rasa NLP 和 DM 集成。
關于作者
Nikhil Srihari 是 NVIDIA 的深入學習軟件技術營銷工程師。他在自然語言處理、計算機視覺和語音處理領域擁有廣泛的深度學習和機器學習應用經驗。 Nikhil 曾在富達投資公司和 Amazon 工作。他的教育背景包括布法羅大學的計算機科學碩士學位和印度蘇拉斯卡爾卡納塔克邦國家理工學院的學士學位。
Mady Mantha 是 Rasa 的高級技術傳道者。馬迪在喬治敦大學學習計算機科學、物理學和國際政治。她在智庫、初創公司和企業中擁有多年構建 ML 驅動產品的經驗。瑪迪是個太空愛好者。
Alex Qi 是英偉達 AI 軟件集團的產品經理。她的重點是對話 AI 框架( Riva )和多媒體流 AI / ML ( Maxine )的 AI 軟件和應用程序。在加入 NVIDIA 之前,她在領導技術和工程組織中各種角色的具有挑戰性的技術項目方面擁有豐富的經驗,如數據科學家、計算建模和設計工程。 Alex 擁有麻省理工學院的雙學位碩士學位:麻省理工學院斯隆管理學院的 MBA 學位,以及工程機械工程學院的理學碩士學位,她在該學院主要研究機器人技術和人工智能。
審核編輯:郭婷
-
AI
+關注
關注
91文章
39878瀏覽量
301530 -
機器學習
+關注
關注
66文章
8554瀏覽量
136996
發布評論請先 登錄
達索系統與 NVIDIA 合作構建支持虛擬孿生的工業 AI 平臺

Caterpillar借助NVIDIA技術推動重工業領域智能化升級

PYQT 應用程序框架及開發工具
搭建自己的ubuntu系統之創建ubuntu虛擬機
學生適合使用的SOLIDWORKS 云應用程序
輕松配置小智AI語音開發板,安信可IOT小程序功能更新

外圍設備通過手機連接到BLE應用程序,為什么不能連接到Infineaon BLE?
NVIDIA技術助力企業創建主權AI智能體
完整符合服務器需求的虛擬化解決方案X100+AIA+IOMMU




 工商網監
工商網監
評論