 HugeCTR能夠高效地利用GPU來進行推薦系統的訓練
HugeCTR能夠高效地利用GPU來進行推薦系統的訓練

1. Introduction
HugeCTR 能夠高效地利用 GPU 來進行推薦系統的訓練,為了使它還能直接被其他 DL 用戶,比如 TensorFlow 所直接使用,我們開發了 SparseOperationKit (SOK),來將 HugeCTR 中的高級特性封裝為 TensorFlow 可直接調用的形式,從而幫助用戶在 TensorFlow 中直接使用 HugeCTR 中的高級特性來加速他們的推薦系統。
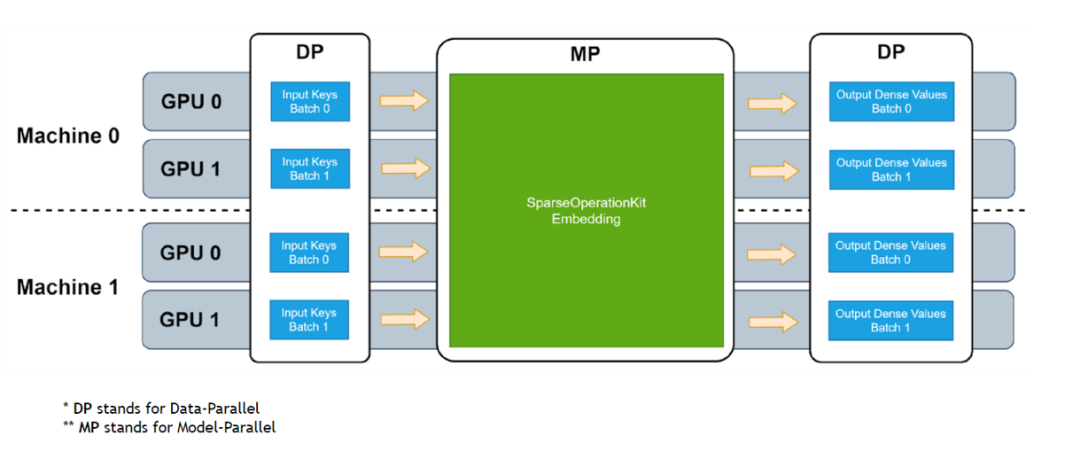
圖 1. SOK embedding 工作流程
SOK 以數據并行的方式接收輸入數據,然后在 SOK 內部做黑盒式地模型轉換,最后將計算結果以數據并行的方式傳遞給初始 GPU。這種方式可以盡可能少地修改用戶已有的代碼,以更方便、快捷地在多個 GPU 上進行擴展。
SOK 不僅僅是加速了 TensorFlow 中的算子,而是根據業界中的實際需求提供了對應的新解決方案,比如說 GPU HashTable。SOK 可以與 TensorFlow 1.15 和 TensorFlow 2.x 兼容使用;既可以使用 TensorFlow 自帶的通信工具,也可以使用 Horovod 等第三方插件來作為 embedding parameters 的通信工具。
使用 MLPerf 的標準模型 DLRM 來對 SOK 的性能進行測試。
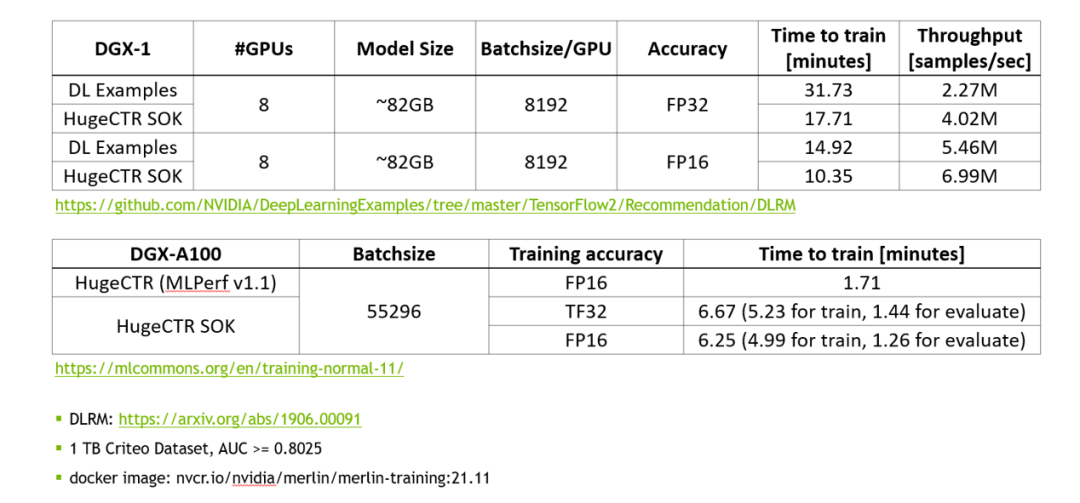
圖 2. SOK 性能測試數據
相比于 NVIDIA 的 DeepLearning Examples,使用 SOK 可以獲得更快的訓練速度以及更高的吞吐量。
3. API
SOK 提供了簡潔的、類 TensorFlow 的 API;使用 SOK 的方式非常簡單、直接;讓用戶通過修改幾行代碼就可以使用 SOK。
1. 定義模型結構

左側是使用 TensorFlow 的 API 來搭建模型,右側是使用 SOK 的 API 來搭建相同的模型。使用 SOK 來搭建模型的時候,只需要將 TensorFlow 中的 Embedding Layer 替換為 SOK 對應的 API 即可。
2. 使用 Horovod 來定義 training loop

同樣的,左側是使用 TensorFlow 來定義 training loop,右側是使用 SOK 時,training loop 的定義方式。可以看到,使用 SOK 時,只需要對 Embedding Variables 和 Dense Variables 進行分別處理即可。其中,Embedding Variables 部分由 SOK 管理,Dense Variables 由 TensorFlow 管理。
3. 使用 tf.distribute.MirroredStrategy 來定義 training loop

類似的,還可以使用 TensorFlow 自帶的通信工具來定義 training loop。
4. 開始訓練

在開始訓練過程時,使用 SOK 與使用 TensorFlow 時所用代碼完全一致。
4. 結語
SOK 將 HugeCTR 中的高級特性包裝為 TensorFlow 可以直接使用的模塊,通過修改少數幾行代碼即可在已有模型代碼中利用上 HugeCTR 的先進設計。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
5194瀏覽量
135453 -
SOK
+關注
關注
0文章
5瀏覽量
6474
原文標題:Merlin HugeCTR Sparse Operation Kit 系列之一
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPU 利用率<30%?這款開源智算云平臺讓算力不浪費 1%
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
提高RISC-V在Drystone測試中得分的方法
NVIDIA Isaac Lab多GPU多節點訓練指南
PCIe協議分析儀能測試哪些設備?
aicube的n卡gpu索引該如何添加?
如何在Ray分布式計算框架下集成NVIDIA Nsight Systems進行GPU性能分析
別讓 GPU 故障拖后腿,捷智算GPU維修室來救場!

利用API提升電商用戶體驗:個性化推薦系統

SL3075 dcdc65V耐壓 5A電流高效率降壓芯片替換TPS54340
Vicor高效電源模塊優化自動駕駛系統
提升AI訓練性能:GPU資源優化的12個實戰技巧

電機高效再制造在企業生產中的應用
利用RAKsmart服務器托管AI模型訓練的優勢
摩爾線程GPU原生FP8計算助力AI訓練




 工商網監
工商網監
評論