") 如何改進雙塔模型才能更好的提升你的算法效果
如何改進雙塔模型才能更好的提升你的算法效果

來自:對白的算法屋
今天寫點技術干貨來回饋一下我的粉絲們。本來想繼續(xù)寫對比學習(Contrastive Learing)相關類型的文章,以滿足我出一本AI前沿技術書籍的夢想,但奈何NIPS2021接收的論文一直未公開,在arxiv上不停地刷,也只翻到了零碎的幾篇。于是,我想到該寫一下雙塔模型了,剛進美團的第一個月我就用到了Sentence-BERT。
為什么呢?因為雙塔模型在NLP和搜廣推中的應用實在太廣泛了。不管是校招社招,面試NLP或推薦算法崗,這已經(jīng)是必問的知識點了。
接下來,我將從模型結構,訓練樣本構造,模型目標函數(shù)三個方面介紹雙塔模型該如何改進,才能更好的提升業(yè)務中的效果。
一、雙塔模型結構改進
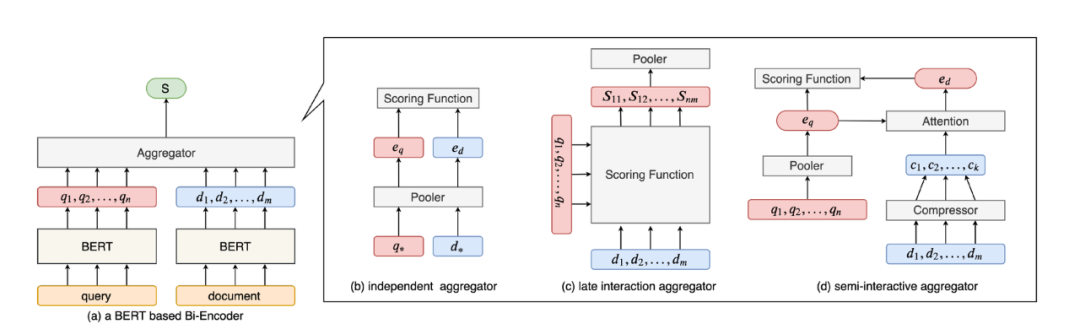
如圖所示,目前主流的雙塔模型結構主要可以歸為三類。
第一類在離線階段直接將BERT編碼的document映射為固定長度的向量,在線階段將query映射為固定長度的向量,然后通過打分函數(shù)計算最后的得分,例如:Sentence-BERT,DPR。
第二類
模型在離線階段將BERT編碼document得到的多個向量(每個向量對應一個token)全部保留,在線階段利用BERT將query編碼成多個向量,和離線階段保留的document的多個向量進行交互打分(復雜度O(mn)),得到最后的得分,代表工作,Col-BERT。
第三類
模型是前兩種的折中,將離線階段BERT編碼得到的document向量進行壓縮,保留k個(k《m)個向量,并且使用一個向量來表示query(一般query包含的信息較少),在線階段計算一個query向量和k個document向量的交互打分(復雜度O(k)),代表工作:Poly-BERT,PQ-BERT。
總結這類工作的主要思想是增強雙塔模型的向量表示能力,由于document較長,可能對應多種語義,而原始雙塔模型對query和document只使用一個向量表示,可能造成語義缺失。那么可以使用多個向量來表示document,在線階段再進行一些優(yōu)化來加速模型的推斷。
二、訓練樣本構造
檢索任務中,相對于整體document庫,每個query所對應的相關document是很少的一部分。在訓練時,模型往往只接收query對應的相關文檔(正樣本)以及少量query的不相關文檔(負樣本),目標函數(shù)是區(qū)分正樣本和負樣本。然而在模型推斷時,模型需要對document庫中的所有document進行打分。如果模型在訓練時讀取的document和document庫中的一些document之間的語義距離相差較大,則可能造成模型在推斷階段表現(xiàn)不佳。因此,如何構造訓練樣本是一個重要的研究方向。
方法一:(1) 首先介紹一個比較簡單的trick,In-batch negatives。顧名思義,在訓練時,假設一個batch中包含b個query,每個query(q_i)都有一個對應的正樣本dp_i和負樣本dq_i,那么在這個batch中,每個q_i除了自己所對應的負樣本,還可以將batch中其他query所對一個的正樣本和負樣本都作為當前query所對應的負樣本,大大提高了訓練數(shù)據(jù)的利用率。實驗表明,該trick在各種檢索任務上都能提高模型的效果。
方法二:(2) 上述方法的目標是在訓練過程中利用更多的負樣本,讓模型的魯棒性更強。然而訓練過程能遍歷的負樣本始終是有限的,那么如何在有限的訓練樣本中構造更有利于模型訓練的負樣本是一個重要的研究問題。
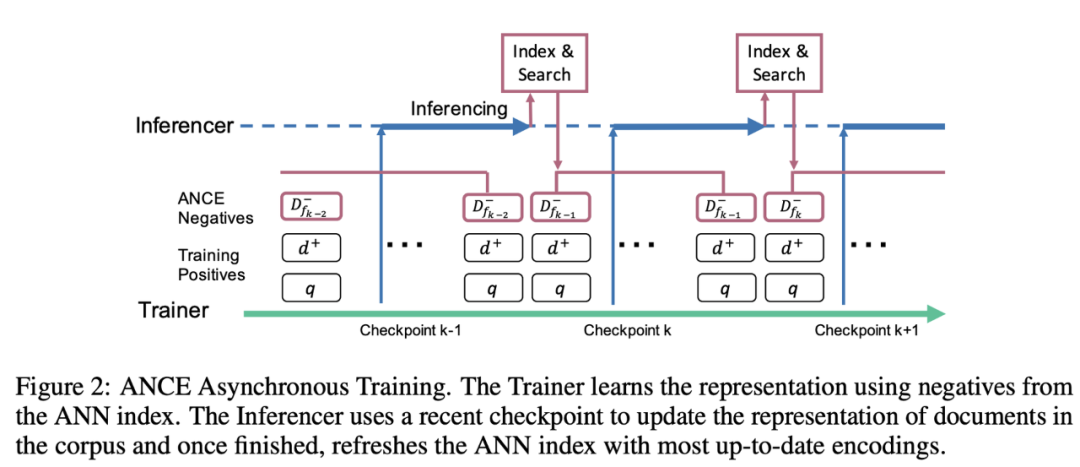
ANCE提出了一種迭代式生成負樣本的思路:隨著訓練的進行,模型對于文本的表示也會變化,之前對于模型較難的負樣本可能變得不那么難,而之前沒見過的負樣本對于模型可能會較難區(qū)分。該工作以此為出發(fā)點,同時進行train和inference,在訓練的同時,利用上一個checkpoint中的模型進行inference,對訓練數(shù)據(jù)生成新的負樣本,在inference完成后,使用新的負樣本進行訓練。這樣可以漸進的訓練模型,保持負樣本的難度,更充分的訓練模型。
方法三:(3) 除了利用模型本身來生成負樣本,還可以利用比雙塔模型復雜的交互模型來生成訓練數(shù)據(jù)。RocketQA提出了基于交互模型來增強數(shù)據(jù)的方法。由于交互模型的表現(xiàn)更強,作者使用交互模型來標注可能成為正樣本的文檔(這些文檔未經(jīng)過標注),以及篩選更難的訓練雙塔模型的樣本。具體的訓練過程如下圖所示:
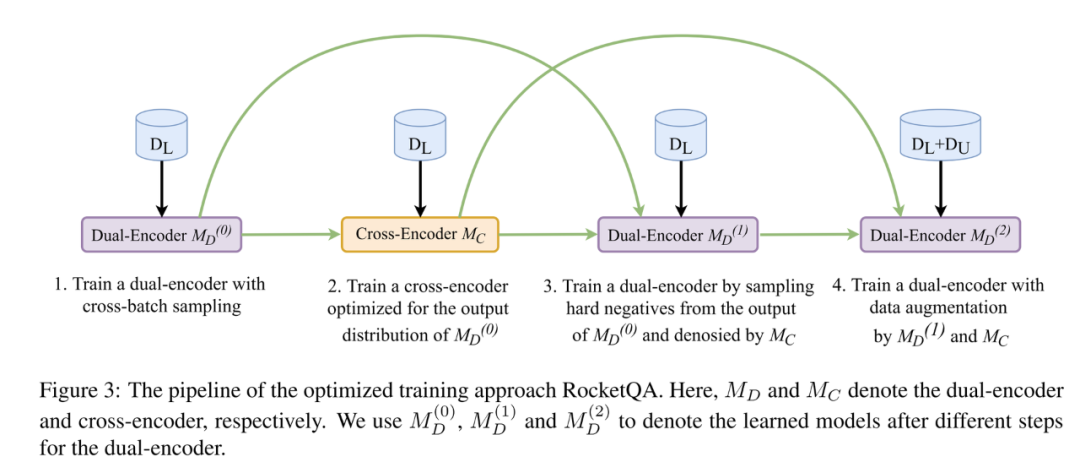
總結:這類工作從訓練數(shù)據(jù)著手,彌補原有的訓練模式對于缺少負樣本優(yōu)化的不足。個人角度認為這類工作提升可能更為顯著。
三、訓練目標改進
訓練目標上的改進比較靈活,有多種不同的改進方式,首先介紹利用交互模型改進雙塔模型的工作。
相對于雙塔模型,交互模型的表現(xiàn)更好,但復雜度更高,因此很多工作的idea是通過模型蒸餾將交互模型的文本表示能力遷移到雙塔模型中,這方面有很多類似的工作。這里選取一個SIGIR2021的最新文章作為代表。
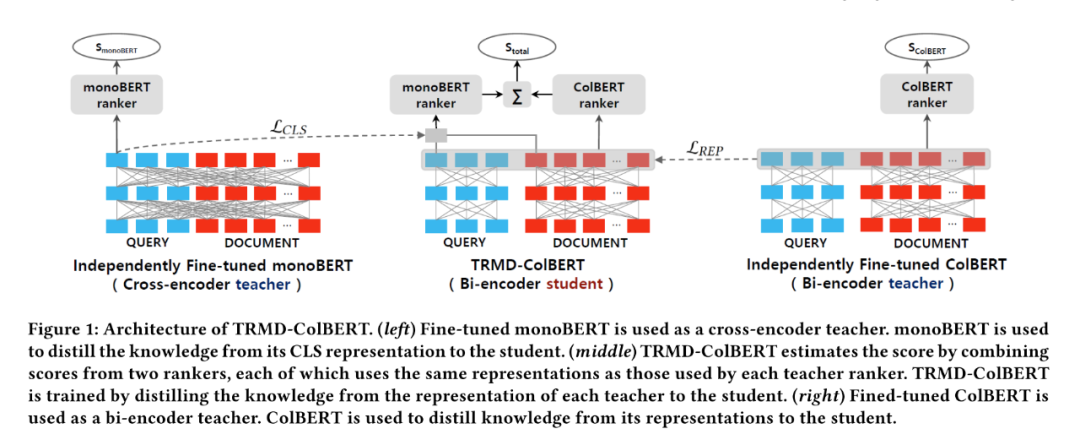
如上圖所示,該模型不僅蒸餾了一個交互模型(monoBERT),同時還蒸餾了一個基于雙塔的改進模型ColBERT。該模型使用monoBERT作為teacher,對模型的CLS位置向量進行蒸餾,使用ColBERT作為teacher,對模型的除了[CLS]位置的向量進行蒸餾,目標函數(shù)為以下三部分的加和:
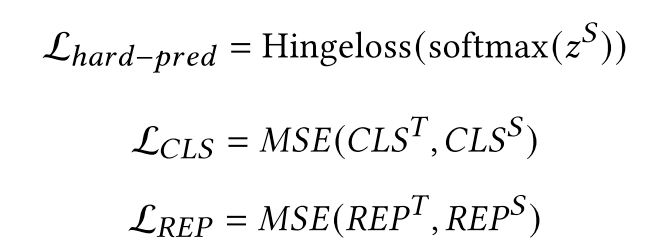
最后的打分函數(shù)是monoBERT和ColBERT的組合,即,首先使用document和query的CLS位置向量輸入MLP,輸出一個分數(shù),同時使用document和query的其他位置表示向量輸入到和ColBERT相同的打分函數(shù)中,最后使用兩個分數(shù)的和作為最后打分。
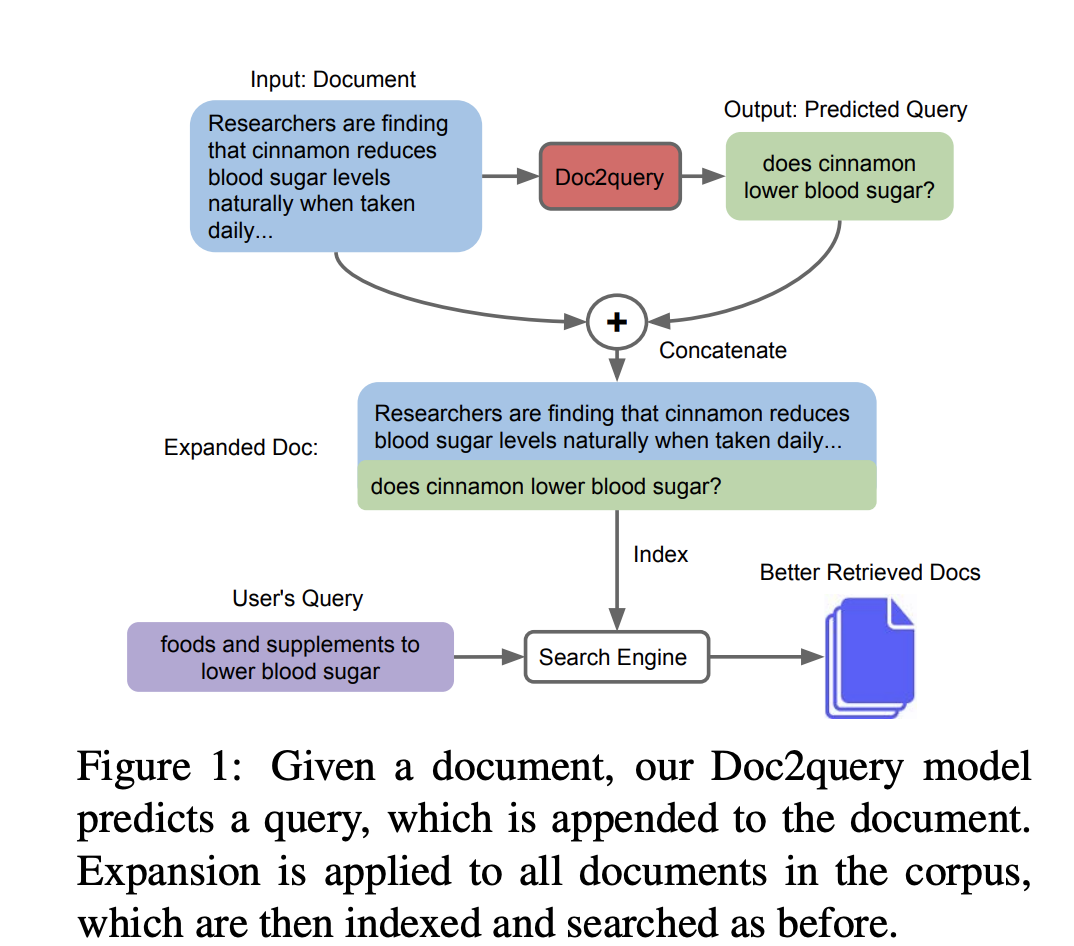
前文所述的工作都是將query和document的文本映射到稠密向量空間中,然后進行匹配。另外還有的工作是直接利用文字進行匹配。Doc2query使用一個基于seq2seq的預訓練語言模型(比如T5),利用標注的document,query對進行finetune,目標是輸入document輸出對應的query,然后將輸出的query和document本身進行拼接,擴展document。然后利用傳統(tǒng)的檢索方法,比如BM25,對擴展過的document建立索引并查找。過程示意如下圖所示。在MSMARCO上的一些實驗表明,這個方法可以和基于向量的搜索一起使用,提高模型的表現(xiàn)。
四、雙塔模型預訓練
一般的預訓練模型使用的目標函數(shù)主要是MLM或者seq2seq,這種預訓練目標和雙塔的匹配任務還是有一些不一致。并且已有的預訓練模型即使有匹配任務(比如NSP),也是使用交互而非雙塔的工作方式。為了使用預訓練提高雙塔模型的效果,SimCSE通過對比學習,提升模型對句子的表示能力。
該方法的實現(xiàn)很簡單,假設提取一個batch的句子,通過模型自帶的dropout,將每個句子輸入到預訓練模型中,dropout兩次,將同一個句子dropout后的結果作為正樣本,不同句子的dropout結果作為負樣本,拉近正樣本的距離,拉遠負樣本的距離,每個句子的向量由BERT的CLS位置向量表示。如下圖所示:
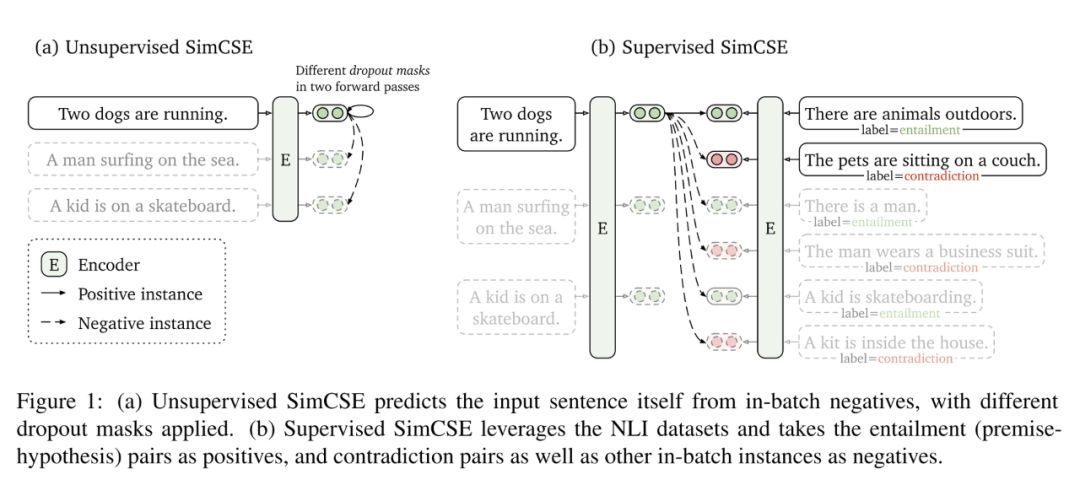
模型雖然很簡單,但是在句子匹配任務上取得了很好的效果。該模型在檢索任務上的效果還需實驗。
還有的工作是針對檢索任務的預訓練。ICLR2020一篇論文Pre-training Tasks for Embedding-based Large-scale Retrieval提出了一些預訓練任務,這些任務主要是針對Wikipedia的,不一定具有普適性。如下圖所示,紫色d框出來的代表document,q1,q2,q3代表不同任務構造的的query,q1是ICT,即利用document所在的一句話作為query,q2是BFS,即利用document所在網(wǎng)頁的第一段中的一句話作為query,q3是WLP,使用document中的某個超鏈接頁面的第一句話作為query。任務目標是匹配q1,q2,q3和d。

Condenser
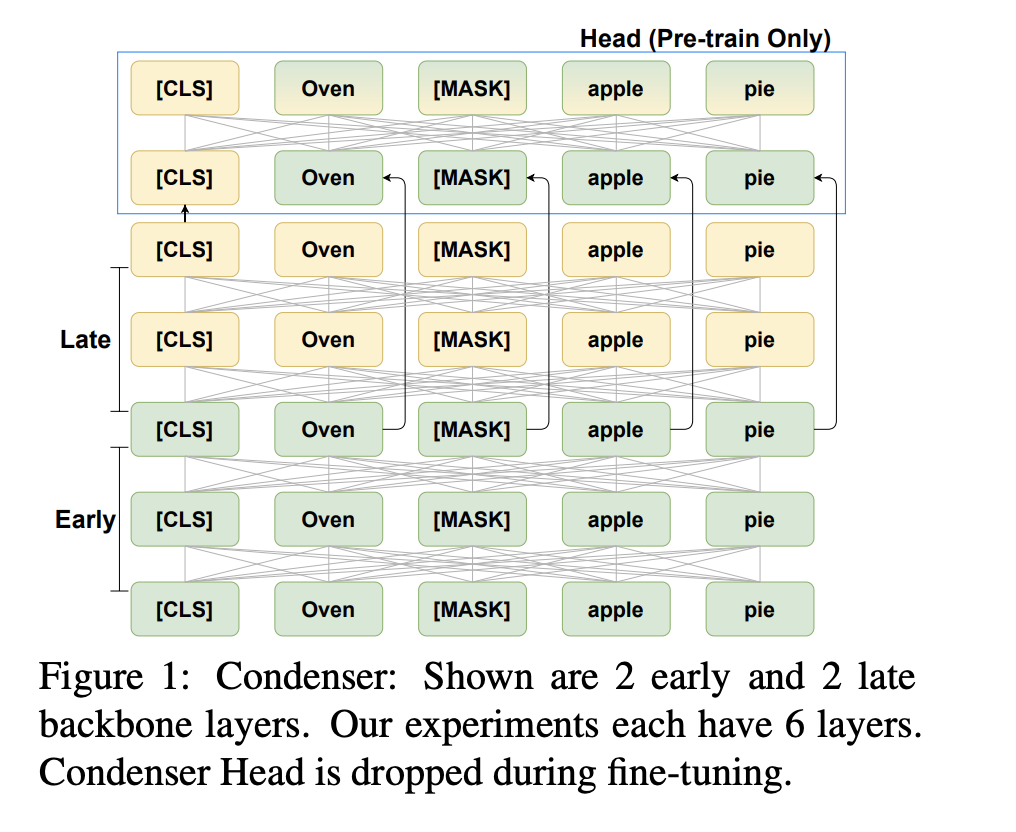
傳統(tǒng)的MLM預訓練任務如下圖所示,該任務沒有特別強制訓練CLS位置的向量表示能力。為了將整個序列的信息壓縮到CLS位置上,Condenser將模型分成兩部分,第一部分和普通的Transformer一樣,第二部分使用經(jīng)過更多交互后的[CLS]位置向量(黃色部分)來預測[MASK]的token,強制模型的[CLS]編碼可以具有還原其他token的能力。
編輯:jq
-
AI
+關注
關注
91文章
39793瀏覽量
301407 -
編碼
+關注
關注
6文章
1039瀏覽量
56974 -
CLS
+關注
關注
0文章
9瀏覽量
9884 -
nlp
+關注
關注
1文章
491瀏覽量
23280
原文標題:業(yè)界總結 | 如何改進雙塔模型,才能更好的提升你的算法效果?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
算法工程師需要具備哪些技能?
e203除法器算法改進(一)
e203除法器算法改進(二)
借助NVIDIA Megatron-Core大模型訓練框架提高顯存使用效率

曠視借助大模型與智能體推動算法落地
了解SOLIDWORKS202仿真方面的改進
MSCMG無刷直流電機改進的I_f無位置起動方法
移遠通信飛鳶AIoT大模型應用算法成功通過備案



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論