") 怎么使用蒸餾法對低精度推理出浮點網(wǎng)絡進行高保真的轉(zhuǎn)換?
怎么使用蒸餾法對低精度推理出浮點網(wǎng)絡進行高保真的轉(zhuǎn)換?

神經(jīng)網(wǎng)絡加速器快速、低功耗推理的一個主要挑戰(zhàn)是模型的大小。近年來,隨著模型尺寸的增加,推理時間和每次推理能耗的相應增加,神經(jīng)網(wǎng)絡向更深的神經(jīng)網(wǎng)絡發(fā)展,激活和系數(shù)也在增加。這在資源受限的移動和汽車應用中尤為重要。
低精度推理有助于通過降低 DRAM 帶寬(這是影響設(shè)備能耗的一個重要因素)、計算邏輯成本和功耗來降低推理成本。在這種情況下,下面的問題自然而然地出現(xiàn)了:編碼神經(jīng)網(wǎng)絡權(quán)重和激活的最佳位深度是多少?有幾個建議的數(shù)字格式可以減少位深度,包括Nvidia的TensorFloat,谷歌的8位非對稱定點(Q8A)和bfloat16。
但是,雖然這些格式是朝著正確方向邁出的一步,但不能說它們是最佳的:例如,大多數(shù)格式都為要表示的每個值存儲一個指數(shù),當多個值在同一區(qū)間時,這些指數(shù)可能是多余的。
更重要的是,他們沒有考慮神經(jīng)網(wǎng)絡的不同部分通常有不同的位深度要求這一事實。有些圖層可以用較低的位深度編碼,而其他圖層(如輸入和輸出層)需要更高的位深度。MobileNet v3就是一個例子,它可以從 32 位浮點轉(zhuǎn)換為大多數(shù)在 5-12 位區(qū)間內(nèi)的位深度(見圖 1)。
我們稱使用不同的位深度來編碼原始浮點網(wǎng)絡的不同部分為可變位深度 (VBD) 壓縮。當然,權(quán)重的位深度編碼和網(wǎng)絡準確度也是需要權(quán)衡的。較低的位深度會導致更有效的推斷,但刪除過多的信息會損害準確性,這意味著需要找到一個最佳的折中方案。VBD 壓縮的目標是在壓縮和精度之間進行平衡。
原則上,可以將其視為優(yōu)化問題:我們希望用盡可能少的比特數(shù)達到最佳精度的網(wǎng)絡。這是通過在損失函數(shù)中添加新的一項來實現(xiàn)的,該項表示網(wǎng)絡的大小,以便可以沿原始損失函數(shù)最小化,該函數(shù)可以大致表示為:總損失=網(wǎng)絡錯誤+γ(網(wǎng)絡大小)其中γ是一個權(quán)重因子,用于控制網(wǎng)絡大小和誤差之間的目標權(quán)衡。
因此,要以這種方式壓縮網(wǎng)絡,我們需要兩件事:精度的可微度量(錯誤)和網(wǎng)絡大小的可微度量(壓縮位深度)。網(wǎng)絡大小項和網(wǎng)絡誤差項相對于比特數(shù)的可微性非常重要,因為它使我們能夠優(yōu)化(學習)比特深度。
可微網(wǎng)絡規(guī)模
對于可微量化,我們可以使用任何具有可微位深度參數(shù)的函數(shù),該參數(shù)將一個或多個浮點值映射為硬件可表示的壓縮數(shù)字格式。例如,我們可以使用 Google Q8A 量化的可變位深度版本(其中可表示范圍不是以零為中心):
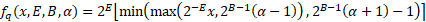
其中:
?x?是 x 四舍五入到最近的整數(shù)(使用目標硬件平臺的舍入模式)
B 是位深度。
E 是浮點表示的指數(shù)。
α是不對稱參數(shù)。
在實踐中,量化參數(shù) B、E 和α用于壓縮多個權(quán)重,例如,單個參數(shù)用于壓縮整個神經(jīng)網(wǎng)絡層(激活或權(quán)重張量)或?qū)觾?nèi)的通道。我們還可以通過將不對稱參數(shù)設(shè)置為 0 來使用對稱量化(有效地將其轉(zhuǎn)換為縮放的 B位無符號整數(shù)格式):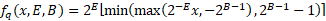 為了實現(xiàn)對所有參數(shù)的反向傳播,我們使用直通估計器,將圓形函數(shù)的梯度作為 1。這使得公式中的所有操作都是可微的,使所有參數(shù)(包括位深度)都可學習!此時,我們可以選擇要訓練的參數(shù):1. 權(quán)重和最大壓縮位深度。2. 只有權(quán)重和指數(shù)(對于固定的位深度)。3. 只有量化參數(shù),它有幾個好處(如下所述),成本可能更低的壓縮比。在生成本文的結(jié)果時選擇了選項 3。
為了實現(xiàn)對所有參數(shù)的反向傳播,我們使用直通估計器,將圓形函數(shù)的梯度作為 1。這使得公式中的所有操作都是可微的,使所有參數(shù)(包括位深度)都可學習!此時,我們可以選擇要訓練的參數(shù):1. 權(quán)重和最大壓縮位深度。2. 只有權(quán)重和指數(shù)(對于固定的位深度)。3. 只有量化參數(shù),它有幾個好處(如下所述),成本可能更低的壓縮比。在生成本文的結(jié)果時選擇了選項 3。
另一個需要考慮的方面是優(yōu)化位深度參數(shù) B(對于某些格式的指數(shù) E):任何硬件都需要 B 是整數(shù)。要找到整數(shù)解,我們有多種選擇:
將四舍五入與直通估計器一起應用于 B 參數(shù)(例如,使用公式)。但是,這給優(yōu)化表面帶來了不連續(xù)性,雖然可以處理,但超出了本文的范圍。
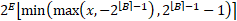
這里選擇的替代方案是在訓練的第一階段優(yōu)化浮點數(shù)B,“保守”地將其四舍五入到最近的整數(shù)?B?( 否則激活和權(quán)重張量的重要部分可能會被鉗制),將其固定為常量并繼續(xù)訓練。這樣平均會損失大約 0.5 位的潛在壓縮,但保證不會發(fā)生不適當?shù)牟眉簟?/p>
可微精度測度
為了測量網(wǎng)絡的準確性,我們可以簡單地使用網(wǎng)絡最初訓練的相同損失函數(shù)。然而,在許多應用中,目標是壓縮一個已經(jīng)用32 位浮點訓練的網(wǎng)絡,這意味著我們可以用蒸餾損失代替。這意味著壓縮網(wǎng)絡的精度是根據(jù)原始網(wǎng)絡的輸出來衡量的。在這項工作中,選擇(輸出)logits之間的絕對差異作為蒸餾損失,但也可以采用其他措施。
使用的蒸餾損失定義為:
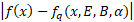
(等式1)
蒸餾損失有許多優(yōu)點:
無標簽訓練:我們不需要標簽數(shù)據(jù)來壓縮網(wǎng)絡,因為我們用原始網(wǎng)絡的輸出取代了標簽。這意味著我們可以壓縮網(wǎng)絡,而無需訪問(可能是專有的)原始數(shù)據(jù)集:我們只需要具有代表性的輸入和原始網(wǎng)絡。
通用性:神經(jīng)網(wǎng)絡壓縮機具有通用性:它不需要特定于網(wǎng)絡。
更少的訓練數(shù)據(jù):由于我們只是訓練量化參數(shù),過度擬合的范圍大大縮小,所以我們可以使用更少的訓練數(shù)據(jù)。有時候一張圖片就足夠了!
軟目標:由于從輸入得到的蒸餾損失比標簽包含更多的量化誤差信息,因此它允許更快、更準確的收斂。
我們可以使用蒸餾損失將權(quán)重與量化參數(shù)一起訓練。然而,在這種情況下,我們需要更多的訓練數(shù)據(jù)來防止過度擬合。兩全其美的方法是以很小的學習率來訓練權(quán)重,并提前停止。這樣,權(quán)重可以抵消量化誤差,而不會過度擬合數(shù)據(jù)集。
可微壓縮將通用的、可微的精度度量與可微量化相結(jié)合,得到可微壓縮的損失函數(shù):
(等式2)第一個項是誤差,第二項是網(wǎng)絡大小的成本。B 是網(wǎng)絡的平均位深度,可根據(jù)整個網(wǎng)絡的深度參數(shù)來計算:
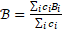
(等式3)其中c_i是使用位深度參數(shù)B_i量化的網(wǎng)絡參數(shù)(權(quán)重或激活)的數(shù)量。請注意,此測量方式取決于批次大小。例如,如果對32個批次網(wǎng)絡進行評估,則激活張量的大小實際上比使用1 批次大小的高出 32 倍。如果目標是將網(wǎng)絡權(quán)重存儲在盡可能小的空間中,則此指標中也可以忽略激活。
選擇量化粒度一些神經(jīng)網(wǎng)絡表示,如谷歌的Q8A格式,允許將不同的比例系數(shù)(與上面的指數(shù)E的2次冪相關(guān))應用于權(quán)重張量(過濾器)的不同通道。這種更精細的粒度可提高給定壓縮級別的網(wǎng)絡精度。
通過對每個通道應用單獨的 E 和α參數(shù),同時對整個張量使用相同的 B 參數(shù),可以通過可變位深度壓縮實現(xiàn)相同的目標。然而,每個通道的量化會導致更慢的收斂,因此根據(jù)我們的經(jīng)驗,使用學習前張量參數(shù)的訓練階段更快,然后將這些參數(shù)分解為每通道參數(shù),并讓它們在另一個訓練階段收斂。
這最終導致三個階段的訓練計劃:
根據(jù)張量訓練所有量化參數(shù)
切換到每通道指數(shù)和移位參數(shù)
將位深度舍入到整數(shù),并將其固定到常量,然后訓練指數(shù)和移位參數(shù)α。此外,權(quán)重也以較小的學習率進行訓練。
結(jié)果對象分類
壓縮分類網(wǎng)絡的精確度。
圖像分割
應用于分割網(wǎng)絡的不同壓縮方法之間的比較。第二個列基于啟發(fā)式算法,該算法試圖在不使用反向傳播的情況下確定固定位深度的最佳指數(shù)。
風格轉(zhuǎn)換
最后一列使用上述啟發(fā)式給出10 比特時的完全空白輸出。
結(jié)論用于編碼神經(jīng)網(wǎng)絡權(quán)重和激活的位深度對推理性能有顯著影響。將大小精度權(quán)衡作為損失函數(shù)的一部分,可以在神經(jīng)網(wǎng)絡訓練過程中學習任意粒度的最佳比特深度。此外,當優(yōu)化將 0 位分配給網(wǎng)絡的一部分時,它會有效地從架構(gòu)中刪除該部分,作為一種架構(gòu)搜索,從而降低計算成本和帶寬成本。今后的工作將探索這方面的可微網(wǎng)絡壓縮。我們提出了一種基于微分量化和蒸餾的通用而靈活的方法,允許在不影響精度的情況下為各種任務優(yōu)化位數(shù)。我們的方法有幾個優(yōu)點,包括訓練時間短,重復使用訓練過的網(wǎng)絡,不需要標簽,可調(diào)整的大小精度權(quán)衡和問題無關(guān)的損失功能。通過這種方式,我們可以將網(wǎng)絡壓縮為有效的可變位深度表示,而不犧牲對原始浮點網(wǎng)絡的保真度。
[i] https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-精確格式/
[ii]https://www.tensorflow.org/lite/performance/quantization_spec
[iii]https://arxiv.org/abs/1905.12322
[iv] https://arxiv.org/abs/1308.3432
[v]https://arxiv.org/abs/1503.02531
作者:Szabolcs Cséfalvay
原文鏈接:https://www.imaginationtech.com/blog/low-precision-inference-using-distillation/
編輯:jq
-
DRAM
+關(guān)注
關(guān)注
41文章
2394瀏覽量
189195 -
谷歌
+關(guān)注
關(guān)注
27文章
6254瀏覽量
111466 -
神經(jīng)網(wǎng)絡
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107854 -
估計器
+關(guān)注
關(guān)注
0文章
3瀏覽量
5672
原文標題:使用蒸餾法對低精度推理的浮點網(wǎng)絡進行高保真轉(zhuǎn)換
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
德州儀器PCM1796音頻DAC:高保真音頻設(shè)計的理想之選
TPA6120A2高保真耳機放大器:技術(shù)剖析與應用指南
探索SSM6322:高保真低功耗立體聲音頻放大器的卓越之選
石英晶振在高保真(Hifi)音頻中的應用

嵌入式中的浮點型數(shù)據(jù)轉(zhuǎn)換為字節(jié)類型的三種方法
免費獲取 | SimData高保真虛擬數(shù)據(jù)集開源發(fā)布,兼容nuScenes,開箱即用!

浮點指令(二:雙精度)
浮點指令(一:單精度)
蜂鳥E203擴展浮點指令設(shè)計(1)
RVF單精度浮點指令集擴展介紹(2)
功放IC搭配的升壓芯片選型指南:為何H6801更適合高保真功放系統(tǒng)?
功放IC搭配的升壓芯片選型指南:為何H6922更適合高保真功放系統(tǒng)?
Simcenter STAR-CCM+在燃燒學方面的應用:提供了一個可以高效、高保真進行燃燒仿真的迅速而可擴展的化學求解器

LME49600 單通道、110MHz、高保真、高電流耳機緩沖器技術(shù)手冊
揭秘:為什么說TS-AWG系列+外部衰減器是低幅脈沖測試的終極解決方案?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論