") 什么?不用GPU也能加速你的YOLOv3深度學(xué)習(xí)模型
什么?不用GPU也能加速你的YOLOv3深度學(xué)習(xí)模型

你還在為神經(jīng)網(wǎng)絡(luò)模型里的冗余信息煩惱嗎?
或者手上只有CPU,對(duì)一些只能用昂貴的GPU建立的深度學(xué)習(xí)模型“望眼欲穿”嗎?
最近,創(chuàng)業(yè)公司Neural Magic帶來(lái)了一種名叫新的稀疏化方法,可以幫你解決煩惱,讓你的深度學(xué)習(xí)模型效率“一節(jié)更比七節(jié)強(qiáng)”!
Neural Magic是專(zhuān)門(mén)研究深度學(xué)習(xí)的稀疏方法的公司,這次他們發(fā)布了教程:用recipe稀疏化YOLOv3。
聽(tīng)起來(lái)有點(diǎn)意思啊,讓我們來(lái)看看是怎么實(shí)現(xiàn)的~
稀疏化的YOLOv3
稀疏化的YOLOv3使用剪枝(prune)和量化(quantize)等算法,可以刪除神經(jīng)網(wǎng)絡(luò)中的冗余信息。
這種稀疏化方法的好處可不少。
它的推斷速度更快,文件更小。
但是因?yàn)檫^(guò)程太復(fù)雜,涉及的超參數(shù)又太多,很多人都不太關(guān)心這種方法。
Neural Magic的ML團(tuán)隊(duì)針對(duì)必要的超參數(shù)和指令,創(chuàng)建了可以自主編碼的recipe。
各種不同條件下的recipe構(gòu)成了一種可以滿足客戶(hù)各類(lèi)需求的框架。
這樣就可以建立高度精確的pruned或pruned quantized的YOLOv3模型,從而簡(jiǎn)化流程。
那這種稀疏化方法的靈感來(lái)源是什么呢?
其實(shí),Neural Magic 的 Deep Sparse(深度稀疏)架構(gòu)的主要靈感,是在產(chǎn)品硬件上模仿大腦的計(jì)算方式。
它通過(guò)利用 CPU 的大型快速緩存和大型內(nèi)存,將神經(jīng)網(wǎng)絡(luò)稀疏性與通信局部性相結(jié)合,實(shí)現(xiàn)效率提升。
教程概況
本教程目錄主要包括三大模塊:
創(chuàng)建一個(gè)預(yù)訓(xùn)練的模型
應(yīng)用Recipe
導(dǎo)出推理教程的這些recipe可以幫助用戶(hù)在Ultralytics強(qiáng)大的訓(xùn)練平臺(tái)上,使用稀疏深度學(xué)習(xí)的recipe驅(qū)動(dòng)的方法插入數(shù)據(jù)。
教程中列出的示例均在VOC數(shù)據(jù)集上執(zhí)行,所有結(jié)果也可通過(guò)“權(quán)重和偏差”項(xiàng)目公開(kāi)獲得(地址見(jiàn)參考鏈接4)。
調(diào)試結(jié)果展示
研究團(tuán)隊(duì)給出了稀疏YOLOv3目標(biāo)檢測(cè)模型在Deep Sparse引擎和PyTorch上的運(yùn)行情況。
這段視頻以波士頓著名地標(biāo)為特色,在Neural Magic的誕生地——MIT的校園取景。
同樣的條件下,在Deep Sparse引擎上比PyTorch上效率會(huì)更高。
遇到的常見(jiàn)問(wèn)題
如果用戶(hù)的硬件不支持量化網(wǎng)絡(luò)來(lái)推理加速,或者對(duì)完全恢復(fù)的要求非常高,官方建議使用pruned或pruned short 的recipe。
如果用戶(hù)的硬件可以支持量化網(wǎng)絡(luò),如CPU 上的 VNNI 指令集,官方建議使用pruned quantized或pruned quantized short的recipe。
所以使用哪一種recipe,取決于用戶(hù)愿意花多長(zhǎng)時(shí)間訓(xùn)練數(shù)據(jù),以及對(duì)完全恢復(fù)的要求。
具體要比較這幾種recipe的話,可以參考下表。
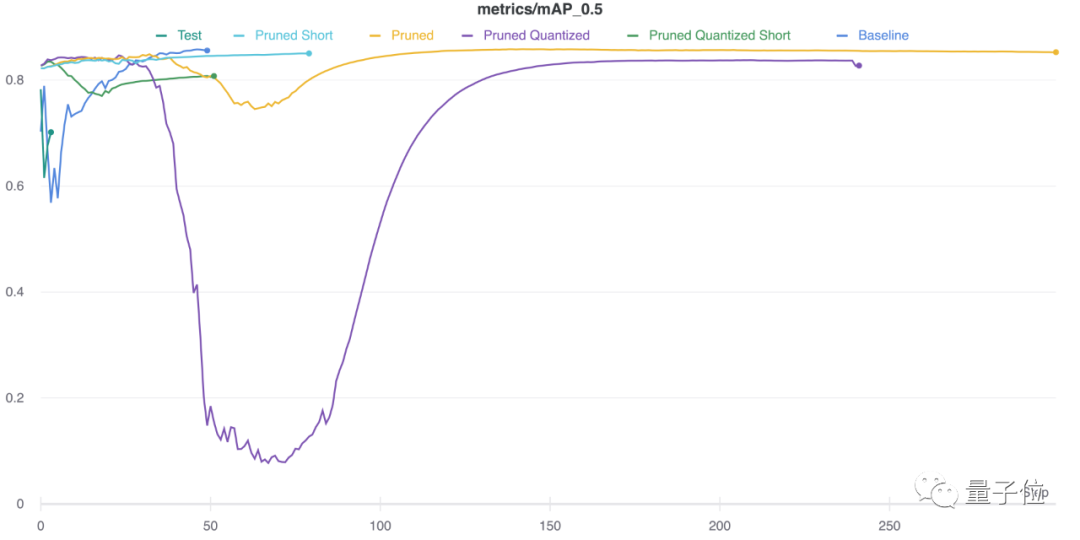
網(wǎng)友:這個(gè)框架會(huì)比傳統(tǒng)的機(jī)器學(xué)習(xí)框架pytorch好嗎?
既然給出了和pytorch的比較視頻,就有網(wǎng)友發(fā)問(wèn)了:
Neural Magic也使用python嗎?為什么一個(gè)比另一個(gè)快10倍以上?我不相信像pytorch這樣傳統(tǒng)的機(jī)器學(xué)習(xí)框架不會(huì)得到優(yōu)化。兩種模型的實(shí)現(xiàn)是否相同?
公司官方人員也下場(chǎng)解釋了:
我們擁有專(zhuān)利技術(shù),可以通過(guò)減少計(jì)算和內(nèi)存移動(dòng)來(lái)使稀疏網(wǎng)絡(luò)在CPU上更高效的運(yùn)行。
雖然傳統(tǒng)的ML框架也能很好地實(shí)現(xiàn)簡(jiǎn)單而高效的訓(xùn)練過(guò)程。
但是,多加入一些優(yōu)化的推理,可以實(shí)現(xiàn)更多的性能,尤其是在CPU上更明顯。
看來(lái),有了以上強(qiáng)大的YOLOv3 模型工具和教程,用戶(hù)就可以在CPU上,以最小化的占用空間和GPU的速度來(lái)運(yùn)行深度學(xué)習(xí)模型。
這樣有用的教程,你還在等什么?
希望教程能對(duì)大家有所幫助,歡迎在評(píng)論區(qū)分享交流訓(xùn)練模型經(jīng)驗(yàn)~
最后介紹一下Neural Magic,有興趣的朋友可以去了解一下。
Neural Magic是一家什么樣的公司?
Neural Magic成立在馬薩諸塞州的劍橋。
創(chuàng)始人Nir Shavit和Alexander Matveev在MIT繪制大腦中的神經(jīng)連接圖時(shí),一直覺(jué)得GPU有許多限制。
因此他們停下來(lái)問(wèn)自己兩個(gè)簡(jiǎn)單的問(wèn)題:
為什么深度學(xué)習(xí)需要GPU等專(zhuān)用硬件?
有什么更好的方法嗎?
畢竟,人腦可以通過(guò)廣泛使用稀疏性來(lái)減少神經(jīng)網(wǎng)絡(luò),而不是添加FLOPS來(lái)匹配神經(jīng)網(wǎng)絡(luò),從而滿足神經(jīng)網(wǎng)絡(luò)的計(jì)算需求。
基于這種觀察和多年的多核計(jì)算經(jīng)驗(yàn),他們采用了稀疏和量化深度學(xué)習(xí)網(wǎng)絡(luò)的技術(shù),并使其能夠以GPU的速度或更高的速度在商用CPU上運(yùn)行。
這樣,數(shù)據(jù)科學(xué)家在模型設(shè)計(jì)和輸入大小上就不需要再做妥協(xié),也沒(méi)必要用稀缺且昂貴的GPU資源。
Brian Stevens
Neural Magic的CEO,Red Hat和Google Cloud的前CTO。
Nir Shavit
Neural Magic聯(lián)合創(chuàng)始人。
麻省理工學(xué)院教授,他目前的研究涉及為多處理器設(shè)計(jì)可伸縮軟件的技術(shù),尤其是多核計(jì)算機(jī)的并發(fā)數(shù)據(jù)結(jié)構(gòu)。
Alexander Matveev
Neural Magic首席技術(shù)官兼聯(lián)合創(chuàng)始人。
麻省理工學(xué)院前研究科學(xué)家,專(zhuān)門(mén)研究AI多核算法和系統(tǒng)。
參考鏈接:
[1]https://github.com/neuralmagic/sparseml/blob/main/integrations/ultralytics-yolov3/t2.utorials/sparsifying_yolov3_using_recipes.md
[2]https://neuralmagic.com/blog/sparsifying-yolov3-using-recipes-tutorial/
[3]https://arxiv.org/pdf/1804.02767.pdf
[4]https://wandb.ai/neuralmagic/yolov3-spp-lrelu-voc
編輯:jq
-
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
224991 -
gpu
+關(guān)注
關(guān)注
28文章
5194瀏覽量
135450 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1236瀏覽量
26194 -
voc
+關(guān)注
關(guān)注
0文章
110瀏覽量
16189
原文標(biāo)題:不用GPU,稀疏化也能加速你的YOLOv3深度學(xué)習(xí)模型
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
老舊設(shè)備采數(shù):不用改造也能連

【團(tuán)購(gòu)】獨(dú)家全套珍藏!龍哥LabVIEW視覺(jué)深度學(xué)習(xí)實(shí)戰(zhàn)課(11大系列課程,共5000+分鐘)
【團(tuán)購(gòu)】獨(dú)家全套珍藏!龍哥LabVIEW視覺(jué)深度學(xué)習(xí)實(shí)戰(zhàn)課程(11大系列課程,共5000+分鐘)
使用ROCm?優(yōu)化并部署YOLOv8模型
【「AI芯片:科技探索與AGI愿景」閱讀體驗(yàn)】+第二章 實(shí)現(xiàn)深度學(xué)習(xí)AI芯片的創(chuàng)新方法與架構(gòu)
基于瑞芯微RK3576的 yolov5訓(xùn)練部署教程

自動(dòng)駕駛中Transformer大模型會(huì)取代深度學(xué)習(xí)嗎?

在K230中,如何使用AI Demo中的object_detect_yolov8n,YOLOV8多目標(biāo)檢測(cè)模型?
yolov5訓(xùn)練部署全鏈路教程

別讓 GPU 故障拖后腿,捷智算GPU維修室來(lái)救場(chǎng)!

大模型推理顯存和計(jì)算量估計(jì)方法研究
智算加速卡是什么東西?它真能在AI戰(zhàn)場(chǎng)上干掉GPU和TPU!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論