 為什么Kafka會怎么快 Kafka 的應用場景
為什么Kafka會怎么快 Kafka 的應用場景

“Kafka 是由 LinkedIn 公司推出的一個高吞吐的分布式消息系統,通俗地說就是一個基于發布和訂閱的消息隊列,溫故而知新,反復學習優秀的框架,定有所獲。
應用場景
Kafka 的應用場景如下:
異步解構:在上下游沒有強依賴的業務關系或針對單次請求不需要立刻處理的業務。
系統緩沖:有利于解決服務系統的吞吐量不一致的情況,尤其對處理速度較慢的服務來說起到緩沖作用。
消峰作用:對于短時間偶現的極端流量,對后端的服務可以啟動保護作用。
數據流處理:集成 spark 做實時數據流處理。
Kafka 拓撲圖(多副本機制)
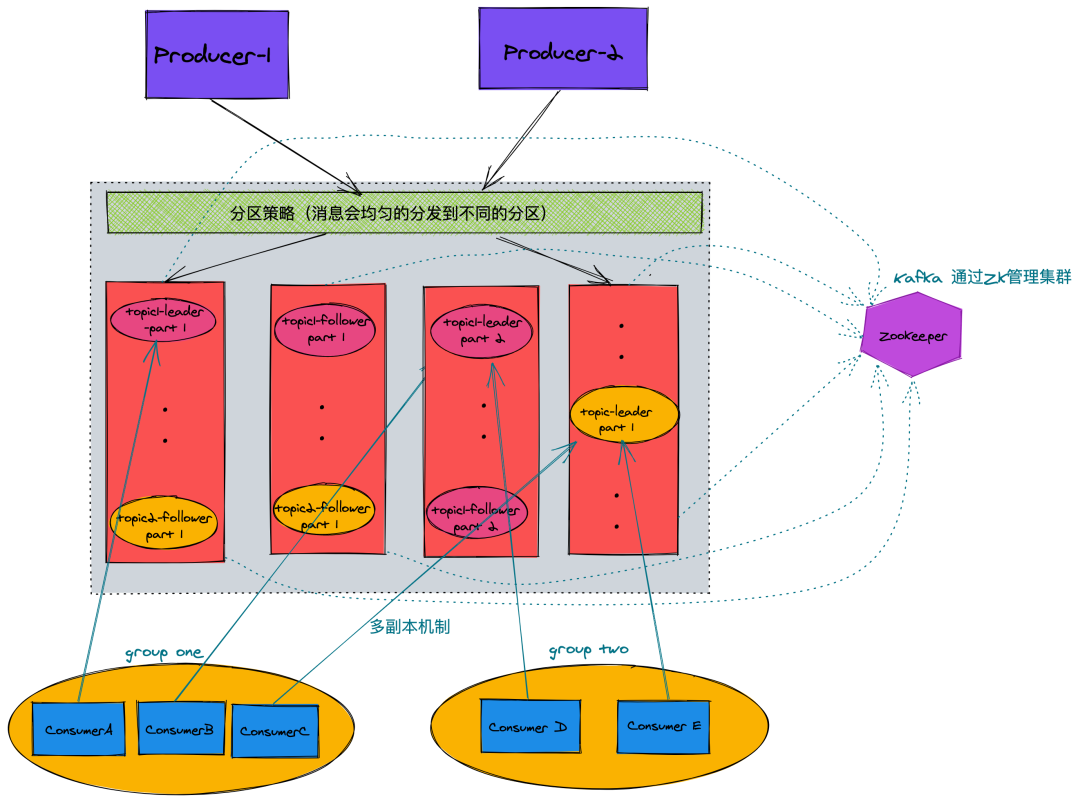
由上圖我們可以發現 Kafka 是分布式,對于每一個分區都存在多副本,同時整個集群的管理都通過 Zookeeper 管理。
Kafka 核心組件
①broker
Kafka 服務器,負責消息存儲和轉發;一個 broker 就代表一個 kafka 節點。一個 broker 可以包含多個 topic。
②topic
消息類別,Kafka 按照 topic 來分類消息。
③partition
topic 的分區,一個 topic 可以包含多個 partition,topic 消息保存在各個 partition 上。
由于一個 topic 能被分到多個分區上,給 kafka 提供給了并行的處理能力,這也正是 kafka 高吞吐的原因之一。
partition 物理上由多個 segment 文件組成,每個 segment 大小相等,順序讀寫(這也是 kafka 比較快的原因之一,不需要隨機寫)。
每個 Segment 數據文件以該段中最小的 offset ,文件擴展名為.log。當查找 offset 的 Message 的時候,通過二分查找快找到 Message 所處于的 Segment 中。
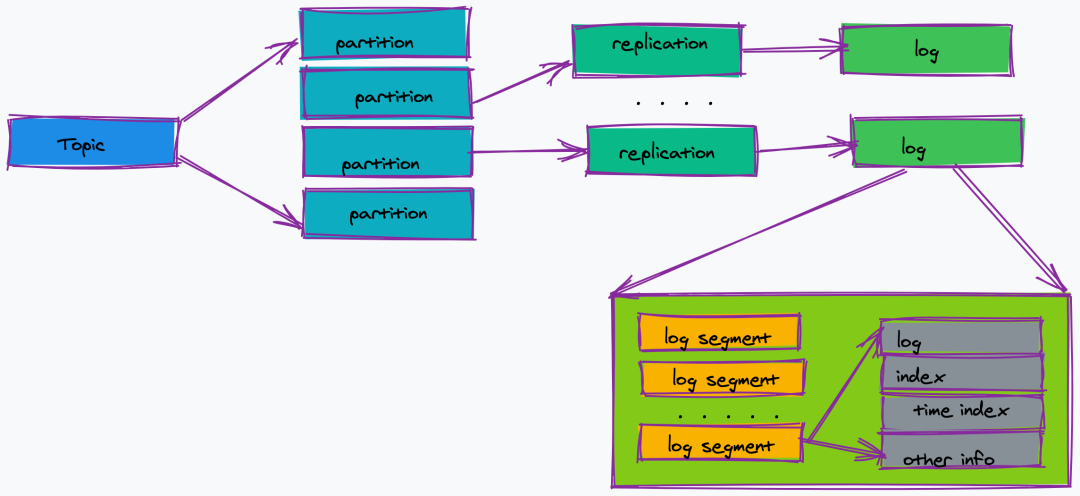
④offset
消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表該消息的唯一序號。
同時也是主從之間的需要同步的信息。
⑤Producer
生產者,負責向 Kafka Broker 發消息的客戶端。
⑥Consumer
消息消者,負責消費 Kafka Broker 中的消息。
⑦Consumer Group
消費者組,每個 Consumer 必須屬于一個 group;(注意:一個分區只能由組內一個消費者消費,消費者組之間互不影響。)
⑧Zookeeper
管理 kafka 集群,負責存儲了集群 broker、topic、partition 等 meta 數據存儲,同時也負責 broker 故障發現,partition leader 選舉,負載均衡等功能。
服務治理
既然 Kafka 是分布式的發布/訂閱系統,這樣如果做的集群之間數據同步和一致性,kafka 是不是肯定不會丟消息呢?以及宕機的時候如果進行 Leader 選舉呢?
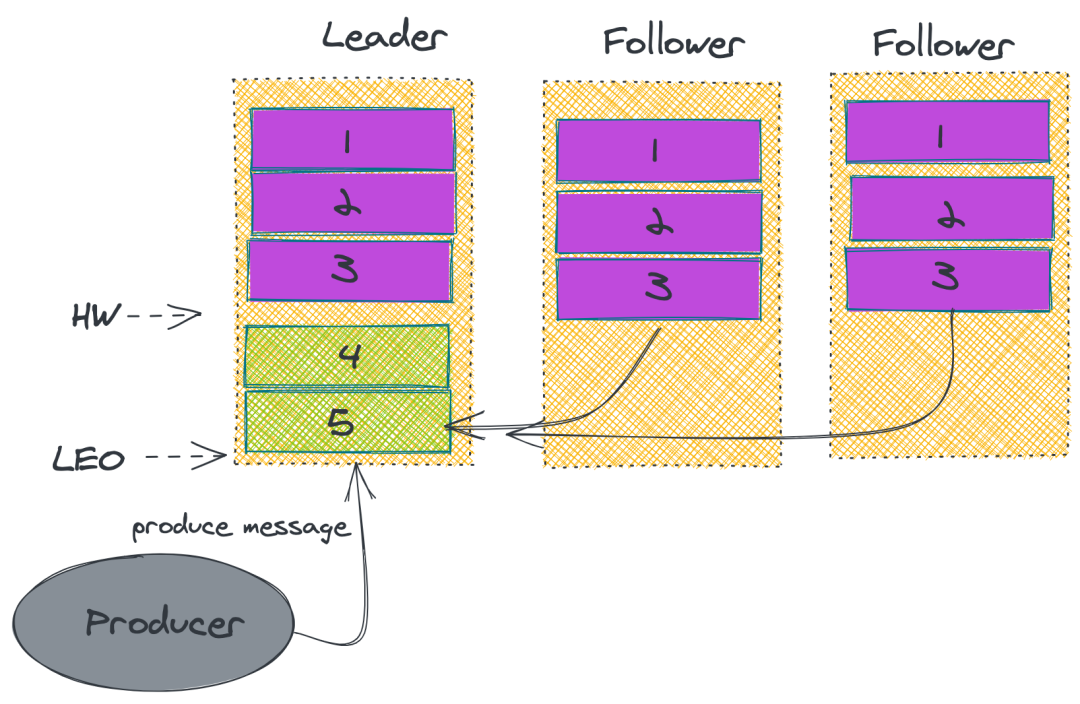
①數據同步
在 Kafka 中的 Partition 有一個 leader 與多個 follower,producer 往某個 Partition 中寫入數據,是只會往 leader 中寫入數據,然后數據才會被復制進其他的 Replica 中。
而每一個 follower 可以理解成一個消費者,定期去 leader 去拉消息。而只有數據同步了后,kafka 才會給生產者返回一個 ACK 告知消息已經存儲落地了。
②ISR
在 Kafka 中,為了保證性能,Kafka 不會采用強一致性的方式來同步主從的數據。
而是維護了一個:in-sync Replica 的列表,Leader 不需要等待所有 Follower 都完成同步,只要在 ISR 中的 Follower 完成數據同步就可以發送 ACK 給生產者即可認為消息同步完成。
同時如果發現 ISR 里面某一個 follower 落后太多的話,就會把它剔除。
具體流程如下:
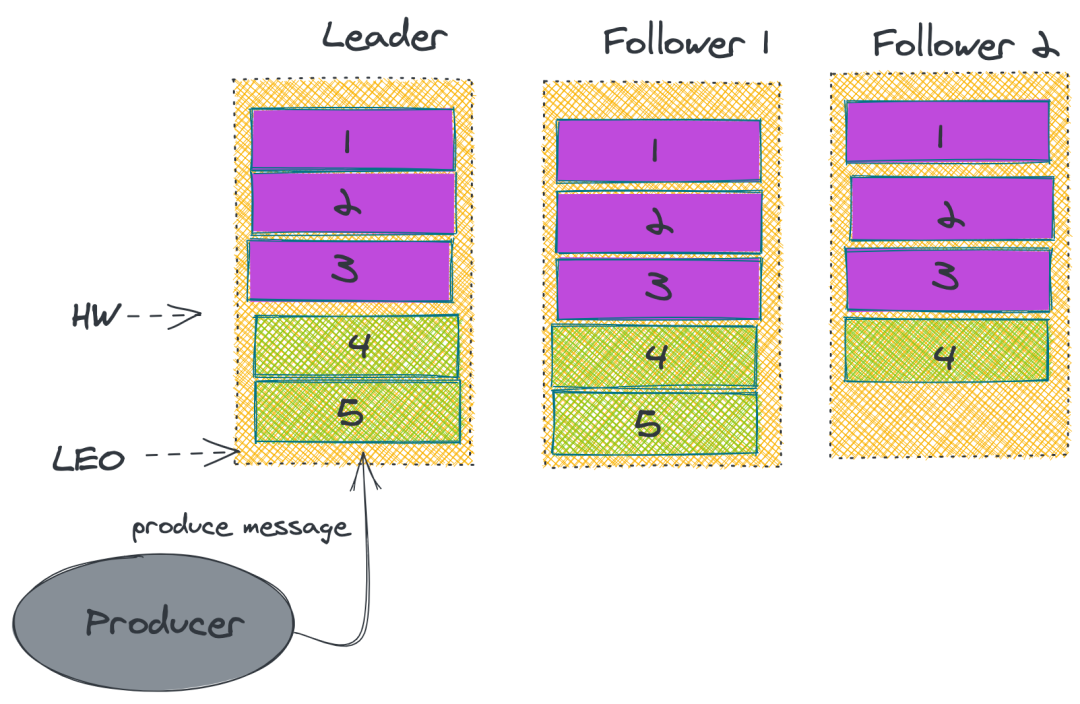
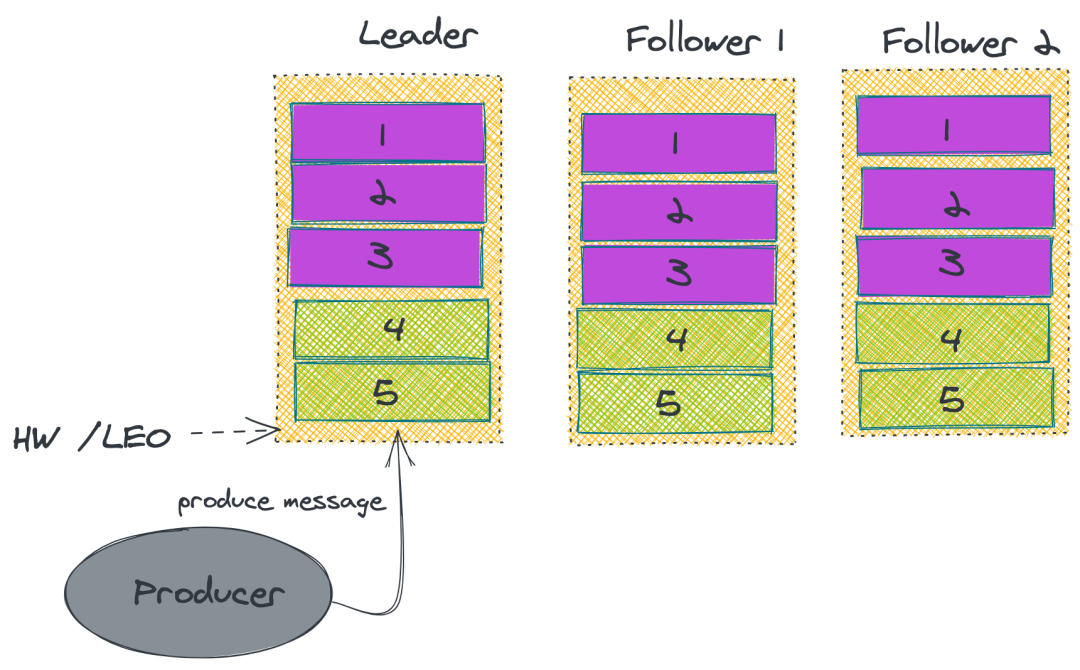
上述的做法并無法保證 Kafka 一定不丟消息。雖然 Kafka 通過多副本機制中最大限度保證消息不會丟失,但是如果數據已經寫入系統 page cache 中但是還沒來得及刷入磁盤,此時突然機器宕機或者掉電,那消息自然而然地就會丟失。
③Kafka 故障恢復
Kafka 通過 Zookeeper 連坐集群的管理,所以這里的選舉機制采用的是Zab(zookeeper 使用):
生產者發生消息給 leader ,這個時候 leader 完成數據存儲,突然發生故障,沒有給 producer 返回 ack。
通過 ZK 選舉,其中一個 follower 成為 leader ,這個時候 producer 重新請求新的 leader,并存儲數據。
Kafka 為什么這么快
①順序寫磁盤
Kafka 采用了順序寫磁盤,而由于順序寫磁盤相對隨機寫,減少了尋地址的耗費時間。(在 Kafka 的每一個分區里面消息是有序的)
②Page Cache
Kafka 在 OS 系統方面使用了 Page Cache 而不是我們平常所用的 Buffer。Page Cache 其實不陌生,也不是什么新鮮事物。
我們在 Linux 上查看內存的時候,經常可以看到 buff/cache,兩者都是用來加速 IO 讀寫用的,而 cache 是作用于讀。
也就是說,磁盤的內容可以讀到 cache 里面,這樣應用程序讀磁盤就非常快。
而 buff 是作用于寫,我們開發寫磁盤都是,一般如果寫入一個 buff 里面再 flush 就非常快。
而 Kafka 正是把這兩者發揮到了極致:Kafka 雖然是 scala 寫的,但是依舊在 Java 的虛擬機上運行。
盡管如此,Kafka 它還是盡量避開了 JVM 的限制,它利用了 Page cache 來存儲,這樣躲開了數據在 JVM 因為 GC 而發生的 STW。
另一方面也是 Page Cache 使得它實現了零拷貝,具體下面會講。
③零拷貝
無論是優秀的 Netty 還是其他優秀的 Java 框架,基本都在零拷貝減少了 CPU 的上下文切換和磁盤的 IO。
當然 Kafka 也不例外。零拷貝的概念具體這里不作太詳細的復述,大致地給大家講一下這個概念。
傳統的一次應用程請求數據的過程:
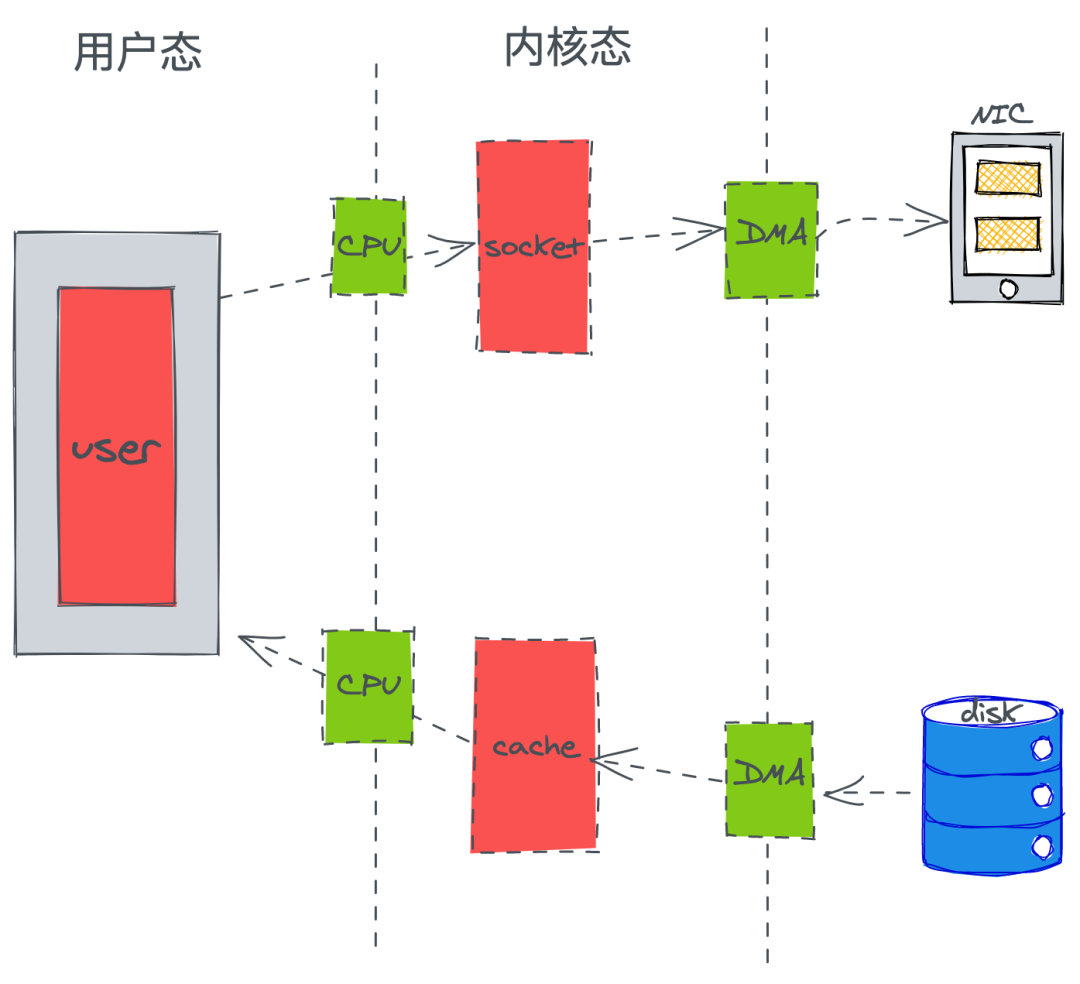
這里大致可以發傳統的方式發生了 4 次拷貝,2 次 DMA 和 2 次 CPU,而 CPU 發生了4次的切換。
DMA 簡單理解就是,在進行 I/O 設備和內存的數據傳輸的時候,數據搬運的工作全部交給 DMA 控制器,而 CPU 不再參與任何與數據搬運相關的事情。
④零拷貝的方式
通過優化我們可以發現,CPU 只發生了 2 次的上下文切換和 3 次數據拷貝。
Linux 系統提供了系統事故調用函數 “sendfile()”,這樣系統調用,可以直接把內核緩沖區里的數據拷貝到 socket 緩沖區里,不再拷貝到用戶態。
⑤分區分段
我們上面也介紹過,Kafka 采取了分區的模式,而每一個分區又對應到一個物理分段,查找的時候可以根據二分查找快速定位。這樣不僅提供了數據讀的查詢效率,也提供了并行操作的方式。
⑥數據壓縮
Kafka 對數據提供了:Gzip 和 Snappy 壓縮協議等壓縮協議,對消息結構體進行了壓縮,一方面減少了帶寬,也減少了數據傳輸的消耗。
Kafka 安裝
①安裝 JDK
由于使用壓縮包還需要自己配置環境變量,所以這里推薦直接用 yum 安裝,熟悉查看目前 Java 的版本:
yum -y list Java*
安裝你想要的版本,這里我是 1.8:
yum install java-1.8.0-openjdk-devel.x86_64
查看是否安裝成功:
Java -version
②安裝 Zookeeper
首先需要去官網下載安裝包,然后解壓:
tar -zxvf zookeeper-3.4.9.tar.gz
要做的就是將這個文件復制一份,并命名為:zoo.cfg,然后在 zoo.cfg 中修改自己的配置即可。
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
主要配置解釋如下:
# zookeeper內部的基本單位,單位是毫秒,這個表示一個tickTime為2000毫秒,在zookeeper的其他配置中,都是基于tickTime來做換算的tickTime=2000# 集群中的follower服務器(F)與leader服務器(L)之間 初始連接 時能容忍的最多心跳數(tickTime的數量)。initLimit=10#syncLimit:集群中的follower服務器(F)與leader服務器(L)之間 請求和應答 之間能容忍的最多心跳數(tickTime的數量)syncLimit=5# 數據存放文件夾,zookeeper運行過程中有兩個數據需要存儲,一個是快照數據(持久化數據)另一個是事務日志dataDir=/tmp/zookeeper
## 客戶端訪問端口clientPort=2181
配置環境變量:
vim ~/.bash_profile
export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK/bin
export PATH
// 啟動
zkServer.sh start
下面能看啟動成功:
③安裝 Kafka
下載 Kafka:
https://www.apache.org/dyn/closer.cgi?path=/kafka/2.8.0/kafka-2.8.0-src.tgz
安裝 Kafka:
tar -xzvf kafka_2.12-2.0.0.tgzbr
配置環境變量:
export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK/bin
export KAFKA=/usr/local/src/kafka
export PATH=$PATH:$KAFKA/bin
啟動 Kafka:
nohup kafka-server-start.sh 自己的配置文件路徑/server.properties &br
大功告成!
編輯:jq
-
數據
+關注
關注
8文章
7335瀏覽量
94769 -
服務器
+關注
關注
14文章
10253瀏覽量
91487 -
拓撲圖
+關注
關注
1文章
20瀏覽量
14748
原文標題:為什么Kafka如此之快?
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
工程師之夜系列分享第三十九篇:Kafka、RocketMQ、JMQ 存儲架構深度對比




 工商網監
工商網監
評論