") 淺談GPU: 衡量計(jì)算效能的正確姿勢(3)
淺談GPU: 衡量計(jì)算效能的正確姿勢(3)

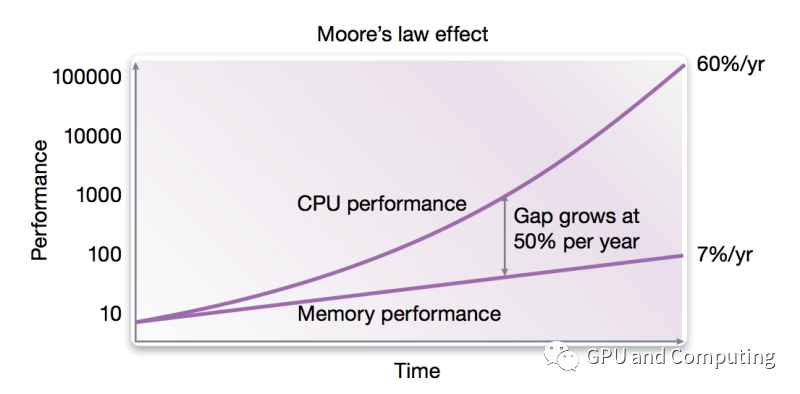
上期我們講了現(xiàn)代計(jì)算機(jī)體系結(jié)構(gòu)通過處理器(CPU/GPU)和內(nèi)存的交互來執(zhí)行計(jì)算程序,處理輸入數(shù)據(jù),并輸出結(jié)果。實(shí)際上,由于CPU是高速器件,而內(nèi)存訪問速度往往受限(如圖所示,CPU和內(nèi)存的性能差距從上個(gè)世紀(jì)80年代開始,不斷拉大),為解決速度匹配的問題,在CPU和內(nèi)存之間設(shè)置了高速緩沖存儲器Cache。
而且Cache往往分幾個(gè)層級,與內(nèi)存以及其它外部存儲器共同構(gòu)成計(jì)算機(jī)系統(tǒng)的存儲器層次結(jié)構(gòu)(Memory Hierarchy),如下圖所示,使得整個(gè)系統(tǒng)在性能,成本和制造工藝達(dá)到平衡。
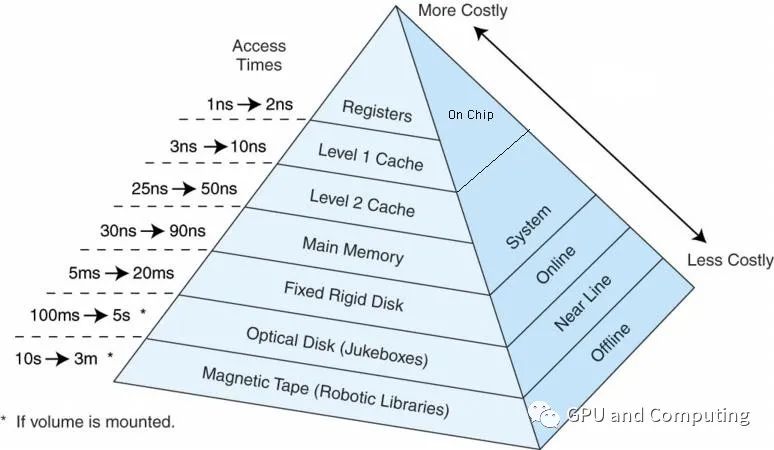
我們可以看到,各個(gè)存儲層次在訪問時(shí)間上存在數(shù)量級別的差異,訪問速度越快,單位制造成本越高,容量越小。在這里,我們并不打算討論Cache具體設(shè)計(jì)和實(shí)現(xiàn),只是希望針對Cache及其命中率對性能的影響有一個(gè)直觀的認(rèn)識。為了簡化討論問題的復(fù)雜性,我們這里做如下假設(shè)。
整個(gè)流水線分為5個(gè)階段,分別為《1》取指、《2》譯碼、《3》運(yùn)算執(zhí)行、《4》訪存讀寫 (可選)、《5》寫回結(jié)果至寄存器。
這里只考慮一級Cache,而且指令、數(shù)據(jù)共享L1 Cache。Cache命中的情況下,每個(gè)階段都是1個(gè)時(shí)鐘(cycle),而cache不命中的情況,階段《1》,《5》各耗時(shí)100個(gè)時(shí)鐘(cycles)。
訪存指令占所有指令1/3。下面我們來分別計(jì)算3種情況下的CPI。
= 100 cycles + 3 * (1 cycle) + ((1 cycle * 2/3) + (100 cycles * 1/3))
= 137 cycles.
= (1 cycle * 0.9 + 100 cycles * (1 - 0.9)) + (3 cycles) + ((1 cycle * (2/3 + 0.9/3)) + (100cycles * (1 - 0.9) * 1/3))
= 18.2 cycles.
= (1 cycle * (0.99) + 100 cycles * (1 - 0.99)) + (3 cycles) + ((1 cycle * (2/3 + 0.99/3)) + (100 cycles * (1 - 0.99) * 1/3))
= 6.32 cycles.
Cache完全缺失。
CPI = 《1》階段的時(shí)鐘+《2, 3, 5》階段的時(shí)鐘+《4》階段的時(shí)鐘
Cache命中率達(dá)到90%。
CPI = 《1》階段的時(shí)鐘+《2, 3, 5》階段的時(shí)鐘+《4》階段的時(shí)鐘
Cache命中率達(dá)到99%
CPI = 《1》階段的時(shí)鐘+《2, 3, 5》階段的時(shí)鐘+《4》階段的時(shí)鐘另外在上期文章里我們也提到同樣32b數(shù)據(jù)的訪問,DRAM的耗能是SRAM的百倍(640pJ vs 5pJ)。完全可見正確配置Cache對高能效高性能計(jì)算的重要作用。
值得一提的是,由于CPU和GPU設(shè)計(jì)面向的差異,他們的Memory Hierarchy存在明顯的區(qū)別,一個(gè)典型的對比如下圖,可以看到GPU的Memeory Hierarchy設(shè)計(jì)的時(shí)候更注意帶寬或者說Throughput,而相比之下對Latency就沒有CPU重視, GPU Cache容量也相對比較小。
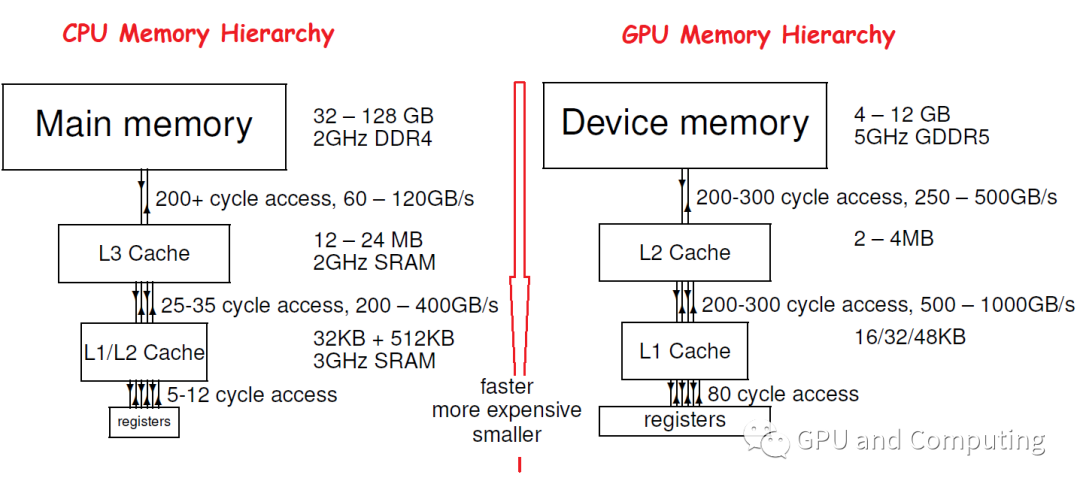
那我們不禁要問,GPU的Latency指標(biāo)這么糟糕,按照我們先前的計(jì)算,Cache不命中的后果是不是很嚴(yán)重?不過不要擔(dān)心,CPU的Cache不命中可能會導(dǎo)致叫停流水線的嚴(yán)重后果,而對GPU,只要計(jì)算任務(wù)量足夠,它的硬件調(diào)度器(Hardware Scheduler)能夠自動在不同的任務(wù)間無縫切換,來掩藏特定任務(wù)訪問memory帶來的延遲。關(guān)于GPU的Latency hiding,值得大書特書,我們以后會詳細(xì)討論。
編輯:lyn
-
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
224994 -
Cache
+關(guān)注
關(guān)注
0文章
130瀏覽量
29711
原文標(biāo)題:GPU: 衡量計(jì)算效能的正確姿勢(3)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
炎核開源開放平臺上架推出OpenSparseBlas高性能稀疏計(jì)算庫
汽車中的GPU是如何使用的?

絕緣子漏電起痕試驗(yàn)儀泄漏電流信號的小波變換分析及電弧能量計(jì)算

別讓 GPU 故障拖后腿,捷智算GPU維修室來救場!

如何選擇合適的電池電量計(jì)
如何計(jì)算孔板流量計(jì)和平衡流量計(jì)的流量?計(jì)算公式一樣嗎?
GPU架構(gòu)深度解析

自己動手繞線圈電感詳細(xì)計(jì)算公式(建議收藏!)
求助,關(guān)于FX3使用SDK自帶回環(huán)固遇到的問題求解
變壓器速查速算手冊(完整版)
常見傳動機(jī)構(gòu)負(fù)載慣量計(jì)算方法及實(shí)例

淺談電磁流量計(jì)的常見故障及排除方法
如何選擇合適的水位流量計(jì)算公式?




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論