 全球人工智能技術創新大賽短文本語義匹配方案技巧
全球人工智能技術創新大賽短文本語義匹配方案技巧

好久不打比賽,周末看到“全球人工智能技術創新大賽”已經開打了一段時間,前排分數沖的有點兇,技癢的我看到了一道熟悉的賽題——小布助手對話短文本語義匹配,由于在搜索推薦系統的一些任重中,文本語義匹配子任務也是經常會遇到的一個問題,于是乎掏出那根...咳咳..沉睡了很久的GPU,翻出了祖傳代碼,跑了一波Baseline...
賽題題型不新鮮,在Baseline的的基礎上參考了一些思路做些煉丹技巧上的操作,3次提交之后順利沖進排行榜首頁。針對短文本語義匹配,本文幫大家梳理一波方案技巧。
P.S.發稿之前,看了一眼排行榜,分數已經被大家刷上去了,參加人數還蠻多,有興趣的同學可以去戰一波...
賽題背景
意圖識別是對話系統中的一個核心任務,而對話短文本語義匹配是意圖識別的主流算法方案之一。本賽題要求參賽隊伍根據脫敏后的短文本query-pair,預測它們是否屬于同一語義,提交的結果按照指定的評價指標使用在線評測數據進行評測和排名,得分最優者獲勝。
數據及評估指標
數據
訓練數據包含輸入query-pair,以及對應的真值。初賽訓練樣本10萬,復賽訓練樣本30萬,這份數據主要用于參賽隊伍訓練模型,為確保數據的高質量,每一個樣本的真值都有進行人工標注校驗。每行為一個訓練樣本,由query-pair和真值組成,每行格式如下:
query-pair格式:query以中文為主,中間可能帶有少量英文單詞(如英文縮寫、品牌詞、設備型號等),采用UTF-8編碼,未分詞,兩個query之間使用 分割。
真值:真值可為0或1,其中1代表query-pair語義相匹配,0則代表不匹配,真值與query-pair之間也用 分割。
評估標準
比賽的評估標準由性能標準和效果標準兩部分組成,初賽采用效果標準,AUC 指標,具體定義如下:
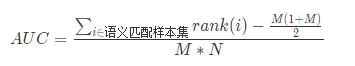
其中:
rank(i):表示i這個樣本的預測得分在測試集中的排序;
M:測試集中語義匹配的樣本的個數;
N:測試集中語義不匹配的樣本的個數。
解決方案與技巧
在BERT橫行的時代,解決方案大同小異,直接梭哈BERT的性價比是很高的,當所有人都會使用這套操作時,你又該怎么辦呢?首先針對此類問題,分享一波煉丹小技巧。由于本賽題開賽前,將文本替換成了加密形式,有些技巧可能無法使用,但不影響學習。
數據增強
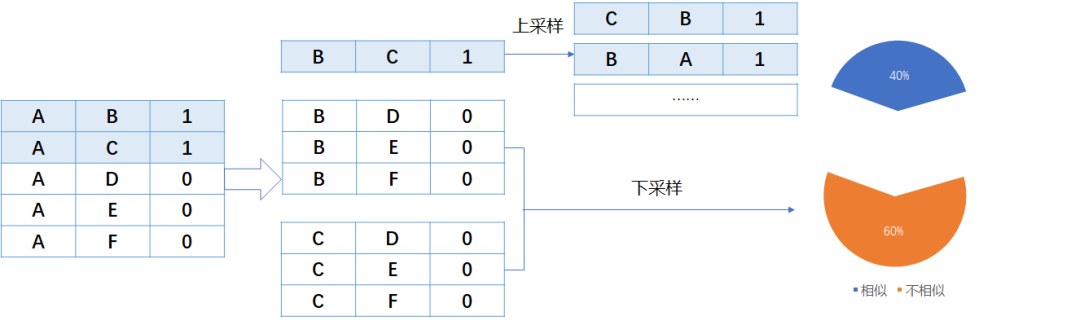
1. 標簽傳遞
根據IF A=B and A =C THEN B=C 的規則,對正樣本做了擴充增強。
根據IF A=B and A!=C THEN B!=C的規則,對負樣本做了擴充增強。
2. 隨機刪除,隨機替換, 隨機交換
Query比較短,大約有10-20個字的長度,隨機刪除部分。
很多query僅僅相差一個單詞, 隨機替換部分。
多數屬于問句, 隨機交換部分。
3. 同義詞替換
建模思路
第一個Baseline我沿用了之前計算相似度的方式對問題就行了求解,也做了模型線上的第一次提交,線上0.88的水平。具體思路如下:
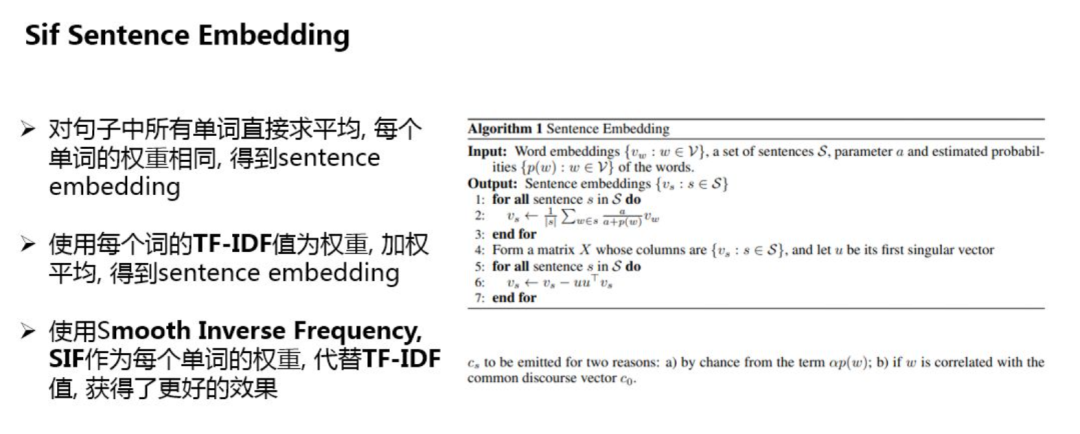
1. SIF Sentence Embedding
SIF Sentence Embedding 使用預訓練好的詞向量,使用加權平均的方法,對句子中所有詞對應的詞向量進行計算,得到整個句子的embedding向量。
SIF的計算分為兩步:
對句子中的每個詞向量,乘以一個獨特的權重b,權重b是一個常數 a除以a與該詞頻率的和,這種做法的會對出現頻率高詞進行降權,也就是說出現頻次越高,其權重也就越小;
計算句向量矩陣的第一主成分u,讓每個Sentence Embedding減去它在u上的投影;
這里,利用該方法做召回,在驗證集上的準確性要比其他兩種方式效果好。
對句子中所有單詞求平均得到sentence embedding;
對句子中所有單詞利用IDF值加權后求平均得到sentence embedding。
2. InferSent
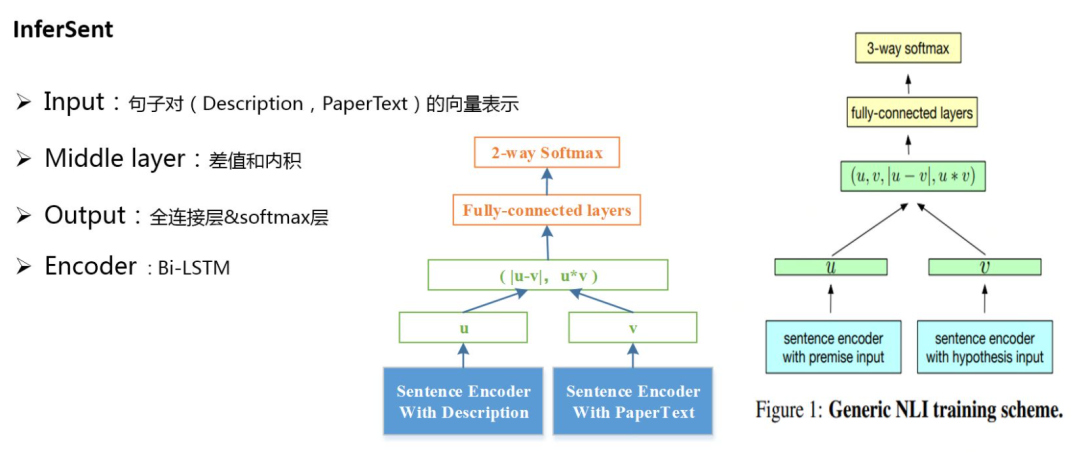
InferSent相似度模型是Facebook提出了一種通過不同的encoder得到Sentence Embedding,然后計算兩個Sentence Embedding的差值、點乘得到交互向量,計算兩者之間的相似度。
這里,對原始論文方法做了兩處修改:其一是針對這個問題對3-way softmax層(entailment,contradiction,neutral)做了相應的修改變為2-way softmax;其二是中間層去掉了u和v,只使用差值和內積兩種特征表征方式;同時在7中編碼器:1)LSTM, 2)GRU, 3)bi-GRU, 4)bi-LSTM(mean pooling), 5)bi-LSTM(max pooling), 6)self-attention, 7)CNN 中選用了Bi-LSTM MaxPooling的方式。
開源方案
本賽題蘇劍林開源了一套方案,這套方案讓脫敏數據,也能使用BERT。脫敏數據對于BERT來說,其實就是Embedding層不一樣而已,其他層還是很有價值的。所以重用BERT主要還是通過預訓練重新對齊Embedding層。
在這個過程中,初始化很重要。首先,我們把BERT的Embedding層中的[UNK]、[CLS]、[SEP]等特殊標記拿出來,這部分不變;然后,我們分別統計密文數據和明文數據的字頻,明文數據指的是任意的開源通用語料,不一定要密文數據對應的明文數據;接著按照頻率簡單對齊明文字表和密文字表。這樣一來,我們就可以按照明文的字來取出BERT的Embedding層來作為相應的初始化。
簡單來說,就是蘇劍林用最高頻的明文字對應的BERT Embedding,來初始化最高頻的密文字,依此類推來做一個基本的字表對齊。對比實驗表明,這個操作可以明顯加快模型的收斂速度。
我的第2次提交是對該方案增加了FGM部分進行了提交測試,因為FGM帶了百一的得分收益,線上0.87+的水平,跟蘇兄開源時公布的0.86+得分相對一致。
FGM對抗訓練
上面提到了FGM的對抗訓練,其實也算是一個煉丹小技巧,這里做一下見到介紹。
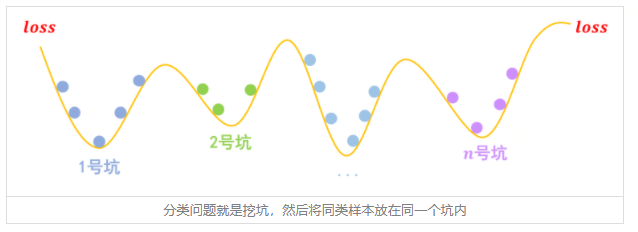
對抗訓練(Adversarial Training),顧名思義,就是在訓練過程中產生一些攻擊樣本,早期是FGSM和I-FGSM攻擊,目前當前最優的攻擊手段是PGD。對抗訓練,相當于是加了一層正則化,給神經網絡的隨機梯度優化限制了一個李普希茨的約束。
傳統上認為,這個訓練方式會犧牲掉一定的測試精度,因為卷積模型關注局部特性,會學到一些敏感于擾動的特征,對抗訓練是一種去偽存真的過程,這是目前像素識別的視覺算法的局限性。這里蘇建林在kexue.fm里實現是很簡單的,詳情參看引用鏈接。
總結
最后,第3次提交將前兩次的提交的結果,做了一個簡單的線性融合,線上到了當時排行榜的首頁,Ensemble的方式其實很多,由于時間的關系并沒去堆很多模型,對此感興趣的同學,可以去看一下《Kaggle競賽寶典》的系列文章。
比賽結束還有一段時間,感興趣的同學可以去嘗試一波。數據競賽作為一種保持競技狀態(戰斗狀態)的一種方式,在工作中直接應用的層面的可能很少,但是它能帶給選手的更多是一種對問題的深層次思考,一種解決問題的實戰訓練能力,如果你有時間,不妨一試。這次全球人工智能技術創新大賽是清華大學劉強老師負責跟的,劉老師的負責態度和對選手的正面鼓勵,我想很多接觸過的人都會印象深刻。哈哈哈,依稀的記得2017年首次參賽,劉老師送的清華大學百年紀念郵票。
工作之后,時間會過很快,考慮更多的可能是做一件事是否能有結果,考慮的事情多了,也就沒有了當年肝肝肝的勇氣。偶爾回到賽場提醒一下自己,懷念一下過去....ALL in BERT,便是這份高效利用自己時間的體現,簡單、有效、奧卡姆剃刀...
原文標題:【比賽經驗】ALL in BERT:一套操作沖進排行榜首頁
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
人工智能
+關注
關注
1817文章
50098瀏覽量
265427
原文標題:【比賽經驗】ALL in BERT:一套操作沖進排行榜首頁
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
云知聲斬獲2025全國人工智能應用場景典型案例
主線科技入選“人工智能+”創新應用實踐案例
成都華微出席人工智能技術創新能力供需對接活動
微軟與新思科技分享智能體人工智能技術的行業影響
何同學“AI尋牛”硬件激發創意,2025 SparkS全球AI硬件創新大賽啟動

恭賀!同星智能TSMaster項目榮獲2025全國顛覆性技術創新大賽優勝獎




 工商網監
工商網監
評論