 Python爬蟲之Beautiful Soup模塊
Python爬蟲之Beautiful Soup模塊

模塊安裝
pip3 install beautifulsoup4
模塊導入
from bs4 import BeautifulSoup
示例html內容
獲取html內容代碼
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36 115Browser/9.0.0"
}
response = requests.get("https://www.xbiquge6.com/xbqgph.html",headers=headers)
response.encoding = "utf-8"
html = response.text
print(html)
獲取的html內容
小說排行榜列表
-
作品分類作品名稱最新章節作者更新時間狀態 -
[都市言情]我本港島電影人今天有更再來一盤菇涼2019-11-16連載中 -
[玄幻奇幻]艾澤拉斯新秩序第一百三十六章 卡拉贊的收獲想靜靜的頓河2019-11-16連載中 -
[都市言情]超級狂婿第654章:他不夠格我本幸運2019-11-16連載中 -
[都市言情]我在都市修個仙完本感言一劍蕩清風2019-11-16連載中 -
[都市言情]都市超級醫圣第2613章 戰后處理斷橋殘雪2019-11-16連載中 -
[都市言情]祖傳土豪系統第二百零五章 我能試試嗎第九傾城2019-11-16連載中 -
[都市言情]都市紅粉圖鑒第1510章 我,才是坐館龍頭!秋江獨釣2019-11-16連載中 -
[武俠仙俠]勝天傳奇第三百八十章 游歷天宮騎牛者2019-11-16連載中 -
[都市言情]總裁爸比從天降第1748章奈何自己是婆婆一碟茴香豆2019-11-16連載中 -
[玄幻奇幻]太古魔帝第一千三百二十四章 魂帝草根2019-11-16連載中
構建BeautifulSoup對象
常用四種解釋器
| 解釋器 | 標識 | 特點 |
|---|---|---|
| Python標準庫 | html.parser | Python內置,執行速度中 |
| lxml的HTML解釋器 | lxml | 速度快 |
| lxml的XML解釋器 | xml | 唯一支持XML解析 |
| html5lib | html5lib | 容錯性最好,以瀏覽器方式解析 |
soup = BeautifulSoup(html, 'html.parser')
還可以解析本地html文件
soup1 = BeautifulSoup(open('index.html'))
.prettify()格式化輸出節點
略
通過 . 獲取節點
title = soup.head.title
print(type(title))
print(title)
結果是
對于名稱唯一的節點,可以省略層級
title = soup.title
print(type(title))
print(title)
結果同樣是
名稱不唯一的節點,直接獲取只會獲取第一個匹配的節點
li = soup.li
print(li)
結果是
find_all根據條件獲取節點
find_all( name , attrs , recursive , text , **kwargs )
name :查找所有名字為 name 的tag,字符串對象會被自動忽略掉;
attrs:根據屬性查詢,使用字典類型;
text :可以搜搜文檔中的字符串內容.與 name 參數的可選值一樣, text 參數接受 字符串 , 正則表達式 , 列表, True ;
recursive:調用tag的 find_all() 方法時,Beautiful Soup會檢索當前tag的所有子孫節點,如果只想搜索tag的直接子節點,可以使用參數 recursive=False ;
limit:find_all() 方法返回全部的搜索結構,如果文檔樹很大那么搜索會很慢.如果我們不需要全部結果,可以使用 limit 參數限制返回結果的數量.效果與SQL中的limit關鍵字類似,當搜索到的結果數量達到 limit 的限制時,就停止搜索返回結果;
class_ :通過 class_ 參數搜索有指定CSS類名的tag,class_ 參數同樣接受不同類型的 過濾器 ,字符串,正則表達式,方法或 True。
根據標簽名字
lis = soup.find_all(nam)
for item in lis:
print(item)
結果是
-
首頁 -
永久書架 -
玄幻奇幻 -
武俠仙俠 -
都市言情 -
歷史軍事 -
科幻靈異 -
網游競技 -
女頻頻道 -
完本小說 -
排行榜單 -
臨時書架 -
作品分類作品名稱最新章節作者更新時間狀態 -
[都市言情]我能舉報萬物第九十六章 巡撫視察【第三更】必火2019-11-16連載中 -
[科幻靈異]女戰神的黑包群第3046章 惡毒女配,在線提刀45二謙2019-11-16連載中 -
[玄幻奇幻]花崗巖之怒第一百五十二章 意外到來的斷劍咱的小刀2019-11-16連載中 -
[網游競技]超神機械師1090 韭菜的自覺齊佩甲2019-11-16連載中 -
[武俠仙俠]無量真途第六百三十二章 突然出現的神智燕十千2019-11-16連載中 -
[科幻靈異]我的細胞監獄第四百五十九章 白霧穿黃衣的阿肥2019-11-16連載中 -
[武俠仙俠]前任無雙第三百章 事急速辦躍千愁2019-11-16連載中 -
[武俠仙俠]元陽道君第四十章 洞開劍扼虛空2019-11-16連載中 -
[歷史軍事]逆成長巨星655:不是辦法的辦法葛洛夫街兄弟2019-11-16連載中 -
[歷史軍事]承包大明第一百九十三章 真會玩南希北慶2019-11-16連載中
根據標簽屬性
屬性和值以字典形式傳入
lis = soup.find_all(attrs={"class":"s2"})
for item in lis:
print(item)
結果是
作品名稱
我能舉報萬物
女戰神的黑包群
花崗巖之怒
超神機械師
無量真途
我的細胞監獄
前任無雙
元陽道君
逆成長巨星
承包大明
限制搜索范圍
find_all 方法會搜索當前標簽的所有子孫節點,如果只想搜索直接子節點,可以使用參數 recursive=False
遍歷獲取子節點
.contents獲取所有子節點
以列表形式返回所有子節點,要注意,列表里面還會摻雜 '/n'
ul = soup.ul
print(ul)
print(ul.contents)
結果是
['/n',
-
首頁, '/n', -
永久書架, '/n', -
玄幻奇幻, '/n', -
武俠仙俠, '/n', -
都市言情, '/n', -
歷史軍事, '/n', -
科幻靈異, '/n', -
網游競技, '/n', -
女頻頻道, '/n', -
完本小說, '/n', -
排行榜單, '/n', -
臨時書架, '/n']
.children獲取所有子節點
返回一個list生成器對象
ul = soup.ul
print(ul.children)
print(list(ul.children))
結果是
['/n',
-
首頁, '/n', -
永久書架, '/n', -
玄幻奇幻, '/n', -
武俠仙俠, '/n', -
都市言情, '/n', -
歷史軍事, '/n', -
科幻靈異, '/n', -
網游競技, '/n', -
女頻頻道, '/n', -
完本小說, '/n', -
排行榜單, '/n', -
臨時書架, '/n']
.descendants遍歷所有子孫節點
ul = soup.ul
for item in ul.descendants:
print(item)
結果是(中間很多'/n'空行我刪掉了)
首頁 首頁
永久書架 永久書架
玄幻奇幻 玄幻奇幻
武俠仙俠 武俠仙俠
都市言情 都市言情
歷史軍事 歷史軍事
科幻靈異 科幻靈異
網游競技 網游競技
女頻頻道 女頻頻道
完本小說 完本小說
排行榜單 排行榜單
臨時書架 臨時書架
獲取其父節點
a = soup.li.a
print(a)
p = a.parent
print(p)
結果是
首頁
提取節點信息
節點名稱
感覺沒什么用
title = soup.title
print(title.name)
結果是
title
節點屬性
a = soup.li.a
print(a)
print(a.attrs) # 獲取所有屬性,返回字典形式
print(a['href'])# 獲取a節點的href屬性值
結果是
首頁
{'href': '/'}
/
節點文本
a = soup.li.a
print(type(a.string)) # 節點內文本的類型
print(a.string) # 獲取節點內的文本內容
print(a.get_text()) # 也是獲取節點內的文本內容
結果是
首頁
注意!!!如果節點內文本是注釋,則用string取出文本時會自動去除注釋標記
注釋的類型:,可以通過類型判斷
遍歷獲取所有子孫節點中的文本
for string in soup.stripped_strings: # 去除多余空白內容
print(repr(string))
想進一步了解編程開發相關知識,與我一同成長進步,請關注我的公眾號“松果倉庫”,共同分享宅&程序員的各類資源,謝謝!!!
審核編輯 黃昊宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
JAVA
+關注
關注
20文章
3001瀏覽量
116434 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265374 -
python
+關注
關注
57文章
4876瀏覽量
90031 -
爬蟲
+關注
關注
0文章
87瀏覽量
8091
發布評論請先 登錄
相關推薦
熱點推薦
UCC33020-Q1:超小型汽車級DC/DC模塊的卓越之選
UCC33020-Q1:超小型汽車級DC/DC模塊的卓越之選 在汽車電子和工業應用領域,對于電源模塊的需求愈發嚴苛,不僅要求高功率密度、可靠的隔離性能,還需要具備多種保護功能和良好的電磁兼容性。TI
京東關鍵詞搜索商品列表的Python實戰
" return url def _parse_page(self, html): """解析頁面,提取商品信息""" soup = BeautifulSoup(html, "html.parser
京東關鍵詞搜索商品列表的Python爬蟲實戰
京東關鍵詞搜索商品列表 Python 爬蟲實戰 你想要實現京東關鍵詞搜索商品的爬蟲,我會從 合規聲明、環境準備、頁面分析、代碼實現、反爬優化 五個方面展開,幫助你完成實戰項目。 一、前置聲明(重要
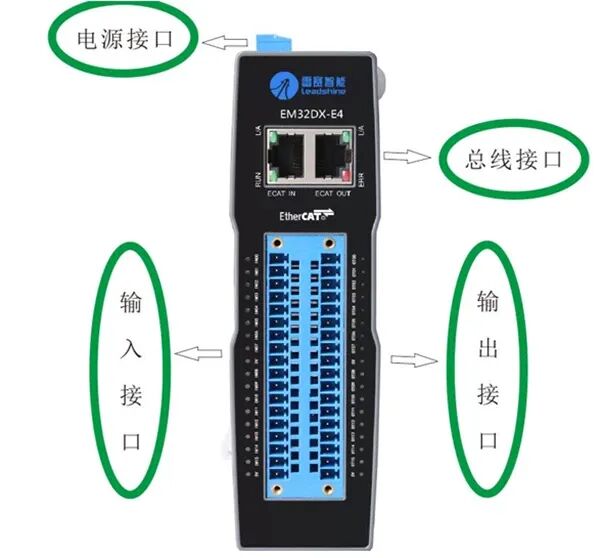
【睿擎派】EtherCAT總線之IO模塊讀寫
在上一篇文章《【睿擎派】CANOpen總線之IO模塊讀寫(DS401協議)》我寫了關于睿擎派上CANOpen的IO模塊通信,為什么先寫CANOpen?說來也有挺意思,是因為在睿擎派上對接
沒有專利的opencv-python 版本
所有 官方發布的 opencv-python 核心版本(無 contrib 擴展)都無專利風險——專利問題僅存在于 opencv-contrib-python 擴展模塊中的少數算法(如早期 SIFT
發表于 12-13 12:37
# 深度解析:爬蟲技術獲取淘寶商品詳情并封裝為API的全流程應用
需求。本文將深入探討如何借助爬蟲技術實現淘寶商品詳情的獲取,并將其高效封裝為API。 一、爬蟲技術核心原理與工具 1.1 爬蟲運行機制 網絡爬蟲本質上是一種遵循特定規則,自動抓取網頁信
用 Python 給 Amazon 做“全身 CT”——可量產、可擴展的商品詳情爬蟲實戰
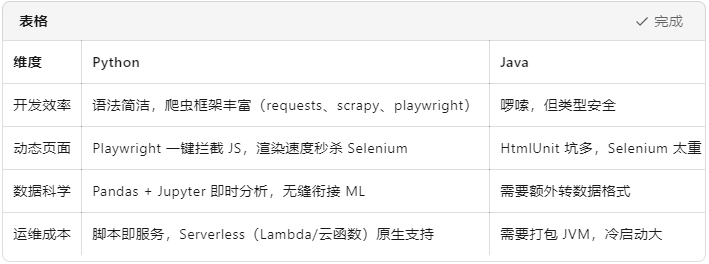
一、技術選型:為什么選 Python 而不是 Java? 結論: “調研階段用 Python,上線后如果 QPS 爆表再考慮 Java 重構。” 二、整體架構速覽(3 分鐘看懂) 三、開發前準備(5
從 0 到 1:用 PHP 爬蟲優雅地拿下京東商品詳情
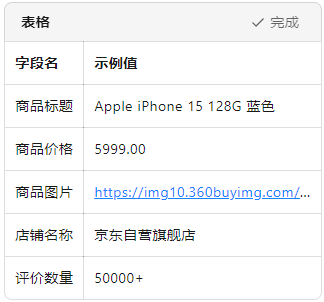
PHP 語言 實現一個 可運行的京東商品爬蟲 ,不僅能抓取商品標題、價格、圖片、評價數,還能應對常見的反爬策略。全文附完整代碼, 復制粘貼即可運行 。 一、為什么選擇 PHP 做爬蟲? 雖然 Python 是
Nginx限流與防爬蟲配置方案
在互聯網業務快速發展的今天,網站面臨著各種流量沖擊和惡意爬蟲的威脅。作為運維工程師,我們需要在保證正常用戶訪問的同時,有效防范惡意流量和爬蟲攻擊。本文將深入探討基于Nginx的限流與防爬蟲解決方案,從原理到實踐,為大家提供一套完
termux如何搭建python游戲
termux如何搭建python游戲
Termux搭建Python游戲開發環境的完整指南
一、Termux基礎環境準備
Termux是一款無需root即可在安卓設備上運行的Linux終端
發表于 08-29 07:06
python app不能運行怎么解決?
;python_agent[1241]: xmlrpc request method supervisor.stopProcess failed;python_agent[1241]: xmlrpc request method supervisor.stopProces
發表于 08-06 06:27
夢之墨電能檢測模塊在教學場景中的應用
工程訓練中心的電工電子實驗室里,學生們正圍著一臺風能發電裝置進行調試。他們手中的黑色小方盒正實時顯示著電流以及電壓的波動數據--這是夢之墨電能檢測模塊在教學場景中的應用。夢之墨自主研發并推出的電能檢測

?如何在虛擬環境中使用 Python,提升你的開發體驗~
RaspberryPiOS預裝了Python,你需要使用其虛擬環境來安裝包。今天出版的最新一期《TheMagPi》雜志刊登了我們文檔負責人NateContino撰寫的一篇實用教程,幫助你入門

零基礎入門:如何在樹莓派上編寫和運行Python程序?
在這篇文章中,我將為你簡要介紹Python程序是什么、Python程序可以用來做什么,以及如何在RaspberryPi上編寫和運行一個簡單的Python程序。什么是Python程序?
爬蟲數據獲取實戰指南:從入門到高效采集
爬蟲數據獲取實戰指南:從入門到高效采集 ? ? 在數字化浪潮中,數據已成為驅動商業增長的核心引擎。無論是市場趨勢洞察、競品動態追蹤,還是用戶行為分析,爬蟲技術都能助你快速捕獲目標信息。然而,如何既



 工商網監
工商網監
評論