") 針對設(shè)備上使用的Voice Filter的更新
針對設(shè)備上使用的Voice Filter的更新

語音輔助技術(shù)使用戶能夠使用語音命令與他們的設(shè)備進(jìn)行交互,并且依靠準(zhǔn)確的語音識別來確保對特定用戶的響應(yīng)。但是在許多實際的使用案例中,這類技術(shù)的輸入一般由重疊的語音組成,這給許多語音識別算法帶來了巨大的挑戰(zhàn)。
2018年,我們推出了VoiceFilter系統(tǒng),該系統(tǒng)利用了谷歌的Voice Match,通過允許用戶注冊和登記自己的語音,實現(xiàn)與輔助技術(shù)的個性化交互。
雖然VoiceFiltr的方法很成功,并且實現(xiàn)了比傳統(tǒng)方法更好的信噪比(SDR),但高效的設(shè)備上流媒體語音識別需要解決模型大小、CPU、內(nèi)存限制和電池使用注意事項和延遲最小化等的限制。
在“Voice Filter-lite方面:針對面向設(shè)備上語音識別的流媒體目標(biāo)語音分離”中,我們推出了針對設(shè)備上使用的Voice Filter的更新,該更新可以通過利用選定發(fā)言人的注冊語音來達(dá)到顯著提高和改善重疊語音的語音識別。重要的是,該模型可以很容易地與現(xiàn)有的設(shè)備語音識別應(yīng)用程序集成,允許用戶在極其嘈雜的條件下訪問語音輔助功能,即使互聯(lián)網(wǎng)連接不可用。我們的實驗表明,一個2.2MB的voice filer-lite模型在重疊語音上可以使誤詞率(WER) 改善25.1% 。
改進(jìn)設(shè)備上的語音識別
雖然最初的VoiceFilter系統(tǒng)非常成功地將目標(biāo)發(fā)言人的語音信號從其他重疊的信號源中分離出來,但它的模型大小、計算成本和延遲,對于移動設(shè)備上的語音識別是不可行的。
新的Voice Filter-Lite系統(tǒng)經(jīng)過精心設(shè)計,與設(shè)備上的應(yīng)用程序相適應(yīng)。Voice Filter-Lite不需要處理音頻波形,而是采用與語音識別模型完全相同的輸入特征功能(stacked log Mel-filterbanks堆疊的對數(shù)Mel濾波器組) , 并通過實時過濾掉不屬于目標(biāo)說話者的組成部分來直接增強(qiáng)這些特征。加上對網(wǎng)絡(luò)拓?fù)涞亩囗梼?yōu)化,運(yùn)行時操作的數(shù)量大大減少。在使用Tensor Flow Lite庫對神經(jīng)網(wǎng)絡(luò)進(jìn)行量化后,模型大小只有2.2MB,適合大多數(shù)設(shè)備上的應(yīng)用程序。
為了訓(xùn)練Voice Filter-Lite模型,將帶噪聲語音的濾波器組與代表目標(biāo)發(fā)言人身份的嵌入向量(i.e.ad-vector d矢量)一起被輸進(jìn)網(wǎng)絡(luò)。該網(wǎng)絡(luò)預(yù)測了一個掩碼,將其與輸入逐元素相乘,從而產(chǎn)生增強(qiáng)的過濾庫。在訓(xùn)練過程中,我們定義了一個損失函數(shù)來最小化增強(qiáng)濾波器組和干凈語音的濾波器組之間的差異。
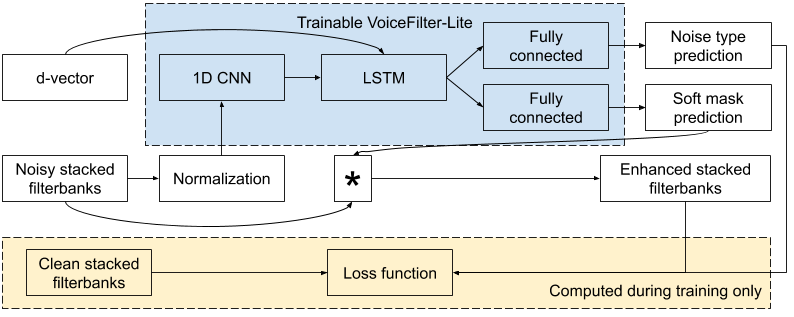
Voice Fliter-Lite系統(tǒng)的模型架構(gòu)
Voice Filter-Lite是一種即插即用的模型,它允許實如果說話者沒有登記他們的聲音,那么實現(xiàn)它的應(yīng)用程序可以輕松地繞過它。這也意味著語音識別模型和Voice Filer-Lite模型可以分別進(jìn)行訓(xùn)練和更新,這在很大程度上降低了部署過程中的工程復(fù)雜性。

作為即插即用模型,如果發(fā)言人沒有注冊他們的聲音,Voice Fliter-Lite可以很輕易地被忽略。
應(yīng)對過度抑制的挑戰(zhàn)
當(dāng)使用語音分離模型來改進(jìn)語音識別時,可能會出現(xiàn)兩種類型的錯誤:抑制不足,即模型無法濾除信號中的噪聲成分;以及過度抑制,當(dāng)模型不能保留有用的信號時,導(dǎo)致一些單詞從識別的文本中丟失。過度抑制問題尤其嚴(yán)重,因為現(xiàn)代語音識別模型通常已經(jīng)使用大量的增強(qiáng)數(shù)據(jù)(如房間模擬和SpecAugment) 進(jìn)行訓(xùn)練,因此對抑制不足更有魯棒性。
Voice Filter-Lite通過兩種新方法解決了過度抑制的問題。首先,它在訓(xùn)練過程中使用了非對稱性損失,使得模型對過度抑制的容忍度低于抑制不足的。其次,它對運(yùn)行時的噪聲類型進(jìn)行預(yù)測,并根據(jù)預(yù)測結(jié)果自適應(yīng)地調(diào)整抑制強(qiáng)度。
當(dāng)檢測重疊語音時,Voice Filter-Lite自適應(yīng)地應(yīng)用更強(qiáng)的抑制強(qiáng)度。
通過這兩種解決方案,Voice Filter-Lite模型在其他場景(如安靜或各種噪聲條件下的單揚(yáng)聲器語音)的流媒體語音識別方面保持了出色的性能,同時在重疊語音方面仍然提供了顯著的改進(jìn)。從我們的實驗中,我們觀察到將2.2MB Voice Filter-Lite模型應(yīng)用于附加性重疊語音后,單詞錯誤率改善了25.1%。對于混響重疊語音,模擬遠(yuǎn)場設(shè)備(如智能家庭揚(yáng)聲器)是一項更具挑戰(zhàn)性的任務(wù), 我們還觀察到使用Voice Filter-Lite可以改善14.7%的單詞錯誤率。
未來的工作
雖然Voice-Filter Lite在各種設(shè)備語音應(yīng)用程序中顯示出了巨大的潛力,但我們也在探索其他幾個方向,以使Voice-Filter Lite更有用。首先,我們目前的模型只用英語語音進(jìn)行訓(xùn)練和評估。我們很高興能夠采用同樣的技術(shù)來改進(jìn)更多語言的語音識別。其次,我們想在訓(xùn)練Voice Filter-Lite的過程中直接優(yōu)化語音識別損失,這可能會進(jìn)一步提高語音識別,而不僅僅是重疊語音。
感謝
本文所描述的研究代表了谷歌中多個團(tuán)隊的共同努力。貢獻(xiàn)者包括Quan Wang, Ignacio Lopez Moreno, Mert Saglam, Kevin Wilson, Alan Chiao, Renjie Liu, Yanzhang He, Wei Li, Jason Pelecanos, Philip Chao, Sinan Akay, John Han, Stephen Wu, Hannah Muckenhirn, Ye Jia, Zelin Wu, Yiteng Huang, Marily Nika, Jaclyn Konzelmann, Nino Tasca, and Alexander Gruenstein.Share on Twitter Share on Facebook在Twitter上的分享,在Facebook上的分享。
責(zé)任編輯:lq
-
流媒體
+關(guān)注
關(guān)注
1文章
200瀏覽量
17192 -
語音識別
+關(guān)注
關(guān)注
39文章
1812瀏覽量
116058 -
應(yīng)用程序
+關(guān)注
關(guān)注
38文章
3344瀏覽量
60262
原文標(biāo)題:使用VoiceFliter-Lite改進(jìn)設(shè)備上的語音識別
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
ulog_tag_lvl_filter_set()函數(shù)無法實現(xiàn)按照文檔說明那樣實現(xiàn)按模塊過濾,怎么解決?
電能質(zhì)量在線監(jiān)測裝置認(rèn)證標(biāo)準(zhǔn)的更新頻率是怎樣的?

請問新唐提供的ISP代碼(USB接口)如何判斷開機(jī)后是否需要ISP更新程序?
SM[HW]:CLOCK:PLL_GLITCH_FILTER 是否需要由SW激活?
HOLTEK發(fā)布HT68RV036 Voice OTP MCU
Android 16更新亮點介紹
請問刪除“wiced_voice_path.a”并繼續(xù)開發(fā) HFP 和 A2DP 功能可以接受嗎?
工廠設(shè)備更新時會遇到哪些問題?如何解決?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論