 算法的迭代:從傳統CTR預估到LTR
算法的迭代:從傳統CTR預估到LTR

前言
在當今互聯網世界,推薦系統在內容分發領域扮演著至關重要的角色。如何盡可能的提升推薦系統的推薦效果,是每個推薦算法同學工作的核心目標。在愛奇藝海外推薦業務,引入 TensorFlow Ranking (TFR) 框架,并在此基礎上進行了研究和改進,顯著提升了推薦效果。本文將分享 TFR 框架在海外推薦業務中的實踐和應用。
01 算法的迭代:從傳統 CTR 預估到 LTR
長期以來,在推薦系統排序階段廣泛應用的 CTR 預估算法的研究重點在于,如何更加準確的估計一個用戶對于一個 item 的點擊概率。在這類算法中,我們將一組同時曝光在用戶面前的 items,當做一個一個單獨的個例看待,將用戶的特征、環境特征和一個一個 item 的特征分別組合成為一條條訓練數據,將用戶對這個 item 的反饋(點擊、未點擊、播放時長等)作為訓練數據的標簽。這樣看似合理的問題抽象其實并不能準確的表征推薦場景。
嚴格來講,排序問題的本質(尤其是以瀑布流形式呈現的業務)并不是研究估計一個用戶對于一個單獨的 item 的點擊概率,而是研究在一組 items 同時曝光的情況下,用戶對這組 items 中哪個的點擊概率更大的問題。
Learning-To-Rank (LTR) 算法正是為解決這個問題而出現的。LTR 算法在訓練時采用 pairwise 或者 listwise 的方式組織訓練數據,將一組同時曝光在用戶面前的 items,兩兩 (pairwise) 或者多個 (listwise) items 和用戶特征環境特征共同組成數據對,作為一條條的訓練數據。相應的,在評估模型的指標上,LTR 算法更多采用 NDCG、ARP、MAP 等能夠反映 items 順序影響的指標。
同時,由于 LTR 算法的這種訓練數據組織形式,使得這類算法在用戶量相對不大的場景下,更容易取得比較好的效果。同樣得益于這種數據組織形式,也很方便的實現更好的負樣本采樣。
注:關于推薦業務中采樣和模型評估指標之間還有一個有趣的研究可以參考,2020 KDD Best Paper Award ,On Sampled Metrics for Item Recommendation
02 框架的設計:TensorFlow Ranking
TensorFlow Ranking (TFR) 是 TensorFlow 官方開發的 LTR 框架,旨在基于 TensorFlow 開發和整合 LTR 相關的技術,使開發人員可以更加方便的進行 LTR 算法的開發。
在實際使用過程中,可以體會到 TFR 框架為我們帶來的收益。框架內抽象出了訓練中不同層級的類,并開發了相關的 loss 函數,以方便我們進行 pairwise 和 listwise 的訓練,同時整合了 arp、ndcg 等模型評估的 metrics,再結合 TensorFlow 高階 api (Estimator),可以非常方便快捷的進行開發,而不用掙扎于各種實施上的細節。
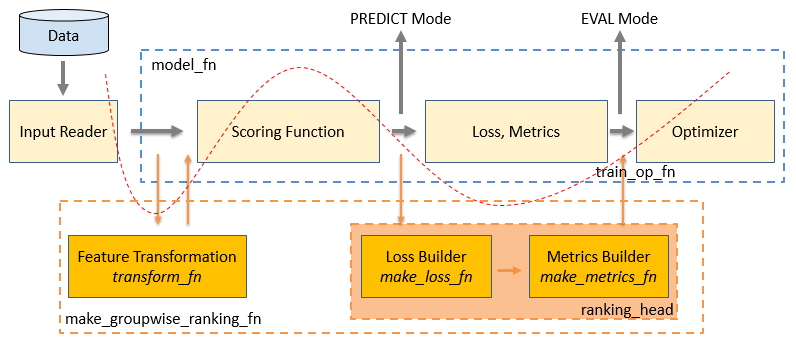
如上圖所示,藍色框圖中是在使用 TensorFlow Estimator 時,model_fn 參數內需要自己設計和開發的算法模型模塊。在這個 model_fn 中,需要自行設計模型結構 (Scoring Function),然后用模型計算的 logit 和 label 來計算 Loss 和 Metrics,最后利用 Optimizer 來進行模型的優化。圖中,紅色虛曲線下方的部分為使用 TFR 框架的整個流程。
從圖中可以看出,其實 TFR 框架主要是做了兩方面的工作:
把原有 model_fn 中 Scoring Function 和 Loss、Metrics 的計算進行了拆分,然后將原有流程中我們自行實現的 Loss 和 Metrics 替換為 TFR 框架中的 LTR 相關的 Loss 和 Metrics。
為了配合 TFR 框架中的 LTR 相關的 Loss 和 Metrics 來實現 LTR 的訓練,訓練數據需要以 listwise 的形式組織。但由于需要使用原有 model_fn 中 Scoring Function,在數據輸入的部分通過 LTR 框架中的數據轉換函數來對模型輸入的訓練數據進行轉化,使得以 listwise 形式組織的數據能夠利用 Scoring Function 來計算 logit。
所以,在 TFR 框架中,從數據到模型訓練完整的流程是:訓練數據-->用戶定義 feature_columns-->transform_fn 特征轉換-->Scoring Function 計算 score-->ranking_head 的 loss_fn 計算 loss–->ranking_head 的 eval_metric_fns 計算評價指標–->optimizer 進行優化。
從使用層面看,TFR 框架就是做了上面兩件事,看起來似乎并不復雜。但是從框架開發的角度上看,為了實現上述流程,TFR 框架內在 losses.py 和 metrics.py 中開發了多個 LTR 相關的 Loss 和 Metrics,在 data.py 內實現了讀取和解析以 listwise 形式組織數據的 tfrecords 文件的工具,還在 feature.py 中開發了兼容 TensorFlow 特征轉換函數的特征處理工具。最后通過 head.py 和 model.py 中的類對上述功能進行了層層封窗和抽象,并與 TensorFlow Estimator 很好的結合起來。
具體一些來看,代碼組織上,TFR 框架主要這樣實現的:
第一:
tfr 通過 tfr.model.make_groupwise_ranking_fn 來對 Estimator 的 model_fn 進行了整體的封裝。我們原有的基于 TensorFlow 的開發,在 Estimator 的 model_fn 這個參數內需要定義包括 Loss、Metrics 在內的完整的模型函數,但是在tfr這里就不需要了,make_groupwise_ranking_fn 會整體返回一個 Estimator 接收的 model_fn。
第二:
tfr.model.make_groupwise_ranking_fn 函數的第一個參數 group_score_fn,這里是需要傳入我們設計和開發的模型結構 (Scoring Function),但是這個模型是之前我們提到的,只需要計算出 logit 的模型。
第三:
tfr.model.make_groupwise_ranking_fn 函數的第三個參數 transform_fn,對應調用 feature.py 中開發了兼容 TensorFlow 特征轉換函數來對以 listwise 形式組織的數據(由 data.py 中的工具讀取進來的 Dataset)進行轉換,確保輸入 Scoring Function 的數據格式正確。
第四:
tfr.model.make_groupwise_ranking_fn 函數的第四個參數 ranking_head,對應調用了 tfr.head.create_ranking_head 函數,里面的三個參數分別定義了 loss、metrics 和 optimizer。loss 和 metrics 分別從 TFR 的 losses.py 和 metrics.py 中選擇我們需要的,而 optimizer 還是使用 TensorFlow 中的 optimizer。
以上就是 TFR 框架的整體架構,其實這個框架整體設計和代碼實現,還是非常優雅和巧妙的。
03 遇到的問題和實踐
TFR 框架的精巧設計和實現解決了我們基于 TensorFlow 做 LTR 算法中的 80% 到 90% 的問題。但是作為一個 2019 年才發布第一個版本的框架,TFR 還是存在一些待優化的地方。
在分享 TFR 框架上的實踐前,首先介紹一下 TFR 框架的版本情況,目前 TFR 框架發布的版本中,0.1.x 版本支持 TensorFlow 1.X 版本,而 0.2.x 和 0.3.x 版本都只支持 TensorFlow 2.X 版本。考慮到 TensorFlow 2.X 版本還存在一些不確定性(如前段時間爆出使用 Keras 功能 API 創建的模型自定義層中的權重無法進行梯度更新的問題。
(https://github.com/tensorflow/tensorflow/issues/40638),目前大量的算法開發人員其實還在用 TensorFlow 1.X 版本。我們目前也在使用 TensorFlow 1.X 版本,所以本文介紹的內容,描述的問題和給出的解決方案,都是基于 TensorFlow 1.14 版本,對應最新的 TFR 0.1.6 版本。
我們最開始使用 TFR 框架是 2019 年年中的時候,當時 TFR 框架的最新版本是 0.1.3。在使用的過程中,我們發現這個版本無法支持 sparse/embedding features。但是推薦的特征中,稀疏特征是不可或缺的一部分,并且可能大部分特征都是稀疏的,所以我們不得不放棄使用。但是很快,在稍后發布的 0.1.4 版本中這個問題就得到了解決。
我們正式開始使用 TFR 框架是從 0.1.4 版本開始的。但是到目前最新的 0.1.6 版本,還是有兩個我們不得不用的特性還是沒有在 TFR 0.1.x 版本上得到支持:
訓練過程中無法實施正則化
如前所述,TFR 框架通過 make_groupwise_ranking_fn 來對 Estimator 的 model_fn 進行了整體的封裝。
我們自己設計和開發的模型 (Scoring Function),定義了網絡,輸入輸出節點,最后只需要輸出一個 logit。這個和傳統 TensorFlow Estimator 下 model_fn 模型開發不一樣,傳統的模型不僅僅要輸出一個 logit,模型里面還需要定義如何計算 loss,怎樣優化等內容。但是 TFR 框架將這部分內容已經進行了封裝和整合,所以這里的 score_fn 就不需要這些了。這就帶來一個問題,原來的模型設計中,我們可以直接拿出網絡中需要正則化的參數,放在 loss 的計算中進行優化就可以了。但是使用 TFR 框架后,由于模型的設計和正向的計算在我們自己設計的模型函數中,而 loss 的計算在 TFR 框架內(ranking_head 中的 loss_fn)進行,這樣就沒辦法加入正則化項了。
已經有人提出了這個issue(https://github.com/tensorflow/ranking/issues/52),但是也沒有很好的解決方案。
當我們使用比較復雜的網絡時,正則化是我們優化過程中必不可少的一環。不加入正則化項進行優化,將無法避免的陷入到嚴重的過擬合中,如下圖所示:
為了能夠方便的利用 TFR 框架其他功能,我們深入 TFR 框架源碼中試圖解決正則化問題。正如上面分析,TFR 框架無法實施正則化的原因在于,模型 (Scoring Function) 是我們自己設計和開發的,但是 loss 的計算是 TFR 框架幫我們封裝好的。所以解決這個問題的核心就是如何在我們自己開發的模型中取出需要正則化的參數并傳遞給 TFR 框架中計算 loss 的部分就可以了。在 TFR 框架中,我們的模型計算好的 logit,是通過 ranking_head 的 create_estimator_spec 方法,把 logit,labels 與 TFR 框架中定義的 loss 函數整合一起,來完成整個優化過程的。而在 0.1.5 版本的 TFR 框架中,這個 create_estimator_spec 方法其實已經支持傳入 regularization_losses 了(估計未來版本一定會支持),而由于初始化 ranking_model 對象(我們的 Scoring Function)。
GroupwiseRankingModel 不支持我們拿到自己模型的正則化項,所以才無法實現。
理論上,只要我們重寫 TFR 源碼中 _GroupwiseRankingModel 類的 compute_logits 方法,就能夠讓 TFR 支持正則化了。具體的代碼上如何處理可以參考這里(如何解決 TensorFlow Ranking 框架中的正則化問題)。在加入正則化項后,跟上圖同樣的模型訓練時就沒有那么嚴重的過擬合現象了:
特征輸入不支持 Sequence Features
前邊介紹過,在 TFR 框架中,模型輸入的特征分為 context_features 和 example_features,分別對應于一次請求公共的特征(上下文特征、用戶特征等)和 item 獨有的特征。以 listwise 形式組織的數據(一般是由 data.py 中的工具讀取 tfrecords 文件生成的 Dataset)需要經過 TFR 的特征轉換函數 (_transform_fn) 轉換后,再送入到我們的模型 (Scoring Function) 中。
而目前的特征轉換函數 (_transform_fn) 只支持 numeric_column、categorical_column 等經典類型特征的轉換,尚不支持 sequence_categorical_column 類型特征的轉換。要解決的 TFR 無法支持 SequenceFeatures 問題,主要是對 transform_fn 特征轉換這一步進行調整。
在 transform_fn 中,特征轉換時用到的 tfr.feature.encode_listwise_features 和 tfr.feature.encode_pointwise_features 函數都在 feature.py 中定義。
這兩個函數的作用是在 listwise 或者 pointwise 模式下利用用戶定義的 feature columns 生成輸入模型的 dense tensors。這兩個函數都是調用 encode_features 函數來具體執行 feature columns 生成輸入模型的 dense tensors,而 encode_features 函數只支持 numeric_column、categorical_column 等經典類型特征的轉換,尚不支持 sequence_categorical_column 類型特征的轉換。通過這里的分析,我們可以看到特征轉換的過程全部是在 feature.py 中完成的,因此,解決 TFR 框架支持 SequenceFeatures 的問題核心思路就是修改 feature.py 中的幾個涉及特征轉換的函數,使這些函數能夠實現 sequence_categorical_column 類型特征的轉換。
我們用到的 sequence_categorical_column 類型特征都在 context_features 中,所以我們的思路是,在處理特征的轉換時,我先將 sequence_categorical_column 從其中拿出來,處理完經典特征的轉換后,單獨增加一段處理 sequence_categorical_column 轉換的代碼。待轉換完成后,再合并回 context_features 中,最終仍然保持 context_features 和 example_features 兩部分輸入到模型中。具體的代碼上如何處理可以參考這里。(讓 TensorFlow Ranking 框架支持 SequenceFeatures)
以上兩個問題的解決方案都涉及到 TFR 框架對源碼的修改。稍有不慎很容易引起穩定性兼容性問題以及意想不到的 bug。為了盡量保障代碼的穩定可靠,我們主要考慮了兩個主要的代碼組織原則:
第一,盡量縮小代碼改動的范圍,所有的改動都在盡可能少的幾個函數內完成,不涉及 TFR 框架的其他模塊代碼。
第二,對于不涉及上述兩個問題的項目要做到完全的兼容。對于不使用 feature columns 的項目或者不使用正則化(應該很少),保證原有邏輯和計算結果不變。
04 實驗:LTR 模型和原生模型的效果對比
究竟 TFR 框架訓練的 LTR 排序模型對比同樣網絡結構的原生模型,能夠帶來多大的效果提升呢,我們也專門做了線上實驗來分析。選取了一個業務場景,取出三個流量組分別做以下模型:
BaseB:沒有排序服務,為每個召回渠道配置優先級,系統按照優先級給出推薦結果。
Ranking:TensorFlow 原生 Estimator 開發的排序算法。
TfrRankingB:基于TFR框架開發的 LTR 排序算法。
其中,TfrRankingB 相比較于 Ranking,模型結構完全一致,也就是采用同一個 Scoring Function,訓練數據集也完全一致。但是由于 TfrRankingB 采用 TFR 框架訓練的 LTR 模型,模型優化上有以下幾處不同:

以上的幾處不同是模型訓練方式和評估指標上的不同,這也正是采用 TFR 框架帶給我們的。而訓練數據和模型本身,包括正則化項在內,TfrRankingB 和 Ranking 是完全一樣。兩個模型訓練后,與 BaseB 一起在線上真實流量環境下測試完整 4 天,其中 day_1 和 day_2 為平日,day_3 和 day_4 是休息日。線上實驗考查用戶的 CTR(點擊率)、UCTR(用戶點擊率)和 LPLAY(長播放占比),效果如下:


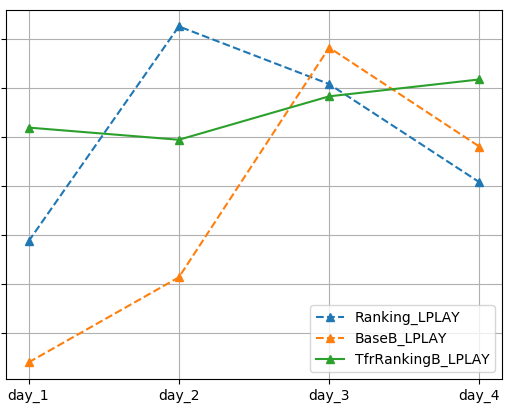
考慮到業務保密性,我們對橫縱坐標的具體取值不做展示。但是結論顯而易見:
在 CTR 和 UCTR 指標上,TfrRankingB 顯著優于 Ranking,Ranking 顯著優于 BaseB。
在 LPLAY 指標上,TfrRankingB 優于 Ranking,Ranking 優于 BaseB。
總結
使用 TFR 框架后,可以非常方便的基于 TensorFlow 開發 LTR 模型或者將現有模型改造為 LTR 模型。同時,TFR 框架的模塊設計、代碼邏輯都非常巧妙,諸如高內聚低耦合等大家常常掛在嘴邊的規范也實實在在的落在了代碼上。在接下來的工作中,逐步將現有的 TensorFlow 1.X 版本升級到 2.X 版本,并觀察 TFR 框架對 TensorFlow 2.X 的支持情況。
責任編輯:lq
-
算法
+關注
關注
23文章
4784瀏覽量
98048 -
CTR
+關注
關注
0文章
39瀏覽量
14523 -
tensorflow
+關注
關注
13文章
334瀏覽量
62178
原文標題:案例分享 | TensorFlow Ranking 框架在愛奇藝海外推薦業務中的實踐與應用
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
XENSIV? BGT60LTR11AIP Radar Shield2Go:超小型低功耗雷達傳感器的應用與配置
探索XENSIV? 60 GHz雷達參考板REF_BGT60LTR11AIP_M0:從原理到實踐
SM4算法實現分享(一)算法原理
AES加解密算法邏輯實現及其在蜂鳥E203SoC上的應用介紹
如何使用恢復算法來實現開平方運算
e203除法器算法改進(二)
自主工具鏈助力端到端組合輔助駕駛算法驗證
突破傳統桎梏,PPEC Workbench 開啟電源智能化設計新路徑
光耦的CTR是什么?
從防爆PDA終端看工業移動設備:如何平衡安全與功能迭代?

光耦的電流傳輸比CTR是什么?
經緯恒潤端到端組合輔助駕駛算法測試解決方案



 工商網監
工商網監
評論