 AI下個大突破之前奏:研究人員正在教大型語言模型
AI下個大突破之前奏:研究人員正在教大型語言模型

GPT-3 自動生成的語言竟然能和人類差不多,堪稱奇跡。但在很大程度上,GPT-3 也不過是個噱頭。判斷方法也很簡單。若提問 GPT-3:羊是什么顏色?它會說 “白色 ”,還會說 “黑色 ”, 頻次一樣高。因為英語里有 “black sheep”(黑羊,引申意為害群之馬)。
這就是語言模型的問題。只用文本訓練語言模型,會導致模型缺乏常識。不過,為了改變這種狀況,北卡羅來納大學教堂山分校(下文簡稱 UNC)的學者莫希特?班薩爾和其博士生譚昊研發了一種新技術,研究人員稱其為為 “視覺監督(vokenization)”,如此,GPT-3 等語言模型便能具備 “看 ” 的功能。
將語言模型與計算機視覺結合起來并不新鮮,該人工智能研究領域其實正在快速發展。出發點是這兩種類型都有不同的優勢。GPT-3 等語言模型通過無監督學習來訓練,不需要人工進行數據標注,因此很容易開發出大型模型。而物體識別系統等圖像模型更多是在現實世界中學習。換句話說,圖像模型并不依賴文本所提供的抽象世界來理解世界。比如,圖像模型可以從羊的圖片中 “看到”,羊其實是白色的。
能夠同時解析語言和視覺輸入的人工智能模型用處很大。例如,機器人需要計算機視覺來導航,也需要語言來與人類交流,因此該模型能用于開發機器人。
但要結合這兩種類型,是說起來容易做起來難。并非把現有的語言模型與物體識別系統拼接在一起便大功告成,而是需要從頭開始訓練新模型。所用數據集要包括文本和圖像,也就是所謂的視覺語言數據集。
要獲得這樣一個數據集,最常見的方法是做帶有描述性標題的圖片集。例如,下面這張圖片的標題設為 “一只橘貓臥在空行李箱里”。這樣的圖片集便和傳統圖片數據集不同。后者只用名詞來標注圖片,比如給下面這張圖片只簡單地命名為 “貓”。因此,視覺語言數據集不僅可以教人工智能模型如何識別對象,還可以教人工智能模型如何根據動詞和介詞識別不同對象之間的相互關系。
但如此也意味著,創建數據集會耗費很長時間。因此,現有的視覺語言數據集太單薄了。而常用的純文本數據集則不同。如英語維基百科,包括了幾乎所有英語維基百科條目,有近 30 億個單詞。而視覺語言數據集 Microsoft Common Objects in Context(下文簡稱 MS COCO)只包含 700 萬個,根本不足以訓練一個有用的 AI 模型。
有了視覺監督,問題迎刃而解。視覺監督使用無監督學習方法,將 MS COCO 的數據規模擴展到與英語維基百科相當。視覺語言模型用規模化后的數據集訓練后,研究人員使用了一些最難的 AI 語言理解能力測試對其進行檢驗。結果模型的表現甚至優于當今最先進的模型。
自然語言處理初創公司 Hugging Face 的聯合創始人兼首席科學官托馬斯?沃爾夫說:“要在這些測試中擊敗最先進的模型,得下大力氣。這些測試可不是兒戲。能有這樣的結果,真的讓人非常激動。”
我們先理清一些術語。到底什么是 “voken”?
在人工智能領域,用來訓練語言模型的詞稱為 token。UNC 研究人員便以 “voken”,來指代所用視覺語言模型中與任一 token 相關聯的圖像。用來匹配 token 和 voken 的算法稱為 vokenizer, 整個匹配過程稱為 “視覺監督”。
說了這么多,主要是為了幫助大家理解視覺監督的基本理念。UNC 研究人員沒有拿著圖像數據集來手動編寫標題,這耗時過長;他們選擇了使用語言數據集以及無監督學習法,匹配每個單詞與相關圖像。如此便很容易規模化。
此處的無監督學習技術正是此項研究的貢獻。那么,究竟如何為每個單詞找到關聯圖像呢?
視覺監督
先回到 GPT-3。GPT-3 所屬語言模型家族有 “變形金剛” 之稱。2017 年,該類模型首次面世,便是將無監督學習應用于自然語言處理取得的重大突破。變形金剛可以觀察單詞在上下文中的使用,再根據上下文創建每個單詞的數學表達式,即 “單詞嵌入”,以此來學習人類語言模式。例如,代表 “貓 ” 的嵌入可能會顯示,“喵 ” 和 “橙” 兩字周圍,“貓” 出現頻率高,但在 “吠 ” 或 “藍色 ” 周圍出現的頻率便較低。
因此,變形金剛猜單詞含義的準確度較高,GPT-3 也因此能寫出仿佛由人所作的句子。變形金剛一定程度上依靠這些嵌入,學習如何將單詞組成句子、句子組成段落。
還有一種類似技術也可以用于處理圖像。這種技術不是通過掃描文本來尋找單詞使用規律,而是通過掃描圖像來尋找視覺規律。比如,該技術將貓出現在床上與出現在樹上的頻率制成表格,并利用這些上下文信息創建 “貓” 的嵌入。
UNC 研究人員認為,處理 MS COCO 要同時使用這兩種嵌入技術。研究人員將圖像處理為視覺嵌入,將標題處理為文字嵌入。而這些嵌入妙就妙在能在三維空間中繪制出來,完全可以看到嵌入之間的關系。如果某一視覺嵌入與某一單詞嵌入密切相關,繪制出來后位置很接近。換句話說,理論上,代表貓的視覺嵌入應該與代表貓的文字嵌入重合。
之后的工作也就水到渠成。一旦嵌入都繪制完畢、并相互比較和關聯,就很容易開始匹配圖像(voken)與文字(token)。而且,由于圖像和單詞基于原嵌入進行匹配,那么實際也在基于上下文進行匹配。這樣,即便一個詞可能有多個不同含義也不必擔心,該技術能為單詞的每個含義找到對應 voken。
比如:
這是她的聯系方式 。 一些貓喜歡被人撫摸。
這兩個例子中的 token 都是 “contact” 一詞。但在第一個句子中,上下文表明 “contact” 是聯系的意思,所以 voken 是聯系圖標。在第二個句子中,上下文表明這個詞有觸摸的意思,所以 voken 顯示的是一只被撫摸的貓。
這些利用 MS COCO 創建的視覺和單詞嵌入,便用來訓練算法 vokenizer。
一旦經過訓練,vokenizer 就能夠在英語維基百科中找 token 的對應 voken。雖然該算法只為大約 40% 的 token 找到了 voken,并不完美,但英語維基百科可是有接近 30 億字。
有了新的數據集后,研究人員重新訓練了 BERT 語言模型。BERT 是谷歌開發的開源變形金剛,比 GPT-3 還要早。然后,研究人員使用六個語言理解測試,測試改進的 BERT。語言理解測試中有 SQuAD 斯坦福回答數據集,該測試要求模型回答基于文章的閱讀理解題;還有 SWAG 測試,該測試利用英語語言的精妙處,檢測模型是否只是單純模仿和記憶。改進的 BERT 在所有測試里表現都比原來更突出。沃爾夫說,這并不奇怪。
11 月 16 日到 18 日將舉辦自然語言處理實證方法會議。研究人員將在會議上展示視覺監督新技術。雖然研究還處于早期階段,但沃爾夫認為,從在視覺語言模型中利用無監督學習方面看,這項工作是一項重要觀念突破。當年,正是類似突破極大推動了自然語言處理的發展。
沃爾夫說:“在自然語言處理領域,兩年多前便有了這一巨大突破,然后突然間自然語言處理領域有了很大發展,開始走在其他 AI 領域前面。但是把文字和其他事物聯系起來還是有很大障礙。就像機器人只能說話,但不會看、不會聽。”
“這篇論文則做到了將文字與另一種模式連接起來,而且效果更好,樹立了典范。可以想象,如果要把這種非常強大的語言模型用到機器人上,也許能用到部分新技術。比如,用同樣的技術將機器人的感官和文本聯系起來。”
原文標題:AI下個大突破之前奏:研究人員正在教大型語言模型 “看” 世界,進而理解世界
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
機器視覺
+關注
關注
165文章
4799瀏覽量
126103 -
AI
+關注
關注
91文章
39866瀏覽量
301520 -
人工智能
+關注
關注
1817文章
50105瀏覽量
265551
原文標題:AI下個大突破之前奏:研究人員正在教大型語言模型 “看” 世界,進而理解世界
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型 ai coding 比較
在AI基礎設施中部署大語言模型的三大舉措

【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的科學應用
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+內容總覽
NVIDIA AI助力科學研究領域持續突破
【書籍評測活動NO.64】AI芯片,從過去走向未來:《AI芯片:科技探索與AGI愿景》
利用自壓縮實現大型語言模型高效縮減

無刷直流電機雙閉環串級控制系統仿真研究
中軟國際在大型銀行AI項目領域實現重大突破
小白學大模型:從零實現 LLM語言模型
研究人員開發出基于NVIDIA技術的AI模型用于檢測瘧疾
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
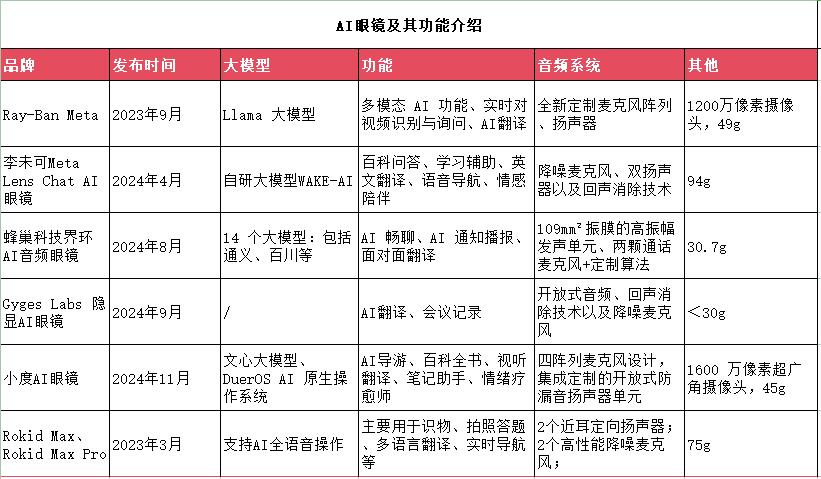
AI眼鏡大模型激戰:多大模型協同、交互時延低至1.3S



 工商網監
工商網監
評論