 最新測試:NVIDIA的安培GPU測試性能是最先進 CPU的237倍
最新測試:NVIDIA的安培GPU測試性能是最先進 CPU的237倍

MLPerf組織今天發布最新的推理基準測試(Benchmark)MLPerf Inference v0.7結果,總共有23個組織提交了結果,相比上一個版本(MLPerf Inference v0.5)的12個提交者增加了近一倍。
結果顯示,今年5月NVIDIA(Nvidia)發布的安培(Ampere)架構A100 Tensor Core GPU,在云端推理的基準測試性能是最先進Intel CPU的237倍。
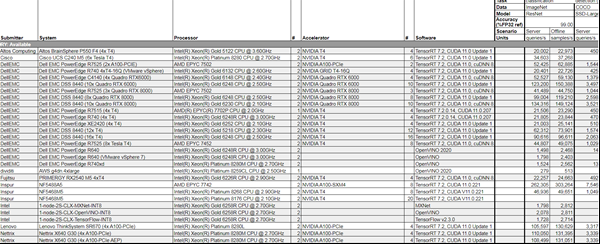
MLPerf Inference V0.7部分結果截圖
最新的AI推理測試結果意味著,NVIDIA未來可能在AI推理和訓練市場都占據領導地位,給云端AI推理市場擁有優勢的Intel帶來更大壓力的同時,也將讓其他追趕者面臨更大挑戰。
MLPerf推理基準測試進一步完善的價值
與2019年的MLPerf Inference v0.5版本相比,最新的0.7版本將測試從AI研究的核心視覺和語言的5項測試,擴展了到了包括推薦系統、自然語言理解、語音識別和醫療影像應用的6項測試,并且有分別針對云端和終端推理的測試,還加入了手機和筆記本電腦的結果。
擴展的測試項從MLPerf和業界兩個角度都有積極意義。
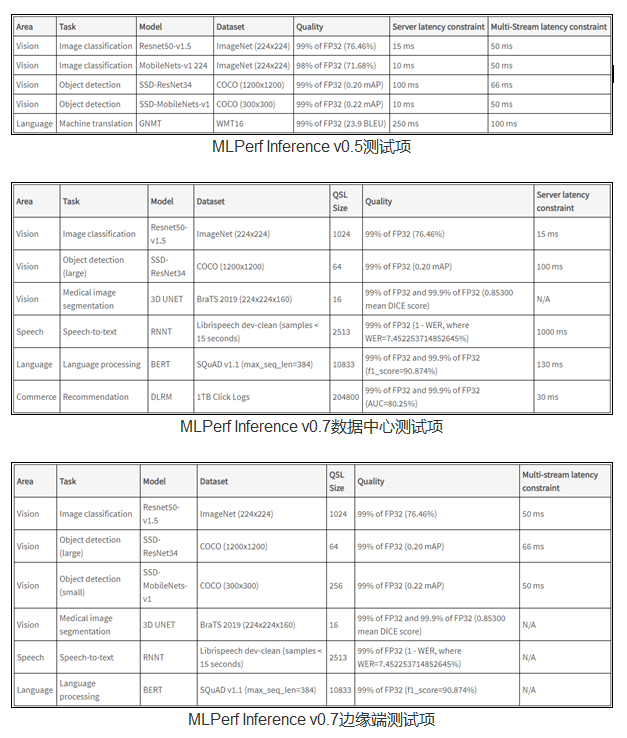
任何一個基準測試都需要給業界具有參考價值的指標。MLPerf基準測試是在業界缺乏對AI芯片公認的評價標準的2018年誕生,因此,MLPerf組織既需要給出各方都認可的成績,還需要根據AI行業的發展完善評價標準。
不過,AI行業發展迅速,AI模型的參數越來越多,應用的場景也越來越廣泛。評價AI芯片和系統的推理性能需要涵蓋可編程性、延遲、準確性、模型大小、吞吐量、能效等指標,也需要選擇更具指導價值的模型和應用。
此次增加的推薦系統測試對于互聯網公司意義重大。在王喆的《深度學習推薦系統》一書中提到,2019年天貓“雙11”的成交額是2684億元,假設推薦系統進行了優化,整體的轉化率提高1%,那么增加的成交額大約為26.84億元。
另外,MLPerf Inference v0.7中增加醫療影像3D U-Net模型測試與新冠大流行以及AI在醫療行業的重要性與日俱增密切相關,比如一家初創公司使用AI簡化了超聲心電圖的采集工作,在新冠大流行初期發揮了作用。
基準測試從v0.5到v0.7,能夠為要選用AI芯片和系統的公司提供更直觀和有價值的參考是MLPerf基準測試的價值所在,比如,幫助金融結構的會話式AI更快速回答客戶問題,幫助零售商使用AI保證貨架庫存充足。
與此同時,這也將促進MLPerf組織在業界的受認可程度,從接近翻倍的提交成績的組織就能看出來。
GPU云端推理性能最高是CPU的237倍
過去幾年,云端AI訓練市場NVIDIA擁有絕對優勢,云端AI推理市場被Intel賺取了大部分利潤是事實。這讓不少人都產生了GPU更適合訓練而CPU更適合推理的認知,但MLPerf最新的推理測試結果可能會改變這一觀點。
MLPerf Inference V0.7的測試結果顯示,在數據中心OFFLINE(離線)測試模式下,賽靈思U250和IntelCooper Lake在各個測試模型下與NVIDIAT4的差距不大,但A100對比CPU、FPGA和自家的T4就有明顯的性能差距。
在SERVER模式下的推薦系統DLRM模型下,A100 GPU對比IntelCooper Lake有最高237倍的性能差距,在其他模型下也有比較顯著的差距。值得注意的是,Intel的Cooper Lake系統的狀態還是預覽,其余三款芯片的系統都已經可用。
A100 GPU的優勢也在邊緣推理中也十分明顯。在單數據流(Singel-Stream)測試中,A100對比NVIDIAT4和面向邊緣終端的NVIDIAJetson AGX Xavier有幾倍到十幾倍的性能優勢。在多數據流(Multi-Stream)測試中,A100對比另外兩款自家產品在不同AI模型中有幾倍到二十多倍的性能優勢。
在邊緣OFFLINE模式下,A100對比T4和Jetson AGX Xavier也有幾倍到二十多倍的性能優勢。
這很好地說明A100的安培架構以及其第三代Tensor Core優勢的同時,也表明了NVIDIA能夠覆蓋整個AI推理市場。
在此次提交結果的23家公司中,除了NVIDIA外還有11家其合作伙伴提交了基于NVIDIA GPU的1029個測試結果,占數據中心和邊緣類別中參評測試結果總數的85%以上。
從提交結果的合作伙伴的系統中可以看到,NVIDIAT4仍然是企業的邊緣服務器推理平臺的主要選擇。A100提升到新高度的性能意味著未來企業邊緣服務器在選擇AI推理平臺的時候,可以從T4升級到A100,對于功耗受限的設備,可以選擇Jeston系列產品。
特別值得注意的是,NVIDIA GPU首次在公有云中實現了超越CPU的AI推理能力。
臨界點到來?AI推理芯片市場競爭門檻更高
五年前,只有少數領先的高科技公司使用GPU進行推理。如今,NVIDIAGPU首次在公有云市場實現超越CPU的AI推理能力,或許意味著AI推理市場臨界點的到來。NVIDIA還預測,基于其GPU的總體云端AI推理計算能力每兩年增長約10倍,增長速度高于CPU。
另外,NVIDIA還強調基于A100高性能系統的成本效益。NVIDIA表示,一套DGX A100系統可以提供相當于近1000臺雙插槽CPU服務器的性能,能為客戶AI推薦系統模型從研發走向生產的過程,具有極高的成本效益。
同時,NVIDIA也在不斷優化推理軟件堆棧,進一步提升在推理市場的競爭力。
最先感受到影響的會是Intel,但在云端AI推理市場體現出顯著變化至少需要幾年時間,因為企業在更換平臺的時候會更加謹慎,生態的護城河此時也更能體現出價值。
但無論如何,我們都看到NVIDIA在AI市場的強勢地位。雷鋒網七月底報道,在MLPerf發布的MLPerf Training v0.7基準測試中,A100 Tensor Core GPU,和HDR InfiniBand實現多個DGX A100 系統互聯的龐大集群DGX SuperPOD系統在性能上開創了八個全新里程碑,共打破16項紀錄。
安培架構A100在MLPerf最新的訓練和推理成績表明NVIDIA不僅給云端AI訓練的競爭者更大的壓力,也可能改變AI推理市場的格局。
NVIDIA將其在云端訓練市場的優勢進一步拓展到云端和邊緣推理市場符合AI未來的發展趨勢。有預測指出,隨著AI模型的成熟,市場對云端AI訓練需求的增速將會降低,云端AI推理的市場規模將會迅速增加,并有望在2022年超過訓練市場。
另據市場咨詢公司ABI Research的數據,預計到2025年,邊緣AI芯片市場收入將達到122億美元,云端AI芯片市場收入將達到119億美元,邊緣AI芯片市場將超過云端AI芯片市場。
憑借強大的軟硬件生態系統,NVIDIA和Intel依舊會是AI市場的重要玩家,只是隨著他們競爭力的不斷提升,其他參與AI市場競爭的AI芯片公司們面臨的壓力也隨之增加。
責編AJX
-
cpu
+關注
關注
68文章
11281瀏覽量
225080 -
NVIDIA
+關注
關注
14文章
5597瀏覽量
109785 -
gpu
+關注
關注
28文章
5196瀏覽量
135505
發布評論請先 登錄
借助NVIDIA CUDA Tile IR后端推進OpenAI Triton的GPU編程
先進封裝時代,芯片測試面臨哪些新挑戰?
NVIDIA RTX PRO 5000 Blackwell GPU的深度評測

NVIDIA RTX PRO 4000 Blackwell GPU性能測試

NVIDIA RTX PRO 2000 Blackwell GPU性能測試

NVIDIA RTX PRO 4500 Blackwell GPU測試分析

NVIDIA桌面GPU系列擴展新產品
NVIDIA Jetson AGX Thor開發者套件概述
PCIe協議分析儀能測試哪些設備?
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄




 工商網監
工商網監
評論