 4種常見的NLP實踐思路分析
4種常見的NLP實踐思路分析

越來越多的人選擇參加算法賽事,為了提升項目實踐能力,同時也希望能拿到好的成績增加履歷的豐富度。期望如此美好,現實卻是:看完賽題,一點思路都木有。那么,當我們拿到一個算法賽題后,如何破題,如何找到可能的解題思路呢。
本文針對NLP項目給出了4種常見的解題思路,其中包含1種基于機器學習的思路和3種基于深度學習的思路。
一、數據及背景
https://tianchi.aliyun.com/competition/entrance/531810/information(阿里天池-零基礎入門NLP賽事)
二、數據下載及分析2.1 獲取數據
我們直接打開數據下載地址,看到的是這樣一個頁面:

接著就三步走:注冊報名下載數據,查看數據前五行可以看到我們獲得的數據如下:

其中左邊的label是數據集文本對應的標簽,而右邊的text則是編碼后的文本,文本對應的標簽列舉如下:

根據官方描述:賽題以匿名處理后的新聞數據為賽題數據,數據集報名后可見并可下載。賽題數據為新聞文本,并按照字符級別進行匿名處理。整合劃分出14個候選分類類別:財經、彩票、房產、股票、家居、教育、科技、社會、時尚、時政、體育、星座、游戲、娛樂的文本數據。 賽題數據由以下幾個部分構成:訓練集20w條樣本,測試集A包括5w條樣本,測試集B包括5w條樣本。為了預防選手人工標注測試集的情況,我們將比賽數據的文本按照字符級別進行了匿名處理。
同時我們還應該注意到官網有給出結果評價指標,我們也需要根據這個評價指標衡量我們的驗證集數據誤差:

既然該拿到的我們都拿到了,我們接下來就開始構思我們都應該使用哪些思路來完成我們的預測。
2.2 常見思路
賽題本質是一個文本分類問題,需要根據每句的字符進行分類。但賽題給出的數據是匿名化的,不能直接使用中文分詞等操作,這個是賽題的難點。
因此本次賽題的難點是需要對匿名字符進行建模,進而完成文本分類的過程。由于文本數據是一種典型的非結構化數據,因此可能涉及到特征提取和分類模型兩個部分。為了減低參賽難度,我們提供了一些解題思路供大家參考:
思路1:TF-IDF + 機器學習分類器:直接使用TF-IDF對文本提取特征,并使用分類器進行分類。在分類器的選擇上,可以使用SVM、LR、或者XGBoost。
思路2:FastText:FastText是入門款的詞向量,利用Facebook提供的FastText工具,可以快速構建出分類器。
思路3:WordVec + 深度學習分類器:WordVec是進階款的詞向量,并通過構建深度學習分類完成分類。深度學習分類的網絡結構可以選擇TextCNN、TextRNN或者BiLSTM。
思路4:Bert詞向量:Bert是高配款的詞向量,具有強大的建模學習能力。
三、基于機器學習的文本分類
3.1 TF-IDF+機器學習分類器(思路1)
3.1.1. 什么是TF-IDF?
TF-IDF(term frequency–inverse document frequency)是一種用于信息檢索與數據挖掘的常用加權技術,常用于挖掘文章中的關鍵詞,而且算法簡單高效,常被工業用于最開始的文本數據清洗。 TF-IDF有兩層意思,一層是"詞頻"(Term Frequency,縮寫為TF),另一層是"逆文檔頻率"(Inverse Document Frequency,縮寫為IDF)。
當有TF(詞頻)和IDF(逆文檔頻率)后,將這兩個詞相乘,就能得到一個詞的TF-IDF的值。某個詞在文章中的TF-IDF越大,那么一般而言這個詞在這篇文章的重要性會越高,所以通過計算文章中各個詞的TF-IDF,由大到小排序,排在最前面的幾個詞,就是該文章的關鍵詞。
3.2.2. TF-IDF算法步驟
第一步,計算詞頻:

考慮到文章有長短之分,為了便于不同文章的比較,進行"詞頻"標準化:

第二步,計算逆文檔頻率:
這時,需要一個語料庫(corpus),用來模擬語言的使用環境。
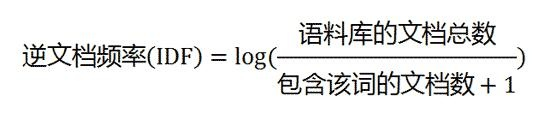
如果一個詞越常見,那么分母就越大,逆文檔頻率就越小越接近0。分母之所以要加1,是為了避免分母為0(即所有文檔都不包含該詞)。log表示對得到的值取對數。
第三步,計算TF-IDF:
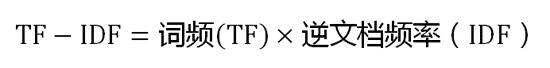
可以看到,TF-IDF與一個詞在文檔中的出現次數成正比,與該詞在整個語言中的出現次數成反比。所以,自動提取關鍵詞的算法就很清楚了,就是計算出文檔的每個詞的TF-IDF值,然后按降序排列,取排在最前面的幾個詞。
3.3.3. 優缺點
TF-IDF的優點是簡單快速,而且容易理解。缺點是有時候用詞頻來衡量文章中的一個詞的重要性不夠全面,有時候重要的詞出現的可能不夠多,而且這種計算無法體現位置信息,無法體現詞在上下文的重要性。如果要體現詞的上下文結構,那么你可能需要使用word2vec算法來支持。
四、基于深度學習的文本分類
4.1 FastText(思路2)
4.1.1 FastText的核心思想
將整篇文檔的詞及n-gram向量疊加平均得到文檔向量,然后使用文檔向量做softmax多分類。這中間涉及到兩個技巧:字符級N-gram特征的引入以及分層Softmax分類。
4.1.2字符級N-gram特征
N-gram是基于語言模型的算法,基本思想是將文本內容按照子節順序進行大小為N的窗口滑動操作,最終形成窗口為N的字節片段序列。舉個例子:
我來到達觀數據參觀
相應的bigram特征為:我來 來到 到達 達觀 觀數 數據 據參 參觀
相應的trigram特征為:我來到 來到達 到達觀 達觀數 觀數據 數據參 據參觀
注意一點:n-gram中的gram根據粒度不同,有不同的含義。它可以是字粒度,也可以是詞粒度的。上面所舉的例子屬于字粒度的n-gram,詞粒度的n-gram看下面例子:
我 來到 達觀數據 參觀
相應的bigram特征為:我/來到 來到/達觀數據 達觀數據/參觀
相應的trigram特征為:我/來到/達觀數據 來到/達觀數據/參觀
n-gram產生的特征只是作為文本特征的候選集,你后面可能會采用信息熵、卡方統計、IDF等文本特征選擇方式篩選出比較重要特征。
4.1.3 分層Softmax分類
softmax函數常在神經網絡輸出層充當激活函數,目的就是將輸出層的值歸一化到0-1區間,將神經元輸出構造成概率分布,主要就是起到將神經元輸出值進行歸一化的作用。
下圖是一個分層Softmax示例:
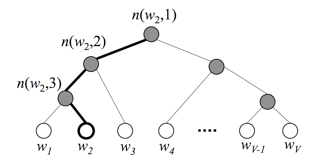
通過分層的Softmax,計算復雜度一下從|K|降低到log|K|。
4.2Word2Vec+深度學習分類器(思路3)
4.2.1 Word2Vec
Word2vec,是一群用來產生詞向量的相關模型。這些模型為淺而雙層的神經網絡,用來訓練以重新建構語言學之詞文本。網絡以詞表現,并且需猜測相鄰位置的輸入詞,在word2vec中詞袋模型假設下,詞的順序是不重要的。訓練完成之后,word2vec模型可用來映射每個詞到一個向量,可用來表示詞對詞之間的關系,該向量為神經網絡之隱藏層。【百度百科】
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的詞嵌入方法。
4.2.2 優化方法
為了提高速度,Word2vec 經常采用 2 種加速方式:
1、Negative Sample(負采樣)
2、Hierarchical Softmax
4.2.3 優缺點
優點:
由于 Word2vec 會考慮上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
比之前的 Embedding方 法維度更少,所以速度更快
通用性很強,可以用在各種 NLP 任務中
缺點:
由于詞和向量是一對一的關系,所以多義詞的問題無法解決。
Word2vec 是一種靜態的方式,雖然通用性強,但是無法針對特定任務做動態優化
4.3Bert詞向量(思路4)
BERT(Bidirectional Encoder Representations from Transformers)詞向量模型,2018年10月在《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》這篇論文中被Google提出,在11種不同nlp測試中創出最佳成績,包括將glue基準推至80.4%(絕對改進7.6%),multinli準確度達到86.7% (絕對改進率5.6%)等。
4.1.1 特征
1、通過聯合調節所有層中的左右上下文來預訓練深度雙向表示
2、the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many systems with task-specific architectures
3、所需計算量非常大。Jacob 說:「OpenAI 的 Transformer 有 12 層、768 個隱藏單元,他們使用 8 塊 P100 在 8 億詞量的數據集上訓練 40 個 Epoch 需要一個月,而 BERT-Large 模型有 24 層、2014 個隱藏單元,它們在有 33 億詞量的數據集上需要訓練 40 個 Epoch,因此在 8 塊 P100 上可能需要 1 年?16 Cloud TPU 已經是非常大的計算力了。
4、預訓練的BERT表示可以通過一個額外的輸出層進行微調,適用于廣泛任務的state-of-the-art模型的構建,比如問答任務和語言推理,無需針對具體任務做大幅架構修改。
-
nlp
+關注
關注
1文章
491瀏覽量
23322
原文標題:【特征提取+分類模型】4種常見的NLP實踐思路
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ChatGPT爆火背后,NLP呈爆發式增長!
可靠性失效分析常見思路
Altium常見4層板的設計思路
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

網絡維護與常見故障的分析與排除詳細資料分析
金融市場中的NLP 情感分析
幾個常見的EMI輻射問題分析思路資料下載

NLP類別不均衡問題之loss大集合
NLP類別不均衡問題之loss合集
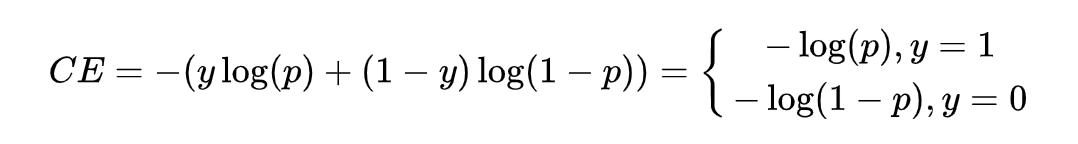



 工商網監
工商網監
評論