 設計非對稱式互信息估計器減少音頻向視頻模態表達的不確定性
設計非對稱式互信息估計器減少音頻向視頻模態表達的不確定性

隨著近年來音視頻生成技術的不斷發展,“虛擬主播”逐漸走入人們視野,并以其在虛擬客服、遠程會議、電影剪輯等現實應用場景中的重要作用而獲得了社會各界的廣泛關注。該技術旨在對輸入的音頻預測相應口型,從而生成指定或任意人物的自然而準確的面部說話視頻。近日,中科院自動化所智能感知與計算研究中心為此提出了一種新穎的音視頻協同計算方法,并重點解決了此前難以達成的任意人物協同生成問題。
該方法一方面實現了利用語音驅動任意對象的高清視頻生成,另一方面在正臉、側臉等多種場景下均顯著提升了生成視頻質量。目前,該成果已被IJCAI 2020大會接收。
由于音視頻模態之間差異性等問題,這項技術目前仍然存在著眾多挑戰。以往的研究方法往往將重點放在了模態內之間,如只關注了視頻幀之間的損失約束,卻忽略了音視頻模態間最重要的問題之一:如何將音頻信息高效充分地表達入視頻模態?同時由于人物與人物之間的個體差異,將同一模型應用于任意人物視頻生成也存在較大的挑戰。
為解決上述問題,團隊精心設計了一個非對稱式互信息估計器(Asymmetric Mutual Information Estimator, AMIE),以構建音視頻模態間的約束。如圖1示,輸入一對音頻與人臉圖像數據,互信息估計器輸出預測的互信息值。在這里,該方法使用Jensen-Shannon表示形式來改善互信息計算方式,使其更好地應用于神經網絡。通過這樣的互信息估計方式,該方法最大化音頻與視頻模態之間的互信息,減少音頻向視頻模態表達的不確定性,并以此獲得音頻和視頻信息之間的跨模態一致性,使得生成視頻中人物的口型更加準確自然。
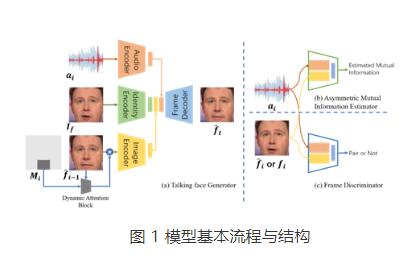
該方法在LRW和GRID基礎數據集上進行了實驗驗證。圖2中的結果表明該方法生成的口型準確度高,且能夠有效適應不同膚色與嘴唇形狀差異。表1的量化結果顯示該方法在常用的對比指標上的優越性能。

該方法有能力對不存在于數據集中的任意人物進行視頻合成,并能夠有效處理如姿態表情、性別差異等變化因素(見圖3)。例如,輸入一段女性語音(圖中第二行),該方法分別生成了現實場景的同性別人臉視頻(圖中第一行),和跨性別人臉視頻(圖中第三行)。

責任編輯:gt
-
音頻
+關注
關注
31文章
3188瀏覽量
85582 -
神經網絡
+關注
關注
42文章
4838瀏覽量
107799 -
視頻
+關注
關注
6文章
2005瀏覽量
74964
發布評論請先 登錄
功率放大器在膠滴氣泡質量與一致性分析研究中的應用

戴爾PowerScale文件存儲系統專為數據生命周期靈活性而設計
DP83826:確定性、低延遲、低功耗工業以太網PHY的卓越之選
DP83826Ax工業以太網PHY:確定性、低延遲與低功耗的完美融合
DP83826Ax:確定性、低延遲工業以太網PHY的深度解析
渦輪部件多源不確定性機理與分類體系研究:從幾何變異到認知局限的系統解析

4種神經網絡不確定性估計方法對比與代碼實現

尋跡智行AMR融合RFID識別技術,為柔性搬運注入“確定性"

自動駕駛端到端大模型為什么會有不確定性?
非對稱密鑰生成和轉換規格詳解
虹科干貨 | 拆解TSN四大支柱:從「盡力而為」到工業實踐的確定性網絡

康謀分享 | 基于多傳感器數據的自動駕駛仿真確定性驗證

應用分享 | 精準生成和時序控制!AWG在確定性三量子比特糾纏光子源中的應用




 工商網監
工商網監
評論