 螞蟻集團全模態代碼算法團隊自研OpAgent技術框架
螞蟻集團全模態代碼算法團隊自研OpAgent技術框架

以下文章來源于CodeFuse,作者CodeFuse
為應對真實 Web 環境的非結構化復雜性、時序不穩定性與交互隱式邏輯等挑戰,螞蟻集團全模態代碼算法團隊提出了一套結合了多任務微調、在線強化學習與模塊化協作的綜合解決方案:OpAgent。
OpAgent 通過層次化多任務微調 (MT-SFT) 構建具備規劃、行動和定位能力的視覺語言模型(VLM)基座;繼而,在自建的在線交互環境中,利用創新的混合獎勵機制進行在線強化學習(Online RL) ,有效緩解了離線訓練帶來的分布偏移問題;最后,通過一個包含規劃器、定位器、反思器和總結器的模塊化智能體架構,實現對復雜長時程任務的魯棒執行與自我修正。
在權威 Web 智能體評測基準 WebArena 上,OpAgent 以 71.6% 的成功率于 2026 年 1 月取得了榜單第一的 SOTA 成績。
GitHub:https://github.com/codefuse-ai/OpAgent
Hugging Face:https://huggingface.co/codefuse-ai/OpAgent
ModelScope:https://modelscope.cn/models/codefuse-ai/OpAgent-32B
Technical Report:https://github.com/codefuse-ai/OpAgent/blob/main/technical_report/OpAgent.pdf
一、背景與挑戰
自主Web智能體旨在模擬人類在圖形用戶界面( GUI )上執行任務,其在自動化測試、數據采集、智能助理等領域具有廣闊應用前景。然而,相較于 PC 或移動端環境,Web 環境呈現出獨特的挑戰:
非結構化復雜性:網頁的 DOM 樹結構龐大且充滿噪聲,傳統基于 HTML 或 DOM 解析的方法難以有效提取關鍵信息,容易被冗余內容干擾。
時序不穩定性:網頁內容是動態的,異步加載、實時更新和臨時性元素(如彈窗)使得環境狀態頻繁變化。依賴靜態離線數據集訓練的模型在部署于真實動態環境時,會面臨嚴重的分布偏移( Distributional Shift )問題。
交互的隱式邏輯:許多 Web 交互(如懸停觸發菜單)依賴實時的視覺反饋來確認操作的成功與否,這種閉環交互邏輯是離線學習范式無法有效建模的。
為應對上述挑戰,我們設計并實現了 OpAgent 框架,其核心在于從依賴靜態數據向與真實環境動態交互的范式轉變。
二、OpAgent技術框架
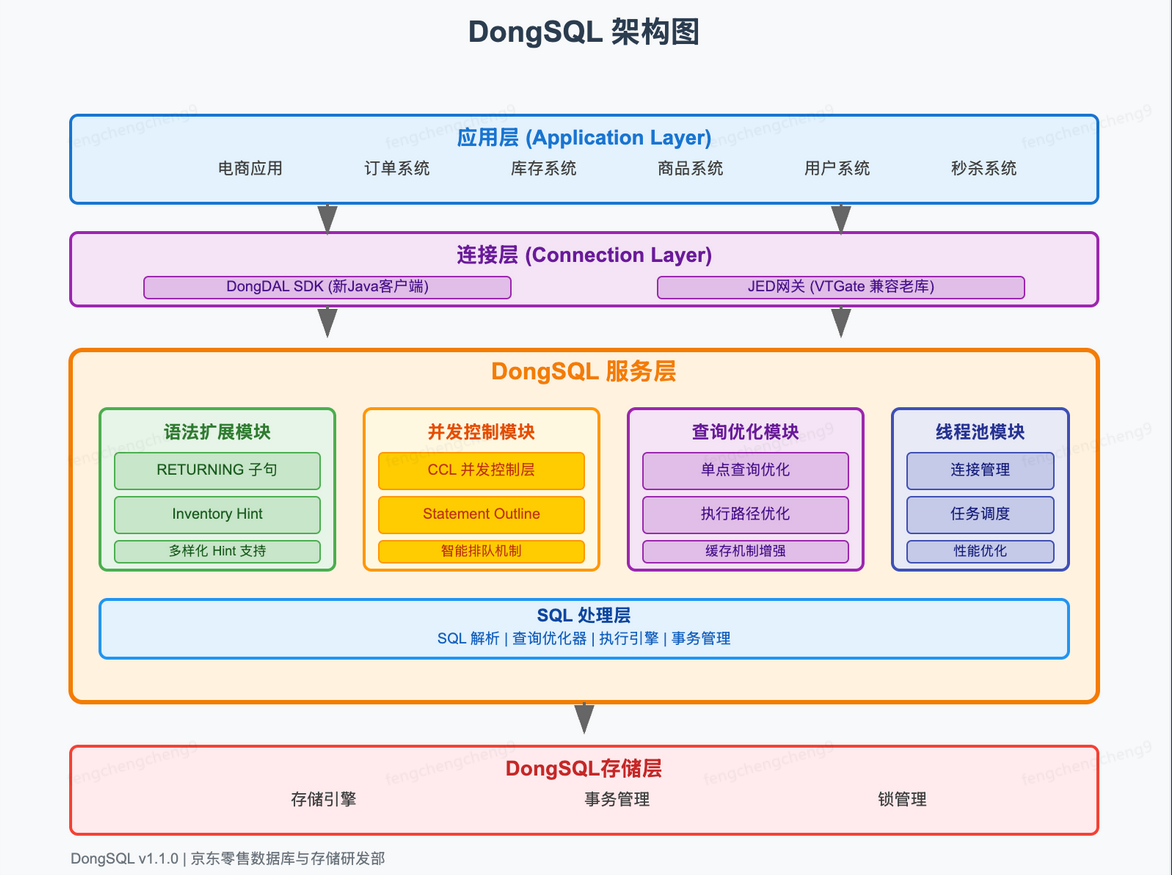
OpAgent 的整體設計遵循一個分階段的優化路徑:首先通過多任務監督微調( MT-SFT )為模型注入基礎的 Web 交互能力,然后通過在線強化學習( Online RL )在真實環境中對策略進行迭代優化,最終在推理階段利用模塊化智能體架構( Agentic Architecture )執行復雜任務。

2.1 層次化多任務微調 (Hierarchical Multi-Task Fine-tuning)
為構建一個強大的視覺語言模型( VLM )基座,我們首先摒棄了對脆弱的 HTML 文本解析的依賴,轉而讓模型直接從視覺截圖( Screenshot )中感知和理解頁面布局。我們將 Web 智能體的基礎能力分解為三個維度:
規劃 ( Planning ):預測交互行為將導致的頁面狀態變遷。
行動 ( Acting ):基于當前頁面狀態,決策下一步所需執行的操作。
定位 ( Grounding ):在視覺上精確定位執行操作的UI元素坐標。
我們整合了包括 Mind2Web 、Aguvis 、UGround 在內的多個領域數據集,分別對上述三種能力進行訓練。為解決不同數據集樣本量級差異巨大(例如,百萬級 vs. 千級)可能導致的梯度主導問題,我們引入了基于有效樣本數 (Effective Number of Samples)的加權策略,動態調整各任務在訓練中的損失權重,確保模型在所有基礎能力上得到均衡發展。

2.2 真實環境在線強化學習 ( Online Agentic RL in the Wild )
在線學習是解決分布偏移問題的關鍵。為此,我們構建了一套支持在真實 Web 環境中進行大規模在線強化學習的系統。
1. 四層RL基礎設施:該系統分為決策層、執行層、基礎設施層和環境層。VLM 代理在決策層生成動作,通過 Playwright 引擎在執行層被解析并分發至分布式瀏覽器集群,與環境層中的真實網站(包括自部署的 WebArena 環境)進行交互,最終將包含截圖和 DOM 的觀測數據反饋回決策層,形成一個完整的閉環交互與數據采集流程。

2. 混合獎勵機制 ( Hybrid Reward Mechanism ):在沒有真值( Ground-truth )軌跡的真實環境中,如何為智能體的探索行為提供有效監督信號至關重要。我們設計了一種混合獎勵機制:
基于規則的決策樹 ( RDT ) 進行過程監督:為智能體的每一步提供即時反饋。該機制通過一系列規則判斷動作的有效性,如是否產生頁面視覺變化、是否點擊在可交互元素上等,對無效或冗余的動作給予懲罰。
基于 VLM 的 WebJudge 進行結果評估:在一條軌跡( trajectory )結束后,引入一個強大的 VLM 評估器 WebJudge ,從任務完成度、動作有效性和路徑效率三個維度對整個軌跡進行綜合評分,作為最終的稀疏獎勵信號。
這種結合了稠密過程獎勵和稀疏結果獎勵的機制,為模型在真實環境中的策略優化提供了穩定且全面的監督。

2.3 Operator Agentic 模塊化智能體架構
對于長時程、多步驟的復雜任務,單一模型的決策能力有限。我們因此設計了一個包含四個專業角色的模塊化協作架構,以提升任務執行的魯棒性和成功率。
| 模塊 | 核心職責 | 主要輸出 |
|
Planner 規劃器 |
任務分解與策略制定 | 語義化的步驟指令 |
|
Grounder 定位器 |
將語義指令映射到UI坐標 | 標準化的工具調用(Tool Call) |
|
Reflector 反思器 |
驗證動作效果,監控任務進展 | 反思信號與中間筆記 |
|
Summarizer 總結器 |
綜合軌跡信息,生成最終答案 | 整合后的最終答案 |
該架構通過一個“規劃-執行-反思”的迭代循環運作:Planner 根據全局目標和當前狀態生成高層指令,Grounder 將其翻譯為具體動作并執行,Reflector 在動作后評估狀態變化并判斷是否需要重新規劃。這種機制實現了有效的錯誤檢測與自我修正。

三、實驗與結果
我們在多個基準上對 OpAgent 框架的各組件進行了充分評估。
單模型性能:
經過在線RL優化的單模型( Qwen3-VL-32B-Thinking + RL-HybridReward-Zero )在 WebArena 上取得了 38.1% 的成功率( Pass@5 ),顯著超越了原始基線模型( 27.4% )以及其他采用類似 Test-Time Training ( TTT ) 策略的方法。

Pass@K 分析:
對比 RL 優化前后的模型在不同 Pass@K 下的表現,可以看到隨著嘗試次數 K 的增加,RL優化后模型的性能優勢愈發明顯,Pass@5 的絕對提升達到 10.66% 。這表明在線強化學習顯著增強了模型決策的魯棒性。

Agentic Architecture 性能:
最終,集成了所有優化的 OpAgent 整體框架(使用 Gemini-3-Pro 作為部分模塊后端,Qwen2.5-VL-MFT 作為 Grounder ),在 WebArena 上達到了 71.6% 的成功率,刷新了該基準的 SOTA 記錄,并登頂排行榜。

四、總結與展望
本文介紹了螞蟻全模態代碼算法團隊在 Web 智能體方向的最新研究成果 OpAgent 。通過在多任務微調、真實環境在線強化學習以及模塊化智能體架構等方面的探索,我們顯著提升了 Web 智能體在復雜動態環境中的任務執行能力,并在 WebArena 基準上取得了 SOTA 性能。
當前工作在實現高性能的同時,仍一定程度上依賴于精細的提示工程和多智能體的復雜編排。未來的研究方向將包括提升單模型內在的探索與泛化能力,以期減少對復雜框架的依賴,實現更加通用和高效的自主智能體。
關于我們
我們是螞蟻集團智能平臺工程的全模態代碼算法團隊。團隊成立 3 年以來,在 ACL、EMNLP、ICLR、NeurIPS、ICML 等頂級會議發表論文 20 余篇,兩次獲得螞蟻技術最高獎 T-Star ,1 次螞蟻集團最高獎 SuperMA ,我們研發的 CodeFuse 項目連續兩年蟬聯學術開源先鋒項目。
團隊常年招聘研究型實習生,有志于 NLP、大模型、多模態、圖神經網絡的同學歡迎聯系 hyu.hugo@antgroup.com,期待與你一起,探索AI的無限可能!
-
Web
+關注
關注
2文章
1307瀏覽量
74682 -
強化學習
+關注
關注
4文章
272瀏覽量
11981 -
螞蟻集團
+關注
關注
0文章
108瀏覽量
4639
原文標題:螞蟻集團全模態代碼算法團隊自研多模態Web GUI Agent:OpAgent
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
軟通動力基于OpenClaw開源框架深度自研端側智能體平臺
眾智FlagOS適配面壁智能開源全模態大模型MiniCPM-o 4.5

天碩TOPSSD G40 M.2 2280工業級SSD——全棧自研存儲如何成就防數據泄露固態硬盤的典范
北汽集團與中國物流簽署戰略合作框架協議
格靈深瞳多模態大模型榮登InfoQ 2025中國技術力量年度榜單
圖撲智慧汽車展示平臺全自研技術方案

季豐電子自研PCB管理系統的簡單介紹
四川資源集團與華為簽署框架合作協議
知乎開源“智能預渲染框架” 幾行代碼實現鴻蒙應用頁面“秒開”
聲智科技與螞蟻集團共探聲學AI前沿技術
直擊一線 | 簡形電力技術團隊攻堅特殊光伏變壓器檢測難題

商湯科技“小浣熊家族”與螞蟻集團旗下智能體開發平臺“螞蟻百寶箱”正式達成生態合作
江波龍自研車規存儲全矩陣登陸2025上海車展,PTM定制“駕控隨芯”

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現




 工商網監
工商網監
評論