") 構(gòu)建機(jī)器學(xué)習(xí)管道和使用Apache Spark時(shí)的一些經(jīng)驗(yàn)
構(gòu)建機(jī)器學(xué)習(xí)管道和使用Apache Spark時(shí)的一些經(jīng)驗(yàn)

想必每個(gè)人都有這樣的經(jīng)歷:當(dāng)你在學(xué)習(xí)新事物時(shí),萬(wàn)事開(kāi)頭難,你總會(huì)遇到許多未知的因素,并花大量時(shí)間去學(xué)習(xí)、適應(yīng)新的領(lǐng)域。而隨著時(shí)間的推移,你在這個(gè)領(lǐng)域越來(lái)越熟練,也積累了一大堆技巧,想送給當(dāng)初那個(gè)四處碰壁的自己。近日,medium博主Aseem Bansal撰文講述了自己在構(gòu)建機(jī)器學(xué)習(xí)管道和使用Apache Spark時(shí)的一些經(jīng)驗(yàn),希望能幫助入門(mén)者節(jié)約時(shí)間。
謹(jǐn)慎制定預(yù)期
和其他任務(wù)量巨大、未知的事物一樣,我們很難對(duì)機(jī)器學(xué)習(xí)項(xiàng)目進(jìn)展作出時(shí)間預(yù)估。我們知道自己需要做哪些事來(lái)達(dá)成目標(biāo),但隨著工作進(jìn)行,一些想法會(huì)逐漸暴露出缺陷。這時(shí),我們必須接受這個(gè)現(xiàn)實(shí),并馬上靈活更換方法保證工作計(jì)劃快速迭代。
項(xiàng)目中會(huì)有大量未知數(shù),你需要確保團(tuán)隊(duì)能夠快速迭代。
在開(kāi)始前檢驗(yàn)數(shù)據(jù)是否整齊
在我們第一次構(gòu)建機(jī)器學(xué)習(xí)管道時(shí),團(tuán)隊(duì)已經(jīng)花了大約3年的時(shí)間收集原始數(shù)據(jù)。為了防止中途因?yàn)槟承┮馔庑枰亟〝?shù)據(jù)的分析存儲(chǔ),我們沒(méi)有對(duì)數(shù)據(jù)做任何調(diào)整,只是以.csv的格式把它們放在那里。一開(kāi)始我們并沒(méi)有發(fā)現(xiàn)這有什么不妥,但隨著時(shí)間的推移,編寫(xiě)這些文件的代碼發(fā)生了變化,也出現(xiàn)了不少錯(cuò)誤。所以我們不得不一邊構(gòu)建管道,一遍修修補(bǔ)補(bǔ)。直到最后,我們還是在Apache Spark中寫(xiě)代碼,清除了所有歷史數(shù)據(jù)。如果我們事先檢查了數(shù)據(jù)整齊與否,不是直到項(xiàng)目進(jìn)行才發(fā)現(xiàn)問(wèn)題,也許這個(gè)過(guò)程就不會(huì)那么復(fù)雜。
在項(xiàng)目開(kāi)始前,請(qǐng)確保自己的數(shù)據(jù)是正確的。
對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,對(duì)模型進(jìn)行預(yù)訓(xùn)練
為了訓(xùn)練我們的機(jī)器學(xué)習(xí)模型,我們一開(kāi)始試著加載了所有數(shù)據(jù)。由于文件大小是TB級(jí)的,每次加載完,模型的訓(xùn)練速度就會(huì)變得非常慢,這也影響了它的迭代。后來(lái),我們逐漸意識(shí)到似乎不用每次都加載所有數(shù)據(jù),于是就對(duì)數(shù)據(jù)做了一些預(yù)處理并創(chuàng)建了一個(gè)更小的數(shù)據(jù)集,它允許模型調(diào)用我們需要的列來(lái)進(jìn)行訓(xùn)練。同時(shí),我們也沒(méi)有刪除原來(lái)的數(shù)據(jù)源,而是把它作為檢測(cè)的備份資源。
不要混淆ETL和模型訓(xùn)練。如果你需要訓(xùn)練1000個(gè)模型,你并不需要做1000次預(yù)處理。你只要做一次,然后把數(shù)據(jù)保存到一個(gè)地方,然后把它用來(lái)訓(xùn)練模型。
選擇權(quán)限共享的工具
如前所述,我們把原始數(shù)據(jù)放在AWS S3中備份,這看起來(lái)好像沒(méi)什么問(wèn)題,但從數(shù)據(jù)科學(xué)角度來(lái)看,這并沒(méi)有做到真正的共享,因?yàn)楫?dāng)需要從S3中提取數(shù)據(jù)時(shí),只有少數(shù)人有訪問(wèn)權(quán)。
給一個(gè)只讀權(quán)是遠(yuǎn)遠(yuǎn)不夠的。人們能不能在筆記本電腦上下載TB級(jí)別的數(shù)據(jù)?強(qiáng)行來(lái)說(shuō),這是可以的,但在下完數(shù)據(jù)后筆記本電腦能用它們干什么?不是每個(gè)人都會(huì)隨身攜帶32核電腦的。要他們未雨綢繆,隨時(shí)為處理TB級(jí)的數(shù)據(jù)做好準(zhǔn)備,這簡(jiǎn)直是浪費(fèi)時(shí)間。
這時(shí)候,我們發(fā)現(xiàn)一些支持Apache Spark環(huán)境的notebook可以滿足基礎(chǔ)需求,比如jupyter和zeppelin。如果是一些長(zhǎng)期的集群的任務(wù),jupyter的優(yōu)勢(shì)更大一些,但由于AWS EMR內(nèi)置集成,zeppelin可以憑借Amazon EMR群集進(jìn)行機(jī)器學(xué)習(xí)、流處理和圖形分析,所以對(duì)于一般用戶,zeppelin更甚一籌。
只給人們開(kāi)放TB級(jí)數(shù)據(jù)的只讀權(quán)限,并期望他們能做出點(diǎn)什么的想法是荒誕的。你必須先提供正確的工具,別人才能更上一層樓。 對(duì)于這個(gè)問(wèn)題,jupyter、zeppelin等筆記本都是我們的明智之選。
大數(shù)據(jù)必須進(jìn)行監(jiān)控
當(dāng)你處理大數(shù)據(jù)時(shí),你會(huì)發(fā)現(xiàn)傳統(tǒng)的軟件工程方法有時(shí)不頂用。普通程序跑一跑也許只要幾分鐘,但大數(shù)據(jù)可能要幾小時(shí)甚至是幾天,具體取決于你在做什么以及你是怎么做的。幸運(yùn)的是,現(xiàn)在不是十年前,我們不再需要等任務(wù)全部結(jié)束再來(lái)思考怎么提高效率。
和傳統(tǒng)的軟件編程相比,如何減少大數(shù)據(jù)背景下的批量作業(yè)是一個(gè)更復(fù)雜的問(wèn)題。通過(guò)云,現(xiàn)在我們可以等量減少使用機(jī)器的數(shù)量,或是縮短訓(xùn)練的總時(shí)長(zhǎng),但是面對(duì)這些選擇,哪一個(gè)才是真正的首選?我們可以增加機(jī)器數(shù)量,可以改變使用的機(jī)型,可以采用CPU bound、RAM bound,也可以是network bound、disk bound……在這個(gè)分布式環(huán)境里,我們的瓶頸在哪里?這些都是我們必須要回答的問(wèn)題,它們影響項(xiàng)目用時(shí)的長(zhǎng)短。
對(duì)Apache Spark來(lái)說(shuō),它很難弄清楚需要的機(jī)器類(lèi)型。Amazon EMR帶有神經(jīng)節(jié),讓我們一眼就可以監(jiān)控集群內(nèi)存/ CPU。但有時(shí)我們也不得不去檢查底層的EC2實(shí)例監(jiān)測(cè),因?yàn)樯窠?jīng)節(jié)并不完美。只有結(jié)合兩者,我們才能對(duì)比著發(fā)現(xiàn)問(wèn)題。我們發(fā)現(xiàn),執(zhí)行ETL和訓(xùn)練機(jī)器學(xué)習(xí)模型的任務(wù)有不同的配置文件。ETL需要占用大量的網(wǎng)絡(luò)和內(nèi)存,而機(jī)器學(xué)習(xí)訓(xùn)練對(duì)算力要求更高,所以我們?yōu)閮烧哌x擇了不同類(lèi)型的方案。
可以通過(guò)監(jiān)控CPU /內(nèi)存/網(wǎng)絡(luò)/ IO監(jiān)控來(lái)優(yōu)化成本。我們找到了EHL和ML對(duì)硬件的不同需求。
一開(kāi)始就對(duì)機(jī)器學(xué)習(xí)模型預(yù)測(cè)實(shí)行基準(zhǔn)測(cè)試
想一想,你對(duì)機(jī)器學(xué)習(xí)模型的預(yù)測(cè)響應(yīng)時(shí)間有沒(méi)有特殊要求。如果有要求,那你在選擇框架前應(yīng)該先確定該框架能滿足你的預(yù)期。要知道,基礎(chǔ)模型的數(shù)學(xué)理論是很容易把握的,但如果你向當(dāng)然地認(rèn)為模型能按著數(shù)學(xué)方程迅速給你一個(gè)預(yù)測(cè)結(jié)果,那你就錯(cuò)了。
有時(shí)候影響預(yù)測(cè)速度的除了數(shù)學(xué)模型,還有其他一些奇奇怪怪的因素。而這些坑都需要你先做基準(zhǔn)測(cè)試進(jìn)行排查。如果你是在構(gòu)建完機(jī)器學(xué)習(xí)管道后再做基準(zhǔn)測(cè)試,你可能會(huì)浪費(fèi)大量時(shí)間。
如果你對(duì)響應(yīng)時(shí)間有要求,請(qǐng)先利用選擇的框架制作一個(gè)簡(jiǎn)單模型,它可以在精度等方面表現(xiàn)不佳,但你可以基于它測(cè)試延遲情況。
無(wú)論AWS如何顯示,S3都不是一個(gè)文件系統(tǒng)
當(dāng)你在使用AWS的GUI或CLI時(shí),你很容易忘記S3不是個(gè)文件系統(tǒng),它只是一個(gè)對(duì)象存儲(chǔ)。如果你不知道什么是對(duì)象存儲(chǔ),可以聯(lián)系Key-value存儲(chǔ)類(lèi)比一下,把里面的value替換成對(duì)象,而這個(gè)對(duì)象可以是json和圖像等。
區(qū)分這一點(diǎn)很重要,因?yàn)樵赟3中重命名內(nèi)容并不像在文件系統(tǒng)中那么快。如果你在文件系統(tǒng)中移動(dòng)了一個(gè)對(duì)象,它可能很快就好了,這主要取決于你正在調(diào)用的內(nèi)容。但如果是在S3里,你最好不要抱有同樣的幻想。
用map、reduce處理數(shù)據(jù)時(shí),傳統(tǒng)的hadoop會(huì)產(chǎn)生臨時(shí)文件,而Apache Spark在把數(shù)據(jù)寫(xiě)入S3時(shí),會(huì)先寫(xiě)入一個(gè)臨時(shí)文件,再把它們移至對(duì)象存儲(chǔ),簡(jiǎn)而言之,就是速度很慢。所以你可以選擇存本地,也可以用Apache Spark把臨時(shí)數(shù)據(jù)塞內(nèi)存處理完后直接輸出最終結(jié)果。
Apache Spark主要是基于Scala的
如果你要用Apache Spark,首先你該知道它主要是基于Scala的。雖然它支持Java和Python API,但它的大多數(shù)示例還是圍繞scala展開(kāi)的。
在還沒(méi)接觸過(guò)機(jī)器學(xué)習(xí)和scala前,我們用的一直是Java,并且覺(jué)得機(jī)器學(xué)習(xí)對(duì)我們的項(xiàng)目可能有很大的用處,但是學(xué)習(xí)scala是不必要的。事實(shí)上,我們中也沒(méi)人想處理scala的學(xué)習(xí)曲線。這樣的考慮主要是為了防止項(xiàng)目出錯(cuò)。但有一次,我們遇到了一個(gè)Apache Spark問(wèn)題,找到解決方案不麻煩,把scala翻譯成Java也不麻煩,麻煩的是我們得把Spark Scala翻譯成Spark Java,因?yàn)镴ava的API不太好用。
如果你完全不懂scala但又想用Spark Mllib,你可能得向scala妥協(xié)。這不是理想的解決方案,但卻是實(shí)際的解決方案。讓它運(yùn)作,然后把它變得更好。相比找到一種不變的、看似完美的解決方案,學(xué)會(huì)新的東西并讓它發(fā)揮作用才更令人開(kāi)心。
如果這是團(tuán)隊(duì)作業(yè),分享知識(shí)就十分重要
如果你要把機(jī)器學(xué)習(xí)和現(xiàn)有的其他系統(tǒng)集成在一起,你就不得不需要和其他開(kāi)發(fā)人員打交道。你要聯(lián)系的對(duì)象除了開(kāi)發(fā)者,還有業(yè)務(wù)人員、操作人員、市場(chǎng)營(yíng)銷(xiāo)人員等。除非你正在從事人工智能方向的產(chǎn)品研發(fā),否則這些人中的大部分不會(huì)對(duì)AI有太多太深的了解。而因?yàn)闄C(jī)器學(xué)習(xí)是整個(gè)解決方案中的一部分,他們也沒(méi)有時(shí)間去進(jìn)行系統(tǒng)學(xué)習(xí),所以知識(shí)分享就變得尤為重要了。
你不必教給他們算法和其他專(zhuān)業(yè)的東西,但你確實(shí)需要向他們解釋一些常用的術(shù)語(yǔ),如訓(xùn)練、測(cè)試、模型、算法等。
機(jī)器學(xué)習(xí)領(lǐng)域充滿大量術(shù)語(yǔ),你可能會(huì)忽略這個(gè)現(xiàn)實(shí),但對(duì)于團(tuán)隊(duì)中的其他人來(lái)說(shuō),這些陌生的詞匯會(huì)讓他們感到困惑。并不是每個(gè)人都上過(guò)ML課程。
為數(shù)據(jù)構(gòu)建版本是個(gè)好主意
你可能需要為您的數(shù)據(jù)構(gòu)建不同版本的控制方案,讓它能在不重新部署整個(gè)軟件的情況下,切換不同的數(shù)據(jù)集供模型進(jìn)行訓(xùn)練。我們之前創(chuàng)建過(guò)一個(gè)模型,把它放在數(shù)據(jù)集上訓(xùn)練后,可能是數(shù)據(jù)不夠,它的性能不盡如人意。
為此,我們?yōu)閿?shù)據(jù)構(gòu)建了幾個(gè)版本的控制方案,當(dāng)在v1上訓(xùn)練模型時(shí),它會(huì)自動(dòng)生成下一版數(shù)據(jù)。當(dāng)有足夠數(shù)據(jù)后,我們就能直接靠切換代碼來(lái)進(jìn)行訓(xùn)練。我們還制作了一個(gè)UI,能利用它控制機(jī)器學(xué)習(xí)算法的參數(shù),并對(duì)某些特定參數(shù)進(jìn)行基本過(guò)濾,指定我們想要用于訓(xùn)練的數(shù)據(jù)量。
-
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
224991 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136948 -
Apache
+關(guān)注
關(guān)注
0文章
64瀏覽量
12925
原文標(biāo)題:入門(mén)掃雷:在開(kāi)始第一個(gè)ML項(xiàng)目前,你必須知道這幾件事
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
分享一些最常見(jiàn)最實(shí)用的機(jī)器學(xué)習(xí)算法
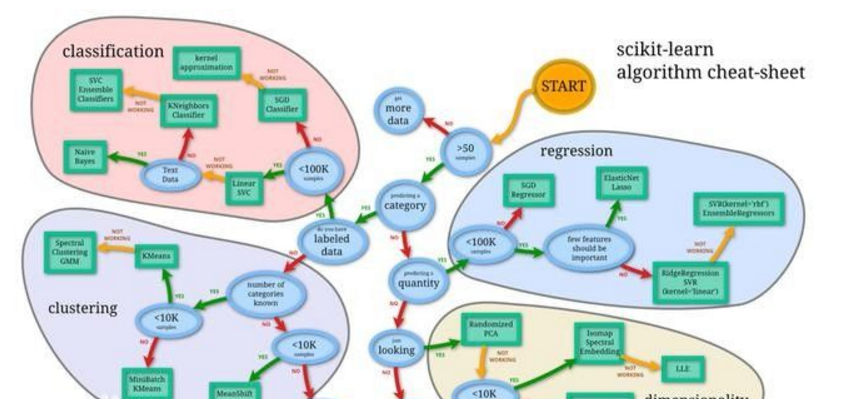
十三個(gè)框架助你掌握機(jī)器學(xué)習(xí)
Spark機(jī)器學(xué)習(xí)庫(kù)的各種機(jī)器學(xué)習(xí)算法
如何使用Apache Spark 2.0
Apache Spark 1.6預(yù)覽版新特性展示
機(jī)器學(xué)習(xí)實(shí)例:Spark與Python結(jié)合設(shè)計(jì)
google機(jī)器學(xué)習(xí)團(tuán)隊(duì)開(kāi)發(fā)機(jī)器學(xué)習(xí)系統(tǒng)Seti的一些經(jīng)驗(yàn)教訓(xùn)
Apache Spark的分布式深度學(xué)習(xí)框架BigDL的概述
Apache Spark上的分布式機(jī)器學(xué)習(xí)的介紹
機(jī)器學(xué)習(xí)的一些代碼示例合集

Apache Spark 3.2有哪些新特性
利用Apache Spark和RAPIDS Apache加速Spark實(shí)踐



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論