") Java的SPI機(jī)制詳解
Java的SPI機(jī)制詳解

作者:京東物流 楊葦葦
1.SPI簡(jiǎn)介
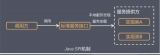
SPI(Service Provicer Interface)是Java語(yǔ)言提供的一種接口發(fā)現(xiàn)機(jī)制,用來(lái)實(shí)現(xiàn)接口和接口實(shí)現(xiàn)的解耦。簡(jiǎn)單來(lái)說(shuō),就是系統(tǒng)只需要定義接口規(guī)范以及可以發(fā)現(xiàn)接口實(shí)現(xiàn)的機(jī)制,而不需要實(shí)現(xiàn)接口。
SPI機(jī)制在Java中應(yīng)用廣泛。例如:JDBC中的數(shù)據(jù)庫(kù)連接驅(qū)動(dòng)使用SPI機(jī)制,只定義了數(shù)據(jù)庫(kù)連接接口的規(guī)范,而具體實(shí)現(xiàn)由各大數(shù)據(jù)庫(kù)廠商實(shí)現(xiàn),不同數(shù)據(jù)庫(kù)的實(shí)現(xiàn)不同,我們常用的mysql的驅(qū)動(dòng)也實(shí)現(xiàn)了其接口規(guī)范,通過(guò)這種方式,JDBC數(shù)據(jù)庫(kù)連接可以適配不同的數(shù)據(jù)庫(kù)。
SPI機(jī)制在各種框架中也有應(yīng)用,例如:springboot的自動(dòng)裝配中查找spring.factories文件的步驟就是應(yīng)用了SPI機(jī)制;dubbo也對(duì)Java的SPI機(jī)制進(jìn)行擴(kuò)展,實(shí)現(xiàn)了自己的SPI機(jī)制。
2.SPI入門(mén)案例
2.1.創(chuàng)建工程
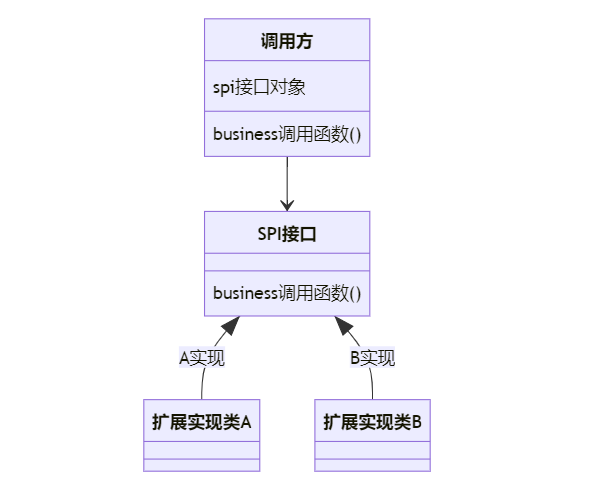
我們剛才在介紹中說(shuō)過(guò)了,SPI機(jī)制需要定義接口規(guī)范,這里我們以一個(gè)簡(jiǎn)單的接口案例來(lái)說(shuō)明。
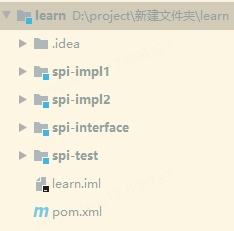
首先我們需要?jiǎng)?chuàng)建四個(gè)工程:
?spi-interface,這里定義SPI的接口類:Person
?spi-impl1,這里定義接口的第一個(gè)實(shí)現(xiàn)類:Teacher
?spi-impl2,這里定義接口的第二個(gè)實(shí)現(xiàn)類:Student
?spi-test,這里通過(guò)SPI機(jī)制加載所有實(shí)現(xiàn)類進(jìn)行測(cè)試
??
2.2.創(chuàng)建SPI接口規(guī)范
接口如下所示:
package com.jd.spi;
public interface Person {
String favorite();
}
2.3.創(chuàng)建實(shí)現(xiàn)類1項(xiàng)目
2.3.1.創(chuàng)建接口
接口如下所示:
package com.jd.spi;
public class Teacher implements Person {
public String favorite() {
return "老師喜歡給學(xué)生上課";
}
}
2.3.2.創(chuàng)建spi配置文件
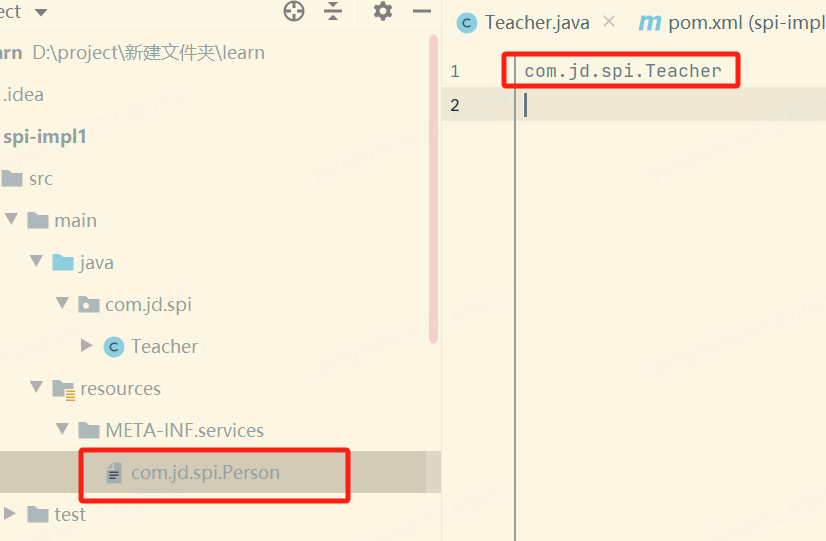
如下圖所示,在項(xiàng)目的resources文件夾下創(chuàng)建兩個(gè)文件夾META-INF/services,然后在文件夾下面創(chuàng)建名稱為com.jd.spi.Person的文件,其文件的內(nèi)容為當(dāng)前項(xiàng)目的接口實(shí)現(xiàn)類com.jd.spi.Teacher。
??
2.4.創(chuàng)建實(shí)現(xiàn)類2項(xiàng)目
2.4.1.創(chuàng)建實(shí)現(xiàn)類2
接口如下所示:
package com.jd.spi;
public class Student implements Person {
public String favorite() {
return "學(xué)生喜歡努力學(xué)習(xí)";
}
}
2.4.2.創(chuàng)建spi配置文件
如下圖所示,在項(xiàng)目的resources文件夾下創(chuàng)建兩個(gè)文件夾META-INF/services,然后在文件夾下面創(chuàng)建名稱為com.jd.spi.Person的文件,其文件的內(nèi)容為當(dāng)前項(xiàng)目的接口實(shí)現(xiàn)類com.jd.spi.Student。

??
2.5.創(chuàng)建測(cè)試項(xiàng)目
2.5.1.引入3個(gè)maven依賴
這里需要引入接口定義項(xiàng)目和兩個(gè)接口實(shí)現(xiàn)項(xiàng)目。
如下所示:
org.example
spi-interface
1.0-SNAPSHOT
org.example
spi-impl1
1.0-SNAPSHOT
org.example
spi-impl2
1.0-SNAPSHOT
2.5.2.創(chuàng)建測(cè)試類
如下所示:
package com.jd.spi; import java.util.Iterator; import java.util.ServiceLoader; public class SPITest { public static void main(String[] args) { ServiceLoader loader = ServiceLoader.load(Person.class); for(Iterator it = loader.iterator(); it.hasNext();){ Person person = it.next(); System.out.println(person.favorite());; } } }
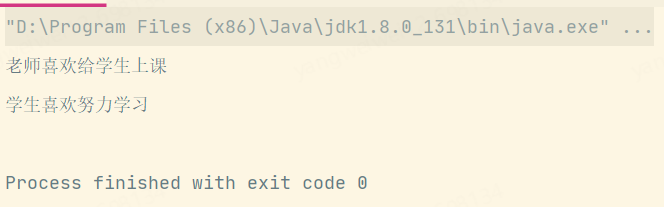
運(yùn)行測(cè)試類,其結(jié)果如下所示:
??
我們發(fā)現(xiàn),Java的SPI機(jī)制獲取了所有Person類的實(shí)現(xiàn)類,并執(zhí)行其對(duì)應(yīng)的favorite方法。
3.SPI機(jī)制的原理
3.1.ServiceLoader的核心屬性
其核心機(jī)制就是ServiceLoader類的load方法,下面我們將從源碼來(lái)分析其原理。
首先我們先看下ServiceLoader的核心屬性:
public final class ServiceLoader
implements Iterable
{
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class service;
// The class loader used to locate, load, and instantiate providers
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// Cached providers, in instantiation order
private LinkedHashMap providers = new LinkedHashMap();
// The current lazy-lookup iterator
private LazyIterator lookupIterator;
這個(gè)PREFIX屬性、providers屬性和lookupIterator屬性將在后續(xù)的代碼中使用到,我們發(fā)現(xiàn)PREFIX屬性就是示例中說(shuō)的META-INF/services路徑。
3.2.ServiceLoader的遍歷器
示例中,我們會(huì)獲取serviceLoader的遍歷器iterator,其方法如下所示:
public Iterator iterator() {
return new Iterator() {
Iterator> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
然后需要執(zhí)行遍歷器的next方法獲取元素,其next方法執(zhí)行的是lookupIterator.next()。
接下來(lái)我們來(lái)看下lookupIterator的next方法:
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction action = new PrivilegedAction() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
其執(zhí)行的是nextService方法,如下所示:
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
nextService方法首先執(zhí)行hasNextService方法,如下所示:
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
這個(gè)方法會(huì)執(zhí)行String fullName = PREFIX + service.getName(),而PREFIX就是我們前面剛才說(shuō)的非常重要的屬性,其值為META-INF/services/,service就是接口類,其最終的fullName指的就是META-INF/services文件夾下的名稱為com.jd.spi.Person的文件。
接著會(huì)執(zhí)行configs = loader.getResources(fullName)方法,這個(gè)方法這里不做詳細(xì)描述,其主要功能就是獲取類路徑下所有相對(duì)路徑為fullName的所有文件的URL對(duì)象。
然后會(huì)執(zhí)行pending = parse(service, configs.nextElement())方法,這個(gè)方法這里也不詳細(xì)描述,其主要功能是讀取文件,將文件內(nèi)容變成字符串,然后nextName就被賦值為當(dāng)前文件的內(nèi)容,即實(shí)現(xiàn)類的接口全限定名。
因此,執(zhí)行hasNextService()方法后,nextName被賦值為一個(gè)實(shí)現(xiàn)類的全限定名。
我們繼續(xù)看上面的nextService()方法,其最終會(huì)執(zhí)行c = Class.forName(cn, false, loader)方法,這個(gè)方法很明顯就是通過(guò)反射實(shí)例化一個(gè)對(duì)象。通過(guò)一系列操作,最終返回了對(duì)應(yīng)實(shí)現(xiàn)類的對(duì)象。
3.3.流程總結(jié)
我們將其總結(jié)為以下幾個(gè)步驟:
1.創(chuàng)建ServiceLoader對(duì)象
2.創(chuàng)建迭代器lookupIterator
3.通過(guò)迭代器的hasNextService方法讀取類路徑下META-INF/services目錄的所有名稱為接口全限定名的文件,將其內(nèi)容存入configs對(duì)象中
4.從configs對(duì)象中獲取實(shí)現(xiàn)類的全限定名,然后通過(guò)反射實(shí)例化對(duì)象
從上述流程,我們也可以總結(jié)實(shí)現(xiàn)SPI的幾點(diǎn)重要信息:
1.實(shí)現(xiàn)工程必須在類路徑下的META-INF/services目錄下創(chuàng)建接口全限定名的文件,其文件內(nèi)容必須是接口實(shí)現(xiàn)類的全限定名
2.實(shí)現(xiàn)類必須有一個(gè)無(wú)參構(gòu)造方法,因?yàn)镾PI默認(rèn)是使用無(wú)參構(gòu)造方法實(shí)例化對(duì)象的
4.總結(jié)
本文首先概述了Java的SPI機(jī)制,隨后闡述了其基本使用方法,最后深入探討了其實(shí)現(xiàn)原理。SPI在Java語(yǔ)言體系中具有廣泛應(yīng)用,能夠有效地實(shí)現(xiàn)系統(tǒng)解耦,眾多框架基于此機(jī)制進(jìn)行了拓展和優(yōu)化,從而實(shí)現(xiàn)了更為強(qiáng)大的SPI機(jī)制。掌握SPI的使用技巧可以幫助我們?cè)O(shè)計(jì)出更為靈活的系統(tǒng),而深入理解其原理則有助于提升我們的技術(shù)水平。
審核編輯 黃宇
-
JAVA
+關(guān)注
關(guān)注
20文章
3004瀏覽量
116726 -
SPI
+關(guān)注
關(guān)注
17文章
1894瀏覽量
101776
發(fā)布評(píng)論請(qǐng)先 登錄
基于Java反射機(jī)制的Excel文件導(dǎo)出實(shí)現(xiàn)_楊敏煜
java類加載機(jī)制圖文詳解
詳解java并發(fā)機(jī)制
java的動(dòng)態(tài)代理機(jī)制和作用
java動(dòng)態(tài)代理機(jī)制詳解的類和接口描述
Java反射機(jī)制到底是什么?有什么作用
源碼級(jí)深度理解Java SPI
基于spring的SPI擴(kuò)展機(jī)制是如何實(shí)現(xiàn)的?
Java、Spring、Dubbo三者SPI機(jī)制的原理和區(qū)別

SPI是什么?Java SPI的使用介紹
什么是SPI機(jī)制



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論