") 【每天學點AI】五個階段帶你了解人工智能大模型發(fā)展史!
【每天學點AI】五個階段帶你了解人工智能大模型發(fā)展史!


20世紀50年代
NLP的早期研究主要基于規(guī)則的方法,依賴于語言學專家手工編寫的規(guī)則和詞典。這些規(guī)則通常是關于語法、語義和句法結構的人工規(guī)則。

例如一個簡單的陳述句通常遵循“主語 + 謂語 + 賓語”的結構,每一個陳述句都以這種規(guī)則做標記。
那時候的NLP就像個剛學步的小孩,靠的是一堆人工的規(guī)則,就像小時候學說話,需要一個字一個字地學,學完單詞學語法。
20世紀70年代
隨著時間的推移,20世紀70年代隨著計算能力的提升和數(shù)據(jù)的積累,NLP開始轉向基于統(tǒng)計學的方法。這些方法依賴于大量的文本數(shù)據(jù),通過統(tǒng)計模型來捕捉語言模式,而非手工制定規(guī)則。統(tǒng)計方法開始重視詞語的共現(xiàn)關系,并通過概率推斷來實現(xiàn)語言處理任務。

NLP開始用大數(shù)據(jù)來學習語言的規(guī)律,就像你長大了,通過聽周圍人說話來學習新詞匯和表達,但是對于你來說每個單詞都是獨立的,相互沒有關系。
2013年
2013年,基于嵌入embedding的NLP方法被發(fā)明,通過將詞語、短語、句子等語言元素映射到高維的連續(xù)向量空間中,這些向量捕捉了詞語之間的語義關系,使得模型能夠更好地理解和處理語言。
就像用表情符號來表達情感一樣,表情是人類語言的抽象,這些向量能捕捉詞語的意思和關系。
同年Encoder-decoder的模型結構被發(fā)明,為后續(xù)的序列到序列(Seq2Seq)模型奠定了基礎,至此命運的齒輪開始轉動。
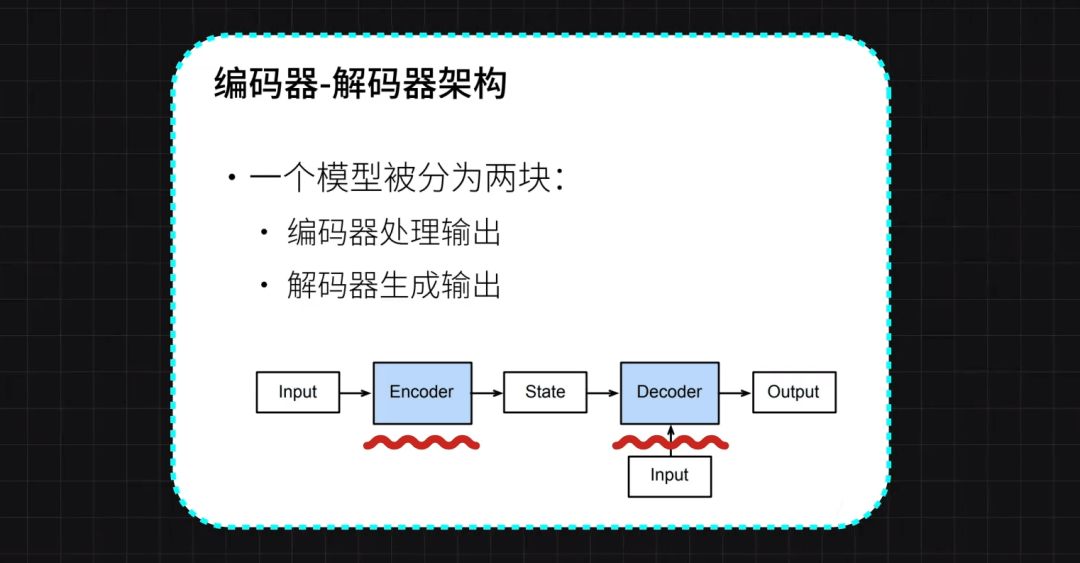
2017年
2017年,"Attention is all you need"論文的發(fā)表標志著Transformer模型的誕生,它在上一個階段詞嵌入的基礎上,基于自注意力機制的模型,它徹底改變了NLP領域的模型設計和訓練方式。

Transformer模型通過多頭注意力機制和位置編碼,有效地處理了序列數(shù)據(jù),提高了模型的并行處理能力和性能。它用自注意力機制讓模型能同時關注句子中的所有詞,就像你在聊天時,能同時關注群里每個人的發(fā)言。
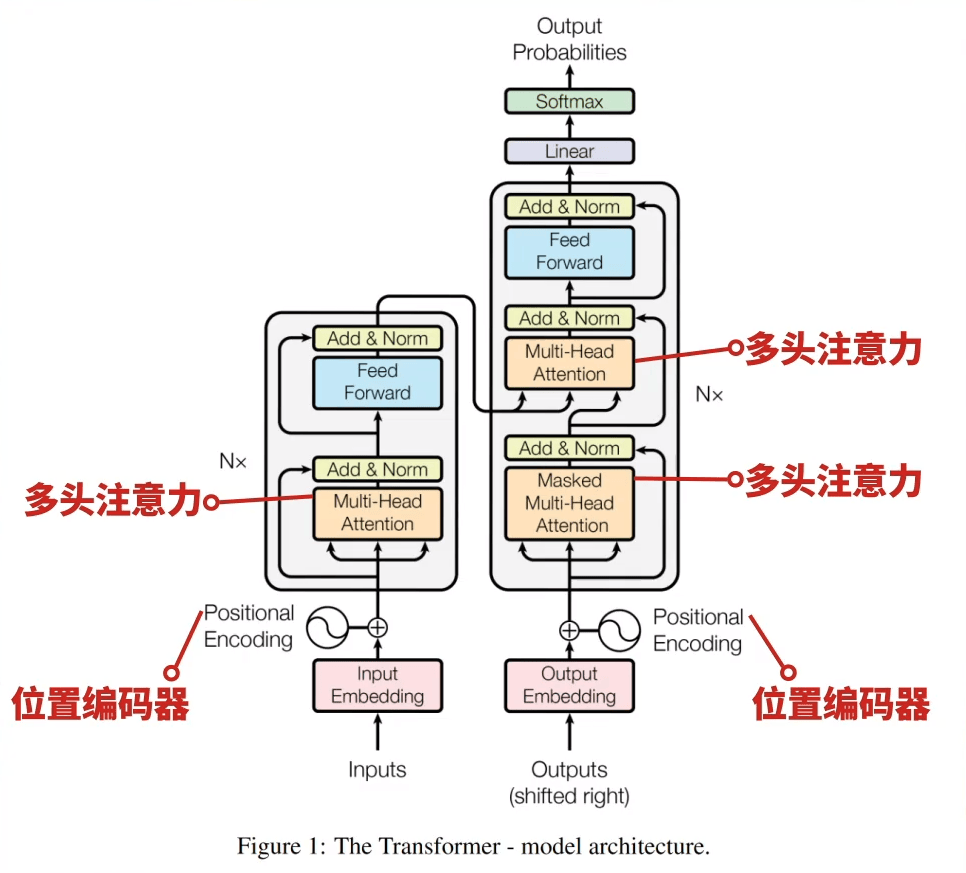
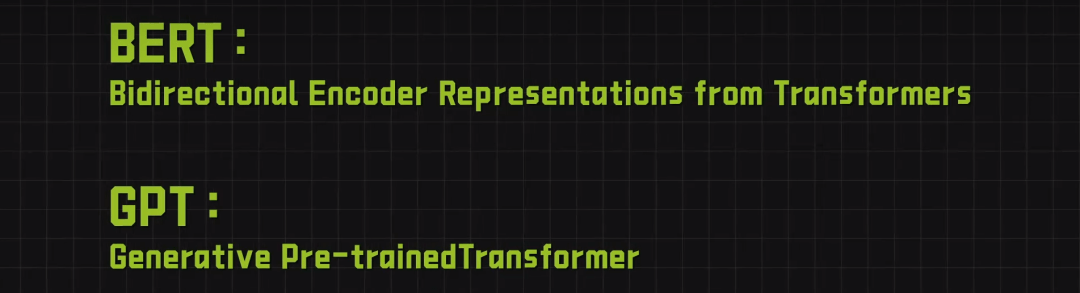
隨后,基于Transformer架構的BERT和GPT等模型相繼出現(xiàn),它們通過預訓練和微調的方式,在多種NLP任務上取得了突破性的性能。
2022年
之后的故事大家都很熟悉了,2022年chatgpt橫空出世,大模型的涌現(xiàn)一發(fā)不可收拾。你知道他們?yōu)槭裁唇写竽P蛦幔渴且驗檫@些模型的參數(shù)量已經(jīng)達到了百億甚至千億級別!
AI體系化學習路線
學習資料免費領
【后臺私信】AI全體系學習路線超詳版+100余講AI視頻課程 +AI實驗平臺體驗權限
全體系課程詳情介紹

-
AI
+關注
關注
91文章
39820瀏覽量
301496 -
人工智能
+關注
關注
1817文章
50102瀏覽量
265518 -
大模型
+關注
關注
2文章
3651瀏覽量
5193
發(fā)布評論請先 登錄
淺談人工智能(2)

《人工智能應用開發(fā)-中級(大模型)》認證證書含金量如何?怎么考?

未來工業(yè)AI發(fā)展的三個必然階段
專家觀點丨大模型技術發(fā)展的五個重點方向

【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
利用超微型 Neuton ML 模型解鎖 SoC 邊緣人工智能
挖到寶了!人工智能綜合實驗箱,高校新工科的寶藏神器
挖到寶了!比鄰星人工智能綜合實驗箱,高校新工科的寶藏神器!
超小型Neuton機器學習模型, 在任何系統(tǒng)級芯片(SoC)上解鎖邊緣人工智能應用.
人工智能技術的現(xiàn)狀與未來發(fā)展趨勢
迅為RK3588開發(fā)板Linux安卓麒麟瑞芯微國產工業(yè)AI人工智能
最新人工智能硬件培訓AI基礎入門學習課程參考2025版(離線AI語音視覺識別篇)
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺,加速企業(yè)人工智能應用

AI人工智能隱私保護怎么樣




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論