 天數智芯天垓100率先完成百億級參數大模型訓練
天數智芯天垓100率先完成百億級參數大模型訓練

6月,在第五屆智源大會AI系統分論壇上,上海天數智芯半導體有限公司(以下簡稱“天數智芯”)對外宣布,在天垓100加速卡的算力集群,基于北京智源人工智能研究院(以下簡稱“智源研究院”)70億參數的Aquila語言基礎模型,使用代碼數據進行繼續訓練,穩定運行19天,模型收斂效果符合預期,證明天數智芯有支持百億級參數大模型訓練的能力。
在北京市海淀區的大力支持下,智源研究院、天數智芯與愛特云翔共同合作,聯手開展基于自主通用GPU的大模型CodeGen(高效編碼)項目,通過中文描述來生成可用的C、Java、Python代碼以實現高效編碼。智源研究院負責算法設計、訓練框架開發、大模型的訓練與調優,天數智芯負責提供天垓100加速卡、構建算力集群及全程技術支持,愛特云翔負責提供算存網基礎硬件及智能化運維服務。
在三方的共同努力下,在基于天垓100加速卡的算力集群上,100B Tokens編程語料、70億參數量的AquilaCode大模型參數優化工作結果顯示,1個Epoch后loss下降到0.8,訓練速度達到87K Tokens/s,線性加速比高達95%以上。與國際主流的A100加速卡集群相比,天垓100加速卡集群的收斂效果、訓練速度、線性加速比相當,穩定性更優。在HumanEval基準數據集上,以Pass@1作為評估指標,自主算力集群訓練出來的模型測試結果達到相近參數級別大模型的SOAT水平,在AI編程能力與國際主流GPU產品訓練結果相近。
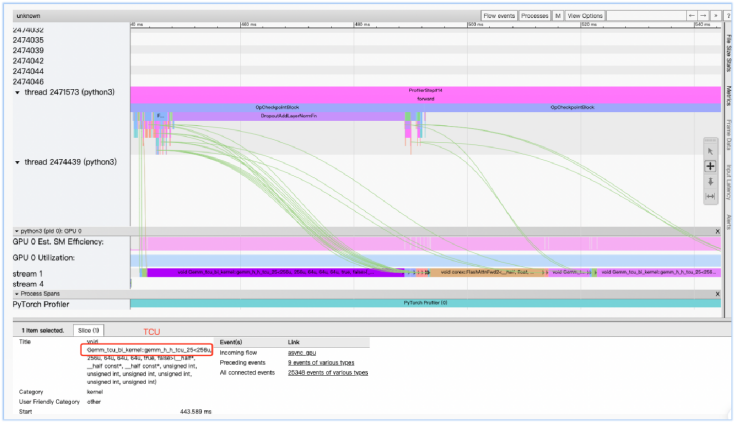
圖 基于天垓100算力集群的AquilaCode大模型訓練性能采樣
天垓100率先完成百億級參數大模型訓練,邁出了自主通用GPU大模型應用的重要的一步。這一成果充分證明了天垓產品可以支持大模型訓練,打通了國內大模型創新發展的關鍵“堵點”,對于我國大模型自主生態建設、產業鏈安全保障具有十分重大的意義。
接下來,天數智芯將與合作伙伴們繼續深入合作,建設更大規模的天垓100算力集群,完成更大參數規模的大模型訓練,以自主通用GPU產品更好支持國內大模型創新應用,進一步夯實我國算力基礎,助力人工智能產業自主生態建設。
責任編輯:彭菁
-
編程
+關注
關注
90文章
3716瀏覽量
97185 -
模型
+關注
關注
1文章
3752瀏覽量
52107 -
天數智芯
+關注
關注
0文章
102瀏覽量
6617
原文標題:天垓100率先完成百億級參數大模型訓練,天數智芯迎來新的里程碑
文章出處:【微信號:IluvatarCoreX,微信公眾號:天數智芯】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

天數智芯重磅公布四代架構路線圖,對標英偉達

欣旺達第100萬顆684Ah疊片電芯順利下線
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
借助NVIDIA Megatron-Core大模型訓練框架提高顯存使用效率

萬億參數!元腦企智一體機率先支持Kimi K2大模型
沐曦MXMACA軟件平臺在大模型訓練方面的優化效果

兆芯率先展開文心系列模型深度技術合作
Say Hi to ERNIE!Imagination GPU率先完成文心大模型的端側部署

MediaTek天璣9400率先完成阿里Qwen3模型部署
AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
憶聯PCIe 5.0 SSD支撐大模型全流程訓練



 工商網監
工商網監
評論