") 7個強大實用的Python機器學習庫!
7個強大實用的Python機器學習庫!

我們總說“不要重復發(fā)明輪子”,python 中的第 3 方工具庫就是最好的例子。借助它們,我們可以用簡單的方式編寫復雜且耗時的代碼。在本篇內(nèi)容中給大家整理了 7 個有用的 Python 庫,如果大家從事機器學習工作,一定要來一起了解一下。1.Prophet
Prophet是 Facebook 開源的時間序列預測工具庫,基于 Stan 框架,可以自動檢測時間序列中的趨勢、周期性和節(jié)假日效應,并根據(jù)這些信息進行預測。這個庫在 GitHub 上有超過 15k 星。
 Prophet 通常用于預測未來幾個月、幾年或幾十年的時間序列數(shù)據(jù),例如銷售額、市場份額等。它提供了 Python 和 R 兩個版本,可以跨平臺使用,支持 CPU 和 GPU 的并行運算。Prophet 的輸入數(shù)據(jù)格式要求是一個包含時間戳和目標值的數(shù)據(jù)框,并支持給定時間范圍、預測期限和寬限期等參數(shù)進行預測。Prophet 對缺失數(shù)據(jù)和趨勢變化很穩(wěn)健,通常可以很好地處理異常值。
Prophet 通常用于預測未來幾個月、幾年或幾十年的時間序列數(shù)據(jù),例如銷售額、市場份額等。它提供了 Python 和 R 兩個版本,可以跨平臺使用,支持 CPU 和 GPU 的并行運算。Prophet 的輸入數(shù)據(jù)格式要求是一個包含時間戳和目標值的數(shù)據(jù)框,并支持給定時間范圍、預測期限和寬限期等參數(shù)進行預測。Prophet 對缺失數(shù)據(jù)和趨勢變化很穩(wěn)健,通常可以很好地處理異常值。
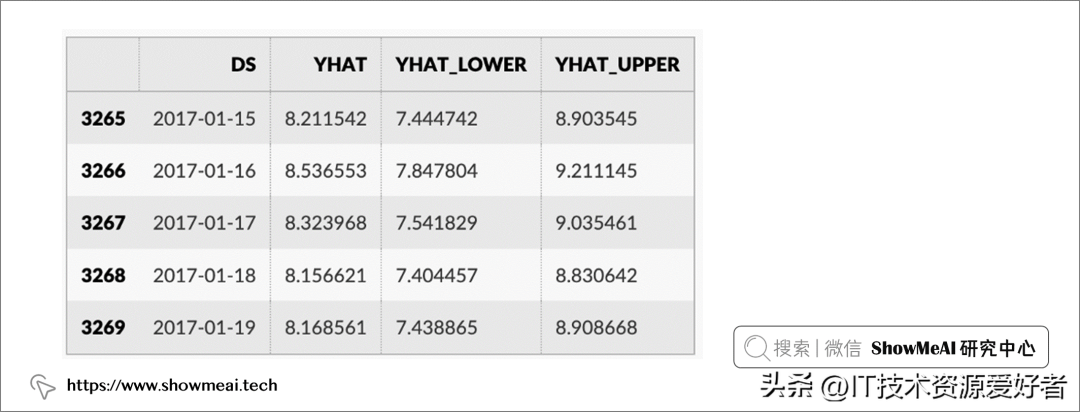
# Pythonforecast = m.predict(future)forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
2.Deep Lake
Deep Lake是一種數(shù)據(jù)集格式,提供簡單的 API 以用于創(chuàng)建、存儲和協(xié)作處理任何規(guī)模的 AI 數(shù)據(jù)集。這個庫在 GitHub 上有超過 5k 星。 Deep Lake 的數(shù)據(jù)布局可以在大規(guī)模訓練模型的同時,實現(xiàn)數(shù)據(jù)的快速轉換和流式傳輸。谷歌、Waymo、紅十字會、牛津大學等都在使用 Deep Lake。
Deep Lake 的數(shù)據(jù)布局可以在大規(guī)模訓練模型的同時,實現(xiàn)數(shù)據(jù)的快速轉換和流式傳輸。谷歌、Waymo、紅十字會、牛津大學等都在使用 Deep Lake。
for epoch in range(2): running_loss = 0.0 for i, data in enumerate(deeplake_loader): images, labels = data['images'], data['labels'] # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(images) loss = criterion(outputs, labels.reshape(-1)) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 100 == 99: #print every 100 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100)) running_loss = 0.0
3.Optuna
Optuna 是一個自動機器學習超參數(shù)調優(yōu)工具,可以幫助用戶通過使用各種規(guī)則自動調整機器學習模型的超參數(shù),以提高模型的性能。這個庫在 GitHub 上擁有超過 7k 顆星。

import ... # Define an objective function to be minimized.def objective(trial): # Invoke suggest methods of a Trial object to generate hyperparameters regressor_name = trial.suggest_categorical('regressor',['SVR', 'RandomForest']) if regressor_name = 'SVR': svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True) regressor_obj = sklearn.svm.SVR(C=svr_c) else: rf_max_depth = trial.suggest_int('rf_max_depth', 2, 332) regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth) X, y = sklearn.datasets.fetch_california_housing(return_X_y=True) X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0) regressor_obj.fit(X_train, y_train) y_pred = regressor_obj.predict(X_val) error = sklearn.metrics.mean_squared_error(y_val, y_pred) return error # An objective value linked with the Trial object. study = optuna.create_study() # Create a neW studystudy.optimize(objective, n_trials=100) # Invoke opotimization of the objective function
4.pycm
pycm是一個用于計算二分類和多分類指標的 Python 庫。這個庫在 GitHub 上有超過 1k 星。

它可以計算多種常用的指標,包括準確率、召回率、F1值、混淆矩陣等。此外,pycm 還提供了一些額外的功能,例如可視化混淆矩陣、評估模型性能的指標來源差異等。pycm是一個非常實用的庫,可以幫助快速評估模型的性能。
from pycm import *y_actu = [2, 0, 2, 2, 0, 1, 1, 2, 2, 0, 1, 2] y_pred = [0, 0, 2, 1, 0, 2, 1, 0, 2, 2, 2, 2] cm = ConfusionMatrix(actual_vector=y_actu, predict_vector=y_pred) cm.classes cm.print_matrix() cm.print_normalized_matrix()
5.NannyML
NannyML是一個開源的 Python 庫,允許估算部署后的模型性能(而無需訪問目標),檢測數(shù)據(jù)漂移,并智能地將數(shù)據(jù)漂移警報鏈接回模型性能的變化。這個庫在 GitHub 上有超過 1k 星。

為數(shù)據(jù)科學家設計的 NannyML 具有易于使用的交互式可視化界面,目前支持所有表格式的用例(tabular use cases)、分類(classification)和回歸(regression)。NannyML 的核心貢獻者研發(fā)了多種用于估算模型性能的新算法:基于信心的性能估算(CBPE)與直接損失估算(DLE)等。NannyML 通過構建“性能監(jiān)控+部署后數(shù)據(jù)科學”的閉環(huán),使數(shù)據(jù)科學家能夠快速理解并自動檢測靜默模型故障。通過使用 NannyML,數(shù)據(jù)科學家最終可以保持對他們部署的機器學習模型的完全可見性和信任。
import nannyml as nmlfrom IPython.display import display # Load synthetic data reference, analysis, analysis_target = nml.load_synthnetic_binary_classification_dataset()display(reference.head())display(analysis.head()) # Choose a chunker or set a chunk sizechunk size = 5000 # initialize, specify required data columns,, fit estimator and estimateestimator = nml.CBPE( y_pred_proba='y_pred_proba', y_pred='y_pred', y_true='work_home_actual', metrics=['roc_auc'], chunk_size=chunk_size, problem_type='classification_binary',)estimator = estimator.fit(reference)estimated_performance = estimator.estimate(analysis) # Show resultsfigure = estimated_performance.plot(kind='performance', metric='roc_auc', plot_reference=True)figure.show()
6.ColossalAI
ColossalAI是一個開源機器學習工具庫,用于構建和部署高質量的深度學習模型。這個庫在 GitHub 上有超過 6.5k 星。

ColossalAI 提供了一系列預定義的模型和模型基礎架構,可用于快速構建和訓練模型。它還提供了一系列工具,用于模型評估,調優(yōu)和可視化,以確保模型的高質量和準確性。此外,ColossalAI 還支持部署模型,使其能夠通過各種不同的接口與其他系統(tǒng)集成。ColossalAI 的優(yōu)勢在于它易于使用,可以為數(shù)據(jù)科學家和機器學習工程師提供快速和有效的方法來構建和部署高質量的大型模型。
from colossalai.logging import get_dist_loggerfrom colossalai.trainer import Trainer, hooks # build components and initialize with colossaalai.initialize... # create a logger so that trainer can log on thhe consolelogger = get_dist_logger() # create a trainer objecttrainer = Trainer( engine=engine, logger=logger)
7.emcee
emcee是一個開源的 Python 庫,用于使用 Markov chain Monte Carlo(MCMC)方法進行模型擬合和參數(shù)估計。這個庫在 GitHub 上有超過 1k 星。
import numpy as npimport emcee def log_prob(x, ivar): return -0.5 * np.sum(ivar * x ** 2) ndim, nwalkers = 5, 100 ivar = 1./np.random.rand(ndim)p0 = np.random.randn(nwalkers, ndim) sampler = emcee.EnsembleSampler(nwalkers, ndim, log_prob, args=[ivar])sampler.run_mcmc(p0, 10000)
總結
以上就是給大家做的工具庫介紹,這7個工具庫都是非常有用的,對于機器學習工作者來說,它們可以大大提高工作效率,讓你能夠在簡單的方式下編寫復雜的代碼。所以,如果你還沒有了解這些工具庫的話,不妨花一點時間來了解一下。
-
機器學習
+關注
關注
66文章
8553瀏覽量
136953 -
python
+關注
關注
57文章
4876瀏覽量
90034 -
GitHub
+關注
關注
3文章
488瀏覽量
18671
原文標題:【推薦】7個強大實用的Python機器學習庫!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
如何在 Vision Five 2 上安裝 python 庫?
無法去除 Python VisionFive.i2c 庫的終端輸出?
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

探索RISC-V在機器人領域的潛力
Python調用API教程
自制巡線解迷宮機器人(上)
termux如何搭建python游戲
C++ 與 Python:樹莓派上哪種語言更優(yōu)?

linux虛擬環(huán)境中調用Linux 版matlab編譯的python庫時出錯
基于米爾瑞芯微RK3576開發(fā)板的創(chuàng)建機器學習環(huán)境方案
python入門圣經(jīng)-高清電子書(建議下載)
十大鮮為人知卻功能強大的機器學習模型

**【技術干貨】Nordic nRF54系列芯片:傳感器數(shù)據(jù)采集與AI機器學習的完美結合**
?如何在虛擬環(huán)境中使用 Python,提升你的開發(fā)體驗~



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論