") 通過場景l(fā)andmark做定位的新思路(CVPR 2022)
通過場景l(fā)andmark做定位的新思路(CVPR 2022)

主要內(nèi)容:提出了一種基于學習的相機定位算法,其無需存儲圖像特征和場景三維點云,降低了存儲限制,通過識別場景中稀疏但顯著有代表性的landmark來找到2D-3D對應(yīng)關(guān)系進行后續(xù)的魯棒姿態(tài)估計,通過訓練檢測landmark的場景特定的CNN來實現(xiàn)所提出的想法,即回歸輸入圖像中對應(yīng)landmark的2D坐標。

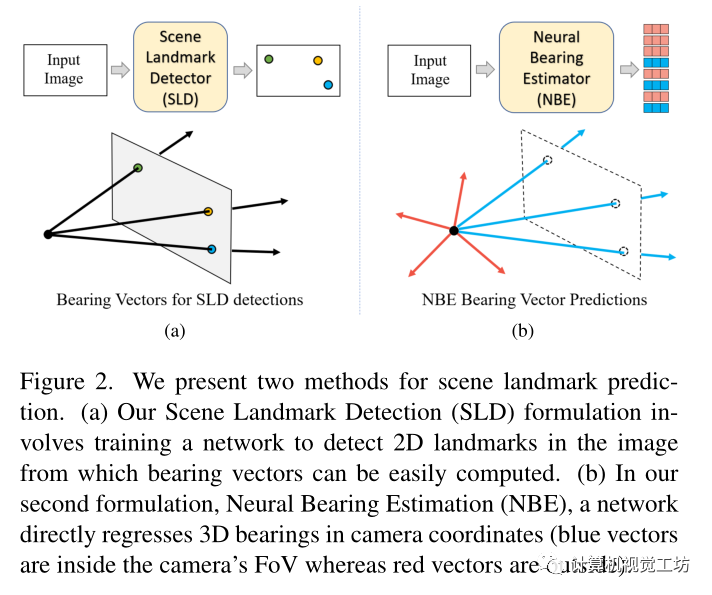
創(chuàng)新點與Contributions:1)與大多數(shù)landmark通常可見的人體姿態(tài)估計不同,由于相機視野有限并且無法同時觀察場景的不同部分,相機姿態(tài)估計任務(wù)中大多數(shù)場景l(fā)andmark不會同時可見,文章通過提出一種新的神經(jīng)方位估計器(Neural Bearing Estimator,NBE)來解決這一問題,該估計器可以直接回歸相機坐標系中場景l(fā)andmark的3D方位向量,NBE學習全局場景表示的同時學習預測場景l(fā)andmark的方向向量,即使它們不可見。 2)提出了一個新的室內(nèi)定位數(shù)據(jù)集,INDOOR-6,相對于傳統(tǒng)的7-Scenes室內(nèi)數(shù)據(jù)集,包含更多變化的場景、晝夜圖像和強烈的照明變化 3)與現(xiàn)有的無存儲定位方法相比,具有低存儲的優(yōu)點且性能較好 文章提出了兩種預測圖像中場景l(fā)andmark的方法,在第一種方法中訓練了一個模型來識別圖像中的2D場景地標,稱之為場景地標檢測器(SLD),由于假設(shè)已知的相機內(nèi)參,這些2D檢測可以轉(zhuǎn)換為3D方位矢量或射線。在第二種方法中訓練了一個不同的模型直接預測相機坐標系中l(wèi)andmark的3D方位向量,稱之為神經(jīng)方位估計器(NBE)。注:使用SLD,只能檢測到相機視場(FoV)中可見的landmark,而NBE預測所有l(wèi)andmark的方位,包括相機視場外不可見的landmark。
首先會有一個SFM構(gòu)建的點云模型,會在這些點云中挑選出有代表性的點云子集,用這些子集以及建圖時SFM算法生成的數(shù)據(jù)庫圖像的偽真值來訓練兩個提出的網(wǎng)絡(luò)模型。SLD:SLD被設(shè)計為將RGB圖像I作為輸入并輸出一組像素似然圖(熱圖)表示每個可見地標的位置,其模型架構(gòu)如下:
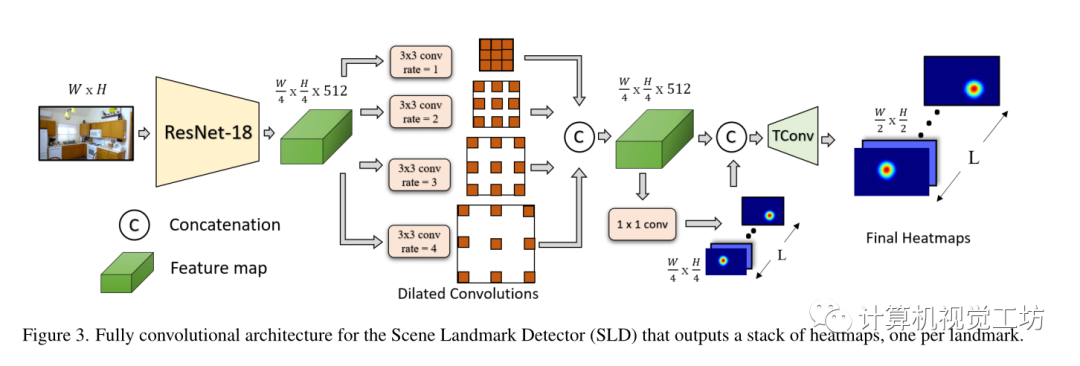
由四個主要組件組成:使用ResNet-18為backbone,刪除最后三個最大池化層以保留高分辨率特征圖(輸出分辨率為輸入圖像分辨率的四分之一),其次在ResNet-18之后使用擴張卷積塊,擴張率設(shè)置為1、2、3和4,接下來轉(zhuǎn)置卷積層執(zhí)行上采樣,并負責生成分辨率為輸入圖像一半的熱圖,最后一層由1×1卷積組成,預測L個熱圖通道,每個地標一個。 訓練損失:

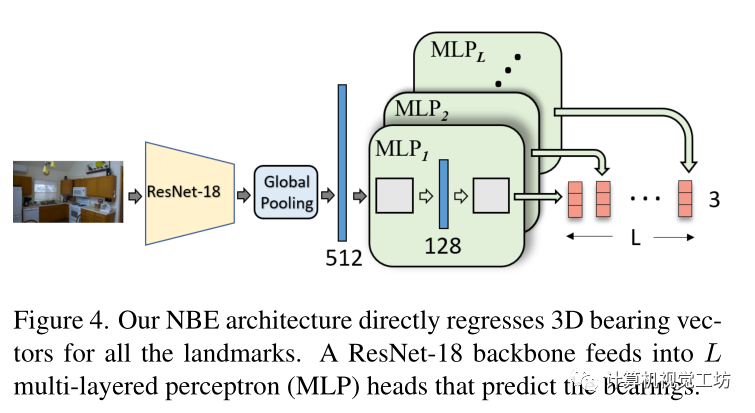
在推斷過程中,假設(shè)當其最大熱圖值超過閾值τ=0.2時表明檢測到地標,利用亞像素精度計算熱圖峰值位置處裁剪的17×17 patch的期望值。NBE:設(shè)計了一個模型在給定圖像I的情況下回歸全部場景l(fā)andmark(即使它不可見)的方位向量。 CNN將圖像I作為輸入以生成深度特征圖,然后是多個MLP(多層感知器)塊,每個塊輸出指向landmark的方向向量,MLP包含兩個全連接層,具有128個ReLU激活節(jié)點。

訓練好兩個模型后,將每個查詢圖像輸入SLD網(wǎng)絡(luò)以獲得2D檢測,然后根據(jù)內(nèi)參將其轉(zhuǎn)換為一組landmark方位向量B1,如果檢測到超過八個場景l(fā)andmark,使用魯棒最小解算器(P3P+RANSAC)計算相機姿態(tài),然后使用基于Levenberg-Marquardt的非線性細化。如果沒有8個,將相同的圖像輸入NBE網(wǎng)絡(luò)并獲得預測方位B2,然后合并方位估計B1和B2的集合以形成新的集合B3,當集合B1和B2中的方位指向同一地標時,保留來自B1的估計,因為SLD通常比NBE更準確。最后使用上面描述的相同過程但使用B3計算相機姿態(tài)。如何從點云中選擇有代表性的場景l(fā)andmark提供給網(wǎng)絡(luò)進行訓練?從SfM點云P中找到L個場景l(fā)andmark的最佳子集是一個組合問題,其中評估每個子集都是困難的。本文受之前以貪婪的方式尋找有區(qū)別的關(guān)鍵點或場景元素工作的啟發(fā),去選擇魯棒性(具有更長的軌跡)、可重復性(在多個場景中看到)和可概括性(從許多不同的觀看方向和深度觀察)的場景l(fā)andmark,測量軌跡長度大于閾值t的3D點x的顯著性得分A(x),如下所示:

除了最大化總體顯著性得分之外還尋找在空間上覆蓋3D場景的場景l(fā)andmark以便從場景內(nèi)的任何地方都可以看到一些地標,例如無論攝像機在場景中的哪個位置都希望一些地標可見。為此使用算法1中描述的約束貪婪方法

下圖表述一些挑選到的landmark在二維圖像中的投影的裁剪patch

實驗:訓練模型的細節(jié)可去論文中查看 實驗數(shù)據(jù)集是在自己提出的INDOOR-6數(shù)據(jù)集和7Scenes數(shù)據(jù)集上

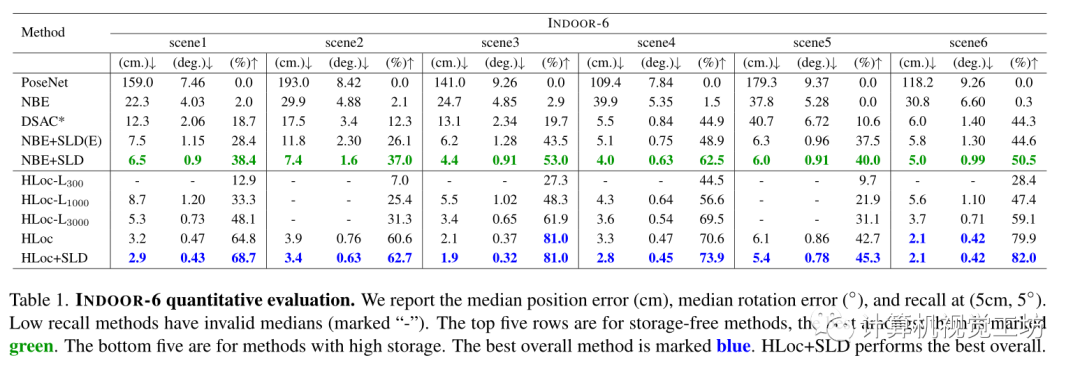
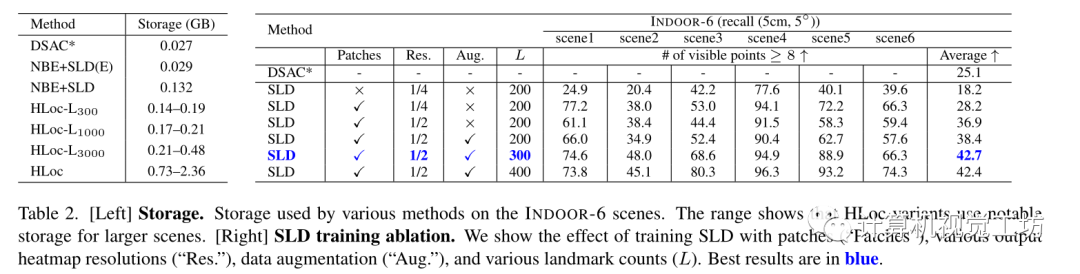
評估了單獨使用NBE, SLD,聯(lián)合使用NBE+SLD, NBE+SLD(E)(是更緊湊的網(wǎng)絡(luò)),和SOTA的基于分層定位方法結(jié)合HLoc+SLD Baseline為Posenet、DSAC、HLoc 在INDOOR-6數(shù)據(jù)集上的結(jié)果:

存儲比較和消融研究:
7Scenes數(shù)據(jù)集上的實驗結(jié)果:
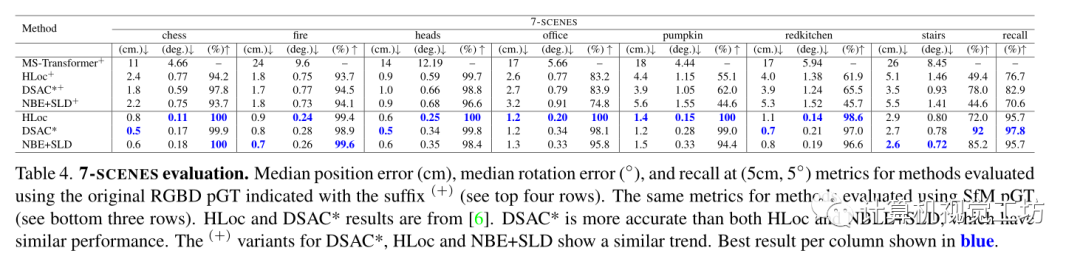
總結(jié):算法是一種存儲要求低但精度高的方法。主要見解是在人和物體姿態(tài)估計中廣泛用于關(guān)鍵點檢測的現(xiàn)代CNN架構(gòu)也適用于檢測顯著的、場景特定的3D landmark。 實驗結(jié)果表明,其方法優(yōu)于以前的無存儲方法,但不如HLoc(頂級檢索和匹配方法之一)準確,但是HLoc需要高存儲。而且基于landmark的2D–3D對應(yīng)關(guān)系補充了HLoc的對應(yīng)關(guān)系,并且在計算姿態(tài)之前結(jié)合這些對應(yīng)關(guān)系進一步提高了HLoc精度。局限性:首先神經(jīng)網(wǎng)絡(luò)是特定于場景的,像其他學習方法一樣每個場景需要許多訓練圖像,而且在使用之前需要仔細選擇場景l(fā)andmark集。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107834 -
算法
+關(guān)注
關(guān)注
23文章
4784瀏覽量
98086 -
cnn
+關(guān)注
關(guān)注
3文章
355瀏覽量
23429
原文標題:通過場景l(fā)andmark做定位的新思路(CVPR 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
從智慧醫(yī)療到多元商業(yè)場景的室內(nèi)人員定位技術(shù)應(yīng)用詳解
Nullmax研發(fā)團隊靜態(tài)元素檢測和拓撲推理新成果入選CVPR 2026
數(shù)字音頻放大器新思路:MAX98360全方位解析
北斗衛(wèi)星導航定位技術(shù)從核心誤差修正方法、不同定位模式到工業(yè)場景融合應(yīng)用詳解(二)
室內(nèi)人員定位手環(huán)從核心技術(shù)的差異、核心功能、應(yīng)用場景及選購要點詳解
uwb人員定位卡的功能、原理和應(yīng)用場景詳解

開源鴻蒙技術(shù)大會2025丨定位與感知分論壇:構(gòu)建開源鴻蒙全場景定位感知用戶體驗

GPS定位和地磁定位有什么區(qū)別?

常見的室內(nèi)定位技術(shù)有哪些?深度剖析UWB、藍牙定位等技術(shù)的優(yōu)劣與應(yīng)用場景

毫米級定位+全場景記錄:鐵路高精度定位工作記錄儀助力鐵路線路巡查

諧波 THD 超標,如何通過監(jiān)測數(shù)據(jù)定位諧波源?

易控智駕榮獲計算機視覺頂會CVPR 2025認可
傳音多媒體團隊攬獲CVPR NTIRE 2025兩項挑戰(zhàn)賽冠亞軍




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論