 緩存分區可提高安全關鍵型多核應用程序的CPU利用率
緩存分區可提高安全關鍵型多核應用程序的CPU利用率

緩存分區減少了關鍵任務的最壞情況下的執行時間,從而提高了 CPU 利用率,尤其是對于多核應用程序。
多核處理器 (MCP) 的可認證、安全關鍵型軟件應用程序的開發人員面臨的最大挑戰之一是管理對共享資源(如緩存)的訪問。MCP 顯著增加緩存爭用,導致最壞情況執行時間 (WCET) 超過平均案例執行時間 (ACET) 100% 或更多。由于安全關鍵型開發人員必須為 WCET 制定預算,因此平均分配的任務(關鍵和非關鍵)的時間超過了所需的時間,從而導致 CPU 利用率顯著降低。解決此問題的一種方法是利用支持緩存分區的 RTOS,它使開發人員能夠以減輕爭用和減少 WCET 的方式綁定和控制干擾模式,從而在不影響安全關鍵性的情況下最大化可用 CPU 帶寬。
緩存爭用
在簡單的雙核處理器配置(圖 1)中,每個內核都有自己的 CPU 和 L1 緩存。兩個內核共享一個二級緩存。(請注意,未顯示共享內存和可選 L3。
圖1:雙核配置,無需緩存分區

在此配置中,在核心 0 上執行的應用程序與在核心 1 上執行的應用程序競爭整個二級緩存。(請注意,同一內核上的應用程序也會相互競爭 L2;緩存分區也適用于這種情況。如果核心 0 上的應用程序 A 使用的數據映射到與核心 1 上的應用程序 B 相同的緩存行,則會發生沖突。
例如,假設 A 的數據駐留在 L2 中;對該數據的任何訪問都將花費很少的處理器周期。但假設 B 訪問的數據恰好映射到與 A 的數據相同的 L2 緩存行。此時,必須從 L2 中逐出 A 的數據(包括對 RAM 的潛在“寫回”),并且必須將 B 的數據從 RAM 中引入緩存。處理此碰撞所需的時間通常由 B 收取。然后,假設 A 再次訪問其數據。由于該數據不再位于 L2 中(B 的數據在其位置),因此必須從 L2 中逐出 B 的數據(包括潛在的“寫回”到 RAM),并且 A 的數據必須從 RAM 中恢復到緩存中。處理此碰撞所需的時間通常由 A 收取。
大多數時候,A和B很少會遇到這樣的碰撞。在這些情況下,它們各自的執行時間可以被視為“平均情況”(ACET)。但是,有時,它們的數據訪問會以高頻率發生沖突。在這些情況下,它們各自的執行時間必須被視為“最壞情況”(WCET)。
在開發可認證的安全關鍵型軟件時,必須為最壞情況的行為預算應用程序的執行時間。此類軟件必須有足夠的時間預算才能在每次執行時完成其預期功能,以免導致不安全的故障情況。安全關鍵型 RTOS 必須強制實施時間分區,以便每個應用程序都有固定的 CPU 時間預算來執行。
由于多個內核上的多個應用程序可能會產生對 L2 緩存的爭用,因此 MCP 上的 WCET 通常比 ACET 高得多。由于可認證的安全關鍵型應用程序必須有時間預算來容納其 WCET,這種情況會導致大量預算但未使用的時間,從而導致 CPU 利用率顯著下降。
緩存分區
緩存分區通過減少 WCET 來提高 CPU 利用率,從而減少必須預算以容納 WCET 的時間量。同樣,在簡單的雙核處理器配置(圖 2)中,每個內核都有自己的 CPU 和 L1 緩存,并且兩個內核共享一個 L2 緩存。
圖2:具有緩存分區的雙核配置
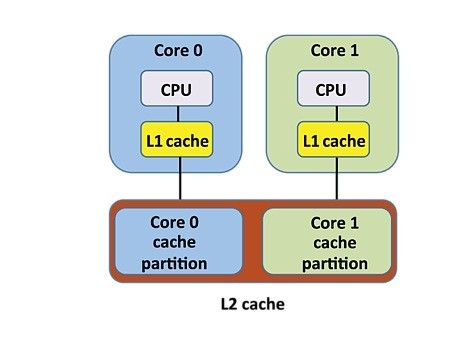
在此配置中,RTOS 對 L2 緩存進行分區,以便每個內核都有自己的 L2 段,這意味著內核 0 上的應用程序使用的數據將僅緩存在內核 0 的 L2 分區中。同樣,核心 1 上的應用程序使用的數據將僅緩存在核心 1 的 L2 分區中。這種分區消除了不同內核上的應用程序通過 L2 沖突相互干擾的可能性。如果沒有這種干擾,應用程序 WCET 和 ACET 之間的增量通常比沒有緩存分區的情況要低得多。通過限制和控制這些干擾模式,緩存分區使應用程序執行時間更具確定性,并使開發人員能夠更嚴格地預算執行時間,從而保持較高的處理器利用率。
測試環境和應用程序
為了演示緩存分區的優勢,DDC-I 使用 Deos(其可認證、安全關鍵、時間和空間分區的 RTOS)來運行一套四個內存密集型測試應用程序,所有這些應用程序都具有一系列數據/代碼大小、順序和隨機訪問策略以及各種工作集大小:
只讀
只寫
復制
代碼執行
測試是在具有 32 KB L1 數據緩存、24 KB L1 指令緩存和 512 KB 統一 L2 緩存的 1.6 GHz 凌動處理器 (x86) 上進行的。請注意,雖然這些測試使用了單核 x86 處理器,但 Deos 的緩存分區功能同樣適用于在同一內核上執行的應用程序(這些應用程序也競爭 L2)。此外,它不依賴于 x86 處理器所特有的任何功能,并且同樣適用于其他處理器類型(如 ARM 或 PowerPC)。
測試是在有和沒有“緩存垃圾箱”應用程序的情況下運行的,該應用程序從L2中逐出測試應用程序數據/代碼,并使用自己的數據/代碼“臟”L2。實際上,從測試應用程序的角度來看,緩存垃圾程序將 L2 置于最壞情況狀態。也就是說,緩存垃圾箱模擬真實場景,其中不同的應用程序同時運行并爭用共享的 L2 緩存。
每個測試應用程序在三種情況下執行。在場景 1 中,在沒有緩存分區或緩存垃圾的情況下執行,測試應用程序將競爭整個 512 KB 二級緩存以及 RTOS 內核和各種調試工具。此測試建立基線平均性能,其中每個測試都以“平均”數量的 L2 爭用執行。
在不使用緩存分區的場景 2 中,測試應用程序與 RTOS 內核、場景 1 中使用的同一組調試工具以及惡意緩存垃圾程序應用程序競爭整個 512 KB 二級緩存。此測試建立基線最壞情況性能,其中每個測試在來自其他應用程序(主要是緩存垃圾程序)的最壞情況下執行 L2 干擾。
在使用緩存分區和緩存垃圾的場景 3 中,將創建三個 L2 分區:
分配給測試應用程序的 256 KB 分區
分配給 RTOS 內核的 64 KB 分區以及方案 1 和方案 2 中使用的同一組調試工具
分配給惡意緩存垃圾程序應用程序的 192 KB 分區。
此方案建立了優化的最壞情況性能,其中每個測試在其自己的 L2 分區內執行,不受其他應用程序(包括緩存垃圾程序)的干擾。
緩存分區結果、優勢
圖 3 顯示了只讀測試應用程序的結果。
圖3:緩存分區對只讀測試的影響
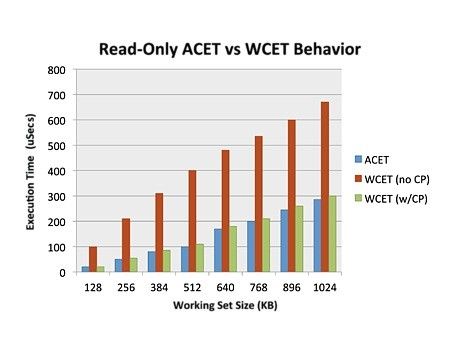
例如,在沒有緩存分區和緩存垃圾的情況下(方案 1,ACET),只讀測試在工作集大小為 512 KB 的情況下,每次執行的平均時間為 105 微秒。在方案 2(沒有分區的 WCET,添加了緩存垃圾箱)中,對于相同的 512 KB 工作集,測試平均每次執行 400 微秒,增加了 280%。添加緩存分區(方案 3,帶緩存垃圾的 WCET)時,平均執行時間降至 117 微秒,僅比 ACET 高 11%。
這些結果證明了緩存分區對于每個周期執行大量讀取的應用程序的有效性。盡管由于量級差異,此處很難辨別,但當應用程序的工作集大小適合其使用的緩存分區(在本例中為 256 KB)時,對邊界 WCET 的影響更為明顯。由于緩存的性質,此結果是預期的。也就是說,嵌入式實時應用程序的工作集大小往往相對較小,因此我們預計緩存分區將使大多數應用程序受益。
只寫測試的結果與只讀測試相似,但對于較小的工作集更明顯。對于較大的工作集,結果顯示具有和不具有緩存分區的 WCET 之間的差異相對較小。
復制測試的結果與只讀測試相似,但對于較小的工作集更明顯。對于較大的工作集,結果不那么顯著,但仍然顯示出具有緩存分區的 WCET 的顯著改進(大約 2 倍)。
代碼執行測試的結果與只讀測試類似,但稍微不那么引人注目。
請注意,在同一緩存分區中執行的應用程序可能會相互干擾。但是,與在具有共享緩存的不同內核上執行的應用程序之間可能發生的不可預測的干擾模式相比,此類干擾通常更容易分析和綁定。在這些情況下,如果干擾不可預測,則可以將應用程序映射到單獨的緩存分區。
基準測試結果清楚地表明,緩存分區提供了一種有效的方法來綁定和控制 MCP 上共享緩存中的干擾模式。特別是,在對緩存進行分區時,可以更嚴格地綁定和控制 WCET。這允許應用程序開發人員設置相對緊湊但安全的執行時間預算,從而最大限度地提高 MCP 利用率。
當然,不同的應用和硬件配置的結果會有所不同,并且需要額外的RTOS功能才能成功認證基于安全關鍵型MCP的系統。無論如何,這些結果代表了在使用MCP托管可認證的安全關鍵應用程序的目標方面的重大進步。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
20255瀏覽量
252342 -
cpu
+關注
關注
68文章
11279瀏覽量
225024
發布評論請先 登錄
GPU 利用率<30%?這款開源智算云平臺讓算力不浪費 1%
華為發布AI容器技術Flex:ai,算力平均利用率提升30%
內存與數據處理優化藝術
普迪飛 secureWISE 全鏈路守護方案:讓 Fab 生產 “遠程可控、數據可管、安全可溯”!

設備利用率算不清?智能管理系統自動分析數據,生成可視化報表幫你降本

從 “被動維修” 到 “主動管理”:這套系統讓設備利用率提升 30%

高性能緩存設計:如何解決緩存偽共享問題
海光DCU率先展開文心系列模型的深度技術合作 FLOPs利用率(MFU)達47%
Linux系統性能指南
mes工廠管理系統:如何讓設備利用率提升50%?
MCU緩存設計
DeepSeek MoE架構下的網絡負載如何優化?解鎖90%網絡利用率的關鍵策略





 工商網監
工商網監
評論