 采用GPU求解大幅提升性能的CFD模型
采用GPU求解大幅提升性能的CFD模型

你可以設想一下,如果每項任務都能節省幾分鐘、幾小時甚至幾天的時間,那一整年下來能節省多少時間啊。如果任務涉及計算流體動力學(CFD)仿真,且希望減少求解時間,那么Ansys Fluent GPU求解器正是您想要的解決方案。
無論是求解10萬個單元還是1億個單元的模型,傳統的減少仿真時間的方法都是使用大量CPU進行求解。近年來,另一種方法開始受到行業的關注,那就是使用圖形處理單元,簡稱GPU。這種方法首先是將CPU求解的某些部分交給GPU來處理,從而加速整體求解時間,這種做法被稱為“轉移”到GPU。
早在2014年,Ansys Fluent就采用了這項“轉移”技術,而今年我們則將GPU技術的使用發揮到全新的高度,在Fluent中推出了原生多GPU(multi-GPU)求解器。本地部署方案能提供GPU上的所有求解器特性,避免CPU和GPU之間因交換數據造成的開銷,從而相對于轉移技術能實現更好的提速。
釋放GPU對CFD的全部潛力需要將整個代碼運行在GPU上。
在系列博客的上半部分中,我們重點介紹了大型汽車外氣動仿真的32倍提速案例,不過并非所有用戶的仿真模型能達到如此大的規模。本文作為系列內容的下半部分,將重點介紹GPU針對包含更多物理功能的小規模模型的優勢,如多孔介質和共軛傳熱(CHT)。
各種不同規模的CFD仿真提速
從51.2萬個單元到700多萬個單元,本文介紹的模型采用GPU求解都能大幅提升性能。而且無需采用最昂貴的服務器級GPU就能大幅提升性能,因為Fluent GPU求解器可以使用您的筆記本或工作站GPU就能顯著縮短求解時間。口說無憑,請繼續往下看,了解原生多GPU求解器如何實現提速:
進氣系統提速8.32倍
牽引逆變器提速8.6倍
兩種不同的換熱器設計分別提速15.47倍和11倍
通過多孔過濾器的氣流
汽車進氣系統吸入的氣體通過過濾器清除雜物,讓清潔空氣進入引擎。這個仿真涉及710萬個單元,過濾器模型為多孔介質,粘滯阻力為1e+8m-2,慣性阻力為2,500m-1。空氣流入進氣系統的質量流率為0.08kg/s。
用一個NVIDIA A100 GPU求解后,優化進氣系統可實現8.32倍的提速。
我們采用四種不同的硬件配置求解該模型,三種配置采用Intel Xeon Gold 6242核心,一種配置采用一個NVIDIA A100 Tensor Core GPU。
使用單個NVIDIA A100 GPU相對于采用32個Intel Xeon Gold核心求解而言,能提速8.3倍。
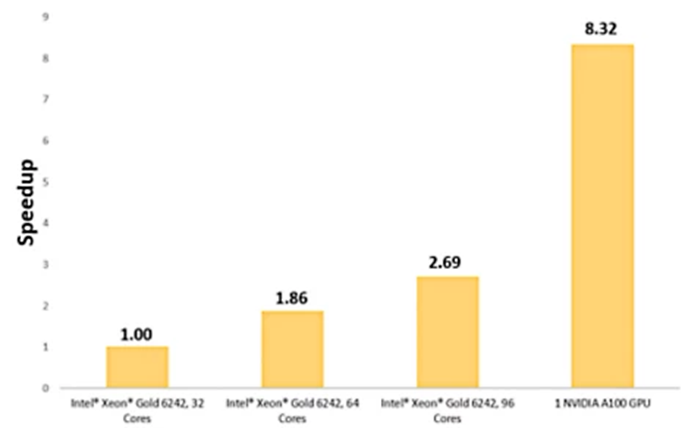
使用單個NVIDIA A100 GPU仿真通過多孔介質的氣流相對于32個Intel Xeon Gold核心而言,能實現8.3倍的提速
使用共軛傳熱建模(CHT)進行熱管理
在許多工業應用中,考慮到流體流動時造成的熱效應至關重要。為準確捕獲系統的熱行為,流體的傳熱與相鄰金屬的熱傳導耦合往往非常重要。我們的原生GPU求解器針對這種耦合CHT問題展示出了強大的提速特性。
以下給出三種涉及CHT的不同熱仿真,一個為400萬個單元的水冷式牽引逆變器,一個為140萬個單元的百葉窗翅片換熱器,還有一個為512,000個單元的立式散熱器。
水冷式牽引逆變器
涉及CHT的牽引逆變器仿真采用一個NVIDIA A100 GPU求解,可實現8.6倍的提速。
牽引逆變器從高壓電池獲得直流電(DC),并將其轉為交流電(AC)發送給電機。熱管理對牽引逆變器確保安全性和長期使用壽命至關重要。
以上所示模型為400萬個單元的水冷式牽引逆變器,其具有4個絕緣柵雙極晶體管(IGBT),熱負載為400 W。25℃的水以0.5 kg/s的速度流過外殼實現制冷,并使用對流邊界條件對周圍空氣的熱消耗進行建模。
采用一個NVIDIA A100 GPU求解問題,相對于32個Intel Xeon Gold 6242核心而言,可提速8.6倍。
百葉窗翅片換熱器
換熱器模型通過百葉窗翅片換熱器實現強制對流。這個待求解的問題涉及20℃的空氣以4 m/s的速度通過鋁制百葉窗翅片,以實現銅管制冷。
為獲得基準,我們在8個Intel Xeon Gold 6242核心上運行了140萬個單元的模型。在一個NVIDIA A100 GPU上運行完全相同的模型,可實現15.5倍的提速。
百葉窗翅片換熱器的溫度分布在一個NVIDIA A100上求解速度快15.47倍。
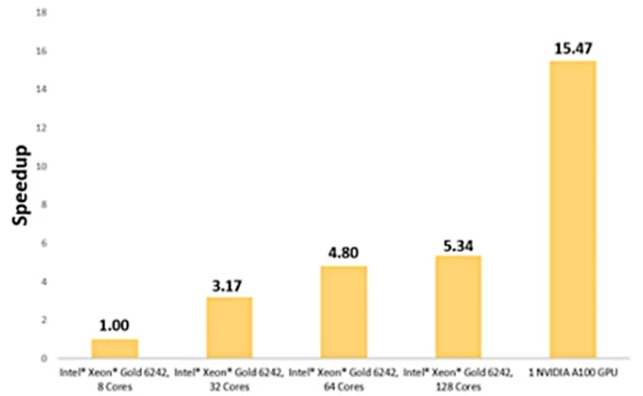
對百葉窗翅片換熱器而言,單GPU求解可實現15.47倍的提速
立式散熱器
最后一個問題涉及一個自由對流五翅片鋁制散熱器,基座保持恒溫76.85℃,周邊空氣環境溫度為16.85℃。
使用安裝有一個NVIDIA Quadro RTX 5000 GPU的一臺筆記本電腦求解包含512,000個單元的外殼,相對于采用六核Intel Core i7-11850H的筆記本電腦而言,可實現11倍的提速。
即便只采用一個NVIDIA Quadro RTX 5000筆記本顯卡GPU,使用Fluent中的原生多GPU求解器也能大幅縮短求解時間。如果采用類似的工作站圖形卡,還能進一步提高性能。
采用一個NVIDIA Quadro RTX 5000 GPU進行求解,512,000個單元的散熱器仿真能實現11倍的提速。
通過GPU實現CFD仿真變革
Fluent用戶現在能在只有一個GPU的筆記本或工作站上獲得強大功能和靈活性,當然也可以擴展至多GPU服務器上。利用您已有的硬件加速CFD仿真,獲得的提速超過您的想象。
Fluent中的原生多GPU求解器能運行在2016年之后推出的任何NVIDIA卡上,安裝的驅動程序版本不低于11.0或更新版本。
Ansys在GPU技術運用于仿真領域一直是領軍者,憑借新型求解器技術,將我們的技術水平提升到新的高度。原生GPU求解器中的所有特性都采用與Fluent CPU求解器相同的離散和數值方法,能在更短的時間內為用戶提供他們所期待的準確結果。
審核編輯:劉清
-
gpu
+關注
關注
28文章
5194瀏覽量
135450 -
服務器
+關注
關注
14文章
10253瀏覽量
91487 -
CFD
+關注
關注
1文章
171瀏覽量
19526 -
求解器
+關注
關注
0文章
85瀏覽量
4936
原文標題:Ansys Fluent:全力釋放GPU的無限潛力(下)
文章出處:【微信號:西莫電機論壇,微信公眾號:西莫電機論壇】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
登臨科技KS系列GPU產品全面適配MiniMax M2.5模型

Altair CFD 以技術賦能工程創新?
Simcenter FLOEFD for PTC Creo:CAD完全嵌入式計算流體力學(CFD)軟件

Simcenter FLOEFD for CATIA V5:CAD嵌入式前置計算流體力學(CFD)軟件
FLOEFD:告別低效CFD分析!
Simcenter FLOEFD for Siemens NX:CAD 嵌入式前置計算流體力學(CFD)軟件
Simcenter FLOEFD擴展設計探索模塊:通過設計探索和優化擴展CFD功能
如何在Ray分布式計算框架下集成NVIDIA Nsight Systems進行GPU性能分析
別讓 GPU 故障拖后腿,捷智算GPU維修室來救場!

如何使用sizefield功能進行CFD網格細化
為什么無法在GPU上使用INT8 和 INT4量化模型獲得輸出?
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
摩爾線程GPU率先支持Qwen3全系列模型
提升AI訓練性能:GPU資源優化的12個實戰技巧




 工商網監
工商網監
評論