") 一文帶你讀懂全景分割
一文帶你讀懂全景分割

圖像分割(image segmentation)是根據(jù)灰度、色彩、空間紋理、幾何形狀等特征將圖片分成若干個特定的、具有獨特性質(zhì)的區(qū)域,并提出感興趣目標的技術(shù)和過程。
目前圖像分割發(fā)展出以下幾個子領(lǐng)域:
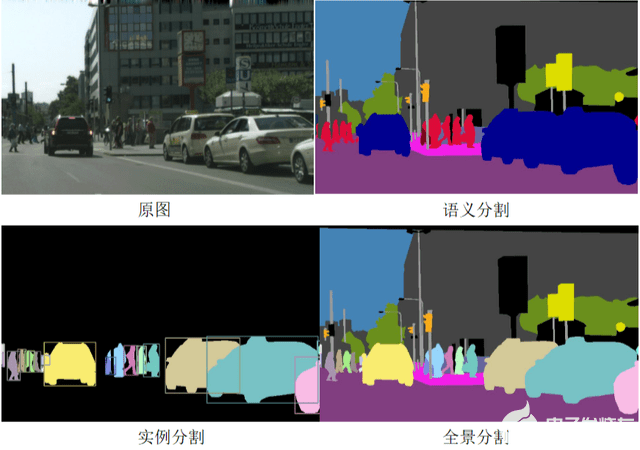
語義分割(semantic segmentation)
是將輸入圖像中的每個像素點預(yù)測為不同的語義類別。更注重類別之間的區(qū)分,會重點將前景里的車輛和背景里的房屋、天空、地面分割開,但是不區(qū)分重疊車輛。主要有FCN,DeepLab,PSPNet等方法。
實例分割(instance segmentation)
是目標檢測和語義分割的結(jié)合,將輸入圖像中的目標檢測出來,對目標包含的每個像素分配類別標簽。更注重前景中目標個體之間的分割,背景的房屋、天空、地面均為一類。主要有DeepMask,Mask R-CNN,PANet等方法。
全景分割(panoptic segmentation)
是語義分割和實例分割的綜合,旨在同時分割實例層面的目標(thing)和語義層面的背景內(nèi)容(stuff),將輸入圖像中的每個像素點賦予類別標簽和實例ID,生成全局的,統(tǒng)一的分割圖像。
01 全景分割的應(yīng)用與發(fā)展
從輸入數(shù)據(jù)上分類,全景分割可以分為基于RGB圖像的全景分割和基于點云數(shù)據(jù)的全景分割。
基于RGB圖像的全景分割算法可以分為三類。
1.box-based,thing和stuff使用不同的分支預(yù)測,其中thing的分割基于目標檢測boxes。
如Panoptic FPN模型,首先進行特征提取,然后接兩個分支分別預(yù)測實例分割和語義分割。其中實例分割分支的預(yù)測過程是先預(yù)測出實例的boxes,再在每個box的范圍內(nèi)預(yù)測出對應(yīng)的實例分割,所以box-based的全景分割最終的預(yù)測結(jié)果主要取決于boxes的預(yù)測精度。語義分割分支直接預(yù)測輸出結(jié)果。最后融合兩個分支結(jié)果得到全景分割。
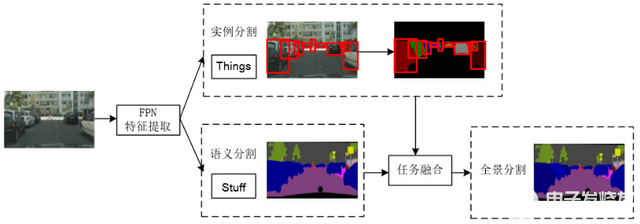
由于通過兩個分支分別預(yù)測thing和stuff,會導(dǎo)致出現(xiàn)兩個分支預(yù)測結(jié)果有重合區(qū)域,后處理去重過程和NMS比較類似:
(1)根據(jù)不同thing的置信度來去除重疊部分;
(2)以thing優(yōu)先原則去除thing和stuff之間的重疊部分;
(3)去除stuff標記為“其他”或者低于給定面積閾值的區(qū)域。
上述模型中
使用FPN(Feature Pyramid Network)特征金字塔網(wǎng)絡(luò)作為主干網(wǎng)絡(luò)。使用一個標準的網(wǎng)絡(luò)提取多個空間位置的特征,再在網(wǎng)絡(luò)的最高層開始上采樣并和對應(yīng)的特征提取網(wǎng)絡(luò)橫向連接,生成多個尺度的特征圖,從而獲得多尺度的語義信息。
因為網(wǎng)絡(luò)高層的特征雖然包含了豐富的語義信息,但是由于低分辨率,很難準確地保存物體的位置信息。與之相反,低層的特征雖然語義信息較少,但是由于分辨率高,就可以準確地包含物體位置信息,所以通過融合這些不同層的特征能達到識別和定位更準確的預(yù)測效果。
FPN可以應(yīng)用到各種網(wǎng)絡(luò)模型,提升模型效果。如目標檢測模型Faster R-CNN,實例分割模型Mask R-CNN,以及下述全景分割網(wǎng)絡(luò)Panoptic FCN。
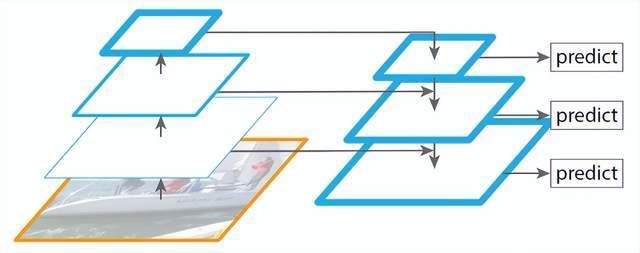
特征金字塔網(wǎng)絡(luò)
2.box-free,thing和stuff使用不同的分支預(yù)測,先預(yù)測語義再生成實例,不需要先進行目標檢測。
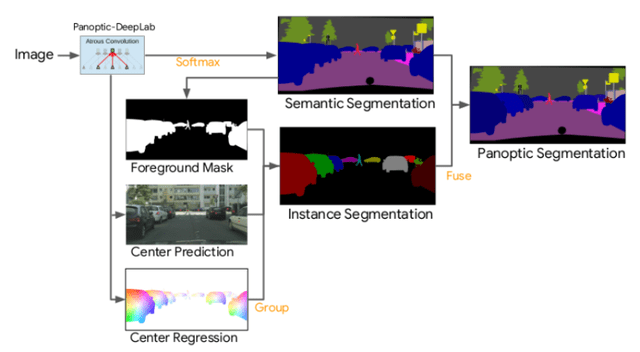
如Panoptic-DeepLab模型,去除了Panoptic FPN的box預(yù)測部分,直接預(yù)測出thing和stuff。為了得到目標實例預(yù)測,在實例分割分支同時預(yù)測了每個實例的中心點及其heatmap,得到像素點與實例關(guān)鍵點之間的關(guān)系,并依此融合形成類別未知的不同實例,另外語義分割分支直接預(yù)測輸出,最后結(jié)合兩個分支輸出得到全景分割的結(jié)果。
與box-based方法相比,去除了boxes預(yù)測步驟,推理速度更快,減少了由于boxes的限制對分割精度的影響。
3.thing和stuff完全使用相同的結(jié)構(gòu)進行預(yù)測,如Panoptic-FCN。
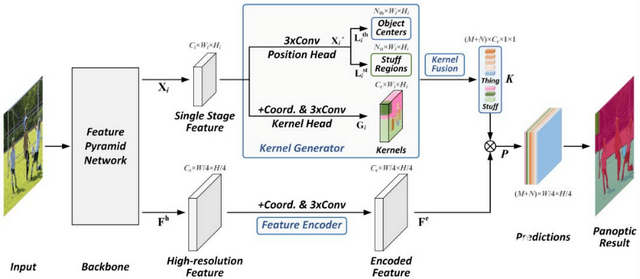
Panoptic FCN是將thing和stuff統(tǒng)一成特征描述子(kernels)來進行預(yù)測。主要由FPN、Kernel Generator、Kernel Fusion和Feature Encoder四個部分組成。
先通過FPN得到多尺度特征圖,對每個特征圖的thing和stuff生成kernels權(quán)重,然后通過Kernel Fusion對多個特征圖的kernels權(quán)重進行合并。
Kernel Generator由Kernel Head和Position Head兩個分支構(gòu)成,首先同時預(yù)測thing和stuff的位置,其中,thing通過預(yù)測中心點(centers)來定位和分類,stuff通過預(yù)測區(qū)域(regions)來定位和分類,然后根據(jù)thing和stuff的位置,從Kernel Head中產(chǎn)生kernels權(quán)重。Feature Encoder用來對高分辨率特征進行編碼,最后將得到的kernels權(quán)重和編碼特征融合得到最終預(yù)測結(jié)果。
上述的box-based和box-free全景分割都是將thing和stuff拆分成兩個分支來進行預(yù)測的,這必然會引入更多的后處理還有設(shè)計不同分支信息融合的操作,使得整個系統(tǒng)既冗余又復(fù)雜。
Panoptic FCN實現(xiàn)了真正的端到端全景分割,省去了子任務(wù)融合的操作,推理速度快,效果好。
02 全景分割在自動駕駛中的應(yīng)用
1.可行駛區(qū)域識別,分割路面及車道線確定機動車行駛區(qū)域或者當前車道區(qū)域等。
由于這種區(qū)域通常是不規(guī)則多邊形,所以使用分割是一種比較好的解決方法。但是也存在邊緣分割不準確的問題。
2.判斷碰撞區(qū)域內(nèi)是否有車輛、行人,與目標檢測相比,分割能更精確表示車輛及行人的邊界位置。但是圖像中目標重疊時,存在像素分配沖突問題。
03 示例圖
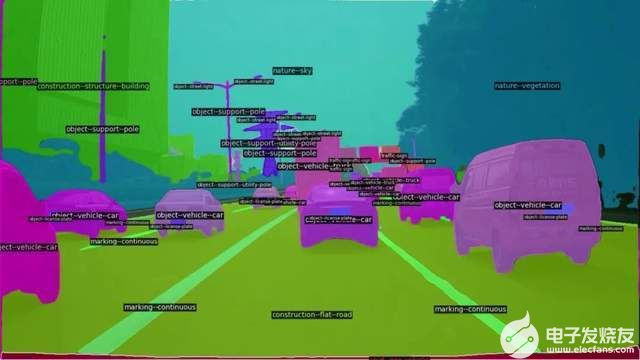
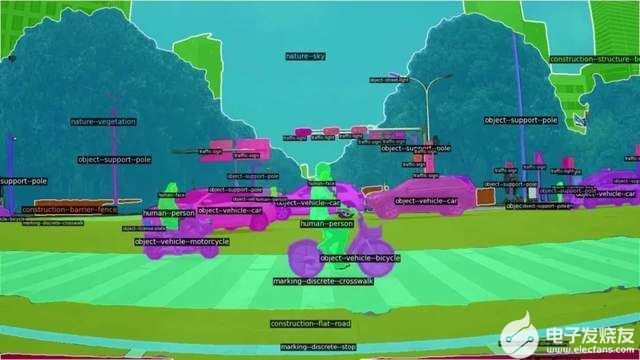
1、ADAS視角城市道路全景分割。
-
RGB
+關(guān)注
關(guān)注
4文章
831瀏覽量
61992 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18776
發(fā)布評論請先 登錄
一文讀懂車載攝像頭產(chǎn)業(yè)鏈
一文匯總當前主流的分割網(wǎng)絡(luò)

一文帶你讀懂耦合與退耦,上拉與下拉資料下載

一文讀懂圖像分割
沒你想的那么難 | 一文讀懂圖像分割






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論