 使用高級 MCU 實現加速機器學習應用
使用高級 MCU 實現加速機器學習應用

從歷史上看,人工智能 (AI) 是一種 GPU / CPU 甚至 DSP 依賴的技術。然而,最近人工智能正在通過集成到運行在較小微控制器(也稱為 MCU)上的受限應用程序中來進入數據采集系統。這一趨勢主要由物聯網 (IoT) 市場推動,Silicon Labs 是其中的主要參與者。
為了應對這一新的物聯網趨勢,Silicon Labs 宣布推出一款可以執行硬件加速 AI 操作的無線 MCU。為了實現這一點,該 MCU 設計為嵌入矩陣矢量處理器 (MVP),即 EFR32xG24。
在本文中,我將首先介紹一些 AI 基礎知識,重點介紹 MVP 的用例。最重要的是,如何使用 EFR32xG24 設計 AI IoT 應用程序。
人工智能、機器學習和邊緣計算
人工智能是一個試圖模仿人類行為的系統。更具體地說,它是一種電氣和/或機械實體,可以模擬對輸入的響應,類似于人類會做的事情。盡管術語 AI 和機器學習 (ML) 經常互換使用,但它們代表了兩種不同的方法。AI 是一個更廣泛的概念,而 ML 是 AI 的一個子集。
使用機器學習,系統可以在重復使用所謂的模型后做出預測并改進(或訓練)自身。模型是使用經過訓練的算法,最終將用于模擬決策。可以通過收集數據或使用現有數據集來訓練該模型。當該系統將其“訓練過的”模型應用于新獲取的數據以做出決策時,我們將其稱為機器學習推理。
如前所述,推理需要通常由高端計算機處理的計算能力。但是,我們現在能夠在不需要連接到此類高端計算機的更多受限設備上運行推理;這稱為邊緣計算。
通過在 MCU 上運行推理,可以考慮執行邊緣計算。邊緣計算涉及在距離獲取數據的最近點運行數據處理算法。邊緣設備的示例通常是簡單且受限的設備,例如傳感器或基本執行器(燈泡、恒溫器、門傳感器、電表等)。這些設備通常在低功耗 ARM Cortex-M 類 MCU 上運行:
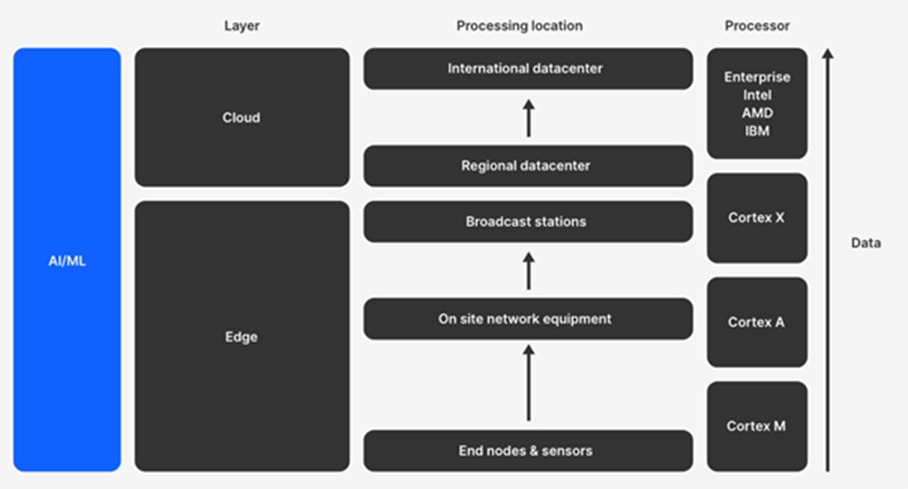
執行邊緣計算有很多好處。可以說,最有價值的好處是使用邊緣計算的系統不依賴于外部實體。設備可以在本地“做出自己的決定”。
在本地進行決策具有以下實際好處:
-
提供更低的延遲
原始數據不需要傳輸到云端進行處理,這意味著決策可以實時出現在設備上。 -
減少所需的互聯網帶寬
傳感器會產生大量實時數據,這反過來又會產生對帶寬的大量需求,即使沒有什么可“報告”,從而使無線頻譜飽和并增加運行成本。 -
降低功耗
與傳輸數據相比,本地分析數據(使用 AI)所需的功率要少得多 -
符合隱私和安全要求
通過在本地做出決策,無需將詳細的原始數據發送到云端,只需將推理結果和元數據發送到云端,從而消除了數據隱私泄露的可能性。 -
降低成本
在本地分析傳感器數據可以節省使用云基礎設施和流量的費用。 -
提高彈性
如果與云的連接中斷,邊緣節點仍可以自主運行。
Silicon Labs 用于邊緣計算的 EFR32xG24
EFR32xG24 是一款安全無線 MCU,支持多種 2.4 GHz IoT 協議(藍牙低功耗、Matter、Zigbee 和 OpenThread 協議)。它還包括 Secure Vault,這是一種改進的安全功能集,適用于所有 Silicon Labs Series 2 平臺。
但是,除了改進了該 MCU 獨有的安全性和連接性之外,還有一個用于機器學習模型推理的硬件加速器(以及其他加速器),稱為矩陣矢量處理器 (MVP)。
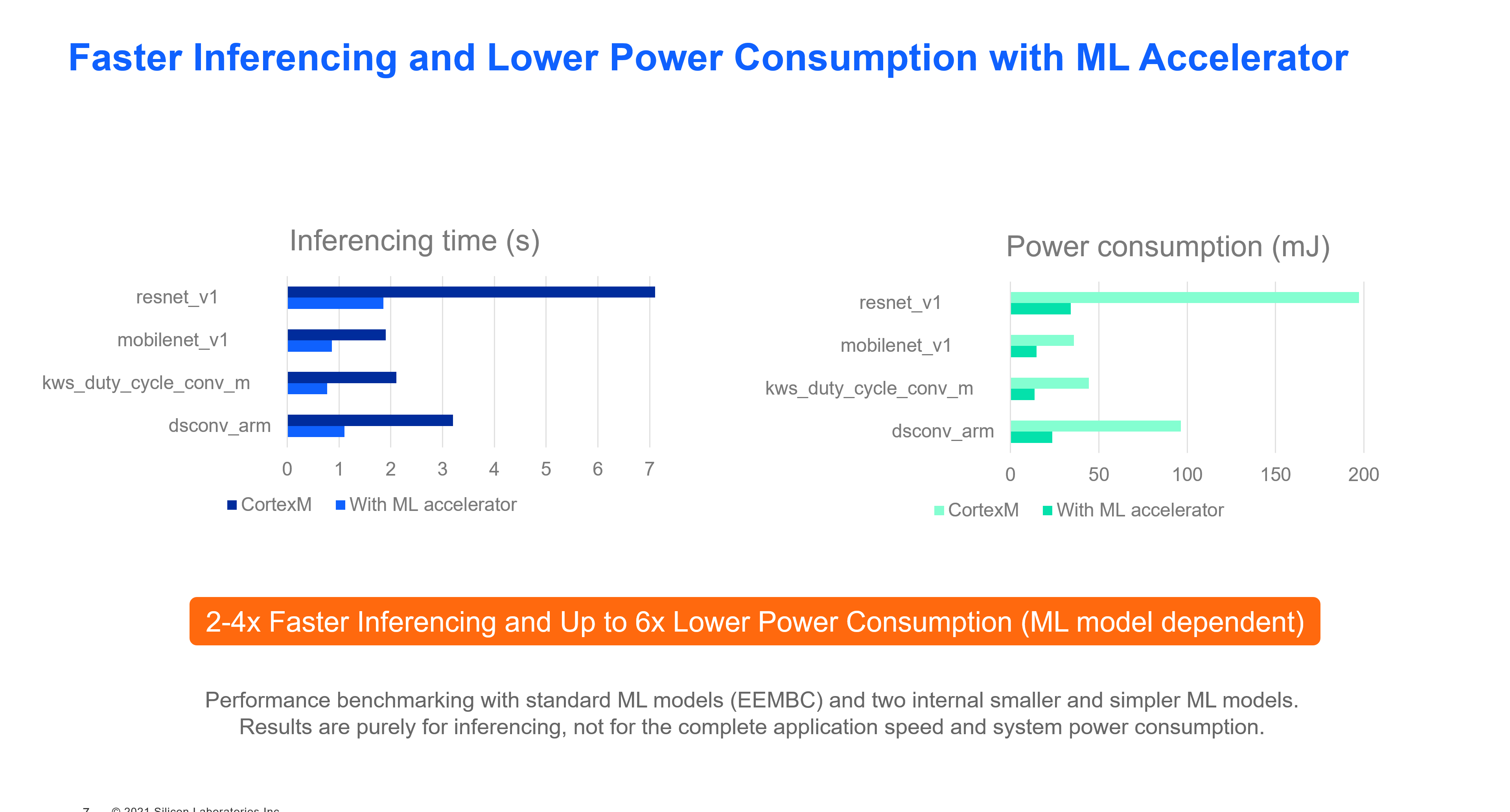
與沒有硬件加速的 ARM Cortex-M 相比,MVP 提供了更高效地運行機器學習推理的能力,功耗降低了 6 倍,速度提高了 2-4 倍(實際改進取決于模型和應用程序)。
MVP 旨在通過處理密集的浮點運算來卸載 CPU。它專為復雜的矩陣浮點乘法和加法而設計。
MVP 由專用硬件算術邏輯單元 (ALU)、加載/存儲單元 (LSU) 和定序器組成。
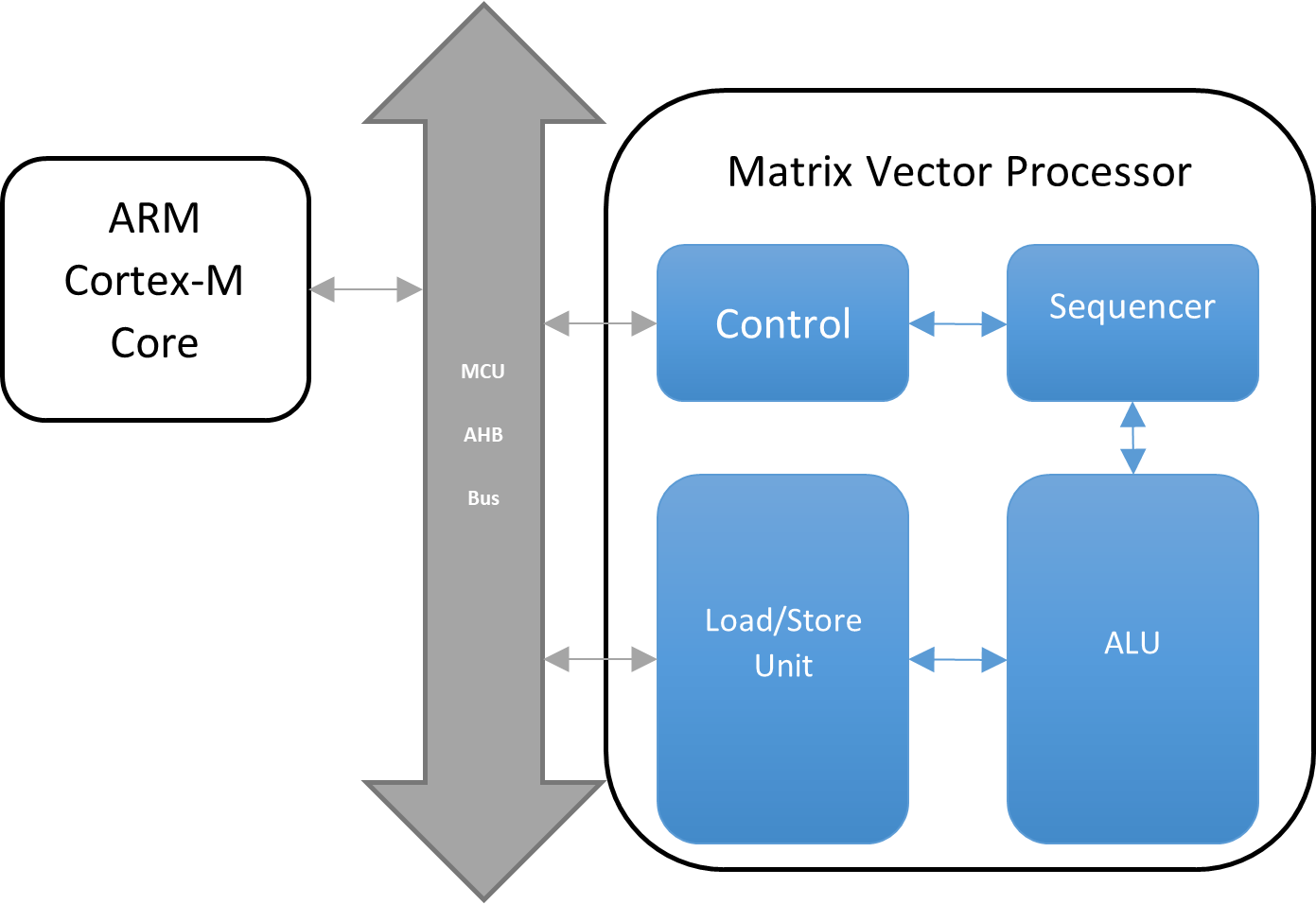
因此,MVP 有助于加速各種應用程序的處理并節省功耗,例如到達角 (AoA)、MUSIC 算法計算、機器學習(本征或基本線性代數子程序 BLAS)等。
由于該設備是一個簡單的 MCU,它無法解決 AI/ML 可以涵蓋的所有用例。它旨在解決下面列出的以下四個類別以及實際應用:
為了幫助解決這些問題,Silicon Labs 提供了基于稱為 TensorFlow 的 AI/ML 框架的專用示例應用程序。
TensorFlow 是來自 Google 的用于機器學習的端到端開源平臺。它擁有一個由工具、庫和社區資源組成的全面、靈活的生態系統,使研究人員能夠推動 ML 的最新技術,開發人員可以輕松構建和部署 ML 驅動的應用程序。
Tensor Flow 項目還針對嵌入式硬件變體進行了優化,稱為 TensorFlow Lite for Microcontrollers (TFLM)。這是一個開源項目,其中大部分代碼由社區工程師貢獻,包括 Silicon Labs 和其他芯片供應商。目前,這是與 Silicon Labs Gecko SDK 軟件套件一起交付的用于創建 AI/ML 應用程序的唯一框架。
Silicon Labs 提供的 AI/ML 示例有:
- Zigbee 3.0 帶語音激活的電燈開關
- 張量流魔棒
- 聲控 LED
- 張量流 Hello world
- 張量流微演講
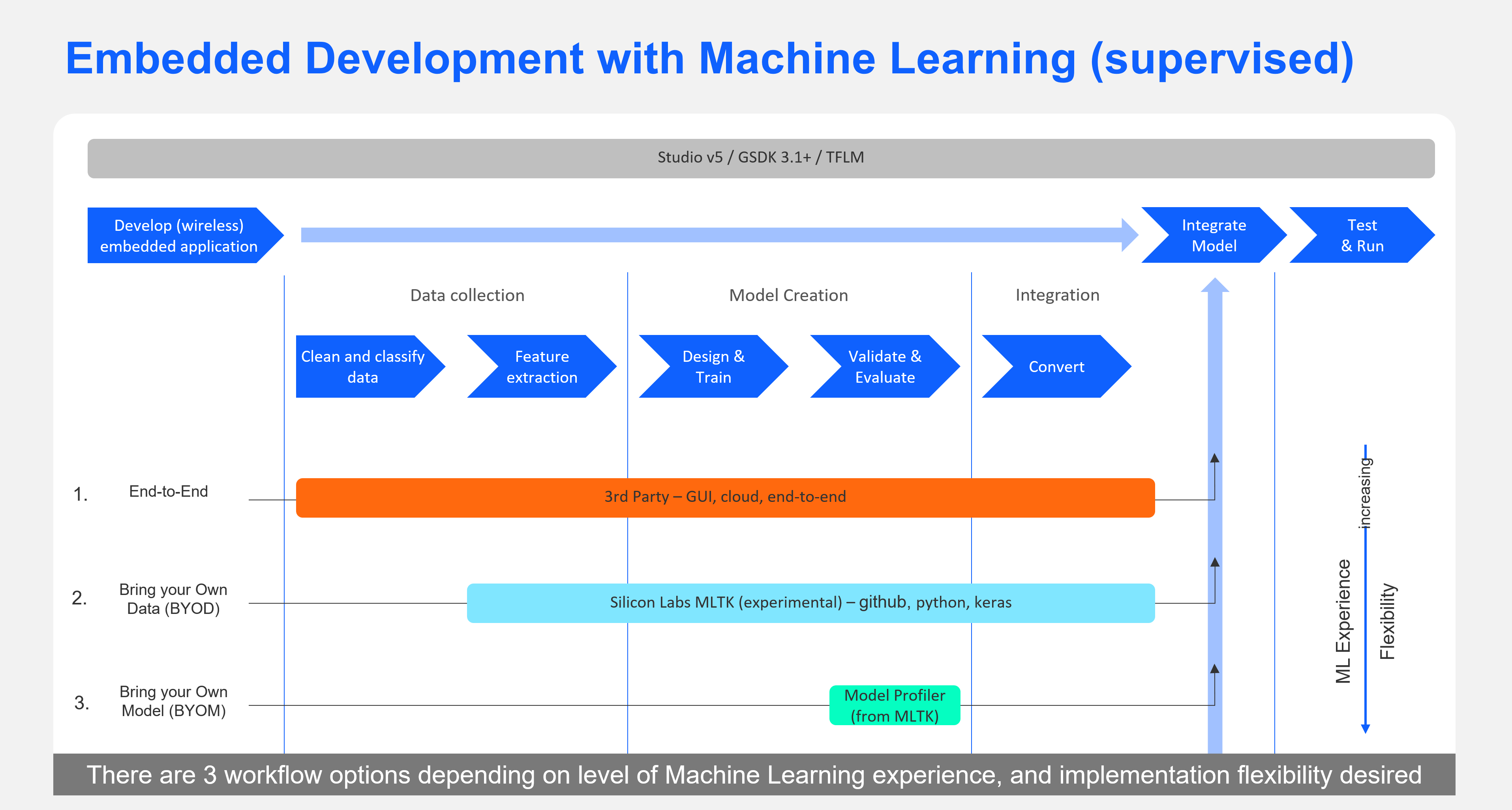
要開始開發基于其中任何一個的應用程序,您可以有很少的經驗,或者您可以成為專家。Silicon Labs 提供多種機器學習開發工具供您選擇,具體取決于您的機器學習專業水平。
對于第一次 ML 開發人員,您可以從我們的一個示例開始,或者嘗試我們的第 3 方合作伙伴之一。我們的第 3 方 ML 合作伙伴通過功能豐富且易于使用的 GUI 界面支持完整的端到端工作流程,以便為我們的芯片構建最佳機器學習模型。
對于希望直接使用 Keras/TensorFlow 平臺的 ML 專家,Silicon Labs 提供了一個自助式、自助式的參考包,將模型開發工作流程組織成一個專為為 Silicon Labs 芯片構建 ML 模型而定制的工作流程。
開發支持 ML 的應用示例:采用 EFR32xG24 的語音控制 Zigbee 開關
要創建支持 ML 的應用程序,需要兩個主要步驟。第一步是創建一個無線應用程序,您可以使用 Zigbee、BLE、Matter 或任何基于 2.4 GHz 協議的專有應用程序來完成。它甚至可以是未連接的應用程序。第二步是構建 ML 模型以將其與應用程序集成。
如上所述,Silicon Labs 提供了多種選項來為其 MCU 創建 ML 應用程序。此處選擇的方法是使用具有預定義模型的現有示例應用程序。在這個例子中,模型被訓練來檢測兩個語音命令:“on”和“off”。
EFR32xG24 應用程序入門
 |
要開始使用,請獲取 EFR32MG24 開發人員套件 BRD2601A(左)。 該開發套件是一個緊湊型電路板,嵌入了多個傳感器(IMU、溫度、相對濕度等)、LED 和 Stereo I 2 S 麥克風。 該項目將使用 I 2 S 麥克風。 這些設備可能不像 GPU 那樣稀有,但如果您沒有機會獲得這些套件之一,您還可以使用基于系列 1 的舊開發套件,稱為“Thunderboard Sense 2”參考。SLTB004A(右)。 但是,此 MCU 沒有 MVP,將使用主內核執行所有推理,無需加速。 |
 |
接下來,您需要 Silicon Labs 的 IDE Simplicity Studio 來創建 ML 項目。它提供了一種下載 Silicon Labs 的 Gecko SDK 軟件套件的簡單方法,該套件提供了應用程序所需的庫和驅動程序,如下所示。
- 無線網絡堆棧(本例中為 Zigbee)
- 硬件驅動程序(用于 I2S 麥克風以及 MVP)
- TensorFlow Lite 框架
- 一個已經訓練過的用于檢測命令詞的模型
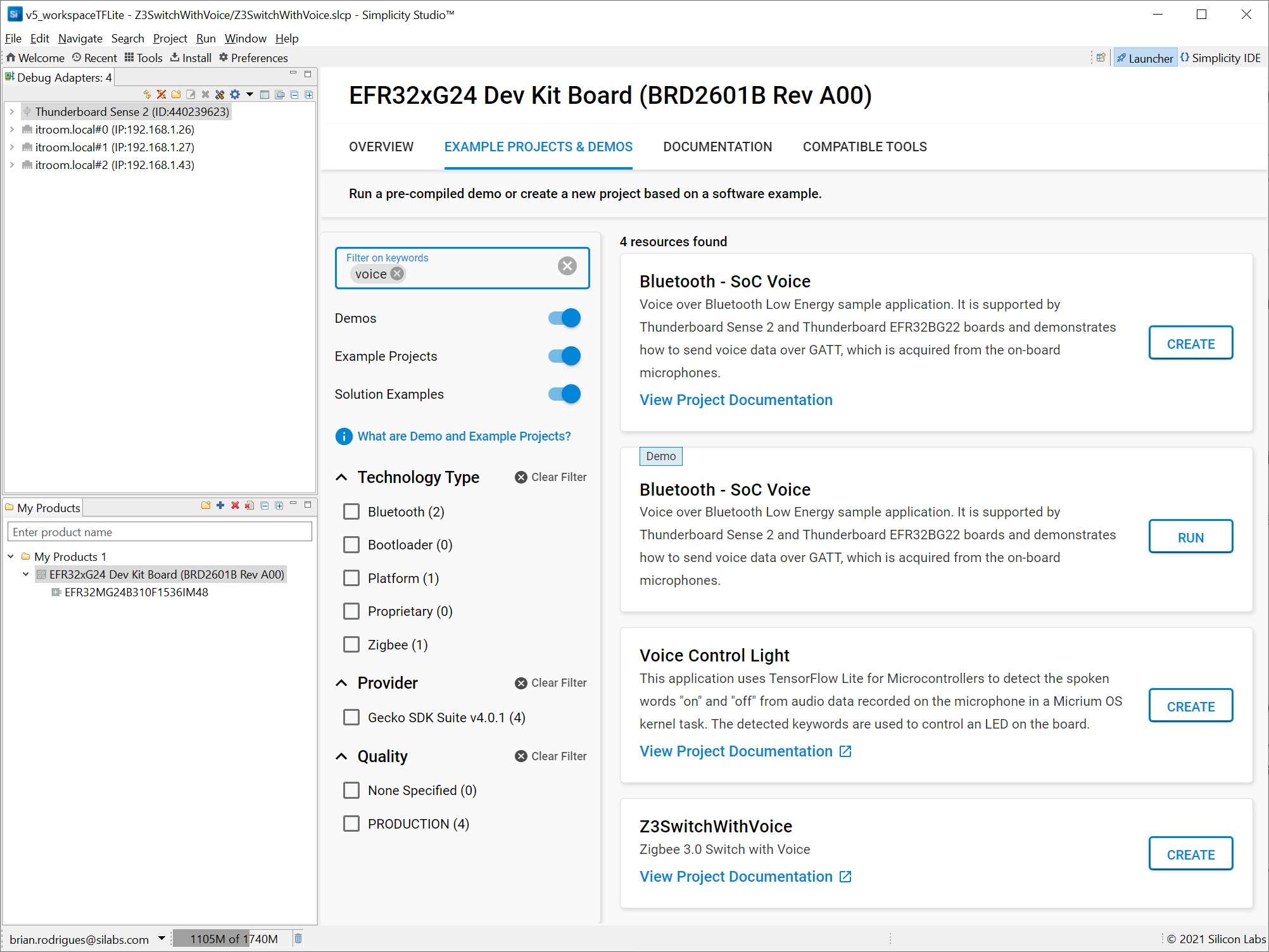
IDE 還提供工具來進一步分析您的應用程序功耗或網絡操作。
創建啟用 MVP 的 Zigbee 3.0 Switch 項目
Silicon Labs 提供了一個即用型示例應用程序 Z3SwitchWithVoice,您將創建和構建該應用程序。該應用程序已經附帶了一個 ML 模型,因此您無需創建一個。
創建后,請注意 Simplicity Studio 項目由組件帶來的源文件組成,這些組件是 GUI 實體,通過簡化復雜軟件的集成,可以輕松使用 Silicon Labs 的 MCU。在這種情況下,您可以看到默認安裝了 MVP 支持和 Zigbee 網絡堆棧。
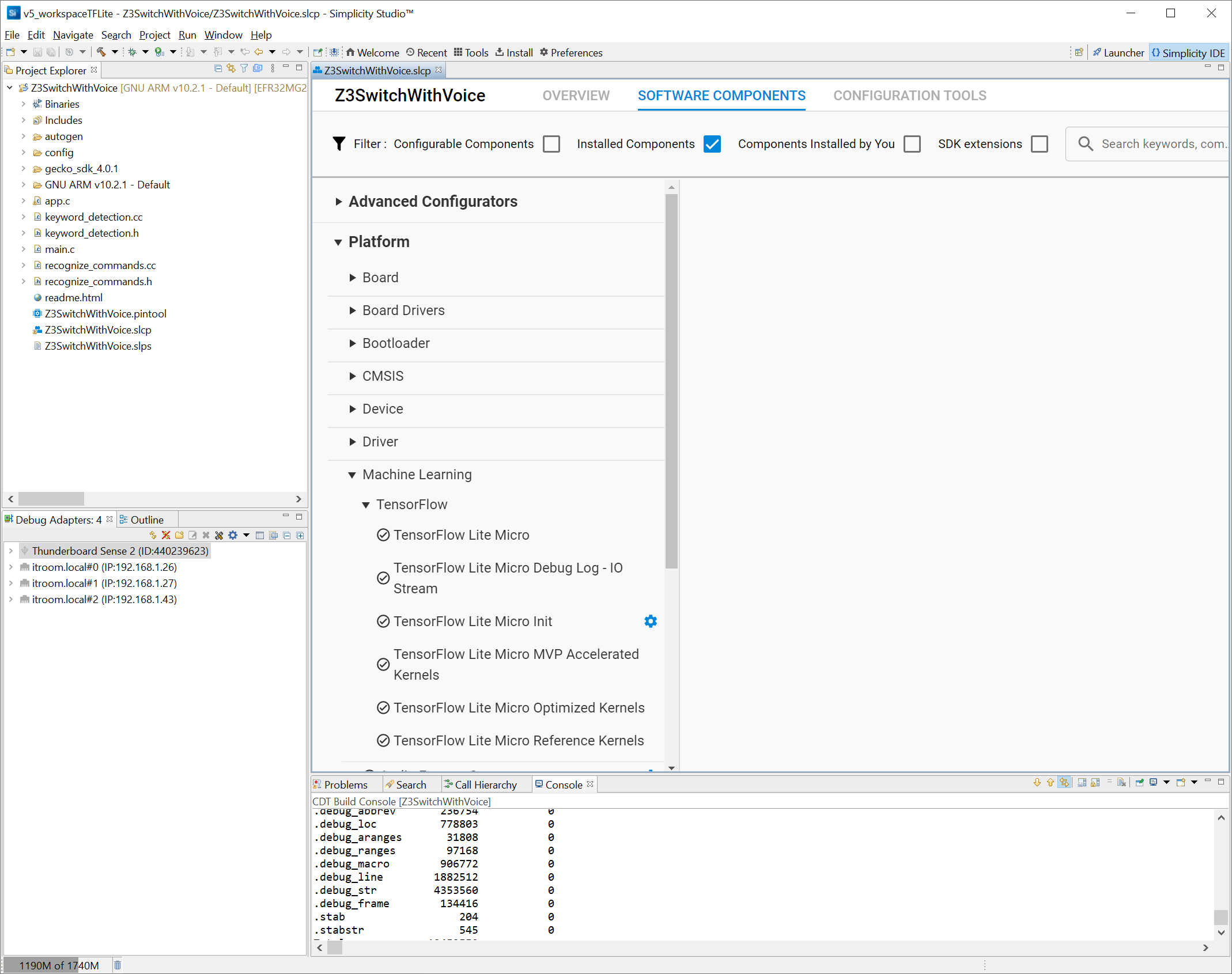
主要應用程序代碼位于 app.c 源文件中。
在網絡方面,應用程序可以通過一個簡單的按鈕與任何現有的 Zigbee 3.0 網絡配對,也稱為“網絡轉向”。聯網后,MCU 將尋找兼容且可配對的照明設備,也稱為“綁定”。
當應用程序的網絡部分啟動并運行時,MCU 將定期輪詢麥克風數據樣本并在其上運行推理。此代碼位于keyword_detection.c 中。
()
{
found_command_index = 0;
分數 = 0;
is_new_command = ;
current_time_stamp;
current_time_stamp = sl_sleeptimer_tick_to_ms(sl_sleeptimer_get_tick_count());
TfLiteStatus process_status = command_recognizer->ProcessLatestResults(
sl_tflite_micro_get_output_tensor(), current_time_stamp, &found_command_index, &score, &is_new_command);
(process_status != ) {
SL_STATUS_FAIL;
}
(is_new_command) {
(found_command_index == 0 || found_command_index == 1) {
printf( , kCategoryLabels[found_command_index],
分數,current_time_stamp);
檢測到的關鍵字(found_command_index);
}
}
SL_STATUS_OK;
}
檢測到關鍵字后,app.c 中的處理程序將發送相應的 Zigbee 命令:
{
狀態;
(emberAfNetworkState()==){
emberAfGetCommandApsFrame()-> = SWITCH_ENDPOINT;
(detected_keyword_index == 0) {
emberAfFillCommandOnOffClusterOn();
} (detected_keyword_index == 1) {
emberAfFillCommandOnOffClusterOff();
}
狀態 = emberAfSendCommandUnicastToBindings();
sl_zigbee_app_debug_print( , , status);
}
}
此時,您已在無線 MCU 上運行硬件加速推理以進行邊緣計算。
自定義 TensorFlow 模型以使用不同的命令詞
如前所述,實際模型已經集成到該應用程序中,并且沒有進一步修改。但是,如果您自己集成模型,則可以通過以下步驟進行:
- 收集和標記數據
- 設計和構建模型
- 評估和驗證模型
- 為嵌入式設備轉換模型
無論您對機器學習多么熟悉,都必須遵循這些步驟。不同之處在于如何構建模型,如下所示:
- 如果您是 ML 的初學者,Silicon Labs 建議使用我們易于使用的端到端第三方合作伙伴平臺之一:Edge Impulse 或 SensiML 來構建您的模型。
- 如果您是 Keras/TensorFlow 方面的專家并且不想使用第三方工具,您可以使用機器學習工具包 (MLTK),它是一個自助式、自助式的 Python 包。Silicon Labs 圍繞音頻用例創建了這個參考包,可以擴展、修改或以其他方式挑選專家認為有吸引力的部分。該包將在 GitHub 上提供,附帶文檔。您也可以直接導入一個 .tflite 文件,該文件在 TensorFlow lite 的嵌入式版本上運行,用于為 EFR32 產品線進行微編譯。您必須確保數據上的特征提取對于訓練模型與在目標芯片上運行推理完全相同。
在 Simplicity Studio 中,后者是最簡單的。要在 Simplicity Studio 中更改模型,請將 .tflite 模型文件復制到項目的 config/tflite 文件夾中。項目配置器提供了一個工具,可以自動將 .tflite 文件轉換為 sl_ml_model 源文件和頭文件。此工具的完整文檔可在Flatbuffer Conversion獲得。
[注意:所有圖片和代碼均由 Silicon Labs 提供。]
審核編輯 黃昊宇
-
mcu
+關注
關注
147文章
18938瀏覽量
398635
發布評論請先 登錄
如何正確配置AG32 MCU,實現FLASH或者代碼加密?
Solist?AI?:讓 MCU 擁有“現場學習能力”的邊緣智能方案

MCU軟件核心庫及示例代碼速覽 !

貿澤開售ROHM Semiconductor ML63Q25x AI MCU 助力實現更高效可靠的自動化、機器人及智能應用

工業級-專業液晶圖形顯示加速器RA8889ML3N簡介+顯示方案選型參考表
RSA加速實現思路
借助高度集成的實時控制MCU實現更平穩、更靜音的電機性能

普迪飛制造業高級洞察解決方案(AIM):以機器學習(ML)重構生產效能,解鎖工業 4.0 落地新路徑

FPGA在機器學習中的具體應用

極海半導體G32R501:面向具身機器人的高性能、高安全實時控制MCU/DSP

48V電氣系統如何實現ADAS的高級功能
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現




 工商網監
工商網監
評論